Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Gestion des dépendances Lambda à l’aide de couches
Une couche Lambda est une archive de fichier .zip qui contient du code ou des données supplémentaires. Les couches contiennent généralement des dépendances de bibliothèque, une exécution personnalisée, ou des fichiers de configuration.
Vous pouvez envisager d'utiliser des couches pour plusieurs raisons :
-
Pour réduire la taille de vos packages de déploiement. Au lieu d'inclure toutes vos dépendances de fonctions avec votre code de fonction dans votre package de déploiement, placez-les dans une couche. Cela permet de maintenir la taille et l'organisation des packages de déploiement.
-
Pour séparer la logique des fonctions de base des dépendances. Avec les couches, vous pouvez mettre à jour les dépendances de vos fonctions indépendamment du code de votre fonction, et vice versa. Cela favorise la séparation des préoccupations et vous aide à vous concentrer sur la logique de votre fonction.
-
Pour partager les dépendances entre plusieurs fonctions. Après avoir créé une couche, vous pouvez l'appliquer à un certain nombre de fonctions de votre compte. Sans couches, vous devez inclure les mêmes dépendances dans chaque package de déploiement individuel.
-
Pour utiliser l'éditeur de code de la console Lambda. L'éditeur de code est un outil utile pour tester rapidement les mises à jour mineures du code des fonctions. Toutefois, vous ne pouvez pas utiliser l'éditeur si la taille de votre package de déploiement est trop importante. L'utilisation de couches réduit la taille de votre package et peut débloquer l'utilisation de l'éditeur de code.
-
Pour verrouiller une version du SDK intégré. Les SDK intégrés peuvent être modifiés sans préavis au fur et à mesure de la AWS sortie de nouveaux services et fonctionnalités. Vous pouvez verrouiller une version du kit SDK en créant une couche Lambda avec la version spécifique requise. La fonction utilise alors toujours la version de la couche, même si la version intégrée au service change.
Si vous utilisez des fonctions Lambda dans Go ou Rust, nous vous déconseillons d’utiliser des couches. Le code des fonctions Go et Rust est fourni sous la forme d’un exécutable, qui contient le code compilé de la fonction ainsi que toutes ses dépendances. Placer vos dépendances dans une couche oblige votre fonction à charger manuellement des assemblages supplémentaires pendant la phase d’initialisation, ce qui peut augmenter les temps de démarrage à froid. Pour des performances optimales pour les fonctions Go et Rust, incluez vos dépendances dans votre package de déploiement.
Le diagramme suivant illustre les différences architecturales de haut niveau entre deux fonctions qui partagent des dépendances. L'un utilise des couches Lambda, l'autre non.
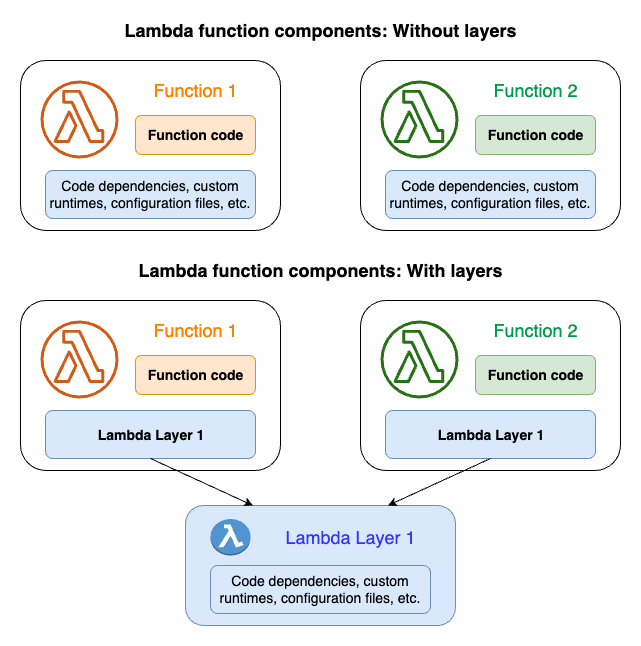
Lorsque vous ajoutez une couche à une fonction, Lambda extrait le contenu de la couche dans le répertoire /opt de l'environnement d'exécution de votre fonction. Toutes les exécutions Lambda prises en charge en mode natif incluent des chemins vers des répertoires spécifiques dans le répertoire /opt. Cela permet à votre fonction d'accéder au contenu de votre couche. Pour plus d'informations sur ces chemins spécifiques et sur la manière d'empaqueter correctement vos couches, consultez Empaquetage du contenu de votre couche.
Vous pouvez inclure jusqu’à cinq couches par fonction. En outre, vous ne pouvez utiliser des couches qu'avec des fonctions Lambda déployées en tant qu'archive de fichiers .zip. Pour des fonctions définies en tant qu'image de conteneur, créez un package avec votre exécution préférée et toutes les dépendances de code lorsque vous créez l'image de conteneur. Pour plus d'informations, consultez la section Utilisation de couches et d'extensions Lambda dans des images de conteneur
Rubriques
Utilisation des couches
Pour créer une couche, empaquetez vos dépendances dans un fichier .zip, de la même manière que vous créer un package de déploiement normal. Plus précisément, le processus général de création et d'utilisation de couches comporte les trois étapes suivantes :
-
Empaquetez d'abord le contenu de votre couche. Cela implique de créer une archive de fichiers .zip. Pour de plus amples informations, veuillez consulter Empaquetage du contenu de votre couche.
-
Créez ensuite la couche dans Lambda. Pour de plus amples informations, veuillez consulter Création et suppression de couches dans Lambda.
-
Ajoutez la couche à vos fonctions. Pour de plus amples informations, veuillez consulter Ajout de couches aux fonctions.
Couches et versions de couches
Une version de couche est un instantané immuable d'une version spécifique d'une couche. Lorsque vous créez une nouvelle couche, Lambda crée une nouvelle version de couche avec un numéro de version de 1. Chaque fois que vous publiez une mise à jour de la couche, Lambda incrémente le numéro de version et crée une nouvelle version de couche.
Chaque version de couche est identifiée par un Amazon Resource Name (ARN) unique. Lorsque vous ajoutez une couche à la fonction, vous devez spécifier la version de couche exacte que vous voulez utiliser (par exemple arn:aws:lambda:us-east-1:123456789012:layer:my-layer:).1
