Amazon Managed Service for Apache Flink (Amazon MSF) was previously known as Amazon Kinesis Data Analytics for Apache Flink.
What is Amazon Managed Service for Apache Flink?
With Amazon Managed Service for Apache Flink, you can use Java, Scala, Python, or SQL to process and analyze streaming data. The service enables you to author and run code against streaming sources and static sources to perform time-series analytics, feed real-time dashboards, and metrics.
You can build applications with the language of your choice in Managed Service for Apache Flink using open-source libraries based on Apache Flink
Managed Service for Apache Flink provides the underlying infrastructure for your Apache Flink applications. It handles core capabilities like provisioning compute resources, AZ failover resilience, parallel computation, automatic scaling, and application backups (implemented as checkpoints and snapshots). You can use the high-level Flink programming features (such as operators, functions, sources, and sinks) in the same way that you use them when hosting the Flink infrastructure yourself.
Decide between using Managed Service for Apache Flink or Managed Service for Apache Flink Studio
You have two options for running your Flink jobs with Amazon Managed Service for Apache Flink. With Managed Service for Apache Flink, you build Flink applications in Java, Scala, or Python (and embedded SQL) using an IDE of your choice and the Apache Flink Datastream or Table APIs. With Managed Service for Apache Flink Studio, you can interactively query data streams in real time and easily build and run stream processing applications using standard SQL, Python, and Scala.
You can select which method that best suits your use case. If you are unsure, this section will offer high level guidance to help you.
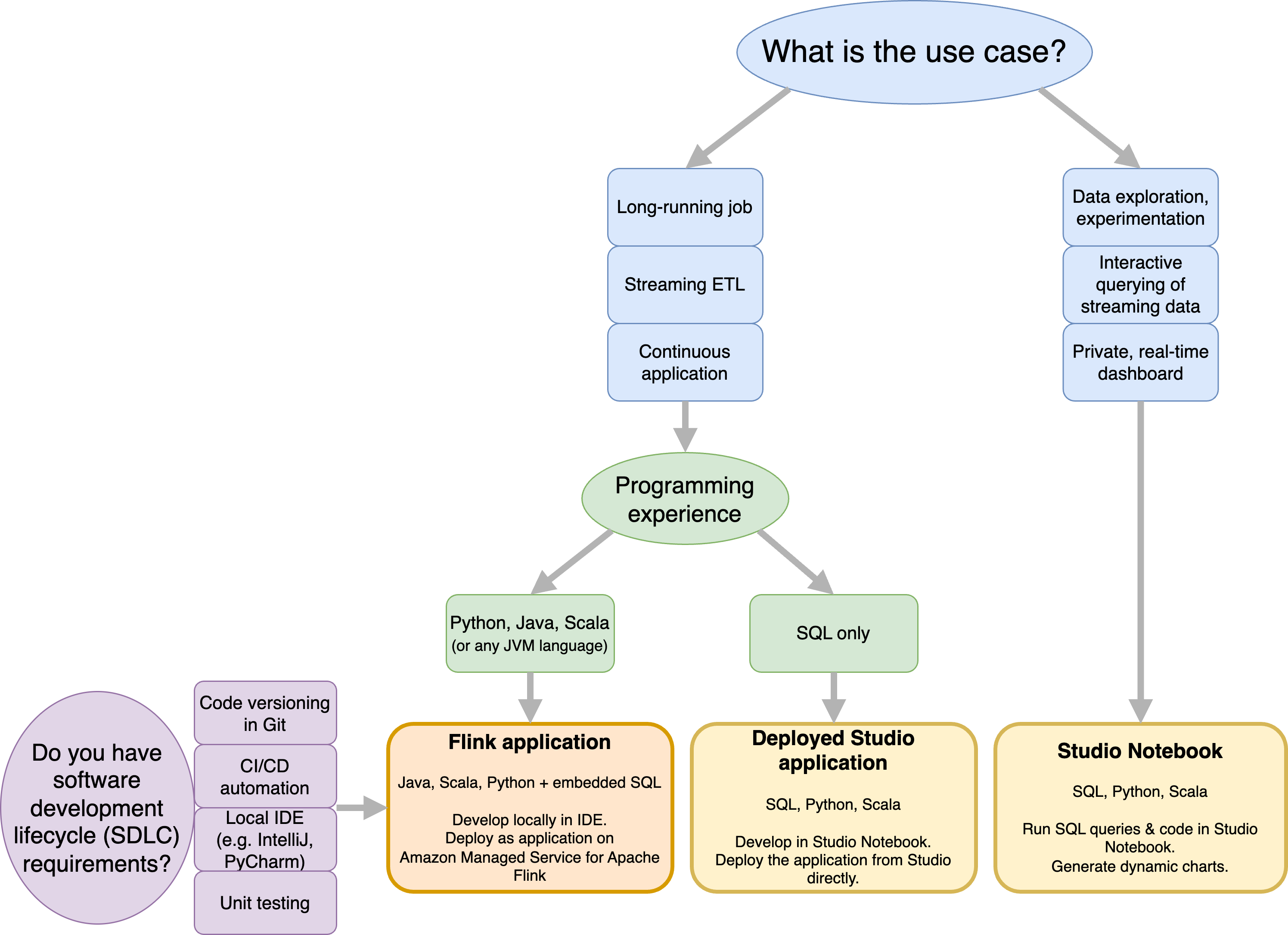
Before deciding on whether to use Amazon Managed Service for Apache Flink or Amazon Managed Service for Apache Flink Studio you should consider your use case.
