Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Categorización de texto con clasificación de texto (etiqueta única)
Para clasificar artículos y texto en categorías predefinidas, utilice la clasificación de texto. Por ejemplo, puede utilizar la clasificación de texto para identificar el sentimiento transmitido en una revisión o la emoción subyacente a una sección de texto. Usa la clasificación de texto de Amazon SageMaker Ground Truth para que los trabajadores clasifiquen el texto en las categorías que tú definas. Puede crear un trabajo de etiquetado y clasificación de textos utilizando la sección Ground Truth de la consola Amazon SageMaker AI o la CreateLabelingJoboperación.
importante
Si crea manualmente un archivo de manifiesto de entrada, utilice "source" para identificar el texto que quiere etiquetar. Para obtener más información, consulte Datos de entrada.
Crear un trabajo de etiquetado de clasificación de texto (consola)
Puede seguir las instrucciones Crear un trabajo de etiquetado (consola) para aprender a crear un trabajo de etiquetado de clasificación de textos en la consola de SageMaker IA. En el paso 10, elija Text (Texto) en el menú desplegable Task category (Categoría de tarea) y, luego, Text Classification (Single Label) [Clasificación de texto (etiqueta única)] como tipo de tarea.
Ground Truth proporciona una interfaz de usuario de trabajador similar a la siguiente para las tareas de etiquetado. Al crear el trabajo de etiquetado con la consola, se especifican instrucciones para ayudar a los trabajadores a completar el trabajo y las etiquetas que los trabajadores pueden elegir.
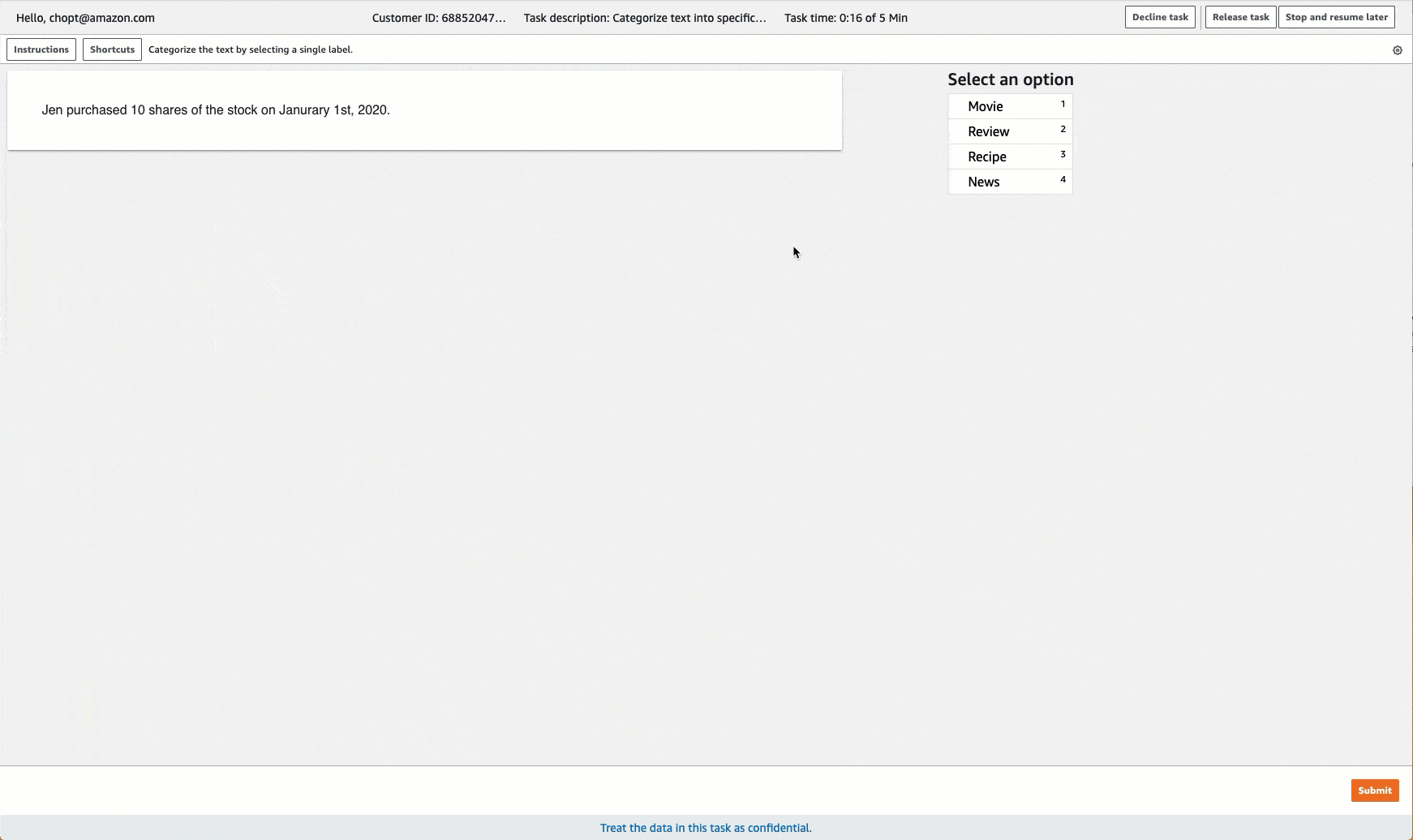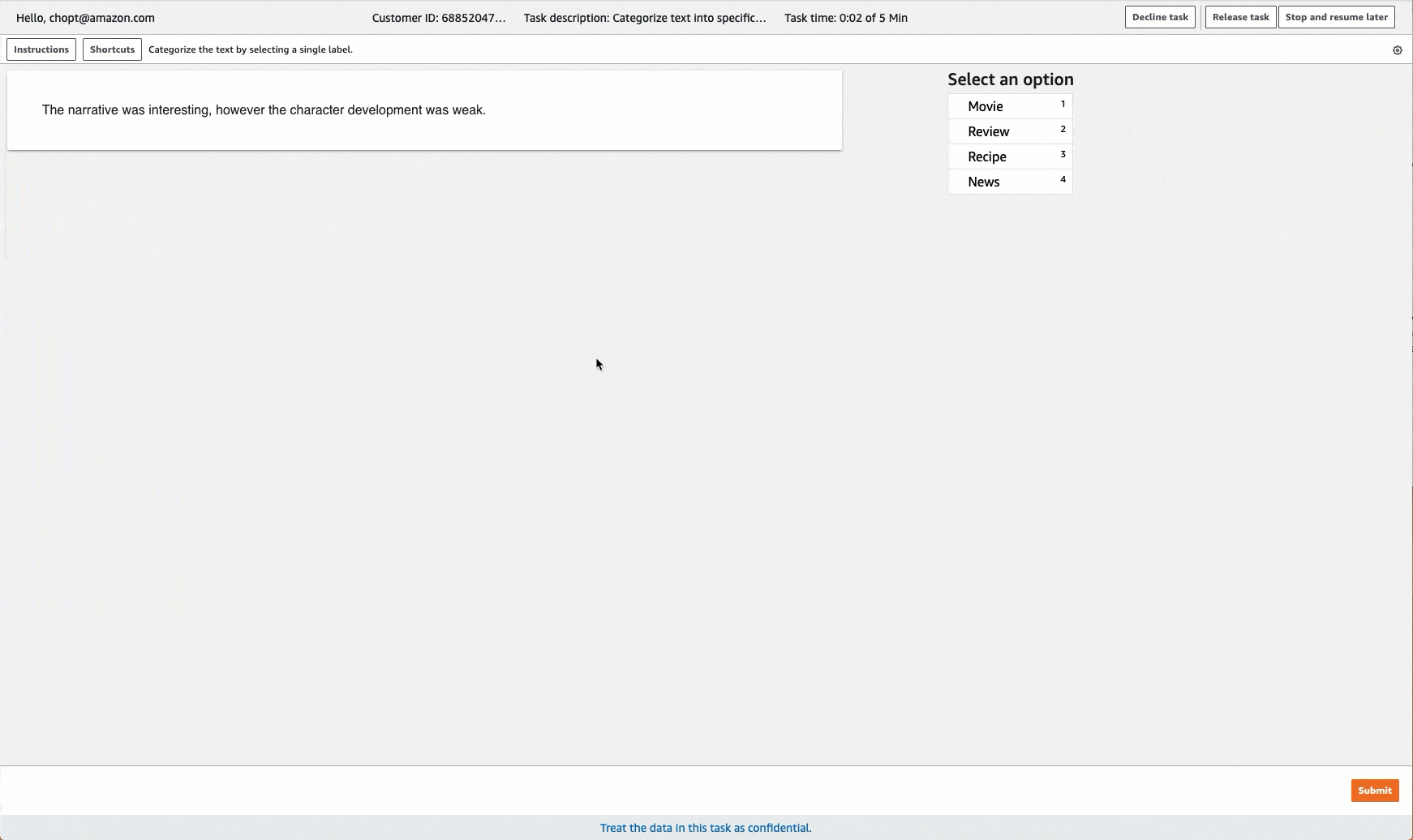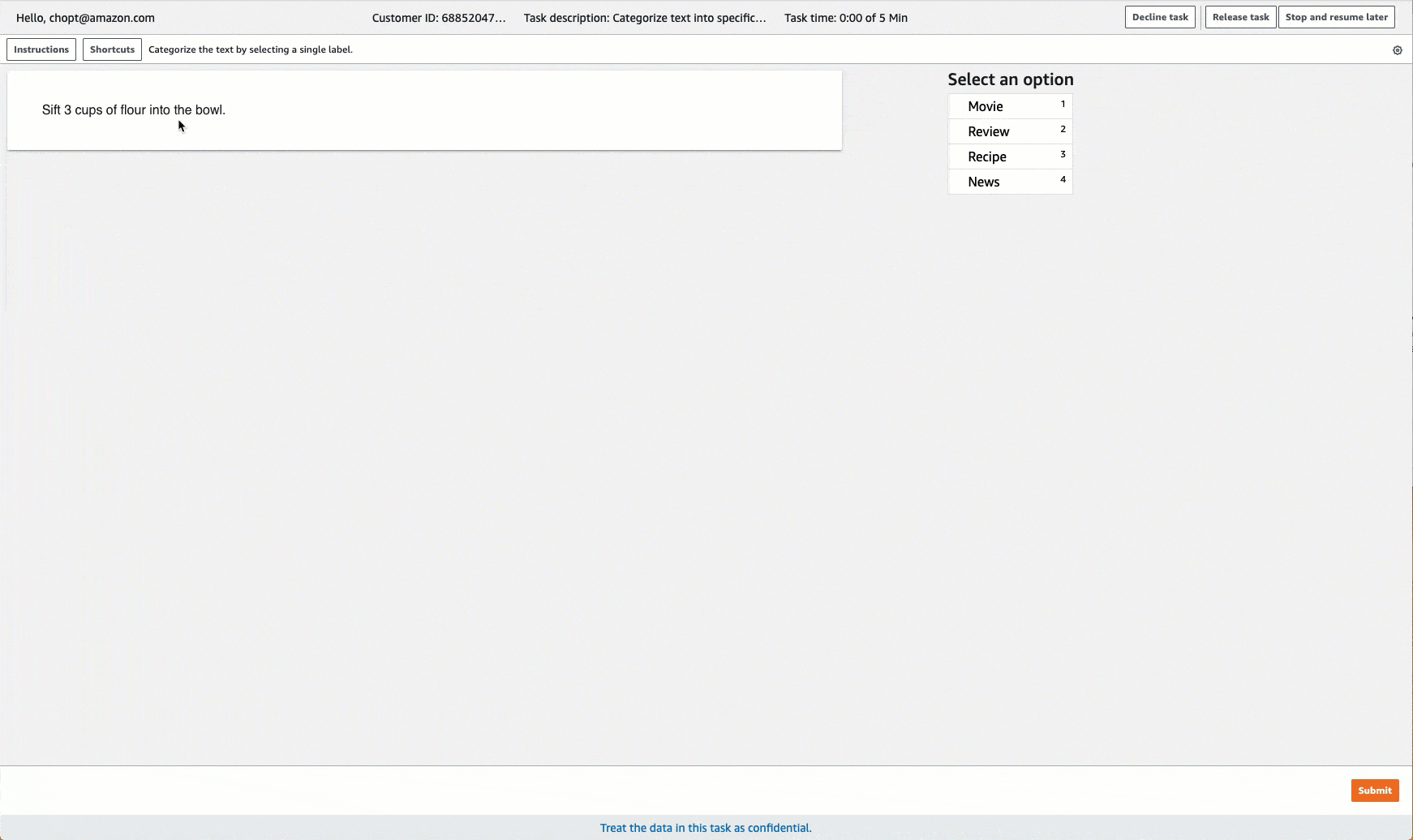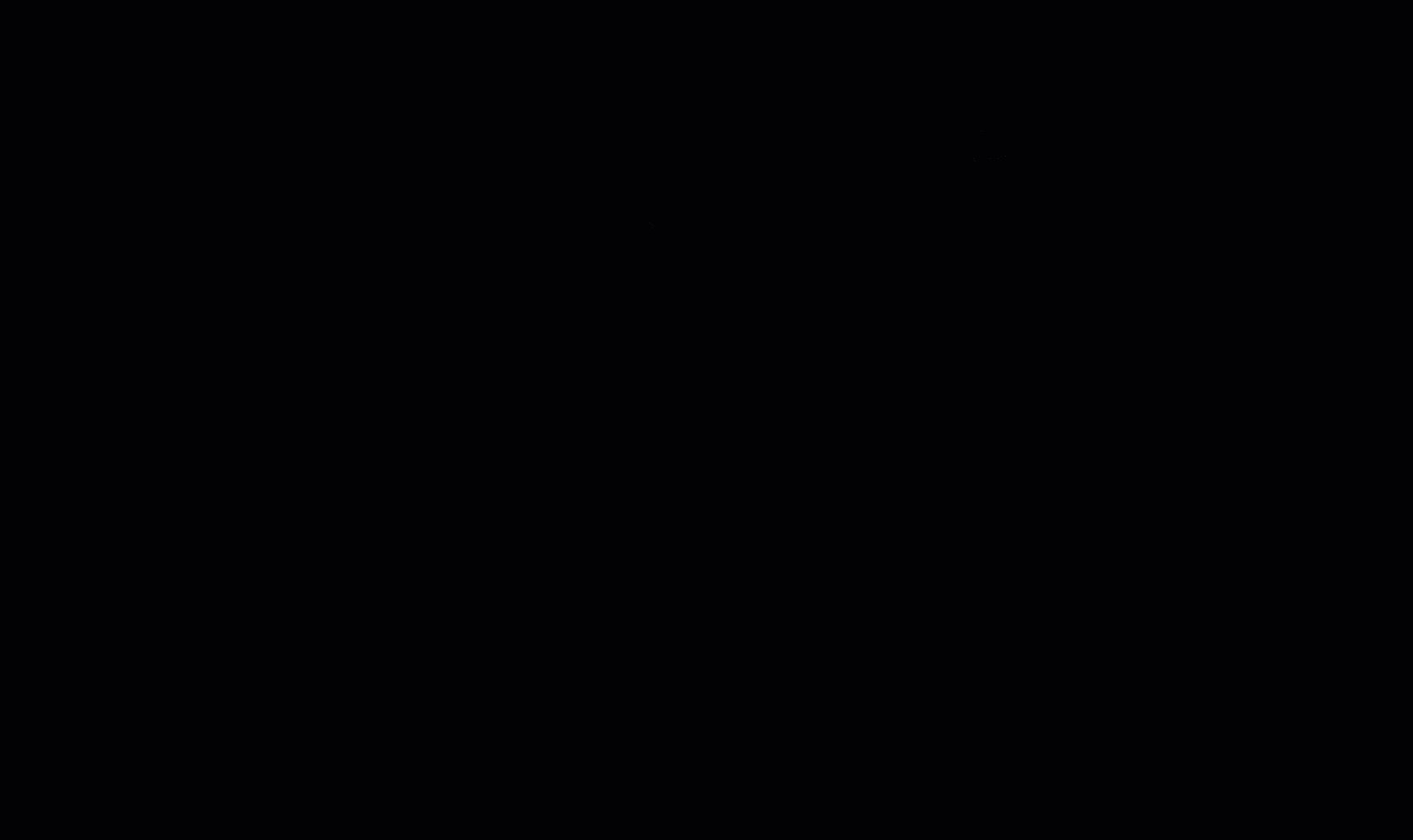
Crear un trabajo de etiquetado de clasificación de texto (API)
Para crear un trabajo de etiquetado de clasificación de texto, utilice la operación SageMaker APICreateLabelingJob. Esta API define esta operación para todos AWS SDKs. Para ver una lista de los idiomas específicos SDKs compatibles con esta operación, consulte la sección Vea también de. CreateLabelingJob
Siga las instrucciones de Crear un trabajo de etiquetado (API) y haga lo siguiente mientras configura su solicitud:
-
Las funciones de Lambda de preanotación para este tipo de tareas terminan con
PRE-TextMultiClass. Para encontrar el ARN Lambda previo a la anotación correspondiente a su región, consulte. PreHumanTaskLambdaArn -
Las funciones de Lambda de consolidación de anotaciones para este tipo de tareas terminan con
ACS-TextMultiClass. Para encontrar el ARN Lambda de consolidación de anotaciones de su región, consulte. AnnotationConsolidationLambdaArn
A continuación se ofrece un ejemplo de solicitud del SDK de AWS Python (Boto3)
response = client.create_labeling_job( LabelingJobName='example-text-classification-labeling-job, LabelAttributeName='label', InputConfig={ 'DataSource': { 'S3DataSource': { 'ManifestS3Uri':'s3://bucket/path/manifest-with-input-data.json'} }, 'DataAttributes': { 'ContentClassifiers': ['FreeOfPersonallyIdentifiableInformation'|'FreeOfAdultContent', ] } }, OutputConfig={ 'S3OutputPath':'s3://bucket/path/file-to-store-output-data', 'KmsKeyId':'string'}, RoleArn='arn:aws:iam::*:role/*, LabelCategoryConfigS3Uri='s3://bucket/path/label-categories.json', StoppingConditions={ 'MaxHumanLabeledObjectCount':123, 'MaxPercentageOfInputDatasetLabeled':123}, HumanTaskConfig={ 'WorkteamArn':'arn:aws:sagemaker:region:*:workteam/private-crowd/*', 'UiConfig': { 'UiTemplateS3Uri':'s3://bucket/path/worker-task-template.html'}, 'PreHumanTaskLambdaArn': 'arn:aws:lambda:us-east-1:432418664414:function:PRE-TextMultiClass, 'TaskKeywords': [Text classification', ], 'TaskTitle':Text classification task', 'TaskDescription':'Carefully read and classify this text using the categories provided.', 'NumberOfHumanWorkersPerDataObject':123, 'TaskTimeLimitInSeconds':123, 'TaskAvailabilityLifetimeInSeconds':123, 'MaxConcurrentTaskCount':123, 'AnnotationConsolidationConfig': { 'AnnotationConsolidationLambdaArn': 'arn:aws:lambda:us-east-1:432418664414:function:ACS-TextMultiClass' }, Tags=[ { 'Key':'string', 'Value':'string'}, ] )
Proporcionar una plantilla para trabajos de etiquetado de clasificación de texto
Si crea un trabajo de etiquetado con la API, debe proporcionar una plantilla de tarea del trabajador en UiTemplateS3Uri. Copie y modifique la siguiente plantilla. Modifique únicamente short-instructions, full-instructions y header.
Cargue esta plantilla a S3 y proporcione el URI de S3 para este archivo en UiTemplateS3Uri.
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script> <crowd-form> <crowd-classifier name="crowd-classifier" categories="{{ task.input.labels | to_json | escape }}" header="classify text" > <classification-target style="white-space: pre-wrap"> {{ task.input.taskObject }} </classification-target> <full-instructions header="Classifier instructions"> <ol><li><strong>Read</strong> the text carefully.</li> <li><strong>Read</strong> the examples to understand more about the options.</li> <li><strong>Choose</strong> the appropriate labels that best suit the text.</li></ol> </full-instructions> <short-instructions> <p>Enter description of the labels that workers have to choose from</p> <p><br></p><p><br></p><p>Add examples to help workers understand the label</p> <p><br></p><p><br></p><p><br></p><p><br></p><p><br></p> </short-instructions> </crowd-classifier> </crowd-form>
Datos de salida de clasificación de texto
Una vez que haya creado un trabajo de etiquetado de clasificación de texto, los datos de salida se ubicarán en el bucket de Amazon S3 especificado en el parámetro S3OutputPath al utilizar la API o en el campo Ubicación del conjunto de datos de salida de la sección Información general del trabajo de la consola.
Para obtener más información sobre el archivo de manifiesto de salida generado por Ground Truth y la estructura de archivos que Ground Truth utiliza para almacenar los datos de salida, consulte Etiquetado de los datos de salida del trabajo.
Para ver un ejemplo de archivos de manifiesto de salida para el trabajo de etiquetado de clasificación de texto, consulte Salida del trabajo de clasificación.
