Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
AWS Clean Rooms ML
AWS Clean Rooms ML permet à deux ou plusieurs parties d'exécuter des modèles d'apprentissage automatique sur leurs données sans avoir à partager leurs données entre elles. Le service fournit des contrôles renforçant la confidentialité qui permettent aux propriétaires de données de protéger leurs données et leur adresse IP de modèle. Vous pouvez utiliser des AWS modèles créés par des créateurs ou apporter votre propre modèle personnalisé.
Pour une explication plus détaillée de son fonctionnement, voirEmplois multi-comptes.
Pour plus d'informations sur les fonctionnalités des modèles Clean Rooms ML, consultez les rubriques suivantes.
Rubriques
Terminologie AWS Clean Rooms ML
Il est important de comprendre la terminologie suivante lors de l'utilisation de Clean Rooms ML :
-
Fournisseur de données de formation : partie qui fournit les données de formation, crée et configure un modèle similaire, puis associe ce modèle similaire à une collaboration.
-
Fournisseur de données sur les semences : partie qui fournit les données sur les semences, génère un segment similaire et exporte son segment similaire.
-
Données d'entraînement : données du fournisseur de données de formation, utilisées pour générer un modèle similaire. Les données d'entraînement sont utilisées pour mesurer la similitude des comportements des utilisateurs.
Les données d'entraînement doivent contenir un ID utilisateur, un ID d'élément et une colonne d'horodatage. Les données d'entraînement peuvent éventuellement contenir d'autres interactions sous forme de caractéristiques numériques ou catégoriques. Des exemples d'interactions sont une liste de vidéos regardées, d'articles achetés ou d'articles lus.
-
Données de départ : données du fournisseur de données de départ, utilisées pour créer un segment similaire. Les données de départ peuvent être fournies directement ou elles peuvent provenir des résultats d'une AWS Clean Rooms requête. Le résultat du segment similaire est un ensemble d'utilisateurs issu des données d'entraînement qui ressemble le plus aux utilisateurs initiaux.
-
Modèle similaire : modèle d'apprentissage automatique des données d'entraînement utilisé pour rechercher des utilisateurs similaires dans d'autres ensembles de données.
Lors de l'utilisation de l'API, le terme modèle d'audience est utilisé de la même manière que modèle similaire. Par exemple, vous utilisez l'CreateAudienceModelAPI pour créer un modèle similaire.
-
Segment similaire : sous-ensemble des données d'entraînement qui ressemble le plus aux données de départ.
Lorsque vous utilisez l'API, vous créez un segment similaire avec l'StartAudienceGenerationJobAPI.
Les données du fournisseur de données de formation ne sont jamais partagées avec le fournisseur de données de départ et les données du fournisseur de données de départ ne sont jamais partagées avec le fournisseur de données de formation. La sortie du segment similaire est partagée avec le fournisseur de données de formation, mais jamais avec le fournisseur de données de départ.
Comment AWS Clean Rooms ML fonctionne avec les AWS modèles
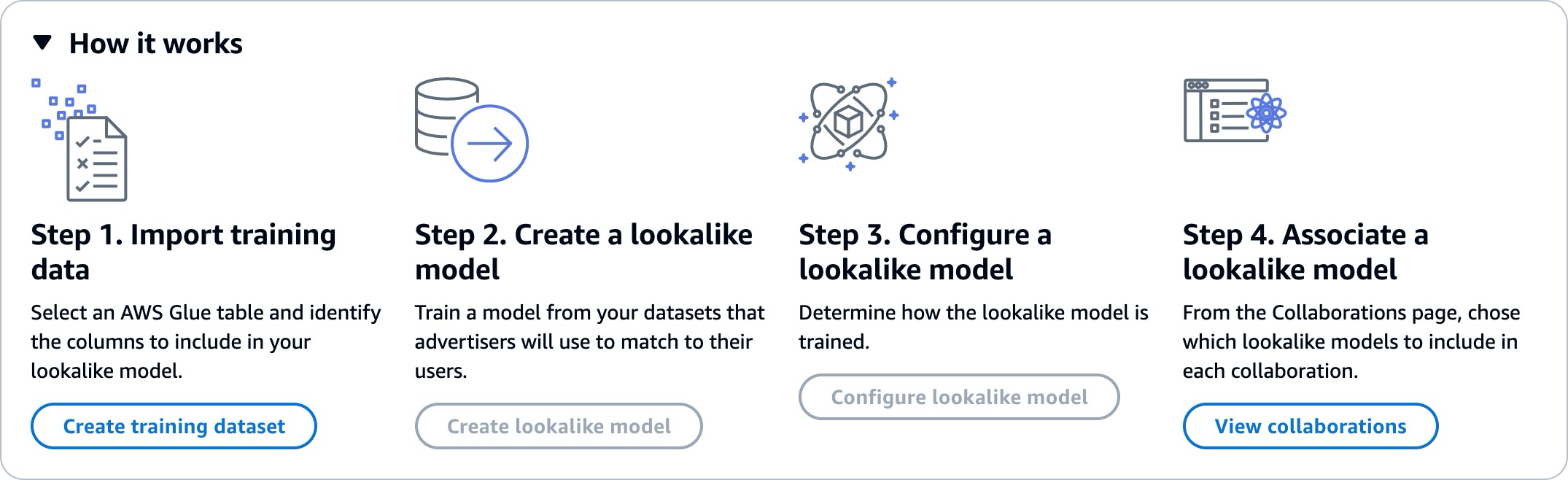
L'utilisation de modèles similaires nécessite que deux parties, un fournisseur de données de formation et un fournisseur de données de départ, travaillent de manière séquentielle AWS Clean Rooms pour intégrer leurs données dans une collaboration. Il s'agit du flux de travail que le fournisseur de données de formation doit effectuer en premier :
-