If you plan to operate a long running application that will undertake workloads such as Streaming ETL or Continuous Applications, you should consider using Managed Service for Apache Flink. This is because you are able to create your Flink application using the Flink APIs directly in the IDE of your choice. Developing locally with your IDE also ensures you can leverage software development lifecycle (SDLC) common processes and tooling such as code versioning in Git, CI/CD automation, or unit testing.
If you are interested in ad-hoc data exploration, want to query streaming data interactively, or create private real-time dashboards, Managed Service for Apache Flink Studio will help you meet these goals in just a few clicks. Users familiar with SQL can consider deploying a long-running application from Studio directly.
Note
You can promote your Studio notebook to a long-running application. However, if you want to integrate with your SDLC tools such as code versioning on Git and CI/CD automation, or techniques such as unit-testing, we recommend Managed Service for Apache Flink using the IDE of your choice.
Choose which Apache Flink APIs to use in Managed Service for Apache Flink
You can build applications using Java, Python, and Scala in Managed Service for Apache Flink using Apache Flink APIs in an IDE of your choice. You can find guidance on how to build applications using the Flink Datastream and Table API in the documentation. You can select the language you create your Flink application in and the APIs you use to best meet the needs of your application and operations. If you are unsure, this section provides high level guidance to help you.
Choose a Flink API
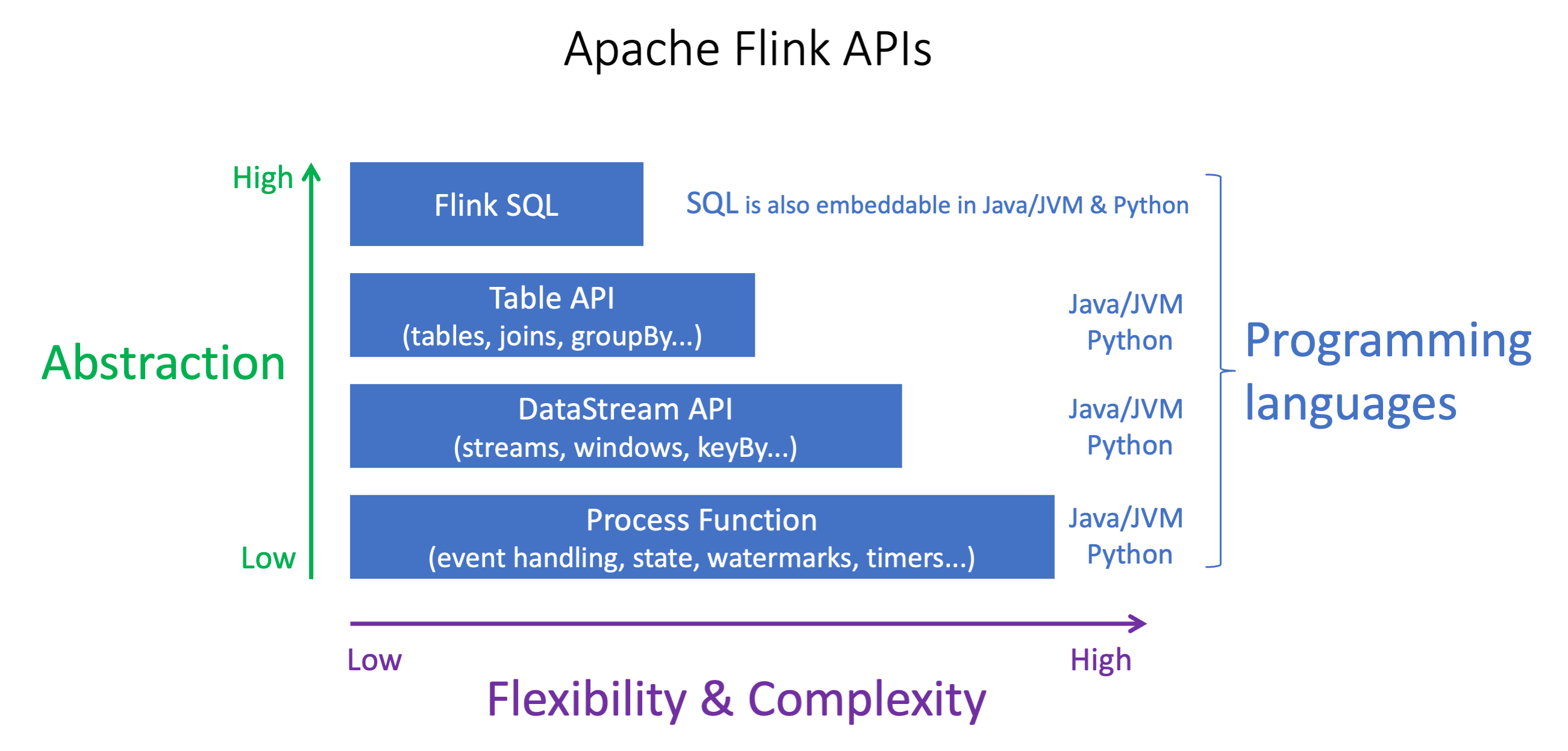
The Apache Flink APIs have differing levels of abstraction that may effect how you decide to build your application.
They are expressive and flexible and can be used together to build your application. You do not have to use only one Flink API.
You can learn more about the Flink APIs in the Apache Flink documentation
Flink offers four levels of API abstraction: Flink SQL, Table API, DataStream API, and Process Function, which is used in conjunction with the DataStream API. These are all supported in Amazon Managed Service for Apache Flink. It is advisable to start with a higher level of abstraction where possible, however some Flink features are only available with the Datastream API where you can create your application in Java, Python, or Scala. You should consider using the Datastream API if:
You require fine-grained control over state
You want to leverage the ability to call an external database or endpoint asynchronously (for example for inference)
You want to use custom timers (for example to implement custom windowing or late event handling)
-
You want to be able to modify the flow of your application without resetting the state
Note
Choosing a language with the DataStream API:
SQL can be embedded in any Flink application, regardless the programming language chosen.
If you are if planning to use the DataStream API, not all connectors are supported in Python.
If you need low-latency/high-throughput you should consider Java/Scala regardless the API.
If you plan to use Async IO in the Process Functions API you will need to use Java.
The choice of the API can also impact your ability to evolve the application
logic without having to reset the state. This depends on a specific feature, the
ability to set UID on operators, that is only available in the
DataStream API for both Java and Python. For more information,
see Set UUIDs For All Operators
Get started with streaming data applications
You can start by creating a Managed Service for Apache Flink application that continuously reads and processes streaming data. Then, author your code using your IDE of choice, and test it with live streaming data. You can also configure destinations where you want Managed Service for Apache Flink to send the results.
To get started, we recommend that you read the following sections:
Altenatively, you can start by creating a Managed Service for Apache Flink Studio notebook that allows you to interactively query data streams in real time, and easily build and run stream processing applications using standard SQL, Python, and Scala. With a few clicks in the AWS Management Console, you can launch a serverless notebook to query data streams and get results in seconds. To get started, we recommend that you read the following sections:
