Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Exemple de modélisation des données relationnelles dans DynamoDB
Cet exemple décrit comment modéliser des données relationnelles dans Amazon DynamoDB. La conception d'une table DynamoDB correspond au schéma de traitement des commandes relationnel illustré dans Modélisation relationnelle. Elle respecte le Modèle de conception de liste adjacente, méthode couramment utilisée pour représenter les structures de données relationnelles dans DynamoDB.
Le modèle de conception nécessite que vous définissiez un ensemble de types d'entités qui coïncident généralement avec les différentes tables du schéma relationnel. Les éléments d'entité sont ensuite ajoutés à la table à l'aide d'une clé primaire composée (partition et tri). La clé de partition de ces éléments d'entité est l'attribut qui identifie de façon unique l'élément et qui est appelé PK de manière générique sur tous les éléments. L'attribut de la clé de tri contient une valeur d'attribut que vous pouvez utiliser pour un index inversé ou un index secondaire global. Il est appelé SK de manière générique.
Vous définissez les entités suivantes, qui prennent en charge le schéma relationnel de saisie des commandes.
-
HR-Employee - PK: EmployeeID, SK: Employee Name
-
HR-Region - PK: RegionID, SK: Region Name
-
HR-Country - PK : CountryId, SK : Nom du pays
-
HR-Location - PK: LocationID, SK: Country Name
-
HR-Job - PK: JobID, SK: Job Title
-
Département des ressources humaines - PK : DepartmentID, SK : DepartmentName
-
OE-Customer - PK : CustomerID, SK : ID AccountRep
-
OE-Order - PK OrderID, SK: CustomerID
-
OE-Product - PK: ProductID, SK: Product Name
-
OE-Warehouse - PK: WarehouseID, SK: Region Name
Une fois ces éléments d'entité ajoutés à la table, vous pouvez définir leurs relations en ajoutant des éléments de bord aux partitions des éléments d'entité. La table suivante illustre cette étape.
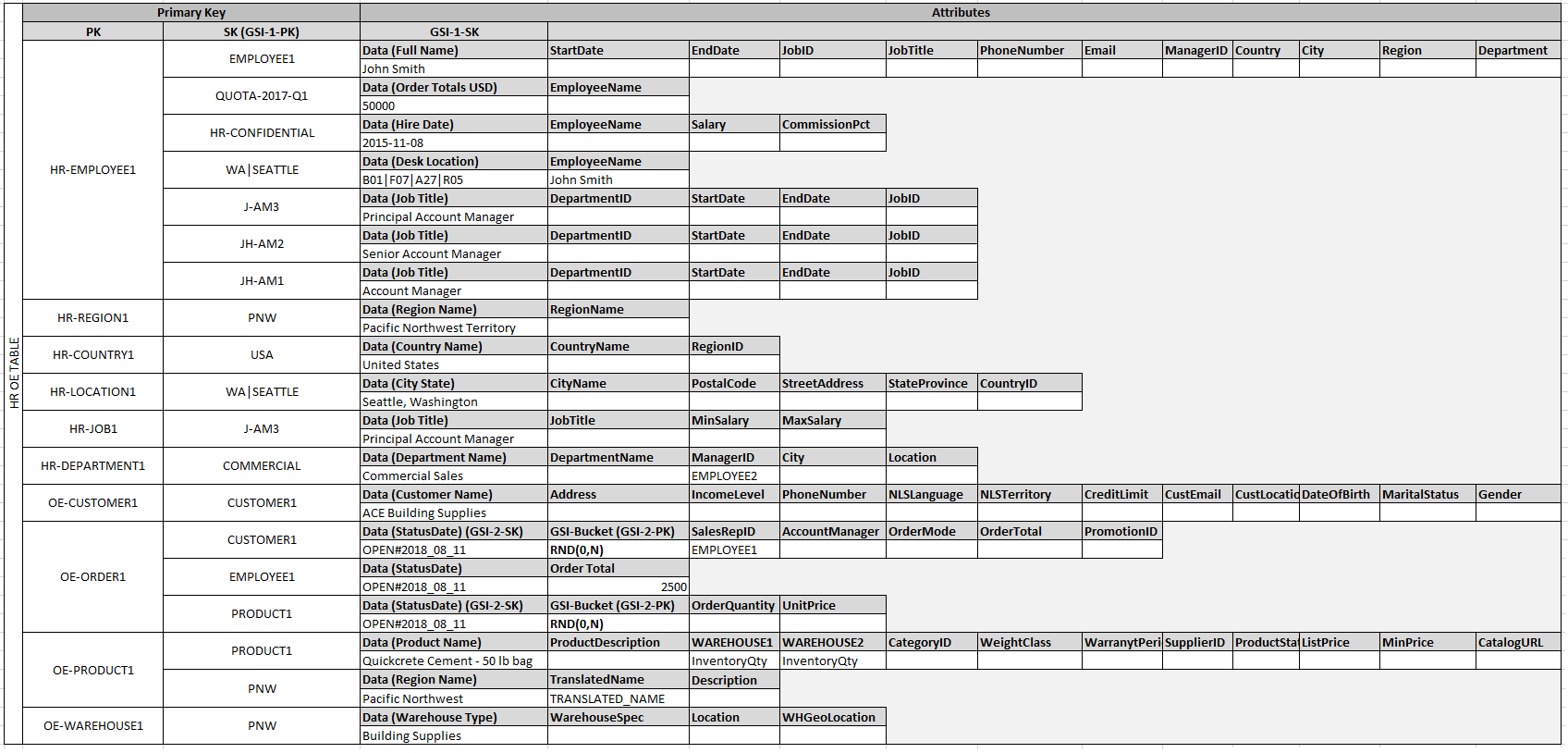
Dans cet exemple, les partitions Employee, Order et Product
Entity de la table disposent d'éléments supplémentaires contenant des pointeurs vers d'autres éléments d'entité de la table. Définissez ensuite quelques index secondaires globaux (GSIs) pour prendre en charge tous les modèles d'accès définis précédemment. Les éléments d'entité n'utilisent pas tous le même type de valeur pour l'attribut de la clé primaire ou l'attribut de la clé de tri. La seule obligation est que les attributs de la clé primaire et de la clé de tri présents soient insérés dans la table.
Le fait que certaines de ces entités utilisent des noms propres et d'autres utilisent d'autres entités IDs comme valeurs de clé de tri permet au même index secondaire global de prendre en charge plusieurs types de requêtes. Cette technique est appelée surcharge d'index secondaire global (GSI). Elle permet de dépasser la limite par défaut de 20 index secondaires globaux pour les tables contenant plusieurs types d'éléments. Ceci est illustré par GSI 1 dans le diagramme suivant :

GSI 2 est conçu pour prendre en charge un schéma d'accès aux applications assez courant, qui consiste à obtenir tous les éléments de la table ayant un état spécifique. Dans le cas d'une grande table dont la répartition des éléments est inégale en termes d'états disponibles, ce modèle d'accès peut entraîner une forte activité, sauf si les éléments sont répartis sur plusieurs partitions logiques pouvant être interrogées en parallèle. Ce modèle de conception s'appelle write sharding.
Pour obtenir ceci pour GSI 2, l'application ajoute l'attribut de la clé primaire de GSI 2 à chaque élément Order. Elle le remplit avec un nombre aléatoire compris dans une plage de 0 à N, où N peut être calculé de façon générique à l'aide de la formule suivante, sauf s'il existe une raison spécifique de faire autrement.
ItemsPerRCU = 4KB / AvgItemSize PartitionMaxReadRate = 3K * ItemsPerRCU N = MaxRequiredIO / PartitionMaxReadRate
Supposons par exemple que vous souhaitez obtenir les résultats suivants :
-
Jusqu'à 2 millions de commandes dans le système, passant à 3 millions en 5 ans.
-
Jusqu'à 20 % de ces commandes seront à l'état OPEN (OUVERT) à un moment donné.
-
L'enregistrement de commande moyen est d'environ 100 octets, avec trois
OrderItemenregistrements dans la partition de commande d'environ 50 octets chacun, ce qui vous donne une taille d'entité de commande moyenne de 250 octets.
Pour cette table, le calcul du facteur N se présenterait comme suit :
ItemsPerRCU = 4KB / 250B = 16 PartitionMaxReadRate = 3K * 16 = 48K N = (0.2 * 3M) / 48K = 13
Dans ce cas, vous devez répartir toutes les commandes sur au moins 13 partitions logiques sur GSI 2 afin de garantir que la lecture de tous les éléments Order dont l'état est OPEN n'entraîne pas de surchauffe de la partition sur la couche du stockage physique. Il est recommandé d'augmenter ce nombre en prévision d'éventuelles anomalies dans l'ensemble de données. Il est donc préférable d'utiliser N = 15. Comme mentionné précédemment, vous le faites en ajoutant la valeur aléatoire de 0 à N à l'attribut PK GSI 2 de chaque registre Order et OrderItem inséré sur la table.
Cette répartition suppose que le modèle d'accès qui nécessite le rassemblement de toutes les factures dont l'état est OPEN a lieu de manière occasionnelle, afin que vous puissiez utiliser la capacité de transmission en mode rafale pour satisfaire la demande. Vous pouvez interroger l'index secondaire global suivant à l'aide d'une condition de clé de tri State et Date Range pour générer un sous-ensemble ou l'ensemble des Orders d'un état donné.

Dans cet exemple, les éléments sont répartis de manière aléatoire sur 15 partitions logiques. Cette structure fonctionne, car le modèle d'accès nécessite qu'un grand nombre d'éléments soient récupérés. Ainsi, il est peu probable qu'aucun des 15 threads renvoie des jeux de résultats vides, ce qui pourrait représenter un gaspillage de capacité. Une requête utilise toujours une unité de capacité de lecture (RCU, read capacity unit) ou une unité de capacité d'écriture (WCU, write capacity unit), même si rien n'est renvoyé ou si aucune donnée n'est écrite.
Si le modèle d'accès nécessite une requête très rapide sur cet index secondaire global qui renvoie un ensemble de résultats fragmenté, il est probablement préférable d'utiliser un algorithme de hachage pour répartir les éléments plutôt qu'un modèle aléatoire. Dans ce cas, vous pouvez sélectionner un attribut connu lorsque la requête est exécutée au moment du runtime, et hacher cet attribut dans un espace de clé 0 à 14 lors de l'insertion des éléments. Ils peuvent ainsi être lus de manière efficace à partir de l'index secondaire global.
Enfin, vous pouvez réexaminer les modèles d'accès définis précédemment. Voici la liste des modèles d'accès et des conditions de requête à utiliser avec la nouvelle version DynamoDB de l'application pour les accueillir.
| S. Non. | Modèles d'accès | Conditions de requête |
|---|---|---|
|
1 |
Rechercher les détails des employés par ID d'employé |
Clé primaire sur la table, ID="HR-EMPLOYEE » |
|
2 |
Interroger les détails des employés par nom d'employé |
Utiliser GSI-1, PK="Nom de l'employé » |
|
3 |
Obtenir uniquement les détails de la tâche actuelle d'un employé |
Clé primaire sur la table, PK=HR-EMPLOYEE-1, SK commence par « JH » |
|
4 |
Obtenir des commandes pour un client pour une plage de dates |
Utilisez GSI-1, PK=, SK="STATUS-DATE »CUSTOMER1, pour chaque StatusCode |
|
5 |
Afficher toutes les commandes en état OUVERT pour une plage de dates pour tous les clients |
Utilisez GSI-2, PK=Query en parallel pour la plage [0.. N], SK entre OpenDate1 et OpenDate2 |
|
6 |
Tous les employés embauchés récemment |
Utilisez GSI-1, PK="HR-CONFIDENTIAL", SK > date1 |
|
7 |
Trouver tous les employés dans un entrepôt spécifique |
Utilisez GSI-1, PK= WAREHOUSE1 |
|
8 |
Obtenir tous les articles de commande d'un produit, y compris les stocks d'entrepôts |
Utilisez GSI-1, PK= PRODUCT1 |
|
9 |
Obtenez des clients par représentant du compte |
Utiliser GSI-1, PK=ACCOUNT-REP |
|
10 |
Obtenir des commandes par représentant du compte et par date |
Utilisez GSI-1, PK=ACCOUNT-REP, SK="STATUS-DATE », pour chaque StatusCode |
|
11 |
Obtenir tous les employés ayant un intitulé de poste spécifique |
Utiliser GSI-1, PK=JOBTITLE |
|
12 |
Obtenir le stock par produit et par entrepôt |
Clé primaire sur la table, PK=OE-PRODUCT1, SK= PRODUCT1 |
|
13 |
Obtenir l'inventaire total des produits |
Clé primaire sur la table, PK=OE-PRODUCT1, SK= PRODUCT1 |
|
14 |
Obtenir le classement des représentants du compte par nombre total de commandes et par période de vente |
Utilisez GSI-1, PK=YYYY-Q1, =False scanIndexForward |
