Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Comment ? Aurora Serverless v1 fonctionnement
Important
AWS a annoncé la end-of-life date de Aurora Serverless v1: 31 mars 2025
Ci-dessous, vous pouvez apprendre comment Aurora Serverless v1 œuvres.
Rubriques
Aurora Serverless v1 application
L'image suivante montre une vue d'ensemble des Aurora Serverless v1 architecture.
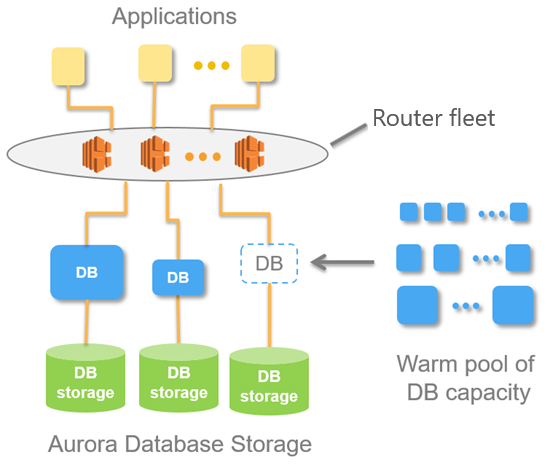
Au lieu de provisionner et de gérer des serveurs de base de données, vous spécifiez les unités de capacité Aurora (ACUs). Chaque unité de capacité combine environ 2 gigaoctets (Go) de mémoire, avec une UC et une mise en réseau correspondantes. Le stockage de base de données s'échelonne automatiquement de 10 gibioctets (GiO) jusqu'à 128 tebibytes (TiB), ce qui équivaut au stockage dans un cluster de base de données Aurora standard.
Vous pouvez définir l'unité de capacité minimale et maximale. L'unité de capacité Aurora minimale est l'unité de capacité la plus petite à laquelle le cluster de bases de données peut être dimensionné. L'unité de capacité Aurora maximale est l'unité de capacité la plus grande à laquelle le cluster de bases de données peut être dimensionné. En fonction de vos paramètres, Aurora Serverless v1 crée automatiquement des règles de dimensionnement pour les seuils d'utilisation du processeur, de connexions et de mémoire disponible.
Aurora Serverless v1 gère le pool de ressources chaudes afin de minimiser le temps de mise Région AWS à l'échelle. Lorsque Aurora Serverless v1 ajoute de nouvelles ressources au cluster de base de données Aurora, il utilise le parc de routeurs pour transférer les connexions client actives vers les nouvelles ressources. À un moment donné, vous n'êtes facturé que pour ceux ACUs qui sont utilisés activement dans votre cluster de base de données Aurora.
Autoscaling pour Aurora Serverless v1
La capacité allouée à votre Aurora Serverless v1 Le cluster de base de données augmente ou diminue de manière fluide en fonction de la charge générée par votre application cliente. Ici, la charge représente l'utilisation du processeur et le nombre de connexions. Lorsque la capacité est limitée par l'un ou l'autre de ces facteurs, Aurora Serverless v1 augmente. Aurora Serverless v1 prend également de l'ampleur lorsqu'il détecte des problèmes de performances qui peuvent être résolus de cette manière.
Vous pouvez consulter les événements de dimensionnement pour votre Aurora Serverless v1 cluster dans le AWS Management Console. Pendant le redimensionnement automatique, Aurora Serverless v1 réinitialise la EngineUptime métrique. La valeur de la valeur de la métrique réinitialisée ne signifie pas que la mise à l'échelle fluide a posé des problèmes ou que Aurora Serverless v1 connexions abandonnées. C'est simplement le point de départ de la disponibilité à la nouvelle capacité. Pour en savoir plus sur les métriques, consultez Surveillance des métriques d'un cluster de bases de données Amazon Aurora.
Lorsque votre Aurora Serverless v1 Le cluster de base de données n'a aucune connexion active, il peut être réduit à une capacité nulle (0 ACUs). Pour en savoir plus, veuillez consulter la section Pause et reprise pour Aurora Serverless v1.
