Soluciones de datos de streaming: ejemplos
Escenario 1: oferta de Internet basada en la ubicación
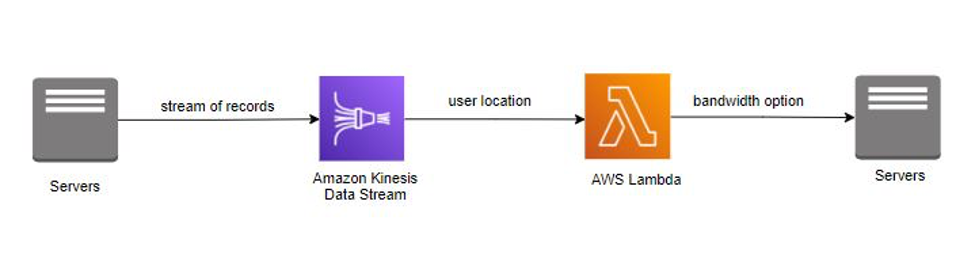
La empresa InternetProvider presta servicios de Internet con diferentes opciones de ancho de banda a los usuarios de todo el mundo. Cuando un usuario se registra en Internet, la empresa InternetProvider proporciona al usuario distintas opciones de ancho de banda según su ubicación geográfica. En función de estos requisitos, la empresa InternetProvider implementó Amazon Kinesis Data Streams para consumir los detalles y la ubicación del usuario. Los detalles y la ubicación del usuario se enriquecen con distintas opciones de ancho de banda antes de volver a publicarse en la aplicación. AWS Lambda
Procesamiento de secuencias de datos con AWS Lambda
Amazon Kinesis Data Streams
Amazon Kinesis Data Streams
Al implementar una solución con Kinesis Data Streams, crea aplicaciones de procesamiento de datos personalizadas que se denominan aplicaciones de Kinesis Data Streams. Una aplicación típica de Kinesis Data Streams lee los datos de una secuencia de Kinesis como registros de datos.
Los datos incluidos en Kinesis Data Streams garantizan una alta disponibilidad y elasticidad, y están disponibles en cuestión de milisegundos. Puede agregar constantemente distintos tipos de datos (por ejemplo, secuencias de clics, registros de aplicaciones y medios sociales) de cientos de miles de fuentes a una secuencia de Kinesis. En cuestión de segundos, los datos estarán disponibles en sus aplicaciones de Kinesis
Amazon Kinesis Data Streams es un servicio de datos de streaming completamente administrado. Se encarga de administrar la infraestructura, el almacenamiento, las redes y la configuración que se necesitan para transmitir sus datos al nivel de su caudal.
Envío de datos a Amazon Kinesis Data Streams
Hay varias formas de enviar datos a Kinesis Data Streams, lo que le proporciona flexibilidad en los diseños de sus soluciones.
-
Puede escribir código con uno de los SDK de AWS
que son compatibles con varios lenguajes conocidos. -
Puede utilizar el agente de Amazon Kinesis, una herramienta para enviar datos a Kinesis Data Streams.
Amazon Kinesis Producer Library (KPL) simplifica el desarrollo de aplicaciones productoras, lo cual permite a los desarrolladores alcanzar un alto rendimiento de escritura en una o más secuencias de datos de Kinesis.
KPL es una biblioteca fácil de usar y con una gran capacidad de configuración que se instala en sus hosts. Ejerce de intermediaria entre el código de aplicación del productor y las acciones de la API de Kinesis Streams. Para obtener más información sobre KPL y su capacidad de producir eventos de forma sincrónica y asincrónica con ejemplos de código, consulte Escribir en sus secuencias de datos de Kinesis con KPL
Hay dos operaciones distintas en la API de Kinesis Data Streams que agregan datos a una secuencia: PutRecords y PutRecord. La operación PutRecords envía varios registros a su secuencia por solicitud HTTP, mientras que PutRecord envía un registro por solicitud HTTP. Para obtener un mayor rendimiento en la mayoría de las aplicaciones, utilice PutRecords.
Para obtener más información sobre estas API, consulte Agregar datos a una secuencia. Los detalles de cada operación de la API se pueden encontrar en la referencia de la API de Amazon Kinesis Data Streams.
