Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Emule las matrices PL/SQL asociativas de Oracle en Amazon Aurora PostgreSQL y Amazon RDS for PostgreSQL
Rajkumar Raghuwanshi, Bhanu Ganesh Gudivada y Sachin Khanna, de Amazon Web Services
Resumen
Este patrón describe cómo emular matrices PL/SQL asociativas de Oracle con posiciones de índice vacías en entornos Amazon Aurora PostgreSQL y Amazon RDS for PostgreSQL
Ofrecemos una alternativa de PostgreSQL al aws_oracle_ext uso de funciones para gestionar posiciones de índice vacías al migrar una base de datos de Oracle. Este patrón utiliza una columna adicional para almacenar las posiciones del índice y mantiene el manejo de matrices dispersas por parte de Oracle, a la vez que incorpora las capacidades nativas de PostgreSQL.
Oracle
En Oracle, las colecciones pueden inicializarse como vacías y rellenarse mediante el método EXTEND collection, que añade NULL elementos a la matriz. Cuando se trabaja con matrices PL/SQL asociativas indexadas porPLS_INTEGER, el EXTEND método agrega NULL elementos secuencialmente, pero los elementos también se pueden inicializar en posiciones de índice no secuenciales. Cualquier posición del índice que no esté inicializada de forma explícita permanece vacía.
Esta flexibilidad permite estructuras de matriz dispersas en las que los elementos se pueden rellenar en posiciones arbitrarias. Al recorrer las colecciones utilizando un ancho FIRST y un FOR LOOP LAST límite, solo se procesan los elementos inicializados (con NULL o sin un valor definido), mientras que las posiciones vacías se omiten.
PostgreSQL (Amazon Aurora y Amazon RDS)
PostgreSQL gestiona los valores vacíos de forma diferente a los valores. NULL Almacena los valores vacíos como entidades distintas que utilizan un byte de almacenamiento. Cuando una matriz tiene valores vacíos, PostgreSQL asigna posiciones de índice secuenciales igual que los valores no vacíos. Sin embargo, la indexación secuencial requiere un procesamiento adicional porque el sistema debe recorrer en iteraciones todas las posiciones indexadas, incluidas las vacías. Esto hace que la creación de matrices tradicional sea ineficiente para conjuntos de datos dispersos.
AWS Schema Conversion Tool
El AWS Schema Conversion Tool (AWS SCT) normalmente gestiona las Oracle-to-PostgreSQL migraciones mediante funciones. aws_oracle_ext En este patrón, proponemos un enfoque alternativo que utiliza las capacidades nativas de PostgreSQL, que combina los tipos de matrices de PostgreSQL con una columna adicional para almacenar las posiciones del índice. Luego, el sistema puede recorrer en iteraciones las matrices utilizando solo la columna de índice.
Requisitos previos y limitaciones
Requisitos previos
Un activo. Cuenta de AWS
Un usuario AWS Identity and Access Management (IAM) con permisos de administrador.
Una instancia compatible con Amazon RDS o Aurora PostgreSQL.
Conocimientos básicos de las bases de datos relacionales.
Limitaciones
Algunas Servicios de AWS no están disponibles en todos Regiones de AWS. Para ver la disponibilidad por región, consulta Servicios de AWS por región
. Para ver puntos de enlace específicos, consulta la página de puntos de enlace y cuotas del servicio y elige el enlace del servicio.
Versiones de producto
Este patrón se probó con las siguientes versiones:
Amazon Aurora PostgreSQL 13.3
Amazon RDS para PostgreSQL 13.3
AWS SCT 1.0.674
Oracle 12c EE 12.2
Arquitectura
Pila de tecnología de origen
Base de datos de Oracle en las instalaciones
Pila de tecnología de destino
PostgreSQL de Amazon Aurora
Amazon RDS para PostgreSQL
Arquitectura de destino
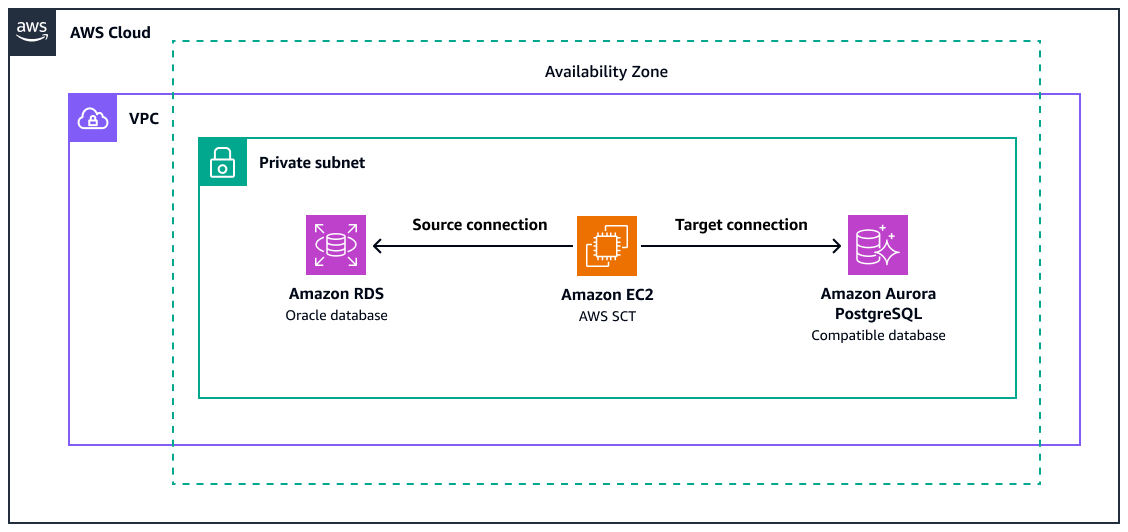
En el diagrama se muestra lo siguiente:
Una instancia de base de datos Amazon RDS for Oracle de origen
Una EC2 instancia de Amazon AWS SCT para convertir las funciones de Oracle al equivalente de PostgreSQL
Una base de datos de destino compatible con Amazon Aurora PostgreSQL
Herramientas
Servicios de AWS
Amazon Aurora es un motor de base de datos relacional completamente administrado diseñado para la nube y compatible con MySQL y PostgreSQL.
La edición de Amazon Aurora compatible con PostgreSQL es un motor de base de datos relacional compatible con ACID, completamente administrado que le permite configurar, utilizar y escalar implementaciones de PostgreSQL.
Amazon Elastic Compute Cloud (Amazon EC2) proporciona una capacidad informática escalable en el Nube de AWS. Puede lanzar tantos servidores virtuales como necesite y escalarlos o reducirlos con rapidez.
Amazon Relational Database Service (Amazon RDS) le ayuda a configurar, operar y escalar una base de datos relacional en. Nube de AWS
Amazon Relational Database Service (Amazon RDS) para Oracle le ayuda a configurar, operar y escalar una base de datos relacional de Oracle en el. Nube de AWS
Amazon Relational Database Service (Amazon RDS) para PostgreSQL le ayuda a configurar, operar y escalar una base de datos relacional de PostgreSQL en. Nube de AWS
AWS Schema Conversion Tool (AWS SCT) admite migraciones de bases de datos heterogéneas al convertir automáticamente el esquema de la base de datos de origen y la mayoría del código personalizado a un formato compatible con la base de datos de destino.
Otras herramientas
Oracle SQL Developer
es un entorno de desarrollo integrado que simplifica el desarrollo y la administración de bases de datos de Oracle, tanto en implementaciones tradicionales como en implementaciones basadas en la nube. pgAdmin
es una herramienta de administración de código abierto para PostgreSQL. Proporciona una interfaz gráfica que permite crear, mantener y utilizar objetos de bases de datos. En este patrón, pgAdmin se conecta a la instancia de base de datos de RDS para PostgreSQL y consulta los datos. Como alternativa, puede utilizar el cliente de línea de comandos psql.
Prácticas recomendadas
Pruebe los límites de los conjuntos de datos y los escenarios periféricos.
Considere la posibilidad de implementar el manejo de errores para las condiciones out-of-bounds del índice.
Optimice las consultas para evitar escanear conjuntos de datos dispersos.
Epics
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Cree un PL/SQL bloque de origen en Oracle. | Cree un PL/SQL bloque de origen en Oracle que utilice la siguiente matriz asociativa:
| Administrador de base de datos |
Ejecute el PL/SQL bloque. | Ejecute el PL/SQL bloque fuente en Oracle. Si hay huecos entre los valores de índice de una matriz asociativa, no se almacena ningún dato en esos huecos. Esto permite que el bucle de Oracle itere únicamente a través de las posiciones del índice. | Administrador de base de datos |
Revise la salida. | Se insertaron cinco elementos en la matriz (
| Administrador de base de datos |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Cree un PL/pgSQL bloque de destino en PostgreSQL. | Cree un PL/pgSQL bloque de destino en PostgreSQL que utilice la siguiente matriz asociativa:
| Administrador de base de datos |
Ejecute el bloque. PL/pgSQL | Ejecute el PL/pgSQL bloque de destino en PostgreSQL. Si hay huecos entre los valores de índice de una matriz asociativa, no se almacena ningún dato en esos huecos. Esto permite que el bucle de Oracle itere únicamente a través de las posiciones del índice. | Administrador de base de datos |
Revise la salida. | La longitud de la matriz es superior a 5 porque
| Administrador de base de datos |
| Tarea | Descripción | Habilidades requeridas |
|---|---|---|
Cree un PL/pgSQL bloque de destino con una matriz y un tipo definido por el usuario. | Para optimizar el rendimiento y adaptarlo a la funcionalidad de Oracle, podemos crear un tipo definido por el usuario que almacene tanto las posiciones del índice como sus datos correspondientes. Este enfoque reduce las iteraciones innecesarias al mantener las asociaciones directas entre índices y valores.
| Administrador de base de datos |
Ejecuta el PL/pgSQL bloque. | Ejecuta el PL/pgSQL bloque objetivo. Si hay huecos entre los valores de índice de una matriz asociativa, no se almacena ningún dato en esos huecos. Esto permite que el bucle de Oracle itere únicamente a través de las posiciones del índice. | Administrador de base de datos |
Revise la salida. | Como se muestra en el siguiente resultado, el tipo definido por el usuario almacena solo los elementos de datos rellenados, lo que significa que la longitud de la matriz coincide con el número de valores. Como resultado,
| Administrador de base de datos |
Recursos relacionados
AWS documentación
Otra documentación