Les données du fournisseur de données de formation doivent être stockées dans une table de catalogue de AWS Glue données répertoriant les interactions entre les utilisateurs et les éléments. Les données d'entraînement doivent au minimum contenir une colonne d'ID utilisateur, une colonne d'identifiant d'interaction et une colonne d'horodatage.
-
Le fournisseur de données de formation enregistre les données de formation auprès de AWS Clean Rooms.
-
Le fournisseur de données de formation crée un modèle similaire qui peut être partagé avec plusieurs fournisseurs de données initiales. Le modèle similaire est un réseau neuronal profond dont l'entraînement peut prendre jusqu'à 24 heures. Il n'est pas automatiquement réentraîné et nous vous recommandons de le réentraîner chaque semaine.
-
Le fournisseur de données de formation configure le modèle de similarité, notamment en indiquant s'il convient de partager les indicateurs de pertinence et l'emplacement des segments de sortie sur Amazon S3. Le fournisseur de données de formation peut créer plusieurs modèles similaires configurés à partir d'un seul modèle similaire.
-
Le fournisseur de données de formation associe le modèle d'audience configuré à une collaboration partagée avec un fournisseur de données de départ.
Il s'agit du flux de travail que le fournisseur de données de départ doit ensuite effectuer :
-
Les données du fournisseur de données de base peuvent être stockées dans un compartiment Amazon S3 ou peuvent provenir des résultats d'une requête.
-
Le fournisseur de données de départ ouvre la collaboration qu'il partage avec le fournisseur de données de formation.
-
Le fournisseur de données de départ crée un segment similaire à partir de l'onglet Clean Rooms ML de la page de collaboration.
-
Le fournisseur de données de base peut évaluer les indicateurs de pertinence, s'ils ont été partagés, et exporter le segment similaire pour une utilisation en dehors AWS Clean Rooms.
Comment AWS Clean Rooms ML fonctionne avec les modèles personnalisés
Avec Clean Rooms ML, les membres d'une collaboration peuvent utiliser un algorithme de modèle personnalisé dockerisé stocké dans Amazon ECR pour analyser conjointement leurs données. Pour ce faire, le fournisseur de modèles doit créer une image et la stocker dans Amazon ECR. Suivez les étapes décrites dans le guide de l'utilisateur d'Amazon Elastic Container Registry pour créer un référentiel privé qui contiendra le modèle de ML personnalisé.
Tout membre d'une collaboration peut être le fournisseur de modèles, à condition de disposer des autorisations appropriées. Tous les membres d'une collaboration peuvent apporter des données d'entraînement, des données d'inférence ou les deux au modèle. Aux fins du présent guide, les membres fournissant des données sont appelés fournisseurs de données. Le membre qui crée la collaboration est le créateur de la collaboration, et ce membre peut être le fournisseur de modèles, l'un des fournisseurs de données ou les deux.
Au plus haut niveau, voici les étapes à suivre pour effectuer une modélisation ML personnalisée :
-
Le créateur de la collaboration crée une collaboration et attribue à chaque membre les capacités et la configuration de paiement appropriées. Le créateur de la collaboration doit attribuer au membre la capacité de recevoir les sorties du modèle ou de recevoir les résultats d'inférence au membre approprié au cours de cette étape, car il ne peut pas être mis à jour une fois la collaboration créée. Pour de plus amples informations, veuillez consulter Création et adhésion à la collaboration dans AWS Clean Rooms ML.