Lorsqu'il doit effectuer une opération de mise à l'échelle, Aurora Serverless v1 essaie d'abord d'identifier un point d'échelle, moment où aucune requête n'est traitée. Aurora Serverless v1 peut ne pas être en mesure de trouver un point d'échelle pour les raisons suivantes :
-
Requêtes de longue durée
-
Transactions en cours
-
Tables temporaires ou verrous de table
Pour augmenter votre Aurora Serverless v1 Taux de réussite du cluster de bases de données Lorsque vous recherchez un point d'échelle, nous vous recommandons d'éviter les requêtes et les transactions de longue durée. Pour en savoir plus sur les opérations qui bloquent la mise à l'échelle et sur la manière de les éviter, consultez la section Meilleures pratiques pour travailler avec Aurora Serverless v1
Par défaut, Aurora Serverless v1 essaie de trouver un point d'échelle pendant 5 minutes (300 secondes). Vous pouvez spécifier un délai d'attente différent lorsque vous créez ou modifiez le cluster. Le délai d'attente peut être compris entre 60 secondes et 10 minutes (600 secondes). If Aurora Serverless v1 Impossible de trouver un point de mise à l'échelle dans la période spécifiée, l'opération de mise à l'échelle automatique expire.
Par défaut, si la mise à l'échelle automatique ne trouve pas de point de mise à l'échelle avant l'expiration du délai imparti, Aurora Serverless v1 maintient le cluster à sa capacité actuelle. Vous pouvez modifier ce comportement par défaut lorsque vous créez ou modifiez votre Aurora Serverless v1 Cluster de base de données en sélectionnant l'option Forcer le changement de capacité. Pour de plus amples informations, veuillez consulter Action de délai d'attente pour les modifications de capacité.
Action de délai d'attente pour les modifications de capacité
Si la scalabilité automatique expire avec la recherche d'un point de mise à l'échelle, Aurora conserve par défaut la capacité actuelle. Vous pouvez faire en sorte que Aurora force le changement en sélectionnant l'option Force the capacity change (Forcer le changement de capacité). Cette option est disponible dans la section Autoscaling timeout and action (Délai de mise à l'échelle automatique et action) de la page Create database (Créer une base de données), lorsque vous créez le cluster.
Par défaut, l'option Force the capacity change (Forcer le changement de capacité) n'est pas sélectionnée. Désactivez cette option pour avoir votre Aurora Serverless v1 La capacité du cluster de bases de données reste inchangée si l'opération de dimensionnement expire sans qu'un point de dimensionnement soit trouvé.
La sélection de cette option entraîne votre Aurora Serverless v1 Cluster de base de données pour appliquer le changement de capacité, même sans point d'échelle. Avant de sélectionner cette option, tenez compte des conséquences de sa sélection :
-
Toutes les transactions en cours de processus sont interrompues et le message d'erreur suivant s'affiche.
Aurora MySQL version 2 –
ERREUR 1105 (HY000) : La dernière transaction a été interrompue en raison d'une mise à l'échelle transparente. Veuillez réessayer.Vous pouvez soumettre à nouveau les transactions dès que votre Aurora Serverless v1 Le cluster de base de données est disponible.
-
Les connexions aux tables temporaires et aux verrous sont abandonnées.
Nous vous recommandons de sélectionner l'option Force the capacity change (Forcer le changement de capacité) uniquement si votre application peut récupérer des connexions interrompues ou des transactions incomplètes.
Les choix que vous faites AWS Management Console lorsque vous créez un Aurora Serverless v1 Les clusters de base de données sont stockés dans l'ScalingConfigurationInfoobjet, dans les TimeoutAction propriétés SecondsBeforeTimeout et. La valeur de la propriété TimeoutAction est définie sur l'une des valeurs suivantes lorsque vous créez votre cluster :
-
RollbackCapacityChange– Cette valeur est définie lorsque vous sélectionnez l'option Roll back the capacity change (Restaurer le changement de capacité). Il s'agit du comportement de par défaut. -
ForceApplyCapacityChange– Cette valeur est définie lorsque vous sélectionnez l'option Force the capacity change (Forcer le changement de capacité).
