Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Preparación de un conjunto de datos
En este paso, cargue el conjunto de datos del censo de adultos
Para ejecutar el siguiente ejemplo, pegue el código de ejemplo en una celda de la instancia de su cuaderno.
Carga del conjunto de datos del censo de adultos mediante SHAP
Con la biblioteca SHAP, importe el conjunto de datos del censo de adultos como se muestra a continuación:
import shap X, y = shap.datasets.adult() X_display, y_display = shap.datasets.adult(display=True) feature_names = list(X.columns) feature_names
nota
Si el kernel de Jupyter actual no tiene la biblioteca SHAP, instálelo ejecutando el siguiente comando conda:
%conda install -c conda-forge shap
Si lo está utilizando JupyterLab, debe actualizar el núcleo manualmente una vez finalizada la instalación y las actualizaciones. Ejecute el siguiente IPython script para cerrar el núcleo (el núcleo se reiniciará automáticamente):
import IPython IPython.Application.instance().kernel.do_shutdown(True)
El objeto de lista feature_names debería devolver la siguiente lista de características:
['Age', 'Workclass', 'Education-Num', 'Marital Status', 'Occupation', 'Relationship', 'Race', 'Sex', 'Capital Gain', 'Capital Loss', 'Hours per week', 'Country']
sugerencia
Si estás empezando con datos sin etiquetar, puedes usar Amazon SageMaker Ground Truth para crear un flujo de trabajo de etiquetado de datos en cuestión de minutos. Para obtener más información, consulte Etiquetado de datos.
Información general del conjunto de datos
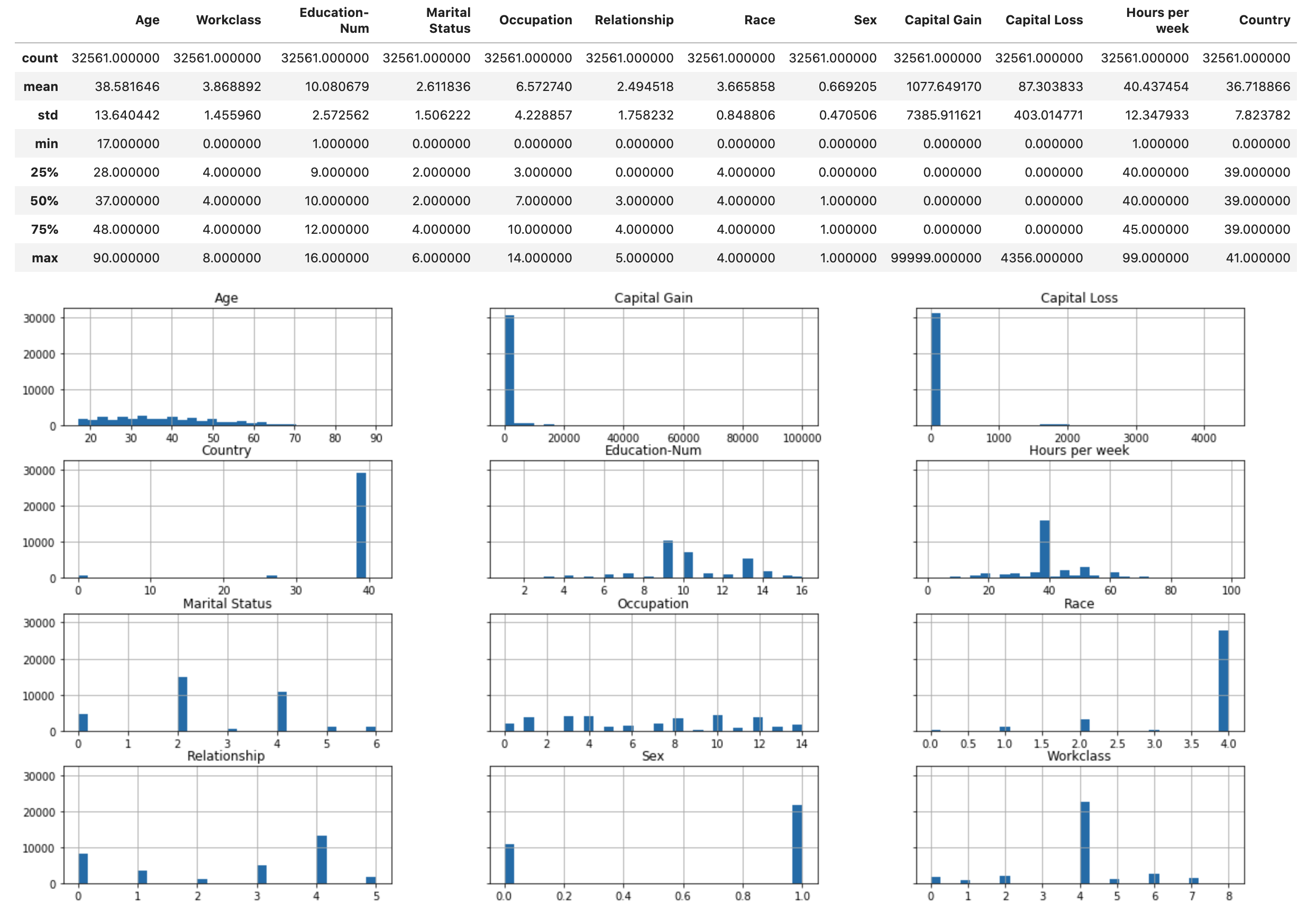
Ejecute el siguiente script para mostrar la descripción estadística del conjunto de datos y los histogramas de las características numéricas.
