Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Descripción general del aprendizaje automático con Amazon SageMaker AI
En esta sección se describe un flujo de trabajo típico de aprendizaje automático (ML) y se describe cómo realizar esas tareas con Amazon SageMaker AI.
En machine learning, le enseña al equipo a realizar predicciones o inferencias. En primer lugar, utilice el algoritmo o los datos de ejemplo para realizar la capacitación de un modelo. A continuación, integre el modelo en la aplicación para generar inferencias en tiempo real y a escala.
En el siguiente diagrama se muestra el flujo de trabajo típico de creación de un modelo de ML. Incluye tres etapas en un flujo circular que trataremos con más detalle a continuación en el diagrama:
-
Generación de datos de ejemplo
-
Entrenamiento de un modelo
-
Implementación del modelo
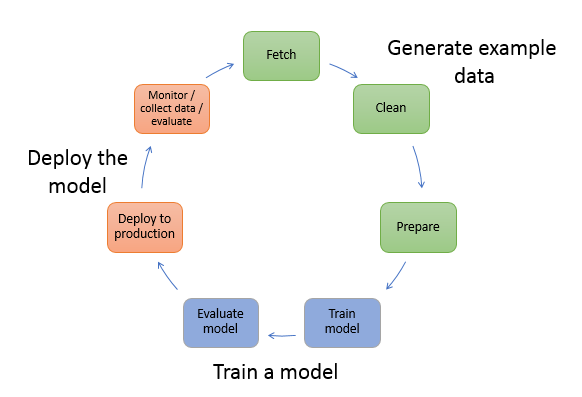
En el diagrama se muestra cómo realizar las siguientes tareas en los escenarios más típicos:
-
Generación de datos de ejemplo: para entrenar un modelo, necesita datos de ejemplo. El tipo de datos que necesita depende del problema empresarial que desee que resuelva el modelo. Esto se refiere a las inferencias que desea que genere el modelo. Por ejemplo, si desea crear un modelo que prediga un número según una imagen de entrada de un dígito escrito a mano. Para entrenar este modelo, necesita imágenes de ejemplo de números escritos a mano.
Los analistas de datos suelen dedicar mucho tiempo a la exploración y el preprocesamiento de los datos de ejemplo antes de usarlos para el entrenamiento de modelos. Para preprocesar datos, normalmente realiza la siguiente operación:
-
Obtención de los datos: puede disponer de repositorios de datos de ejemplo internos o puede usar conjuntos de datos disponibles públicamente. Normalmente, se extraen el conjunto o los conjuntos de datos en un repositorio único.
-
Limpieza de los datos: para mejorar el entrenamiento de modelos, inspeccione los datos y límpielos, según sea necesario. Por ejemplo, si sus datos disponen de un atributo
country namecon valoresUnited StatesyUS, puede editar los datos para que sean coherentes. -
Preparación o transformación de los datos: para mejorar el rendimiento, es posible que desee realizar transformaciones de datos adicionales. Por ejemplo, puede optar por combinar los atributos de un modelo que prediga las condiciones que requieren el deshielo de una aeronave. En lugar de usar los atributos de temperatura y humedad por separado, es posible que los combine en un nuevo atributo para obtener un modelo mejor.
En la SageMaker IA, puedes preprocesar datos de ejemplo SageMaker APIscon el SDK de SageMaker Python
en un entorno de desarrollo integrado (IDE). Con el SDK para Python (Boto3), puede obtener, explorar y preparar sus datos para el entrenamiento de modelos. Para obtener información sobre la preparación, el procesamiento y la transformación de los datos, consulte Recomendaciones para elegir la herramienta de preparación de datos adecuada en SageMaker IA, Cargas de trabajo de transformación de datos con procesamiento SageMaker y Creación, almacenamiento y uso compartido de características con el Almacén de características. -
-
Entrenamiento de un modelo: el entrenamiento del modelo incluye tanto el entrenamiento como la evaluación del modelo, de la siguiente manera:
-
Entrenamiento del modelo: para entrenar un modelo, necesita un algoritmo o un modelo base previamente entrenado. El algoritmo que elija dependerá de un número de factores. Para una solución integrada, puede utilizar uno de los algoritmos que se SageMaker proporcionan. Para obtener una lista de los algoritmos proporcionados por SageMaker y las consideraciones relacionadas, consulteAlgoritmos integrados y modelos previamente entrenados en Amazon SageMaker. Para obtener una solución de entrenamiento basada en la interfaz de usuario que proporciona algoritmos y modelos, consulte SageMaker JumpStart modelos preentrenados.
También necesita computar los recursos para la capacitación. El uso que realice de los recursos depende del tamaño del conjunto de datos de entrenamiento y de la rapidez con la que necesite los resultados. Puede usar recursos que van desde una única instancia de uso general hasta un clúster distribuido de instancias de GPU. Para obtener más información, consulte Entrena a un modelo con Amazon SageMaker.
-
Evaluación del modelo: una vez que haya entrenado el modelo, evalúelo para determinar si la exactitud de las inferencias es aceptable. Para entrenar y evaluar su modelo, utilice el SDK de SageMaker Python
para enviar solicitudes al modelo de inferencias a través de uno de los disponibles IDEs. Para obtener información sobre la evaluación de un modelo, consulte Supervisión de la calidad de los datos y los modelos con Amazon SageMaker Model Monitor.
-
-
Implementación del modelo: tradicionalmente, se rediseña un modelo antes de integrarlo con la aplicación e implementarlo. Con los servicios de alojamiento de SageMaker IA, puede implementar su modelo de forma independiente, lo que lo desvincula del código de la aplicación. Para obtener más información, consulte Implementar modelos para inferencia.
El aprendizaje automático es un ciclo continuo. Después de implementar un modelo, supervise las inferencias, recopile más datos de alta calidad y evalúe el modelo para identificar la desviación. A continuación, puede aumentar la exactitud de las inferencias actualizando los datos de entrenamiento para incluir los datos reales recién recopilados. Conforme estén disponibles más datos de ejemplo, seguirá realizando el entrenamiento del modelo para aumentar la exactitud.