Procesamiento de datos en Amazon Kinesis Data Streams
Para leer y procesar datos de secuencias de Kinesis, debe crear una aplicación de consumidor. Hay varias formas de crear consumidores para Kinesis Data Streams. Algunos de estos enfoques incluyen el uso de Amazon Kinesis Data Analytics
Las aplicaciones de consumidor para Kinesis Data Streams se pueden desarrollar con KCL, que le ayuda a consumir y procesar datos de Kinesis Data Streams. KCL se encarga de muchas de las tareas complejas asociadas a la computación distribuida, como el equilibrio de carga entre varias instancias, la respuesta a errores en las instancias, la creación de puntos de control en registros procesados y la reacción a cambios en las particiones. La KCL le permite concentrarse en la lógica de procesamiento de registros de escritura. Para obtener más información sobre cómo crear su propia aplicación KCL, consulte Uso de la Kinesis Client Library.
Puede suscribir las funciones Lambda para que lean lotes de registros automáticamente de la secuencia de Kinesis y los procese si son detectados en dicha secuencia. AWS Lambda sondea periódicamente la secuencia (una vez por segundo) en busca de nuevos registros y, cuando los detecta, invoca la función Lambda que pasa los nuevos registros como parámetros. La función Lambda solo se ejecuta cuando se detectan nuevos registros. Puede asignar una función Lambda a un consumidor de rendimiento compartido (iterador estándar)
Puede crear un consumidor que utilice una característica llamada distribución ramificada mejorada cuando necesite un rendimiento dedicado que no desee competir con otros consumidores que reciben datos de la secuencia. Esta característica permite a los consumidores recibir registros de una secuencia con un rendimiento de hasta dos MB de datos por segundo por partición.
En la mayoría de los casos, usar Kinesis Data Analytics, KCL, AWS Glue oAWS Lambda debe usarse para procesar los datos de una secuencia. Sin embargo, si lo prefiere, puede crear una aplicación de consumidor desde cero con la API de Kinesis Data Streams. La API de Kinesis Data Streams ofrece los métodos GetShardIterator y GetRecords para recuperar datos de una secuencia.
En este modelo de extracción, el código extrae los datos directamente de las particiones de la secuencia. Para obtener más información sobre cómo escribir su propia aplicación de consumidor con la API, consulte Desarrollo de consumidores personalizados con rendimiento compartido con AWS SDK para Java. Los detalles sobre la API se pueden encontrar en la referencia de la API de Amazon Kinesis Data Streams.
Procesamiento de secuencias de datos con AWS Lambda
AWS Lambda
AWS Lambda se integra de forma nativa con Amazon Kinesis Data Streams. Las complejidades del sondeo, los puntos de comprobación y la gestión de errores se abstraen cuando se utiliza esta integración nativa. Esto permite que el código de función Lambda se centre en el procesamiento de lógica empresarial.
Puede asignar una función Lambda a un consumidor rendimiento compartido (iterador estándar) o de rendimiento dedicado con distribución ramificada mejorada. Con un iterador estándar, Lambda sondea cada partición de la secuencia de Kinesis en busca de registros utilizando el protocolo HTTP. Para minimizar la latencia y maximizar el rendimiento de lectura, puede crear un consumidor de flujo de datos con distribución ramificada mejorada. Los consumidores de secuencias en esta arquitectura obtienen una conexión dedicada a cada partición sin competir con otras aplicaciones que leen la misma secuencia. Amazon Kinesis Data Streams envía los registros a Lambda por HTTP/2.
De forma predeterminada, AWS Lambda llama a su función en cuanto los registros están disponibles en la secuencia. Para almacenar en búfer los registros para escenarios de lotes, puede implementar una ventana de lote de hasta cinco minutos en el origen del evento. Si la función devuelve un error, Lambda volverá a intentar ejecutar el lote hasta que el procesamiento se realice correctamente o los datos caduquen.
Resumen
La empresa InternetProvider aprovecho Amazon Kinesis Data Streams para transmitir los detalles y la ubicación de usuario. AWS Lambda consumió la secuencia del registro para enriquecer los datos con opciones de ancho de banda almacenadas en la biblioteca de la función. Después del enriquecimiento, AWS Lambda publica las opciones de ancho de banda en la aplicación. Amazon Kinesis Data Streams y AWS Lambda gestionaron el aprovisionamiento y la administración de servidores, lo que permitió a la empresa InternetProvider centrarse más en el desarrollo de aplicaciones empresariales.
