Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Definición de una canalización
Para organizar sus flujos de trabajo con Amazon SageMaker Pipelines, debe generar un gráfico acíclico dirigido (DAG) en forma de definición de canalización en JSON. El DAG especifica los pasos diferentes del proceso de ML, como el preprocesamiento de datos, el entrenamiento del modelo, la evaluación del modelo y la implementación del modelo, así como las dependencias y el flujo de datos entre estos pasos. En el siguiente tema, se muestra cómo generar una definición de canalización.
Puede generar su definición de canalización de JSON mediante el SDK de SageMaker Python o la función visual drag-and-drop Pipeline Designer de Amazon SageMaker Studio. La siguiente imagen es una representación del DAG de la canalización que ha creado en este tutorial:
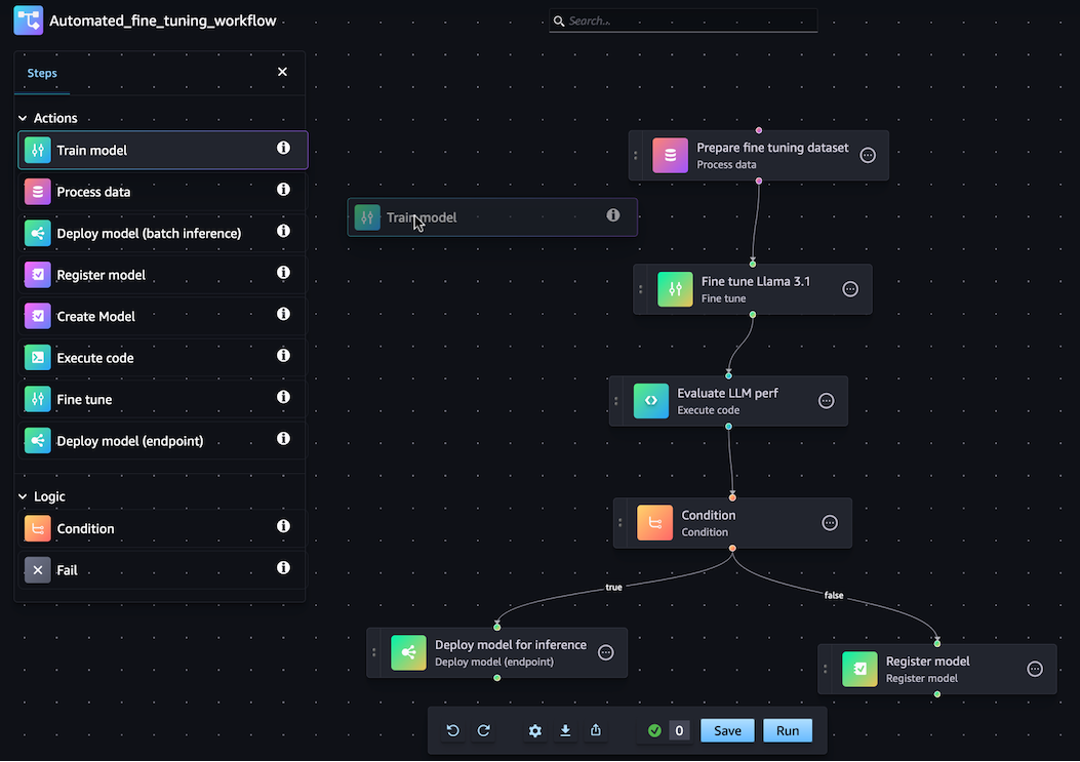
La canalización que se define en las secciones siguientes resuelve un problema de regresión para determinar la edad de un abulón en función de sus medidas físicas. Para ver un cuaderno de Jupyter ejecutable que incluya el contenido de este tutorial, consulte Cómo organizar tareas con Amazon SageMaker Model Building
Temas
El siguiente tutorial te guía por los pasos para crear una canalización básica con el Diseñador de drag-and-drop canalizaciones. Si necesita pausar o finalizar su sesión de edición de la canalización en el diseñador visual en cualquier momento, haga clic en la opción Exportar. Esto le permite descargar la definición actual de su canalización a su entorno local. Más tarde, cuando quiera reanudar el proceso de edición de la canalización, puede importar el mismo archivo de definición de JSON al diseñador visual.
Creación de un paso de procesamiento
Para crear un paso de trabajo de procesamiento de datos, haga lo siguiente:
-
Abra la consola de Studio siguiendo las instrucciones de Lanza Amazon SageMaker Studio.