display(X.describe()) hist = X.hist(bins=30, sharey=True, figsize=(20, 10))
sugerencia
Si desea utilizar un conjunto de datos que deba limpiarse y transformarse, puede simplificar y agilizar el preprocesamiento de datos y la ingeniería de características con Amazon SageMaker Data Wrangler. Para obtener más información, consulte Preparar datos de aprendizaje automático con Amazon SageMaker Data Wrangler.
División de los datos en conjuntos de entrenamiento, validación y prueba.
Con Sklearn, puede dividir el conjunto de datos en un conjunto de entrenamiento y un conjunto de prueba. El conjunto de entrenamiento se usa para entrenar el modelo, mientras que el conjunto de prueba se usa para evaluar el rendimiento del modelo entrenado final. El conjunto de datos se clasifica aleatoriamente con la semilla aleatoria fija: el 80 por ciento del conjunto de datos para el conjunto de entrenamiento y el 20 por ciento para el conjunto de prueba.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1) X_train_display = X_display.loc[X_train.index]
Divida el conjunto de entrenamiento para separar un conjunto de validación. El conjunto de validación se utiliza para evaluar el rendimiento del modelo entrenado y, al mismo tiempo, ajustar los hiperparámetros del modelo. El 75 por ciento del conjunto de entrenamiento se convierte en el conjunto de entrenamiento final y el resto es el conjunto de validación.
