Autenticación con el conector de Spark
En el siguiente diagrama se describe la autenticación entre Amazon S3, Amazon Redshift, el controlador de Spark y los ejecutores de Spark.
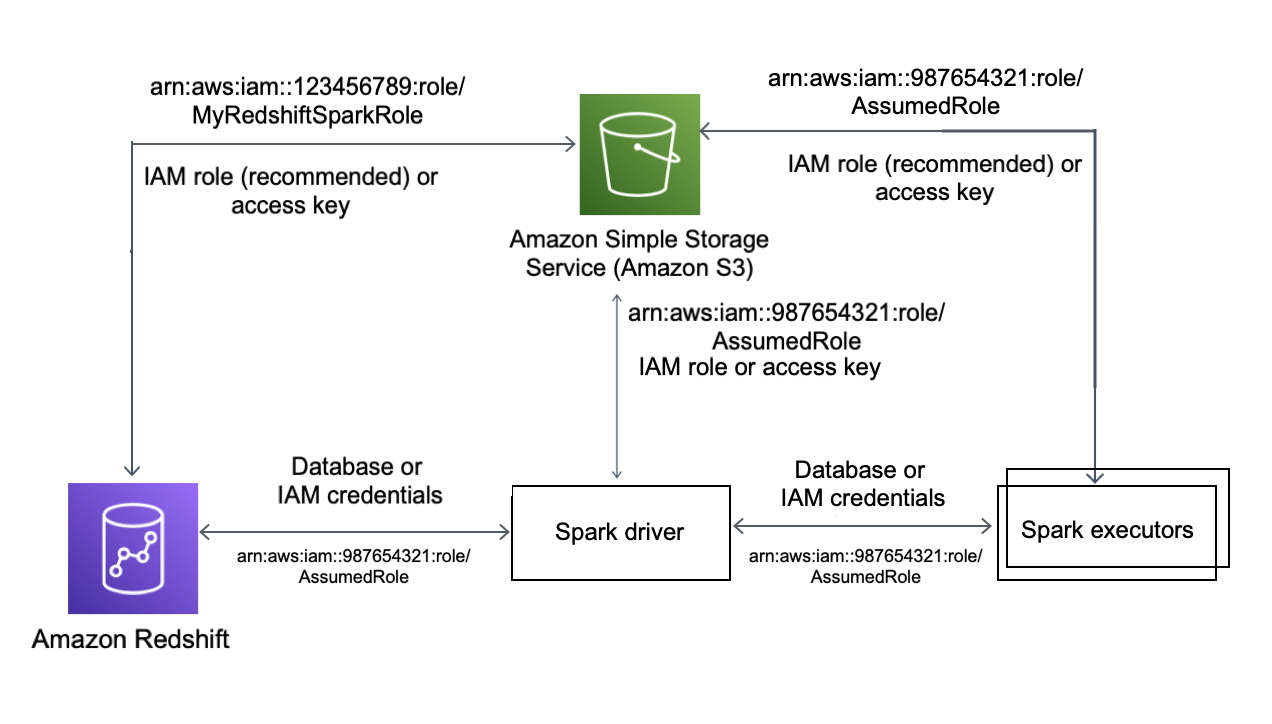
Autenticación entre Redshift y Spark
Puede utilizar el controlador JDBC versión 2 proporcionado por Amazon Redshift para conectarse a Amazon Redshift con el conector de Spark mediante la especificación de credenciales de inicio de sesión. Para utilizar IAM, configure su URL de JDBC para que utilice la autenticación de IAM. Para conectarse a un clúster de Redshift desde Amazon EMR o AWS Glue, asegúrese de que su rol de IAM tiene los permisos necesarios para recuperar credenciales de IAM temporales. En la siguiente lista se describen todos los permisos que su rol de IAM necesita para recuperar credenciales y ejecutar operaciones de Amazon S3.
-
Redshift:GetClusterCredentials (para clústeres de Redshift aprovisionados)
-
Redshift:DescribeClusters (para clústeres de Redshift aprovisionados)
-
Redshift:GetWorkgroup (para grupos de trabajo de Amazon Redshift sin servidor)
-
Redshift:GetCredentials (para grupos de trabajo de Amazon Redshift sin servidor)
Para obtener más información sobre GetClusterCredentials, consulte Políticas de recursos para GetClusterCredentials.
También debe asegurarse de que Amazon Redshift puede asumir el rol de IAM durante las operaciones COPY y UNLOAD.
Si utiliza el controlador JDBC más reciente, este administrará automáticamente la transición de un certificado autofirmado de Amazon Redshift a un certificado de ACM. No obstante, deberá especificar las opciones de SSL para la URL de JDBC.
A continuación, se muestra un ejemplo de cómo especificar la URL del controlador JDBC y aws_iam_role para conectarse a Amazon Redshift.
df.write \ .format("io.github.spark_redshift_community.spark.redshift ") \ .option("url", "jdbc:redshift:iam://<the-rest-of-the-connection-string>") \ .option("dbtable", "<your-table-name>") \ .option("tempdir", "s3a://<your-bucket>/<your-directory-path>") \ .option("aws_iam_role", "<your-aws-role-arn>") \ .mode("error") \ .save()
Autenticación entre Amazon S3 y Spark
Si utiliza un rol de IAM para la autenticación entre Spark y Amazon S3, utilice uno de los siguientes métodos:
-
El SDK de AWS para Java intentará encontrar automáticamente las credenciales de AWS mediante la cadena de proveedores de credenciales predeterminada implementada por la clase DefaultAWSCredentialsProviderChain. Para obtener más información, consulte Using the Default Credential Provider Chain (Uso de la cadena de proveedores de credenciales predeterminada).
-
Puede especificar claves de AWS a través de las propiedades de configuración de Hadoop
. Por ejemplo, si su configuración de tempdirapunta a un sistema de archivoss3n://, establezca las propiedadesfs.s3n.awsAccessKeyIdyfs.s3n.awsSecretAccessKeyen un archivo de configuración XML de Hadoop o llame asc.hadoopConfiguration.set()para cambiar la configuración de Hadoop global de Spark.
Por ejemplo, si utiliza el sistema de archivos s3n, agregue:
sc.hadoopConfiguration.set("fs.s3n.awsAccessKeyId", "YOUR_KEY_ID") sc.hadoopConfiguration.set("fs.s3n.awsSecretAccessKey", "YOUR_SECRET_ACCESS_KEY")
Para el sistema de archivos s3a, agregue:
sc.hadoopConfiguration.set("fs.s3a.access.key", "YOUR_KEY_ID") sc.hadoopConfiguration.set("fs.s3a.secret.key", "YOUR_SECRET_ACCESS_KEY")
Si utiliza Python, utilice las siguientes operaciones:
sc._jsc.hadoopConfiguration().set("fs.s3n.awsAccessKeyId", "YOUR_KEY_ID") sc._jsc.hadoopConfiguration().set("fs.s3n.awsSecretAccessKey", "YOUR_SECRET_ACCESS_KEY")
-
Codifique las claves de autenticación en la URL
tempdir. Por ejemplo, el URIs3n://ACCESSKEY:SECRETKEY@bucket/path/to/temp/dircodifica el par de claves (ACCESSKEY,SECRETKEY).
Autenticación entre Redshift y Amazon S3
Si utiliza los comandos COPY y UNLOAD en la consulta, también deberá conceder acceso a Amazon S3 a Amazon Redshift para que ejecute las consultas en su nombre. Para ello, autorice primero a Amazon Redshift a acceder a otros servicios de AWS y, a continuación, autorice las operaciones COPY y UNLOAD mediante roles de IAM.
Como práctica recomendada, aconsejamos asociar las políticas de permisos a un rol de IAM y luego asignarlo a los usuarios y grupos según sea necesario. Para obtener más información, consulte Administración de identidades y accesos en Amazon Redshift.
Cómo integrar con AWS Secrets Manager
Puede recuperar las credenciales de nombre de usuario y contraseña de Redshift de un secreto almacenado en AWS Secrets Manager. Para proporcionar automáticamente las credenciales de Redshift, utilice el parámetro secret.id. Para obtener más información sobre cómo crear un secreto de credenciales de Redshift, consulte Crear un secreto de base de datos de AWS Secrets Manager.
| GroupID | ArtifactID | Revisiones compatibles | Descripción |
|---|---|---|---|
| com.amazonaws.secretsmanager | aws-secretsmanager-jdbc | 1.0.12 | La biblioteca de conexiones SQL de AWS Secrets Manager para Java permite a los desarrolladores de Java conectarse fácilmente a las bases de datos SQL con los secretos almacenados en AWS Secrets Manager. |
nota
Reconocimiento: esta documentación contiene código y lenguaje de muestra desarrollados por la Apache Software Foundation