-
En el panel de navegación izquierdo, seleccione Canalizaciones.
-
Seleccione Crear.
-
Seleccione En blanco.
-
En la barra lateral izquierda, elija Procesar datos y arrástrelos al lienzo.
-
En el lienzo, elija el paso Procesar datos que ha añadido.
-
Para añadir un conjunto de datos de entrada, seleccione Agregar en Datos (entrada) en la barra lateral derecha y seleccione un conjunto de datos.
-
Para añadir una ubicación para guardar los conjuntos de datos de salida, seleccione Agregar en Datos (salida) en la barra lateral derecha y vaya hasta el destino.
-
Complete el resto de los campos en la barra lateral derecha. Para obtener información sobre los campos de estas pestañas, consulte sagemaker.workflow.steps. ProcessingStep
.
Creación de un paso de entrenamiento
Para configurar un paso de entrenamiento del modelo, haga lo siguiente:
-
En la barra lateral izquierda, seleccione Entrenar modelo y arrástrelo al lienzo.
-
En el lienzo, elija el paso Entrenar modelo que ha añadido.
-
Para añadir un conjunto de datos de entrada, seleccione Agregar en Datos (entrada) en la barra lateral derecha y seleccione un conjunto de datos.
-
Para elegir una ubicación para guardar los artefactos del modelo, introduzca un URI de Amazon S3 en el campo Ubicación (URI de S3) o elija Examinar S3 para ir a la ubicación de destino.
-
Complete el resto de los campos en la barra lateral derecha. Para obtener información sobre los campos de estas pestañas, consulte sagemaker.workflow.steps. TrainingStep
. -
Haga clic y arrastre el cursor desde el paso Procesar datos que añadió en la sección anterior hasta el paso Entrenar modelo para crear un borde que conecte los dos pasos.
Creación de un paquete de modelos con un paso Registrar modelo
Para crear un paquete de modelos con un paso de registro de modelo, haga lo siguiente:
-
En la barra lateral izquierda, seleccione Registrar modelo y arrástrelo al lienzo.
-
En el lienzo, elija el paso Registrar modelo que ha añadido.
-
Para seleccionar un modelo al que anular el registro, elija Agregar en Modelo (entrada).
-
Seleccione Crear un grupo de modelos para añadir el modelo a un nuevo grupo de modelos.
-
Complete el resto de los campos en la barra lateral derecha. Para obtener información sobre los campos de estas pestañas, consulte sagemaker.workflow.step_collections. RegisterModel
. -
Haga clic y arrastre el cursor desde el paso Entrenar modelo que añadió en la sección anterior al paso Registrar modelo para crear un borde que conecte los dos pasos.
Implementación del modelo en un punto de conexión con un paso Implementar modelo (punto de conexión)
Para implementar el modelo mediante un paso de implementación del modelo, haga lo siguiente:
-
En la barra lateral izquierda, seleccione Implementar modelo (punto de conexión) y arrástrelo al lienzo.
-
En el lienzo, elija el paso Implementar modelo (punto de conexión) que ha añadido.
-
Para elegir un modelo para implementar, elija Agregar en Modelo (entrada).
-
Pulse el botón de opción Crear punto de conexión para crear un nuevo punto de conexión.
-
Escriba un Nombre y Descripción para el punto de conexión.
-
Haga clic y arrastre el cursor desde el paso Registrar modelo que añadió en la sección anterior al paso Implementar modelo (punto de conexión) para crear un borde que conecte los dos pasos.
-
Complete el resto de los campos en la barra lateral derecha.
Definición de los parámetros de canalizaciones
Puede configurar un conjunto de parámetros de canalizaciones cuyos valores se pueden actualizar para cada ejecución. Para definir los parámetros de canalizaciones y establecer los valores predeterminados, haga clic en el icono de engranaje situado en la parte inferior del diseñador visual.
Guardado de la canalización
Una vez que haya introducido toda la información necesaria para crear su canalización, haga clic en Guardar en la parte inferior del diseñador visual. Esto valida su canalización para detectar posibles errores en tiempo de ejecución y se lo notifica. La operación Guardar no se realizará correctamente hasta que solucione todos los errores señalados por las comprobaciones de validación automatizadas. Si quiere reanudar la edición más adelante, puede guardar la canalización en curso como una definición JSON en su entorno local. Puede exportar su canalización como un archivo de definición JSON haciendo clic en el botón Exportar situado en la parte inferior del diseñador visual. Más adelante, para reanudar la actualización de su canalización, cargue ese archivo de definición JSON haciendo clic en el botón Importar.
Requisitos previos
Para ejecutar el siguiente tutorial, haga lo siguiente:
-
Configure la instancia del cuaderno tal y como se describe en Create a notebook instance. Esto le da a su rol permisos para leer y escribir en Amazon S3 y crear trabajos de formación, transformación por lotes y procesamiento en SageMaker IA.
-
Conceda permisos a su cuaderno para obtener y transferir su propio rol, tal y como se muestra en Modificación de una política de permisos de rol. Agregue el siguiente fragmento de JSON para asociar esta política a su rol. Sustituya
<your-role-arn>por el ARN utilizado para crear la instancia del cuaderno. -
Confíe en el director del servicio de SageMaker IA siguiendo los pasos que se indican en Modificación de la política de confianza de un rol. Agregue el siguiente fragmento de declaración a la relación de confianza de su rol:
{ "Sid": "", "Effect": "Allow", "Principal": { "Service": "sagemaker.amazonaws.com" }, "Action": "sts:AssumeRole" }
Configure su entorno
Cree una nueva sesión de SageMaker IA mediante el siguiente bloque de código. Esto devuelve el ARN del rol de la sesión. El ARN de este rol debe ser el ARN del rol de ejecución que haya configurado como requisito previo.
import boto3 import sagemaker import sagemaker.session from sagemaker.workflow.pipeline_context import PipelineSession region = boto3.Session().region_name sagemaker_session = sagemaker.session.Session() role = sagemaker.get_execution_role() default_bucket = sagemaker_session.default_bucket() pipeline_session = PipelineSession() model_package_group_name = f"AbaloneModelPackageGroupName"
Creación de una canalización
importante
Las políticas de IAM personalizadas que permiten a Amazon SageMaker Studio o Amazon SageMaker Studio Classic crear SageMaker recursos de Amazon también deben conceder permisos para añadir etiquetas a esos recursos. El permiso para añadir etiquetas a los recursos es necesario porque Studio y Studio Classic etiquetan automáticamente todos los recursos que crean. Si una política de IAM permite a Studio y Studio Classic crear recursos, pero no permite el etiquetado, se pueden producir errores de tipo AccessDenied «» al intentar crear recursos. Para obtener más información, consulte Proporcione permisos para etiquetar los recursos de SageMaker IA.
AWS políticas gestionadas para Amazon SageMaker AIque otorgan permisos para crear SageMaker recursos ya incluyen permisos para añadir etiquetas al crear esos recursos.
Ejecuta los siguientes pasos desde tu instancia de bloc de notas de SageMaker IA para crear una canalización que incluya los siguientes pasos:
-
procesamiento previo
-
entrenamiento
-
evaluación
-
evaluación condicional
-
registro del modelo
nota
Puedes usar ExecutionVariablesExecutionVariablesse resuelve en tiempo de ejecución. Por ejemplo, ExecutionVariables.PIPELINE_EXECUTION_ID se resuelve con el ID de la ejecución actual, que se puede utilizar como identificador único en diferentes ejecuciones.
Paso 1: descarga del conjunto de datos
Este cuaderno utiliza el conjunto de datos de abulón de UCI Machine Learning. El conjunto de datos contiene las siguientes características:
-
length: la medida más larga de la concha del abulón. -
diameter: el diámetro del abulón perpendicular a su longitud. -
height: La talla del abulón con carne en la concha. -
whole_weight: el peso de todo el abulón. -
shucked_weight: el peso de la carne extraída del abulón. -
viscera_weight: el peso de las vísceras del abulón tras el sangrado. -
shell_weight: el peso de la concha de abulón tras retirar la carne y secarla. -
sex: el sexo del abulón. Puede ser “M”, “F” o “I”, don “I” es un abulón cría. -
rings: el número de anillos de la concha del abulón.
El número de anillos de la concha del abulón es una buena indicación de su edad según la fórmula age=rings + 1.5. Sin embargo, la obtención de este número es una tarea que lleva mucho tiempo. Debe cortar la concha a través del cono, teñir la sección y contar el número de anillos con un microscopio. Las demás medidas físicas son más fáciles de determinar. Este cuaderno utiliza el conjunto de datos para crear un modelo predictivo de los anillos variables a partir de las demás medidas físicas.
Para descargar los conjuntos de datos
-
Descargue el conjunto de datos en el bucket de Amazon S3 predeterminado de su cuenta.
!mkdir -p data local_path = "data/abalone-dataset.csv" s3 = boto3.resource("s3") s3.Bucket(f"sagemaker-servicecatalog-seedcode-{region}").download_file( "dataset/abalone-dataset.csv", local_path ) base_uri = f"s3://{default_bucket}/abalone" input_data_uri = sagemaker.s3.S3Uploader.upload( local_path=local_path, desired_s3_uri=base_uri, ) print(input_data_uri) -
Descargue un segundo conjunto de datos para la transformación por lotes una vez creado el modelo.
local_path = "data/abalone-dataset-batch.csv" s3 = boto3.resource("s3") s3.Bucket(f"sagemaker-servicecatalog-seedcode-{region}").download_file( "dataset/abalone-dataset-batch", local_path ) base_uri = f"s3://{default_bucket}/abalone" batch_data_uri = sagemaker.s3.S3Uploader.upload( local_path=local_path, desired_s3_uri=base_uri, ) print(batch_data_uri)
Paso 2: definición de los parámetros de la canalización
Este bloque de código define los siguientes parámetros para la canalización:
-
processing_instance_count: el recuento de instancias del trabajo de procesamiento. -
input_data: la ubicación de los datos de entrada en Amazon S3. -
batch_data: la ubicación de los datos de entrada en Amazon S3 para la transformación por lotes. -
model_approval_status: el estado de aprobación para registrar el modelo entrenado para la CI/CD. Para obtener más información, consulte MLOps Automatización con SageMaker proyectos.
from sagemaker.workflow.parameters import ( ParameterInteger, ParameterString, ) processing_instance_count = ParameterInteger( name="ProcessingInstanceCount", default_value=1 ) model_approval_status = ParameterString( name="ModelApprovalStatus", default_value="PendingManualApproval" ) input_data = ParameterString( name="InputData", default_value=input_data_uri, ) batch_data = ParameterString( name="BatchData", default_value=batch_data_uri, )
Paso 3: definición de un paso de procesamiento para la ingeniería de características
En esta sección se muestra cómo crear un paso de procesamiento para preparar los datos del conjunto de datos para el entrenamiento.
Para crear un paso de procesamiento
-
Cree un directorio para el script de procesamiento.
!mkdir -p abalone -
En el directorio
/abalone, cree un archivo denominadopreprocessing.pycon el contenido siguiente. Este script de procesamiento previo se transfiere al paso de procesamiento para ejecutarse en los datos de entrada. A continuación, el paso de entrenamiento usa las características y etiquetas de entrenamiento preprocesadas para entrenar un modelo. En el paso de evaluación, se usa el modelo entrenado y las características y etiquetas de prueba preprocesadas para evaluar el modelo. El script usascikit-learnpara hacer lo siguiente:-
Rellenar los datos categóricos
sexausentes y codificarlos para que sean adecuados para el entrenamiento. -
Escalar y normalizar todos los campos numéricos excepto
ringsysex. -
Dividir los datos en conjuntos de entrenamiento, validación y prueba.
%%writefile abalone/preprocessing.py import argparse import os import requests import tempfile import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.impute import SimpleImputer from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler, OneHotEncoder # Because this is a headerless CSV file, specify the column names here. feature_columns_names = [ "sex", "length", "diameter", "height", "whole_weight", "shucked_weight", "viscera_weight", "shell_weight", ] label_column = "rings" feature_columns_dtype = { "sex": str, "length": np.float64, "diameter": np.float64, "height": np.float64, "whole_weight": np.float64, "shucked_weight": np.float64, "viscera_weight": np.float64, "shell_weight": np.float64 } label_column_dtype = {"rings": np.float64} def merge_two_dicts(x, y): z = x.copy() z.update(y) return z if __name__ == "__main__": base_dir = "/opt/ml/processing" df = pd.read_csv( f"{base_dir}/input/abalone-dataset.csv", header=None, names=feature_columns_names + [label_column], dtype=merge_two_dicts(feature_columns_dtype, label_column_dtype) ) numeric_features = list(feature_columns_names) numeric_features.remove("sex") numeric_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler()) ] ) categorical_features = ["sex"] categorical_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="constant", fill_value="missing")), ("onehot", OneHotEncoder(handle_unknown="ignore")) ] ) preprocess = ColumnTransformer( transformers=[ ("num", numeric_transformer, numeric_features), ("cat", categorical_transformer, categorical_features) ] ) y = df.pop("rings") X_pre = preprocess.fit_transform(df) y_pre = y.to_numpy().reshape(len(y), 1) X = np.concatenate((y_pre, X_pre), axis=1) np.random.shuffle(X) train, validation, test = np.split(X, [int(.7*len(X)), int(.85*len(X))]) pd.DataFrame(train).to_csv(f"{base_dir}/train/train.csv", header=False, index=False) pd.DataFrame(validation).to_csv(f"{base_dir}/validation/validation.csv", header=False, index=False) pd.DataFrame(test).to_csv(f"{base_dir}/test/test.csv", header=False, index=False) -
-
Cree una instancia de un
SKLearnProcessorpara transferirla al paso de procesamiento.from sagemaker.sklearn.processing import SKLearnProcessor framework_version = "0.23-1" sklearn_processor = SKLearnProcessor( framework_version=framework_version, instance_type="ml.m5.xlarge", instance_count=processing_instance_count, base_job_name="sklearn-abalone-process", sagemaker_session=pipeline_session, role=role, ) -
Cree un paso de procesamiento. Este paso incluye
SKLearnProcessor, los canales de entrada y salida y el scriptpreprocessing.pyque ha creado. Es muy similar alrunmétodo de una instancia de procesador en el SDK de Python para SageMaker IA. El parámetroinput_dataque se pasa aProcessingStepson los datos de entrada del propio paso. La instancia del procesador utiliza estos datos de entrada cuando se ejecuta.Observe los canales denominados
"train,"validationy"test"especificados en la configuración de salida para el trabajo de procesamiento. LasPropertiesdel paso como estas pueden utilizarse en pasos posteriores y se resuelven a sus valores de tiempo de ejecución en el tiempo de ejecución.from sagemaker.processing import ProcessingInput, ProcessingOutput from sagemaker.workflow.steps import ProcessingStep processor_args = sklearn_processor.run( inputs=[ ProcessingInput(source=input_data, destination="/opt/ml/processing/input"), ], outputs=[ ProcessingOutput(output_name="train", source="/opt/ml/processing/train"), ProcessingOutput(output_name="validation", source="/opt/ml/processing/validation"), ProcessingOutput(output_name="test", source="/opt/ml/processing/test") ], code="abalone/preprocessing.py", ) step_process = ProcessingStep( name="AbaloneProcess", step_args=processor_args )
Paso 4: definición de un paso de entrenamiento
En esta sección se muestra cómo usar el XGBoostalgoritmo de SageMaker IA para entrenar un modelo a partir de los datos de entrenamiento generados por los pasos de procesamiento.
Para definir un paso de entrenamiento
-
Especifique la ruta del modelo en la que desea guardar los modelos del entrenamiento.
model_path = f"s3://{default_bucket}/AbaloneTrain" -
Configura un estimador para el XGBoost algoritmo y el conjunto de datos de entrada. El tipo de instancia de entrenamiento se transfiere al estimador. Script de entrenamiento típico:
-
carga datos de los canales de entrada
-
configura el entrenamiento con hiperparámetros
-
entrena un modelo
-
guarda un modelo en
model_dirpoder alojarlo más adelante
SageMaker La IA carga el modelo a Amazon S3 en forma de a
model.tar.gzal final del trabajo de formación.from sagemaker.estimator import Estimator image_uri = sagemaker.image_uris.retrieve( framework="xgboost", region=region, version="1.0-1", py_version="py3", instance_type="ml.m5.xlarge" ) xgb_train = Estimator( image_uri=image_uri, instance_type="ml.m5.xlarge", instance_count=1, output_path=model_path, sagemaker_session=pipeline_session, role=role, ) xgb_train.set_hyperparameters( objective="reg:linear", num_round=50, max_depth=5, eta=0.2, gamma=4, min_child_weight=6, subsample=0.7, silent=0 ) -
-
Cree un
TrainingStepmediante la instancia del estimador y las propiedades delProcessingStep. Pase elS3Uride los canales de salida"train"y"validation"alTrainingStep.from sagemaker.inputs import TrainingInput from sagemaker.workflow.steps import TrainingStep train_args = xgb_train.fit( inputs={ "train": TrainingInput( s3_data=step_process.properties.ProcessingOutputConfig.Outputs[ "train" ].S3Output.S3Uri, content_type="text/csv" ), "validation": TrainingInput( s3_data=step_process.properties.ProcessingOutputConfig.Outputs[ "validation" ].S3Output.S3Uri, content_type="text/csv" ) }, ) step_train = TrainingStep( name="AbaloneTrain", step_args = train_args )
Paso 5: definición de un paso de procesamiento para la evaluación del modelo
En esta sección se muestra cómo crear un paso de procesamiento para evaluar la precisión del modelo. El resultado de esta evaluación del modelo se utiliza en el paso de condición para determinar qué ruta de ejecución se debe seguir.
Para definir un paso de procesamiento para la evaluación del modelo
-
En el directorio
/abalonecree un archivo denominadoevaluation.py. Este script se utiliza en un paso de procesamiento para realizar la evaluación del modelo. Toma un modelo entrenado y el conjunto de datos de prueba como entrada y, a continuación, produce un archivo JSON que contiene las métricas de evaluación de la clasificación.%%writefile abalone/evaluation.py import json import pathlib import pickle import tarfile import joblib import numpy as np import pandas as pd import xgboost from sklearn.metrics import mean_squared_error if __name__ == "__main__": model_path = f"/opt/ml/processing/model/model.tar.gz" with tarfile.open(model_path) as tar: tar.extractall(path=".") model = pickle.load(open("xgboost-model", "rb")) test_path = "/opt/ml/processing/test/test.csv" df = pd.read_csv(test_path, header=None) y_test = df.iloc[:, 0].to_numpy() df.drop(df.columns[0], axis=1, inplace=True) X_test = xgboost.DMatrix(df.values) predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions) std = np.std(y_test - predictions) report_dict = { "regression_metrics": { "mse": { "value": mse, "standard_deviation": std }, }, } output_dir = "/opt/ml/processing/evaluation" pathlib.Path(output_dir).mkdir(parents=True, exist_ok=True) evaluation_path = f"{output_dir}/evaluation.json" with open(evaluation_path, "w") as f: f.write(json.dumps(report_dict)) -
Cree una instancia de un
ScriptProcessorque se utilice para crear unProcessingStep.from sagemaker.processing import ScriptProcessor script_eval = ScriptProcessor( image_uri=image_uri, command=["python3"], instance_type="ml.m5.xlarge", instance_count=1, base_job_name="script-abalone-eval", sagemaker_session=pipeline_session, role=role, ) -
Cree un
ProcessingSteputilizando la instancia del procesador, los canales de entrada y salida y el scriptevaluation.py. Pase lo siguiente:-
la propiedad
S3ModelArtifactsdesde el paso de entrenamientostep_train -
el
S3Uridel canal de salida"test"del paso de procesamientostep_process
Es muy similar al
runmétodo de una instancia de procesador en el SDK de Python para SageMaker IA.from sagemaker.workflow.properties import PropertyFile evaluation_report = PropertyFile( name="EvaluationReport", output_name="evaluation", path="evaluation.json" ) eval_args = script_eval.run( inputs=[ ProcessingInput( source=step_train.properties.ModelArtifacts.S3ModelArtifacts, destination="/opt/ml/processing/model" ), ProcessingInput( source=step_process.properties.ProcessingOutputConfig.Outputs[ "test" ].S3Output.S3Uri, destination="/opt/ml/processing/test" ) ], outputs=[ ProcessingOutput(output_name="evaluation", source="/opt/ml/processing/evaluation"), ], code="abalone/evaluation.py", ) step_eval = ProcessingStep( name="AbaloneEval", step_args=eval_args, property_files=[evaluation_report], ) -
Paso 6: Defina una transformación CreateModelStep por lotes
importante
Recomendamos usarlo Paso de modelo para crear modelos a partir de la versión 2.90.0 del SDK de Python SageMaker . CreateModelStepseguirá funcionando en las versiones anteriores del SDK de SageMaker Python, pero ya no es compatible activamente.
En esta sección se muestra cómo crear un modelo de SageMaker IA a partir del resultado del paso de entrenamiento. Este modelo se utiliza para la transformación por lotes en un nuevo conjunto de datos. Este paso se transfiere al paso de condición y solo se ejecuta si el paso de condición se evalúa como true.
Para definir una transformación CreateModelStep por lotes
-
Cree un modelo de SageMaker IA. Transfiera la propiedad
S3ModelArtifactsdesde el paso de entrenamientostep_train.from sagemaker.model import Model model = Model( image_uri=image_uri, model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts, sagemaker_session=pipeline_session, role=role, ) -
Defina la entrada del modelo para su modelo de SageMaker IA.
from sagemaker.inputs import CreateModelInput inputs = CreateModelInput( instance_type="ml.m5.large", accelerator_type="ml.eia1.medium", ) -
Cree la suya
CreateModelStepcon laCreateModelInputinstancia del modelo de SageMaker IA que definió.from sagemaker.workflow.steps import CreateModelStep step_create_model = CreateModelStep( name="AbaloneCreateModel", model=model, inputs=inputs, )
Paso 7: Defina una transformación por lotes TransformStep para realizar
En esta sección se muestra cómo crear un TransformStep para realizar la transformación por lotes en un conjunto de datos después de entrenar el modelo. Este paso se transfiere al paso de condición y solo se ejecuta si el paso de condición se evalúa como true.
Para definir una transformación por lotes TransformStep para realizar
-
Cree una instancia de transformador con el tipo de instancia de cómputo, el recuento de instancias y el URI de bucket de Amazon S3 de salida adecuados. Transfiera la propiedad
ModelNamedesde el pasoCreateModeldestep_create_model.from sagemaker.transformer import Transformer transformer = Transformer( model_name=step_create_model.properties.ModelName, instance_type="ml.m5.xlarge", instance_count=1, output_path=f"s3://{default_bucket}/AbaloneTransform" ) -
Cree un
TransformStepcon la instancia de transformador que definió y el parámetro de canalizaciónbatch_data.from sagemaker.inputs import TransformInput from sagemaker.workflow.steps import TransformStep step_transform = TransformStep( name="AbaloneTransform", transformer=transformer, inputs=TransformInput(data=batch_data) )
Paso 8: Defina un RegisterModel paso para crear un paquete modelo
importante
Recomendamos usarlo Paso de modelo para registrar modelos a partir de la versión 2.90.0 del SDK de Python SageMaker . RegisterModelseguirá funcionando en las versiones anteriores del SDK de SageMaker Python, pero ya no es compatible activamente.
En esta sección, se muestra cómo crear una instancia de RegisterModel. El resultado de la ejecución de RegisterModel en una canalización es un paquete de modelos. Un paquete de modelos es una abstracción de artefactos de modelos reutilizable que empaqueta todos los ingredientes necesarios para la inferencia. Consiste en una especificación de inferencia que define la imagen de inferencia que se va a utilizar junto con una ubicación opcional de las ponderaciones del modelo. Un grupo de paquetes de modelos es una colección de paquetes de modelos. Puede utilizar un ModelPackageGroup para Canalizaciones para añadir una nueva versión y un paquete de modelos al grupo por cada ejecución de canalización. Para obtener más información acerca del registro de modelos, consulte Implementación del registro de modelos con el registro de modelos.
Este paso se transfiere al paso de condición y solo se ejecuta si el paso de condición se evalúa como true.
Para definir un RegisterModel paso para crear un paquete modelo
-
Construya un paso
RegisterModelcon la instancia del estimador que utilizó para el paso de entrenamiento. Transfiera la propiedadS3ModelArtifactsdesde el paso de entrenamientostep_trainy especifique unModelPackageGroup. Canalizaciones crea esteModelPackageGrouppor usted.from sagemaker.model_metrics import MetricsSource, ModelMetrics from sagemaker.workflow.step_collections import RegisterModel model_metrics = ModelMetrics( model_statistics=MetricsSource( s3_uri="{}/evaluation.json".format( step_eval.arguments["ProcessingOutputConfig"]["Outputs"][0]["S3Output"]["S3Uri"] ), content_type="application/json" ) ) step_register = RegisterModel( name="AbaloneRegisterModel", estimator=xgb_train, model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts, content_types=["text/csv"], response_types=["text/csv"], inference_instances=["ml.t2.medium", "ml.m5.xlarge"], transform_instances=["ml.m5.xlarge"], model_package_group_name=model_package_group_name, approval_status=model_approval_status, model_metrics=model_metrics )
Paso 9: definición de un paso de condición para verificar la exactitud del modelo
Un ConditionStep permite a Canalizaciones respaldar la ejecución condicional en su DAG de canalización en función del estado de las propiedades de los pasos. En este caso, solo le interesa registrar un paquete de modelos si la exactitud de ese modelo supera el valor requerido. La exactitud del modelo viene determinada por el paso de evaluación del modelo. Si la precisión supera el valor requerido, la canalización también crea un modelo de SageMaker IA y ejecuta la transformación por lotes en un conjunto de datos. En esta sección se muestra cómo definir el paso de condición.
Para definir un paso de condición para verificar la precisión del modelo
-
Defina una condición
ConditionLessThanOrEqualTocon el valor de precisión que se encuentra en al salida del paso de procesamiento de la evaluación del modelo,step_eval. Obtenga este resultado utilizando el archivo de propiedades que indexó en el paso de procesamiento y el valor JSONPath de error cuadrático medio, respectivamente."mse"from sagemaker.workflow.conditions import ConditionLessThanOrEqualTo from sagemaker.workflow.condition_step import ConditionStep from sagemaker.workflow.functions import JsonGet cond_lte = ConditionLessThanOrEqualTo( left=JsonGet( step_name=step_eval.name, property_file=evaluation_report, json_path="regression_metrics.mse.value" ), right=6.0 ) -
Construya un
ConditionStep. Pase la condiciónConditionEqualsy, a continuación, establezca los pasos de registro del paquete de modelos y transformación por lotes como los siguientes pasos si se cumple la condición.step_cond = ConditionStep( name="AbaloneMSECond", conditions=[cond_lte], if_steps=[step_register, step_create_model, step_transform], else_steps=[], )
Paso 10: Crear una canalización
Ahora que ha creado todos los pasos, debe combinarlos en una canalización.
Creación de una canalización
-
Defina lo siguiente para su canalización:
name,parametersysteps. Los nombres deben ser únicos en un par(account, region).nota
Un paso solo puede aparecer una vez en la lista de pasos de la canalización o en las listas de pasos if/else del paso de condición. No puede aparecer en ambas.
from sagemaker.workflow.pipeline import Pipeline pipeline_name = f"AbalonePipeline" pipeline = Pipeline( name=pipeline_name, parameters=[ processing_instance_count, model_approval_status, input_data, batch_data, ], steps=[step_process, step_train, step_eval, step_cond], ) -
De forma opcional, examine la definición de canalización de JSON para asegurarse de que esté bien formada.
import json json.loads(pipeline.definition())
Esta definición de canalización está lista para enviarse a SageMaker AI. En el siguiente tutorial, debes enviar esta canalización a SageMaker AI e iniciar una ejecución.
También puede usar boto3
{'Version': '2020-12-01', 'Metadata': {}, 'Parameters': [{'Name': 'ProcessingInstanceType', 'Type': 'String', 'DefaultValue': 'ml.m5.xlarge'}, {'Name': 'ProcessingInstanceCount', 'Type': 'Integer', 'DefaultValue': 1}, {'Name': 'TrainingInstanceType', 'Type': 'String', 'DefaultValue': 'ml.m5.xlarge'}, {'Name': 'ModelApprovalStatus', 'Type': 'String', 'DefaultValue': 'PendingManualApproval'}, {'Name': 'ProcessedData', 'Type': 'String', 'DefaultValue': 'S3_URL', {'Name': 'InputDataUrl', 'Type': 'String', 'DefaultValue': 'S3_URL', 'PipelineExperimentConfig': {'ExperimentName': {'Get': 'Execution.PipelineName'}, 'TrialName': {'Get': 'Execution.PipelineExecutionId'}}, 'Steps': [{'Name': 'ReadTrainDataFromFS', 'Type': 'Processing', 'Arguments': {'ProcessingResources': {'ClusterConfig': {'InstanceType': 'ml.m5.4xlarge', 'InstanceCount': 2, 'VolumeSizeInGB': 30}}, 'AppSpecification': {'ImageUri': 'IMAGE_URI', 'ContainerArguments': [....]}, 'RoleArn': 'ROLE', 'ProcessingInputs': [...], 'ProcessingOutputConfig': {'Outputs': [.....]}, 'StoppingCondition': {'MaxRuntimeInSeconds': 86400}}, 'CacheConfig': {'Enabled': True, 'ExpireAfter': '30d'}}, ... ... ... }
Siguiente paso: Ejecución de una canalización