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=1) X_train_display = X_display.loc[X_train.index] X_val_display = X_display.loc[X_val.index]
Con el paquete de pandas, alinee de forma explícita cada conjunto de datos concatenando las características numéricas con las etiquetas verdaderas.
import pandas as pd train = pd.concat([pd.Series(y_train, index=X_train.index, name='Income>50K', dtype=int), X_train], axis=1) validation = pd.concat([pd.Series(y_val, index=X_val.index, name='Income>50K', dtype=int), X_val], axis=1) test = pd.concat([pd.Series(y_test, index=X_test.index, name='Income>50K', dtype=int), X_test], axis=1)
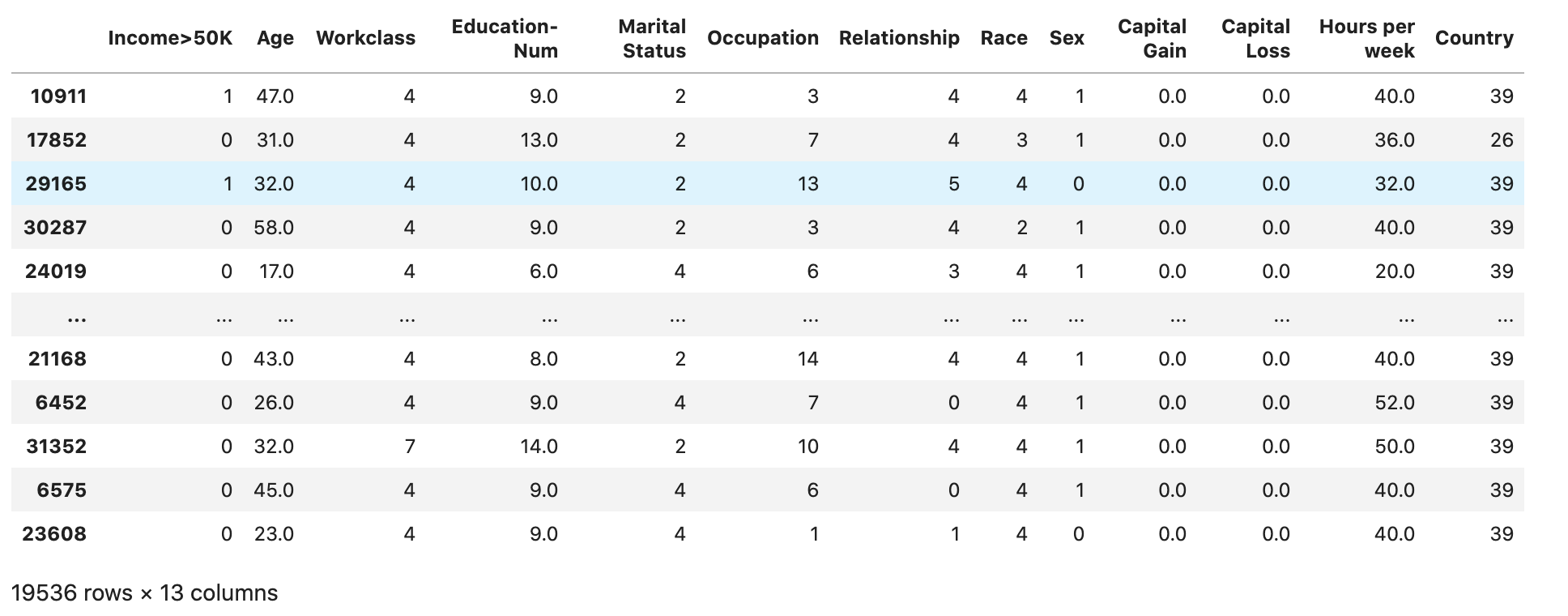
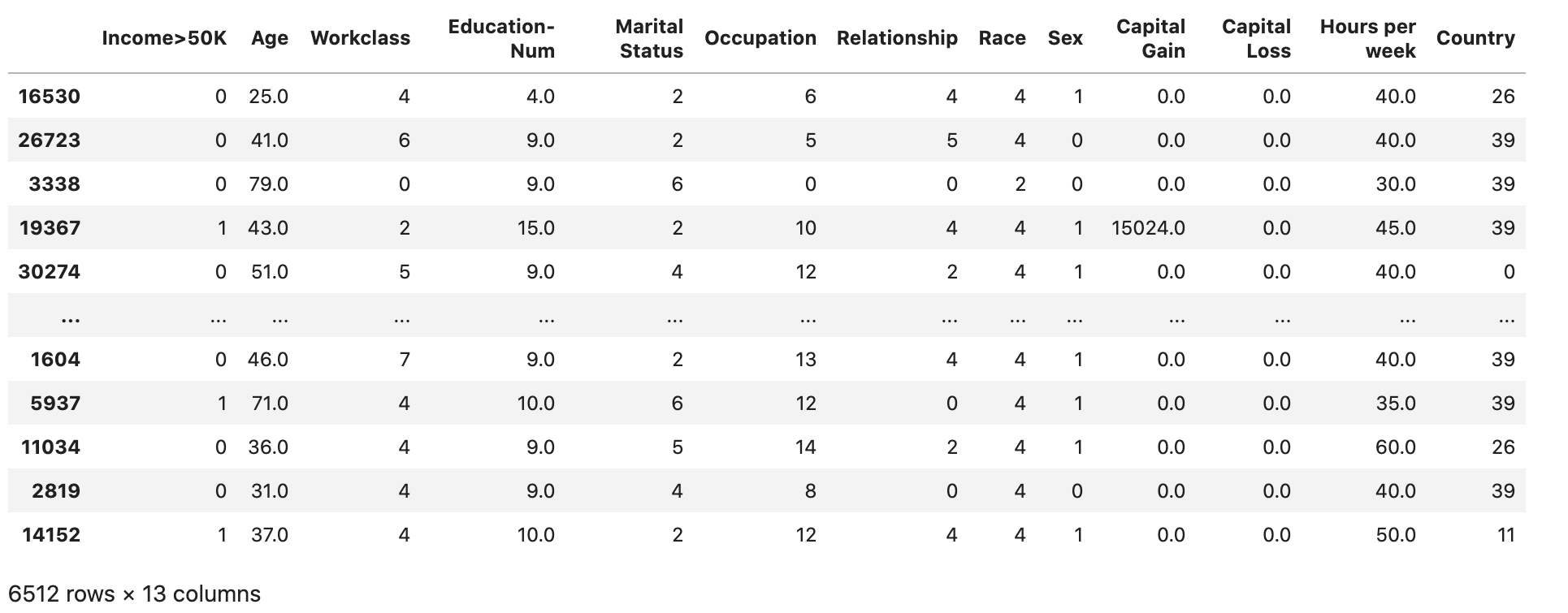
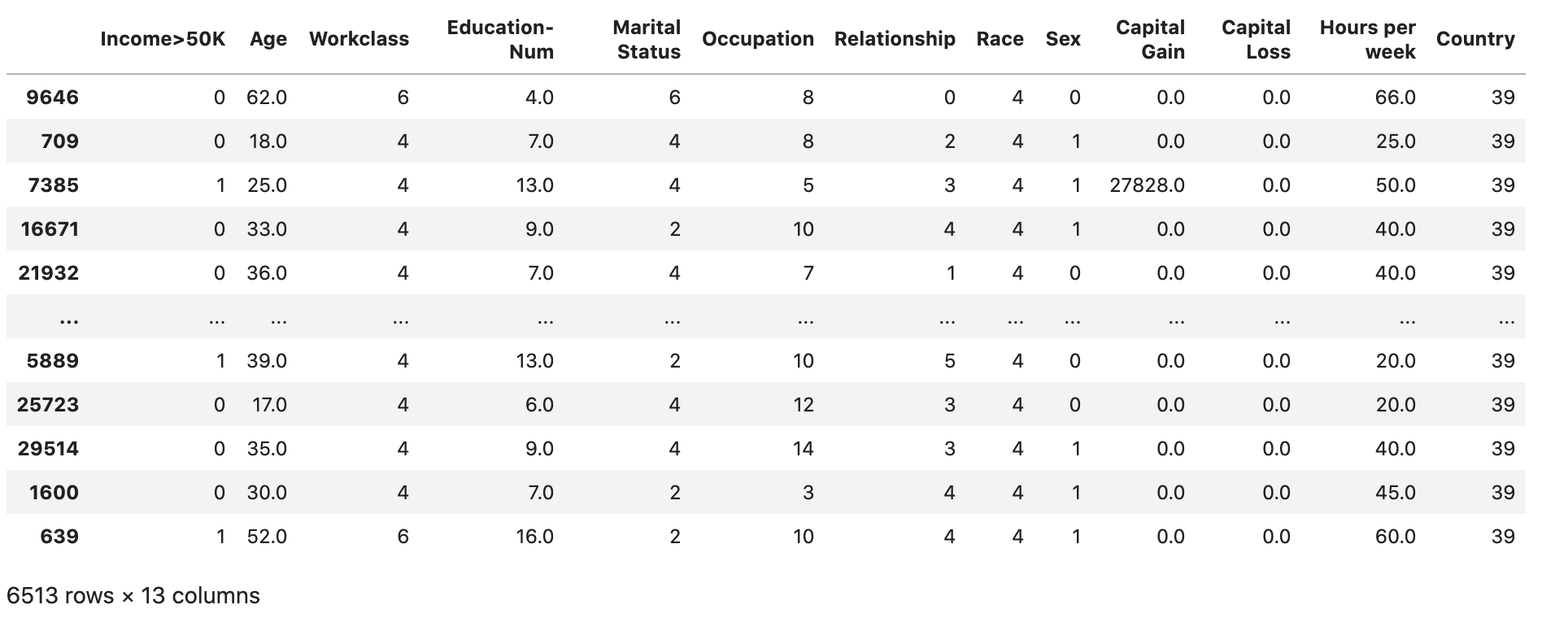
Compruebe si el conjunto de datos está dividido y estructurado como se esperaba:
train
validation
test
Conversión de los conjuntos de datos de entrenamiento y validación en archivos CSV
Convierta los objetos train y el validation marco de datos en archivos CSV para que coincidan con el formato de archivo de entrada del algoritmo. XGBoost
# Use 'csv' format to store the data # The first column is expected to be the output column train.to_csv('train.csv', index=False, header=False) validation.to_csv('validation.csv', index=False, header=False)
Carga de los conjuntos de datos en Amazon S3
Con la SageMaker IA y Boto3, cargue los conjuntos de datos de entrenamiento y validación en el bucket predeterminado de Amazon S3. Una instancia optimizada para la informática de Amazon EC2 utilizará los conjuntos de datos del bucket de S3 con SageMaker fines de formación.
El siguiente código configura el URI del bucket de S3 predeterminado para tu sesión de SageMaker IA actual, crea una nueva demo-sagemaker-xgboost-adult-income-prediction carpeta y carga los conjuntos de datos de entrenamiento y validación en la subcarpeta. data
import sagemaker, boto3, os bucket = sagemaker.Session().default_bucket() prefix = "demo-sagemaker-xgboost-adult-income-prediction" boto3.Session().resource('s3').Bucket(bucket).Object( os.path.join(prefix, 'data/train.csv')).upload_file('train.csv') boto3.Session().resource('s3').Bucket(bucket).Object( os.path.join(prefix, 'data/validation.csv')).upload_file('validation.csv')
Ejecuta lo siguiente AWS CLI para comprobar si los archivos CSV se han cargado correctamente en el depósito de S3.
! aws s3 ls {bucket}/{prefix}/data --recursive
Esto debe devolver la siguiente salida:

