Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Connecteur Amazon Athena HBase
Le HBase connecteur Amazon Athena permet à Amazon Athena de communiquer avec vos instances HBase Apache afin que vous puissiez interroger HBase vos données avec SQL.
Contrairement aux magasins de données relationnels traditionnels, les HBase collections n'ont pas de schéma défini. HBasene possède pas de magasin de métadonnées. Chaque entrée d'une HBase collection peut comporter des champs et des types de données différents.
Le HBase connecteur prend en charge deux mécanismes pour générer des informations de schéma de table : l'inférence de schéma de base et AWS Glue Data Catalog les métadonnées.
L’inférence de schéma est la valeur par défaut. Cette option analyse un petit nombre de documents de votre collection, réunit tous les champs et impose des champs dont les types de données ne se chevauchent pas. Cette option fonctionne bien pour les collections dont les entrées sont généralement uniformes.
Pour les collections comportant une plus grande variété de types de données, le connecteur prend en charge la récupération de métadonnées à partir du AWS Glue Data Catalog. Si le connecteur détecte une AWS Glue base de données et une table qui correspondent à votre HBase espace de noms et aux noms de collection, il obtient ses informations de schéma dans la AWS Glue table correspondante. Lorsque vous créez votre AWS Glue table, nous vous recommandons d'en faire un sur-ensemble de tous les champs auxquels vous souhaitez accéder depuis votre HBase collection.
Si Lake Formation est activé sur votre compte, le rôle IAM de votre connecteur Lambda fédéré Athena que vous avez déployé dans AWS Serverless Application Repository le doit avoir un accès en lecture dans Lake Formation au. AWS Glue Data Catalog
Ce connecteur peut être enregistré auprès de Glue Data Catalog en tant que catalogue fédéré. Il prend en charge les contrôles d'accès aux données définis dans Lake Formation au niveau du catalogue, de la base de données, de la table, des colonnes, des lignes et des balises. Ce connecteur utilise Glue Connections pour centraliser les propriétés de configuration dans Glue.
Prérequis
Déployez le connecteur sur votre Compte AWS à l’aide de la console Athena ou du AWS Serverless Application Repository. Pour plus d’informations, consultez Création d'une connexion à une source de données ou Utilisez le AWS Serverless Application Repository pour déployer un connecteur de source de données.
Paramètres
Utilisez les paramètres de cette section pour configurer le HBase connecteur.
Note
Les connecteurs de source de données Athena créés le 3 décembre 2024 et les versions ultérieures utilisent AWS Glue des connexions.
Les noms et définitions des paramètres répertoriés ci-dessous concernent les connecteurs de source de données Athena créés avant le 3 décembre 2024. Elles peuvent être différentes de leurs propriétés de AWS Glue connexion correspondantes. À compter du 3 décembre 2024, utilisez les paramètres ci-dessous uniquement lorsque vous déployez manuellement une version antérieure d'un connecteur de source de données Athena.
Nous vous recommandons de configurer un HBase connecteur à l'aide d'un objet de connexions Glue. Pour ce faire, définissez la variable d'glue_connectionenvironnement du HBase connecteur Lambda sur le nom de la connexion Glue à utiliser.
Propriétés des connexions à la colle
Utilisez la commande suivante pour obtenir le schéma d'un objet de connexion Glue. Ce schéma contient tous les paramètres que vous pouvez utiliser pour contrôler votre connexion.
aws glue describe-connection-type --connection-type HBASE
Propriétés de l'environnement Lambda
-
glue_connection — Spécifie le nom de la connexion Glue associée au connecteur fédéré.
Note
-
Tous les connecteurs qui utilisent des connexions Glue doivent être utilisés AWS Secrets Manager pour stocker les informations d'identification.
-
Le HBase connecteur créé à l'aide des connexions Glue ne prend pas en charge l'utilisation d'un gestionnaire de multiplexage.
-
Le HBase connecteur créé à l'aide des connexions Glue ne prend en charge que
ConnectionSchemaVersion2.
-
spill_bucket – Spécifie le compartiment Amazon S3 pour les données qui dépassent les limites des fonctions Lambda.
-
spill_prefix – (Facultatif) Par défaut, il s’agit d’un sous-dossier dans le
spill_bucketspécifié appeléathena-federation-spill. Nous vous recommandons de configurer un cycle de vie de stockage Amazon S3 à cet endroit pour supprimer les déversements supérieurs à un nombre de jours ou d’heures prédéterminé. -
spill_put_request_headers – (Facultatif) Une carte codée au format JSON des en-têtes et des valeurs des demandes pour la demande
putObjectAmazon S3 utilisée pour le déversement (par exemple,{"x-amz-server-side-encryption" : "AES256"}). Pour les autres en-têtes possibles, consultez le PutObjectmanuel Amazon Simple Storage Service API Reference. -
kms_key_id – (Facultatif) Par défaut, toutes les données déversées vers Amazon S3 sont chiffrées à l'aide du mode de chiffrement authentifié AES-GCM et d'une clé générée de manière aléatoire. Pour que votre fonction Lambda utilise des clés de chiffrement plus puissantes générées par KMS, comme
a7e63k4b-8loc-40db-a2a1-4d0en2cd8331, vous pouvez spécifier l’ID d’une clé KMS. -
disable_spill_encryption – (Facultatif) Lorsque la valeur est définie sur
True, le chiffrement des déversements est désactivé. La valeur par défaut estFalseafin que les données déversées vers S3 soient chiffrées à l’aide d’AES-GCM, soit à l’aide d’une clé générée de manière aléatoire soit à l’aide de KMS pour générer des clés. La désactivation du chiffrement des déversements peut améliorer les performances, surtout si votre lieu de déversement utilise le chiffrement côté serveur. -
disable_glue — (Facultatif) S'il est présent et défini sur true, le connecteur ne tente pas de récupérer des métadonnées supplémentaires à partir de. AWS Glue
-
glue_catalog – (Facultatif) Utilisez cette option pour spécifier un catalogue AWS Glue entre compte. Par défaut, le connecteur tente d'obtenir des métadonnées à partir de son propre AWS Glue compte.
-
default_hbase — Le cas échéant, spécifie une chaîne de HBase connexion à utiliser lorsqu'aucune variable d'environnement spécifique au catalogue n'existe.
-
enable_case_insensitive_match — (Facultatif) Lorsque
true, effectue des recherches sans distinction majuscules/minuscules dans les noms de table dans. HBase L’argument par défaut estfalse. À utiliser si votre requête contient des noms de table en majuscules.
Définition des chaînes de connexion
Vous pouvez fournir une ou plusieurs propriétés qui définissent les détails de HBase connexion pour les HBase instances que vous utilisez avec le connecteur. Pour ce faire, définissez une variable d’environnement Lambda qui correspond au nom du catalogue que vous souhaitez utiliser dans Athena. Supposons, par exemple, que vous souhaitiez utiliser les requêtes suivantes pour interroger deux HBase instances différentes provenant d'Athena :
SELECT * FROM "hbase_instance_1".database.table
SELECT * FROM "hbase_instance_2".database.table
Avant de pouvoir utiliser ces deux instructions SQL, vous devez ajouter deux variables d’environnement à votre fonction Lambda : hbase_instance_1 et hbase_instance_2. La valeur de chacun doit être une chaîne de HBase connexion au format suivant :
master_hostname:hbase_port:zookeeper_port
Utilisation de secrets
Vous pouvez éventuellement utiliser AWS Secrets Manager une partie ou la totalité de la valeur pour les détails de votre chaîne de connexion. Pour utiliser la fonctionnalité de requête fédérée d’Athena avec Secrets Manager, le VPC connecté à votre fonction Lambda doit avoir un accès internet
Si vous utilisez la syntaxe ${my_secret} pour mettre le nom d’un secret provenant de Secrets Manager dans votre chaîne de connexion, le connecteur remplace le nom secret par vos valeurs de nom d’utilisateur et de mot de passe provenant de Secrets Manager.
Supposons, par exemple, que vous définissiez la variable d’environnement Lambda pour hbase_instance_1 sur la valeur suivante :
${hbase_host_1}:${hbase_master_port_1}:${hbase_zookeeper_port_1}
Le SDK Athena Query Federation tente automatiquement de récupérer un secret nommé hbase_instance_1_creds à partir de Secrets Manager et d’injecte cette valeur à la place de ${hbase_instance_1_creds}. Toute partie de la chaîne de connexion qui est entourée par la combinaison de caractères ${
} est interprétée comme un secret de Secrets Manager. Si vous spécifiez un nom de secret que le connecteur ne trouve pas dans Secrets Manager, le connecteur ne remplace pas le texte.
Configuration de bases de données et de tables dans AWS Glue
L'inférence de schéma intégrée du connecteur ne prend en charge que les valeurs sérialisées HBase sous forme de chaînes (par exemple,String.valueOf(int)). La capacité d’inférence de schéma intégrée du connecteur étant limitée, vous pouvez souhaiter utiliser plutôt AWS Glue
pour les métadonnées. Pour activer l'utilisation d'une AWS Glue table HBase, vous devez disposer d'une AWS Glue base de données et d'une table dont les noms correspondent à l' HBase espace de noms et à la table pour lesquels vous souhaitez fournir des métadonnées supplémentaires. L'utilisation des conventions de dénomination des familles de HBase colonnes est facultative mais pas obligatoire.
Pour utiliser une AWS Glue table pour des métadonnées supplémentaires
-
Lorsque vous modifiez la table et la base de données dans la AWS Glue console, ajoutez les propriétés de table suivantes :
hbase-metadata-flag— Cette propriété indique au HBase connecteur qu'il peut utiliser la table pour des métadonnées supplémentaires. Vous pouvez fournir n’importe quelle valeur pour
hbase-metadata-flagtant que la propriétéhbase-metadata-flagest présente dans la liste des propriétés de la table.-
hbase-native-storage-flag— Utilisez cet indicateur pour activer ou désactiver les deux modes de sérialisation de valeurs pris en charge par le connecteur. Par défaut, lorsque ce champ n'est pas présent, le connecteur suppose que toutes les valeurs sont stockées HBase sous forme de chaînes. En tant que tel, il tentera d'analyser les types de données tels que
INTBIGINT, etDOUBLEfrom HBase sous forme de chaînes. Si ce champ est défini avec une valeur quelconque de la table AWS Glue, le connecteur passe en mode de stockage « natif » et tente de lireINT,BIGINTBIT, etDOUBLEsous forme d'octets à l'aide des fonctions suivantes :ByteBuffer.wrap(value).getInt() ByteBuffer.wrap(value).getLong() ByteBuffer.wrap(value).get() ByteBuffer.wrap(value).getDouble()
-
Assurez-vous d'utiliser les types de données appropriés AWS Glue tels que listés dans ce document.
Modélisation de familles de colonnes
Le HBase connecteur Athena permet de modéliser des familles de HBase colonnes de deux manières : en les nommant de manière complète (aplatie) ou en utilisant des objetsfamily:column. STRUCT
Dans le modèle STRUCT, le nom du champ STRUCT doit correspondre à la famille de colonnes, tandis que les enfants de STRUCT doivent correspondre aux noms des colonnes de la famille. Cependant, étant donné que les lectures de prédicats poussés vers le bas et en colonnes ne sont pas encore totalement prises en charge pour les types complexes tels que STRUCT, l’utilisation de STRUCT n’est actuellement pas conseillée.
L'image suivante montre une table configurée dans AWS Glue qui utilise une combinaison des deux approches.
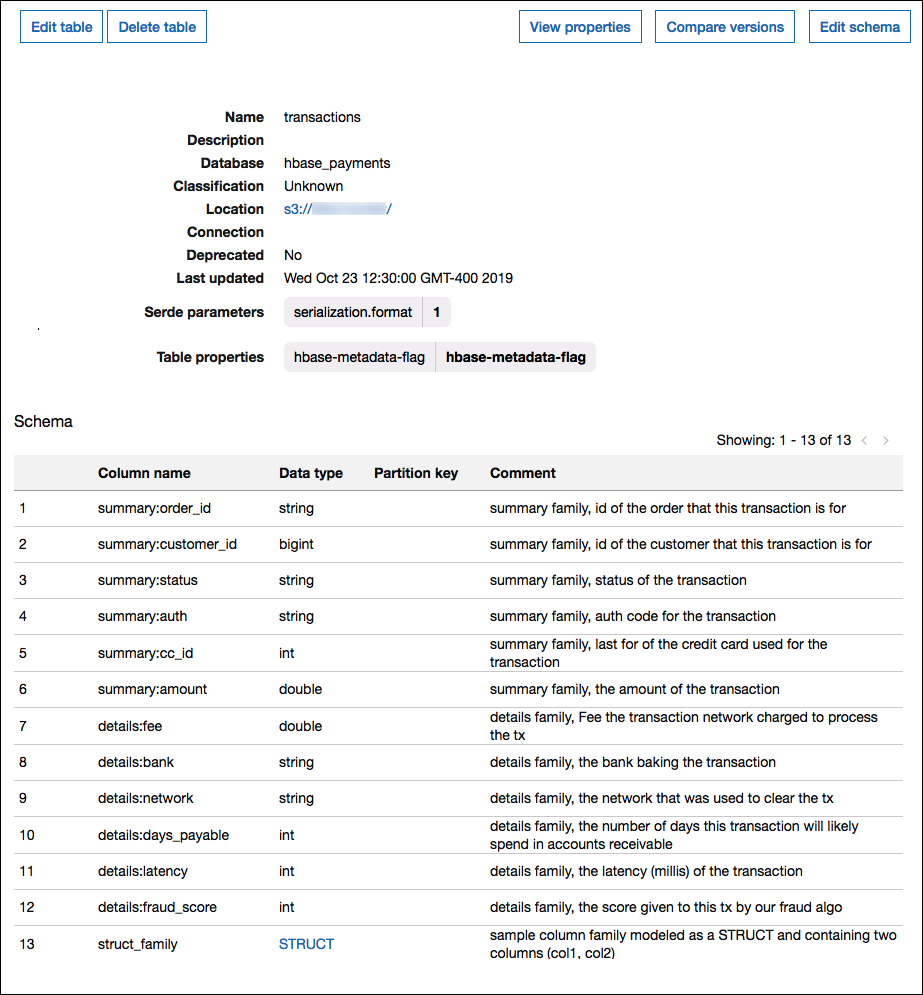
Prise en charge du type de données
Le connecteur récupère toutes les HBase valeurs sous forme de type d'octet de base. Ensuite, en fonction de la façon dont vous avez défini vos tables dans AWS Glue Data Catalog, il mappe les valeurs dans l'un des types de données Apache Arrow du tableau suivant.
| AWS Glue type de données | Type de données Apache Arrow |
|---|---|
| int | INT |
| bigint | BIGINT |
| double | FLOAT8 |
| float | FLOAT4 |
| boolean | BIT |
| binary | VARBINARY |
| chaîne | VARCHAR |
Note
Si vous ne l'utilisez pas AWS Glue pour compléter vos métadonnées, l'inférence du schéma du connecteur utilise uniquement les types de données BIGINTFLOAT8, etVARCHAR.
Autorisations nécessaires
Pour plus de détails sur les politiques IAM requises par ce connecteur, reportez-vous à la section Policies du fichier athena-hbase.yaml
-
Amazon S3 write access (Accès en écriture Amazon S3) – Le connecteur nécessite un accès en écriture à un emplacement dans Amazon S3 pour déverser les résultats à partir de requêtes volumineuses.
-
Athena GetQueryExecution — Le connecteur utilise cette autorisation pour échouer rapidement lorsque la requête Athena en amont est terminée.
-
AWS Glue Data Catalog— Le HBase connecteur nécessite un accès en lecture seule au pour AWS Glue Data Catalog obtenir des informations sur le schéma.
-
CloudWatch Journaux : le connecteur a besoin d'accéder aux CloudWatch journaux pour stocker les journaux.
-
AWS Secrets Manager accès en lecture — Si vous choisissez de stocker les détails du HBase point de terminaison dans Secrets Manager, vous devez autoriser le connecteur à accéder à ces secrets.
-
Accès au VPC : le connecteur doit pouvoir attacher et détacher des interfaces à votre VPC afin qu'il puisse s'y connecter et communiquer avec vos instances. HBase
Performances
Le HBase connecteur Athena tente de paralléliser les requêtes par rapport à votre HBase instance en lisant chaque serveur régional en parallèle. Le HBase connecteur Athena effectue un transfert de prédicat vers le bas pour réduire le nombre de données scannées par la requête.
La fonction Lambda effectue également une poussée vers le bas de projection pour réduire les données analysées par la requête. Cependant, la sélection d'un sous-ensemble de colonnes entraîne parfois un allongement du temps d'exécution des requêtes. LIMITles clauses réduisent la quantité de données numérisées, mais si vous ne fournissez pas de prédicat, vous devez vous attendre à ce que les SELECT requêtes contenant une LIMIT clause analysent au moins 16 Mo de données.
HBase est sujet à des échecs de requêtes et à des temps d'exécution variables. Vous devrez peut-être réessayer vos requêtes plusieurs fois pour qu'elles aboutissent. Le HBase connecteur résiste à l'étranglement dû à la simultanéité.
Requêtes passthrough
Le HBase connecteur prend en charge les requêtes passthrough et est basé sur NoSQL. Pour plus d'informations sur l'interrogation d'Apache HBase à l'aide du filtrage, consultez la section Langage des filtres
Pour utiliser des requêtes directes avec HBase, utilisez la syntaxe suivante :
SELECT * FROM TABLE( system.query( database => 'database_name', collection => 'collection_name', filter => '{query_syntax}' ))
L'exemple suivant filtre les HBase requêtes directes pour les employés âgés de 24 ou 30 ans au sein de la employee collection de la default base de données.
SELECT * FROM TABLE( system.query( DATABASE => 'default', COLLECTION => 'employee', FILTER => 'SingleColumnValueFilter(''personaldata'', ''age'', =, ''binary:30'')' || ' OR SingleColumnValueFilter(''personaldata'', ''age'', =, ''binary:24'')' ))
Informations de licence
Le projet de HBase connecteur Amazon Athena est concédé sous licence Apache-2.0
Ressources supplémentaires
Pour plus d'informations sur ce connecteur, rendez-vous sur le site correspondant
