Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Mejores prácticas para la previsión de la demanda de nuevos productos
En esta sección se analizan las siguientes prácticas recomendadas para la previsión de la demanda de nuevos productos:
Cumpla con los requisitos de preparación de datos para la previsión de la demanda basada en datos NPI
Para adoptar enfoques basados en datos para NPI la previsión de la demanda, su organización debe contar con el apoyo de todas las partes interesadas pertinentes, como los gerentes del departamento de ciencia de datos o análisis, la cadena de suministro, el marketing y la TI. A continuación, su organización debería identificar lo siguiente:
-
Las fuentes de los datos internos existentes y los datos externos relevantes
-
Los propietarios de estas fuentes de datos
-
Los procedimientos y permisos necesarios para utilizar estas fuentes de datos para la iniciativa
Puede evaluar la disponibilidad de sus datos en función de los siguientes tipos de conjuntos de datos obligatorios y opcionales. El uso de tantos conjuntos de datos como sea posible, incluido el opcional, ayuda a los modelos de aprendizaje automático a generar previsiones de NPI demanda más precisas.
Los siguientes son ejemplos de fuentes de datos internas obligatorias:
-
Historial de ventas completo (desde el lanzamiento del producto hasta su descontinuación) de todos los productos o subconjuntos de productos que tengan características similares a las del nuevo producto que se está lanzando. El historial de ventas puede provenir de varios canales de venta o estar combinado en todos los canales.
-
Mapeo de atributos de productos para identificar el subconjunto de productos que tienen atributos similares a los del nuevo producto que se está lanzando.
Los siguientes son ejemplos de fuentes de datos internas opcionales:
-
Datos de marketing que rastrean las promociones y descuentos de productos similares. Estos datos deben ser iguales o superiores a la longitud del historial de ventas.
-
Reseñas de productos, valoraciones y datos de tráfico web. Estos datos deben ser iguales o superiores a la longitud del historial de ventas.
-
Datos demográficos de los consumidores
Los siguientes son ejemplos de fuentes de datos externas opcionales que pueden complementar sus datos internos:
-
Datos del índice de consumo
-
Datos de ventas de la competencia
-
Datos de la encuesta
Cree mecanismos de ingesta de datos rentables
Una vez que se cumpla el requisito de preparación de los datos, su organización puede elegir los mecanismos de ingesta y almacenamiento de datos más adecuados. Si las principales fuentes de datos de ventas de su organización se recopilan a diario desde diferentes canales, considere la posibilidad de incorporar datos por lotes. La ingesta de datos en streaming es otra opción si desea realizar previsiones de autoservicio que se beneficien de disponer de los datos más recientes.
La canalización de ingesta de datos sin procesar debería utilizar una canalización de extracción, transformación y carga (ETL) para una transformación sencilla. La canalización debe realizar comprobaciones de calidad de los datos y almacenar los datos procesados en una base de datos para su consumo posterior.
Puede utilizar Servicios de AWSAmazon Data Firehose y Amazon Simple Storage Service (Amazon S3) para una ingesta y un almacenamiento de datos rentables. AWS GlueAWS Glue Data Catalog AWS Glue es un ETL servicio sin servidor totalmente gestionado que le ayuda a clasificar, limpiar, transformar y transferir datos de forma fiable entre distintos almacenes de datos. Los componentes principales de AWS Glue consisten en un repositorio central de metadatos, conocido como AWS Glue Data Catalog, y un sistema de ETL trabajos que genera automáticamente código de Python y Scala y administra los ETL trabajos. Amazon Data Firehose le ayuda a recopilar, procesar y analizar datos de streaming en tiempo real a cualquier escala. Firehose puede entregar datos de streaming en tiempo real directamente a lagos de datos (como Amazon S3), almacenes de datos y servicios analíticos para su posterior procesamiento. Amazon S3: es un servicio de almacenamiento de objetos de AWS que ofrece escalabilidad, disponibilidad de datos, seguridad y rendimiento.
Determine los enfoques de aprendizaje automático factibles para pronosticar la demanda NPI
Según el caso de uso específico, su organización puede considerar diferentes opciones de previsión.
Un enfoque de pronóstico estadístico, como el modelo de difusión de Bass
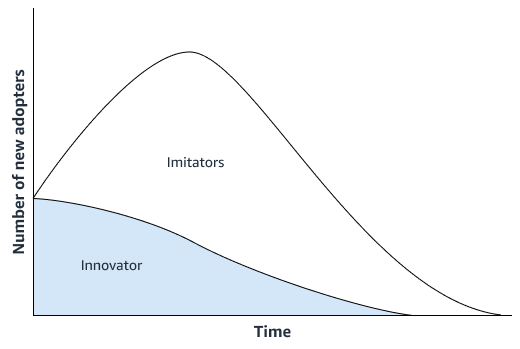
Si el nuevo producto no presenta una innovación significativa, su organización puede utilizar modelos de previsión de series temporales que se basen en el historial de ventas del producto más similar al nuevo producto. Puede utilizar algoritmos de previsión basados en ML, como el algoritmo de previsión Amazon AI SageMaker DeepAR, que puede utilizar datos de ventas de series temporales de varios productos similares. Esto es ideal para escenarios de previsión con arranque en frío, es decir, cuando se quiere generar una previsión para una serie temporal pero se dispone de pocos o ningún dato histórico. La siguiente imagen muestra cómo puede utilizar los datos de series temporales de productos relacionados para generar una previsión para un producto nuevo y similar.
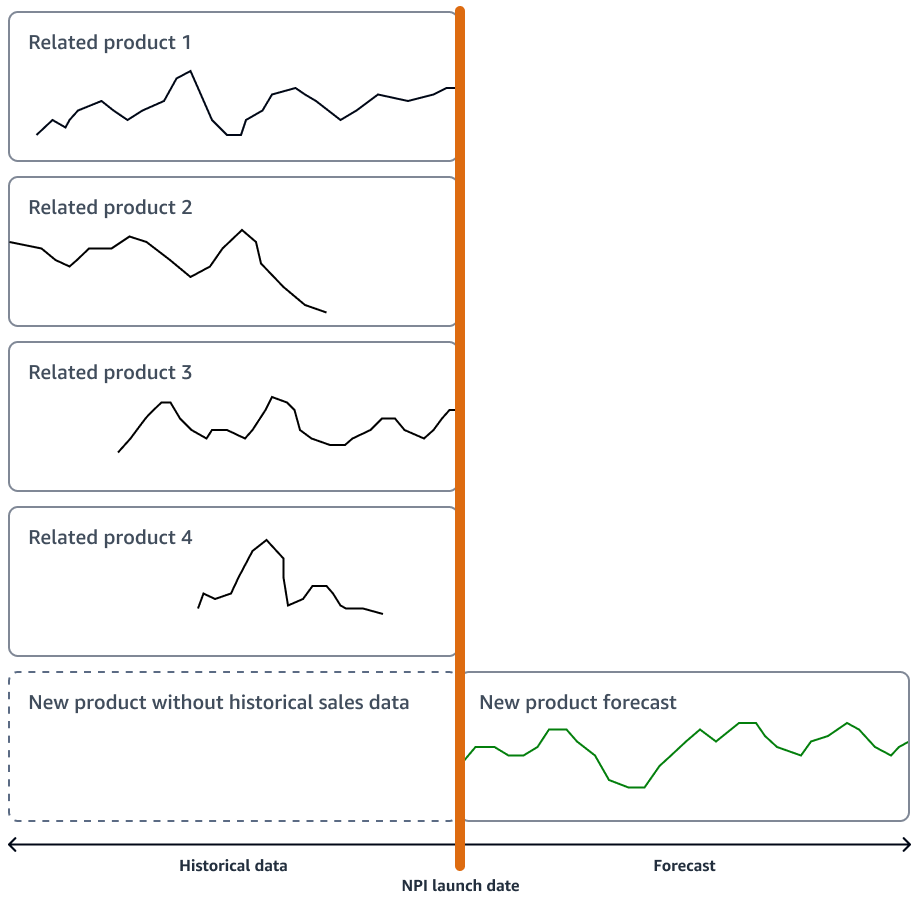
Deberías considerar la posibilidad de generar previsiones que se ajusten al cronograma de lanzamiento de tu nuevo producto. Genere previsiones con bastante antelación para disponer de suficiente margen de maniobra para cualquier corrección logística.
Escale y realice un seguimiento de los efectos del pronóstico
Tras completar una prueba de concepto para NPI la previsión de la demanda, la solución debería ampliarse eventualmente para incluir productos adicionales y varias regiones. Utilice un marco de inteligencia artificial y aprendizaje automático (AI/ML) para preparar los datos y desarrollar, implementar y monitorear el modelo.
El siguiente diagrama muestra la estrategia de lanzamiento y escalado a medida que la solución de NPI previsión de la organización va madurando.
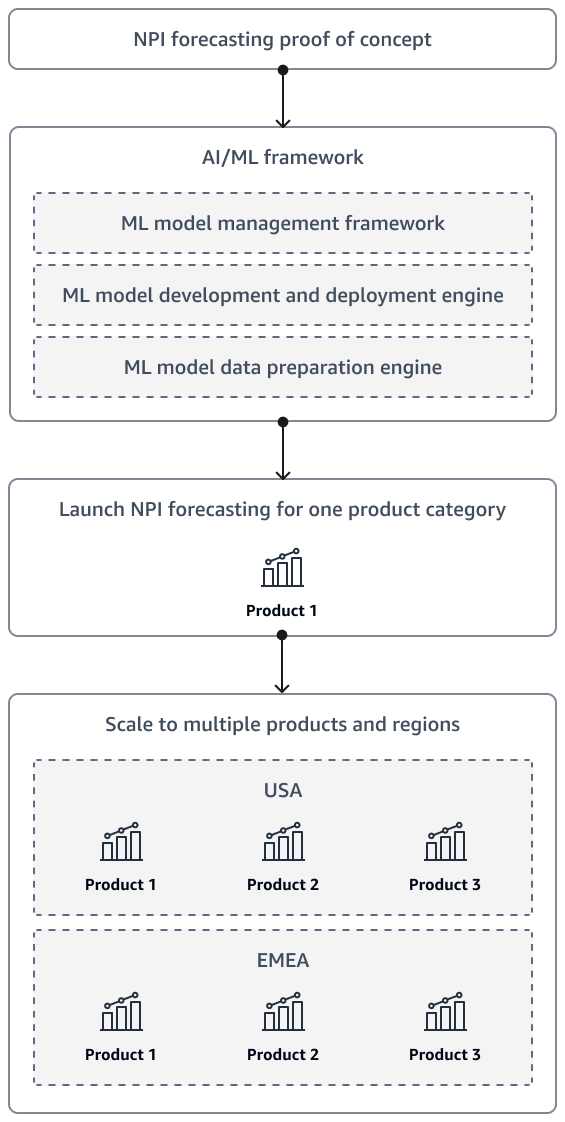
También se recomienda diseñar la solución de forma que los ejecutivos y las partes interesadas puedan elaborar sus propias previsiones. Por ejemplo, puedes crear QuickSightpaneles de Amazon para que las partes interesadas puedan acceder a las últimas previsiones bajo demanda.
Supervise de cerca la precisión de las previsiones e investigue minuciosamente las desviaciones para garantizar un retorno de la inversión razonable ()ROI. Si configura la supervisión de modelos con Amazon SageMaker AI Model Monitor, podrá realizar un seguimiento del rendimiento de sus modelos a medida que realizan predicciones en tiempo real a partir de datos en tiempo real. Puede utilizar el Amazon SageMaker Model Dashboard para encontrar modelos que infrinjan los umbrales que haya establecido en cuanto a la calidad de los datos, la calidad del modelo, el sesgo y la explicabilidad. Para obtener más información, consulte Utilizar la gobernanza para gestionar los permisos y realizar un seguimiento del rendimiento del modelo en la documentación de Amazon SageMaker AI.