Vous pouvez obtenir la valeur de cette propriété sur une propriété existante Aurora Serverless v1 Cluster de base de données à l'aide de la describe-db-clusters AWS CLI commande, comme indiqué ci-dessous.
Dans Linux, macOS, ou Unix:
aws rds describe-db-clusters --regionregion\ --db-cluster-identifieryour-cluster-name\ --query '*[].{ScalingConfigurationInfo:ScalingConfigurationInfo}'
Dans Windows:
aws rds describe-db-clusters --regionregion^ --db-cluster-identifieryour-cluster-name^ --query "*[].{ScalingConfigurationInfo:ScalingConfigurationInfo}"
À titre d'exemple, l'exemple suivant montre la requête et la réponse pour un Aurora Serverless v1 Cluster de base de données nommé west-coast-sles dans la région USA Ouest (Californie du Nord).
$aws rds describe-db-clusters --region us-west-1 --db-cluster-identifier west-coast-sles --query '*[].{ScalingConfigurationInfo:ScalingConfigurationInfo}' [ { "ScalingConfigurationInfo": { "MinCapacity": 1, "MaxCapacity": 64, "AutoPause": false, "SecondsBeforeTimeout": 300, "SecondsUntilAutoPause": 300, "TimeoutAction": "RollbackCapacityChange" } } ]
Comme le montre la réponse, ce Aurora Serverless v1 Le cluster de base de données utilise le paramètre par défaut.
Pour de plus amples informations, veuillez consulter Création d'un Aurora Serverless v1 Cluster DB. Après avoir créé votre Aurora Serverless v1, vous pouvez modifier l'action de temporisation et les autres paramètres de capacité à tout moment. Pour savoir comment procéder, veuillez consulter la section Modification d'un Aurora Serverless v1 Cluster DB.
Pause et reprise pour Aurora Serverless v1
Vous pouvez choisir de suspendre votre Aurora Serverless v1 Cluster de base de données après un certain laps de temps sans activité. Spécifiez la durée d'inactivité du cluster de base de données avant que celui-ci soit mis en pause. Lorsque vous sélectionnez cette option, le temps d'inactivité par défaut est de cinq minutes, mais vous pouvez modifier cette valeur. Il s'agit d'une étape facultative.
Lorsque le cluster de base de données est en pause, aucune activité de calcul ou de mémoire ne se produit ; vous êtes facturé uniquement pour le stockage. Si des connexions à la base de données sont demandées lorsqu'un Aurora Serverless v1 Le cluster de base de données est suspendu, le cluster de base de données reprend automatiquement et traite les demandes de connexion.
Lorsque le cluster de base de données reprend l'activité, il a la même capacité que lorsque Aurora a mis en pause le cluster. Le nombre de ACUs dépend de la mesure dans laquelle Aurora a redimensionné le cluster à la hausse ou à la baisse avant de le suspendre.
Note
Si un cluster de base de données est mis en pause pendant plus de sept jours, il peut être sauvegardé avec un instantané. Dans ce cas, Aurora restaure le cluster de base de données à partir de l'instantané lorsqu'il y a une demande de connexion à celui-ci.
Déterminer le nombre maximal de connexions à la base de données pour Aurora Serverless v1
Les exemples suivants concernent un Aurora Serverless v1 Cluster de base de données compatible avec MySQL 5.7. Vous pouvez utiliser un client MySQL ou l'éditeur de requêtes, si vous y avez configuré l'accès. Pour de plus amples informations, veuillez consulter Exécution de requêtes dans l'éditeur de requête.
Pour trouver le nombre maximal de connexions à une base de données
-
Trouvez la plage de capacité adaptée à votre Aurora Serverless v1 Cluster de base de données utilisant le AWS CLI.
aws rds describe-db-clusters \ --db-cluster-identifier my-serverless-57-cluster \ --query 'DBClusters[*].ScalingConfigurationInfo|[0]'Le résultat indique que sa plage de capacité est comprise entre 1 et 4 ACUs.
{ "MinCapacity": 1, "AutoPause": true, "MaxCapacity": 4, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 } -
Exécutez la requête SQL suivante pour trouver le nombre maximal de connexions.
select @@max_connections;Le résultat affiché correspond à la capacité minimale du cluster, 1 ACU.
@@max_connections 90 -
Redimensionnez le cluster de 8 à 32. ACUs
Pour plus d’informations sur le dimensionnement, consultez Modification d'un Aurora Serverless v1 Cluster DB.
-
Confirmez la plage de capacité.
{ "MinCapacity": 8, "AutoPause": true, "MaxCapacity": 32, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 } -
Trouvez le nombre maximal de connexions.
select @@max_connections;Le résultat affiché correspond à la capacité minimale du cluster, 8 ACUs.
@@max_connections 1000 -
Redimensionnez le cluster au maximum possible, 256 à 256. ACUs
-
Confirmez la plage de capacité.
{ "MinCapacity": 256, "AutoPause": true, "MaxCapacity": 256, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 } -
Trouvez le nombre maximal de connexions.
select @@max_connections;Le résultat affiché est pour 256 ACUs.
@@max_connections 6000Note
La
max_connectionsvaleur n'évolue pas de façon linéaire avec le nombre de ACUs. -
Réduisez le cluster à une valeur de 1 à 4 ACUs.
{ "MinCapacity": 1, "AutoPause": true, "MaxCapacity": 4, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 }Cette fois, la
max_connectionsvaleur est de 4 ACUs.@@max_connections 270 -
Laissez le cluster diminuer à 2 ACUs.
@@max_connections 180Si vous avez configuré le cluster pour qu'il se mette en pause après un certain temps d'inactivité, il est réduit à 0 ACUs. Cependant,
max_connectionsne tombe pas en dessous de 1 ACU.@@max_connections 90
Groupes de paramètres pour Aurora Serverless v1
Lorsque vous créez votre Aurora Serverless v1 Cluster de base de données, vous choisissez un moteur de base de données Aurora spécifique et un groupe de paramètres de cluster de base de données associé. Contrairement aux clusters de base de données Aurora provisionnés, un Aurora Serverless v1 Le cluster de base de données possède une seule instance de base de données en lecture/écriture configurée uniquement avec un groupe de paramètres de cluster de base de données ; il ne possède pas de groupe de paramètres de base de données distinct. Pendant le redimensionnement automatique, Aurora Serverless v1 doit être en mesure de modifier les paramètres pour que le cluster fonctionne au mieux en fonction de l'augmentation ou de la diminution de la capacité. Ainsi, avec un Aurora Serverless v1 Cluster de base de données, certaines des modifications que vous pouvez apporter aux paramètres d'un type de moteur de base de données particulier peuvent ne pas s'appliquer.
Par exemple, une application basée sur Aurora PostgreSQL Aurora Serverless v1 Le cluster de base de données ne peut pas utiliser apg_plan_mgmt.capture_plan_baselines les autres paramètres susceptibles d'être utilisés sur les clusters de base de données Aurora PostgreSQL provisionnés pour la gestion du plan de requêtes.
Vous pouvez obtenir une liste des valeurs par défaut pour les groupes de paramètres par défaut des différents moteurs de base de données Aurora en utilisant la commande CLI describe-engine-default-cluster-parameters et en interrogeant le. Région AWS Pour l'option --db-parameter-group-family, vous pouvez utiliser les valeurs suivantes :
|
Aurora MySQL version 2 |
|
|
Aurora PostgreSQL version 11 |
|
|
Aurora PostgreSQL version 13 |
|
Nous vous recommandons de le configurer AWS CLI avec votre identifiant de clé AWS d'accès et votre clé d'accès AWS secrète, et de définir le vôtre Région AWS avant d'utiliser AWS CLI des commandes. La fourniture de la région à votre configuration CLI vous évite d'entrer dans le paramètre --region lors de l'exécution des commandes. Pour en savoir plus sur la configuration AWS CLI, consultez la section Notions de base de la configuration dans le guide de AWS Command Line Interface l'utilisateur.
L'exemple suivant obtient une liste de paramètres du groupe de clusters de bases de données par défaut pour Aurora MySQL version 2.
Dans Linux, macOS, ou Unix:
aws rds describe-engine-default-cluster-parameters \ --db-parameter-group-family aurora-mysql5.7 --query \ 'EngineDefaults.Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `serverless`) == `true`] | [*].{param:ParameterName}' \ --output text
Dans Windows:
aws rds describe-engine-default-cluster-parameters ^ --db-parameter-group-family aurora-mysql5.7 --query ^ "EngineDefaults.Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, 'serverless') == `true`] | [*].{param:ParameterName}" ^ --output text
Modification des valeurs des paramètres pour Aurora Serverless v1
Comme expliqué dans Groupes de paramètres pour Amazon Aurora (), vous ne pouvez pas modifier directement les valeurs d'un groupe de paramètres par défaut, quel que soit son type (groupe de paramètres de cluster de bases de données, groupe de paramètres de bases de données). Au lieu de cela, vous créez un groupe de paramètres personnalisé basé sur le groupe de paramètres de cluster de bases de données par défaut pour votre moteur de bases de données Aurora et modifiez les paramètres selon les besoins sur ce groupe de paramètres. Par exemple, vous souhaiterez peut-être modifier certains paramètres de votre Aurora Serverless v1 Cluster de base de données pour consigner les requêtes ou pour télécharger des journaux spécifiques au moteur de base de données sur Amazon CloudWatch.
Pour créer un groupe de paramètres de cluster de bases de données personnalisé
-
Connectez-vous à la console Amazon RDS, AWS Management Console puis ouvrez-la à https://console.aws.amazon.com/rds/
l'adresse. -
Choisissez Groupes de paramètres.
-
Choisissez Créer un groupe de paramètres pour ouvrir le volet des détails du groupe de paramètres.
-
Choisissez le groupe de clusters de base de données par défaut approprié pour le moteur de base de données que vous souhaitez utiliser pour votre Aurora Serverless v1 Cluster de bases de données. Veillez à choisir les options suivantes :
-
Pour Famille de groupes de paramètres, choisissez la famille correspondant au moteur de base de données choisi. Assurez-vous que le nom de votre choix comporte le préfixe
aurora-. -
Pour Type, choisissez Groupe de paramètres de cluster DB.
-
Dans le champ Nom du groupe et Description, entrez des noms significatifs pour vous ou pour d'autres personnes susceptibles d'avoir besoin de travailler avec votre Aurora Serverless v1 Le cluster de base de données et ses paramètres.
-
Choisissez Créer.
-
Votre groupe de paramètres de cluster de bases de données personnalisé est ajouté à la liste des groupes de paramètres disponibles dans votre Région AWS. Vous pouvez utiliser votre groupe de paramètres de cluster de base de données personnalisé lorsque vous créez un nouveau Aurora Serverless v1 Clusters de bases de données. Vous pouvez également modifier un existant Aurora Serverless v1 Cluster de base de données pour utiliser votre groupe de paramètres de cluster de base de données personnalisé. Après votre Aurora Serverless v1 Le cluster de base de données commence à utiliser votre groupe de paramètres de cluster de base de données personnalisé. Vous pouvez modifier les valeurs des paramètres dynamiques à l'aide du AWS Management Console ou du AWS CLI.
Vous pouvez également utiliser la console pour afficher une side-by-side comparaison des valeurs de votre groupe de paramètres de cluster de base de données personnalisé par rapport au groupe de paramètres de cluster de base de données par défaut, comme illustré dans la capture d'écran suivante.
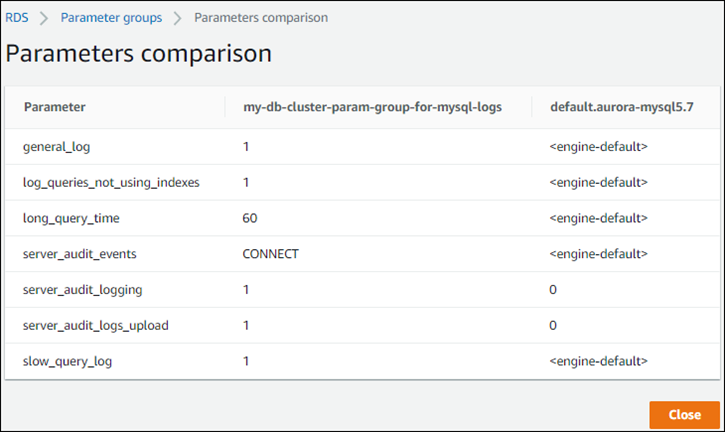
Lorsque vous modifiez les valeurs des paramètres sur un cluster de base de données actif, Aurora Serverless v1 lance une échelle continue afin d'appliquer les modifications de paramètres. Si vos recettes Aurora Serverless v1 Le cluster de base de données est en pause, il reprend et commence à être redimensionné afin de pouvoir effectuer la modification. L'opération de mise à l'échelle d'une modification de groupe de paramètres force toujours un changement de capacité, sachez donc que la modification des paramètres peut entraîner l'abandon des connexions si aucun point de mise à l'échelle ne peut être trouvé pendant la période de mise à l'échelle.
Logging pour Aurora Serverless v1
Par défaut, les journaux d'erreurs pour Aurora Serverless v1 sont activés et automatiquement chargés sur Amazon CloudWatch. Vous pouvez également avoir votre Aurora Serverless v1 Le cluster de bases de données télécharge les journaux spécifiques au moteur de base de données Aurora vers. CloudWatch Pour ce faire, activez les paramètres de configuration dans votre groupe de paramètres de cluster de bases de données personnalisé. Votre Aurora Serverless v1 Le cluster de base de données télécharge ensuite tous les journaux disponibles sur Amazon CloudWatch. À ce stade, vous pouvez l'utiliser CloudWatch pour analyser les données du journal, créer des alarmes et afficher les métriques.
Pour Aurora MySQL, le tableau suivant indique les journaux que vous pouvez activer. Lorsqu'elles sont activées, elles sont automatiquement téléchargées depuis votre Aurora Serverless v1 Cluster de base de données pour Amazon CloudWatch.
| Journal Aurora MySQL | Description |
|---|---|
|
|
Crée le journal général. Paramétrez sur 1 pour activer. La valeur par défaut est désactivée (0). |
|
|
Journalise les requêtes dans le journal des requêtes lentes qui n'utilisent pas d'index. La valeur par défaut est désactivée (0). Paramétrez sur 1 pour activer ce journal. |
|
|
Empêche l'enregistrement des requêtes rapides dans le journal des requêtes lentes. Peut être défini sur une valeur flottante comprise entre 0 et 31 536 000. La valeur par défaut est 0 (non active). |
|
|
Liste des événements à capturer dans les journaux. Les valeurs prises en charge sont |
|
|
Paramétrez sur 1 pour activer la journalisation d'audit de serveur. Si vous activez cette option, vous pouvez spécifier les événements d'audit auxquels les envoyer CloudWatch en les listant dans le |
|
|
Crée un journal des requêtes lentes. Paramétrez sur 1 pour activer le journal des requêtes lentes. La valeur par défaut est désactivée (0). |
Pour de plus amples informations, veuillez consulter Utilisation de l'audit avancé avec un cluster Amazon Aurora My SQL DB.
Pour Aurora PostgreSQL, le tableau suivant indique les journaux que vous pouvez activer. Lorsqu'elles sont activées, elles sont automatiquement téléchargées depuis votre Aurora Serverless v1 Cluster de base de données vers Amazon CloudWatch avec les journaux d'erreurs habituels.
| Journal Aurora PostgreSQL | Description |
|---|---|
|
|
Activé par défaut et ne peut pas être modifié. Il journalise les détails pour toutes les nouvelles connexions client. |
|
|
Activé par défaut et ne peut pas être modifié. Journalise toutes les déconnexions du client. |
|
|
Elle est désactivée par défaut et ne peut pas être modifiée. Les noms d'hôtes ne sont pas enregistrés. |
|
|
La valeur par défaut est 0 (désactivée). Paramétrez sur 1 pour journaliser les attentes de verrouillage. |
|
|
Durée minimale (en millisecondes) d'exécution d'une instruction avant qu'elle ne soit journalisée. |
|
|
Définit les niveaux des messages qui sont enregistrés. Les valeurs prises en charge sont Pour consigner les données de performances dans le journal |
|
|
Journalise l'utilisation de fichiers temporaires qui sont au-dessus des kilo-octets (Ko) spécifiés. |
|
|
Contrôle les instructions SQL spécifiques qui sont journalisées. Les valeurs prises en charge sont |
Après avoir activé les journaux pour Aurora MySQL ou Aurora PostgreSQL pour votre Aurora Serverless v1 Cluster de base de données, vous pouvez consulter les connexions CloudWatch.
Visualisation Aurora Serverless v1 se connecte avec Amazon CloudWatch
Aurora Serverless v1 télécharge (« publie ») automatiquement sur Amazon CloudWatch tous les journaux activés dans votre groupe de paramètres de cluster de bases de données personnalisé. Vous n'avez pas besoin de choisir ou de spécifier les types de journaux. Le chargement des journaux démarre dès que vous activez le paramètre de configuration du journal. Si vous désactivez ultérieurement le paramètre de journal, les chargements supplémentaires s'arrêtent. Cependant, tous les journaux qui ont déjà été publiés seront CloudWatch conservés jusqu'à ce que vous les supprimiez.
Pour plus d'informations sur l'utilisation CloudWatch des journaux Aurora MySQL, consultezSurveillance des événements du journal sur Amazon CloudWatch.
Pour plus d'informations sur CloudWatch Aurora PostgreSQL, consultez. Publication des journaux Aurora PostgreSQL sur Amazon Logs CloudWatch
Pour consulter les journaux de votre Aurora Serverless v1 Cluster DB
Ouvrez la CloudWatch console à l'adresse https://console.aws.amazon.com/cloudwatch/
. -
Choisissez votre Région AWS.
-
Choisissez Groupes de journaux.
-
Choisissez votre Aurora Serverless v1 Journal du cluster de base de données depuis la liste. Pour les journaux d'erreurs, le modèle d'affectation de noms est le suivant.
/aws/rds/cluster/cluster-name/error
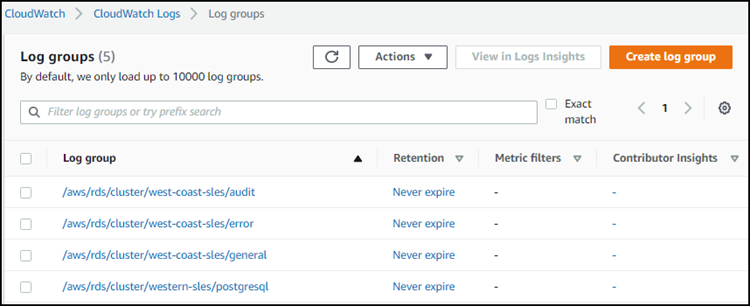
Par exemple, dans la capture d'écran suivante, vous pouvez trouver des listes de journaux publiés pour Aurora PostgreSQL Aurora Serverless v1 Cluster de base de données nomméwestern-sles. Vous pouvez également trouver plusieurs listes pour Aurora MySQL Aurora Serverless v1 cluster de bases de données,west-coast-sles. Choisissez le journal qui vous intéresse pour commencer à explorer son contenu.
Aurora Serverless v1 et entretien
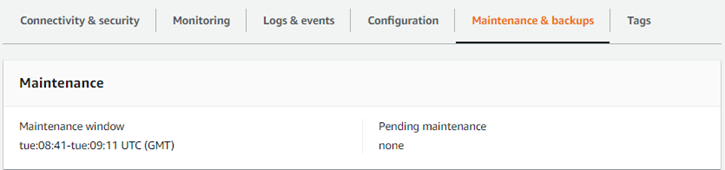
Maintenance pour Aurora Serverless v1 Le cluster de base de données, tel que l'application des dernières fonctionnalités, correctifs et mises à jour de sécurité, est effectué automatiquement pour vous. Aurora Serverless v1 comporte une fenêtre de maintenance que vous pouvez consulter AWS Management Console dans Maintenance et sauvegardes pour votre Aurora Serverless v1 Cluster de bases de données. Vous pouvez trouver la date et l'heure auxquelles la maintenance peut être effectuée et si une maintenance est en attente pour votre Aurora Serverless v1 Cluster de base de données, comme illustré dans la figure suivante.
Vous pouvez définir la fenêtre de maintenance lorsque vous créez Aurora Serverless v1 cluster de base de données, et vous pourrez modifier la fenêtre ultérieurement. Pour de plus amples informations, veuillez consulter Ajustement du créneau de maintenance préféré pour un cluster de base de données.
Les fenêtres de maintenance sont utilisées pour les mises à niveau des versions majeures planifiées. Les mises à niveau des versions mineures et les correctifs sont appliqués immédiatement lors du dimensionnement. La mise à l'échelle s'effectue en fonction de vos paramètres pour TimeoutAction :
-
ForceApplyCapacityChange— La modification est appliquée immédiatement. -
RollbackCapacityChange— Aurora met à jour de force le cluster 3 jours après la première tentative de correctif.
Comme pour toute modification forcée sans point de mise à l'échelle approprié, votre charge de travail peut être interrompue.
Dans la mesure du possible, Aurora Serverless v1 effectue la maintenance de manière non perturbatrice. Lorsqu'une maintenance est requise, votre Aurora Serverless v1 Le cluster de base de données adapte sa capacité pour gérer les opérations nécessaires. Avant la mise à l'échelle, Aurora Serverless v1 recherche un point d'échelle. Il le fait pendant trois jours au maximum si nécessaire.
À la fin de chaque journée, Aurora Serverless v1 Impossible de trouver un point d'échelle, cela crée un événement de cluster. Cet événement vous informe de la maintenance en attente et de la nécessité de procéder à une mise à l'échelle pour l'effectuer. La notification inclut la date à laquelle Aurora Serverless v1 peut forcer le cluster de base de données à évoluer.
Pour de plus amples informations, veuillez consulter Action de délai d'attente pour les modifications de capacité.
Aurora Serverless v1 et basculement
Si l'instance de base de données d'un Aurora Serverless v1 Le cluster de base de données devient indisponible ou la zone de disponibilité (AZ) dans laquelle il se trouve échoue. Aurora recrée l'instance de base de données dans une autre zone de disponibilité. Cependant, le Aurora Serverless v1 le cluster n'est pas un cluster multi-AZ. En effet, il comporte une instance de base de données unique dans une seule zone de disponibilité. Ce mécanisme de basculement prend donc plus de temps que pour un cluster Aurora avec provisionné ou Aurora Serverless v2 instances. Le Aurora Serverless v1 le temps de basculement n'est pas défini car il dépend de la demande et de la disponibilité de la capacité dans les autres AZs limites des données. Région AWS
Comme Aurora sépare la capacité de calcul et le stockage, le volume de stockage du cluster est réparti sur plusieurs AZs. Vos données restent disponibles même si des pannes affectent l'instance de base de données ou la zone de disponibilité associée.
Aurora Serverless v1 et instantanés
Le volume de cluster pour un Aurora Serverless v1 le cluster est toujours chiffré. Vous pouvez choisir la clé de chiffrement, mais vous ne pouvez pas désactiver le chiffrement. Pour copier ou partager un instantané d'un Aurora Serverless v1 cluster, cryptez l'instantané à l'aide du vôtre. AWS KMS key Pour de plus amples informations, veuillez consulter Copie d'instantanés de clusters de bases. Pour en savoir plus sur le chiffrement et sur Amazon Aurora, consultez Chiffrement d'un cluster de base de données Amazon Aurora