-
Le fournisseur de modèles configure et associe son modèle de machine learning conteneurisé à la collaboration et veille à ce que des contraintes de confidentialité soient définies pour les données exportées. Pour de plus amples informations, veuillez consulter Configuration d'un algorithme de modèle dans AWS Clean Rooms ML.
-
Les fournisseurs de données fournissent leurs données à la collaboration et veillent à ce que leurs besoins en matière de confidentialité soient spécifiés. Les fournisseurs de données doivent autoriser le modèle à accéder à leurs données. Pour plus d’informations, consultez Contribution de données de formation dans AWS Clean Rooms ML et Associer l'algorithme du modèle configuré dans AWS Clean Rooms ML.
-
Un membre de la collaboration crée la configuration ML, qui définit l'endroit vers lequel les artefacts du modèle ou les résultats d'inférence sont exportés.
-
Un membre de la collaboration crée un canal d'entrée ML qui fournit des informations au conteneur de formation ou au conteneur d'inférence. Le canal d'entrée ML est une requête qui définit les données à utiliser dans le contexte de l'algorithme du modèle.
-
Un membre de la collaboration invoque l'entraînement du modèle à l'aide du canal d'entrée ML et de l'algorithme de modèle configuré. Pour de plus amples informations, veuillez consulter Création d'un modèle entraîné dans AWS Clean Rooms ML.
-
(Facultatif) Le modèle d'entraînement lance la tâche d'exportation du modèle et les artefacts du modèle sont envoyés au récepteur des résultats du modèle. Seuls les membres dotés d'une configuration ML valide et capables de recevoir les résultats du modèle peuvent recevoir des artefacts du modèle. Pour de plus amples informations, veuillez consulter Exportation d'artefacts de modèles depuis AWS Clean Rooms ML.
-
(Facultatif) Un membre de la collaboration invoque l'inférence de modèle à l'aide du canal d'entrée ML, de l'ARN du modèle entraîné et de l'algorithme de modèle configuré par inférence. Les résultats d'inférence sont envoyés au récepteur de sortie d'inférence. Seuls les membres dotés d'une configuration ML valide et capables de recevoir des résultats d'inférence peuvent recevoir des résultats d'inférence.
Voici les étapes qui doivent être effectuées par le fournisseur de modèles :
-
Créez une image de docker Amazon ECR compatible avec l' SageMaker IA. Clean Rooms ML ne prend en charge que les images docker compatibles avec l' SageMaker IA.
-
Après avoir créé une image docker compatible avec l' SageMaker IA, transférez-la vers Amazon ECR. Suivez les instructions du guide de l'utilisateur d'Amazon Elastic Container Registry pour créer une image de formation sur les conteneurs.
-
Configurez l'algorithme du modèle à utiliser dans Clean Rooms ML.
-
Fournissez le lien du référentiel Amazon ECR et tous les arguments nécessaires pour configurer l'algorithme du modèle.
-
Fournissez un rôle d'accès au service qui permet à Clean Rooms ML d'accéder au référentiel Amazon ECR.
-
Associez l'algorithme du modèle configuré à la collaboration. Cela inclut la fourniture d'une politique de confidentialité qui définit les contrôles pour les journaux des conteneurs, les journaux des défaillances, CloudWatch les métriques et les limites relatives à la quantité de données pouvant être exportées à partir des résultats des conteneurs.
-
Voici les étapes que le fournisseur de données doit suivre pour collaborer avec un modèle de machine learning personnalisé :
-
Configurez une AWS Glue table existante avec une règle d'analyse personnalisée. Cela permet à un ensemble spécifique de requêtes préapprouvées ou de comptes préapprouvés d'utiliser vos données.
-
Associez votre table configurée à une collaboration et fournissez un rôle d'accès au service qui peut accéder à vos AWS Glue tables.
-
Ajoutez une règle d'analyse de collaboration à la table qui permet à l'association d'algorithmes du modèle configuré d'accéder à la table configurée.
-
Une fois le modèle et les données associés et configurés dans Clean Rooms ML, le membre capable d'exécuter des requêtes fournit une requête SQL et sélectionne l'algorithme du modèle à utiliser.
Une fois l'entraînement du modèle terminé, ce membre lance l'exportation des artefacts d'entraînement du modèle ou des résultats d'inférence. Ces artefacts ou résultats sont envoyés au membre capable de recevoir les résultats du modèle entraîné. Le récepteur des résultats doit les configurer MachineLearningConfiguration avant de pouvoir recevoir la sortie du modèle.
