Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Comprendre le cycle de vie de l'environnement d'exécution Lambda
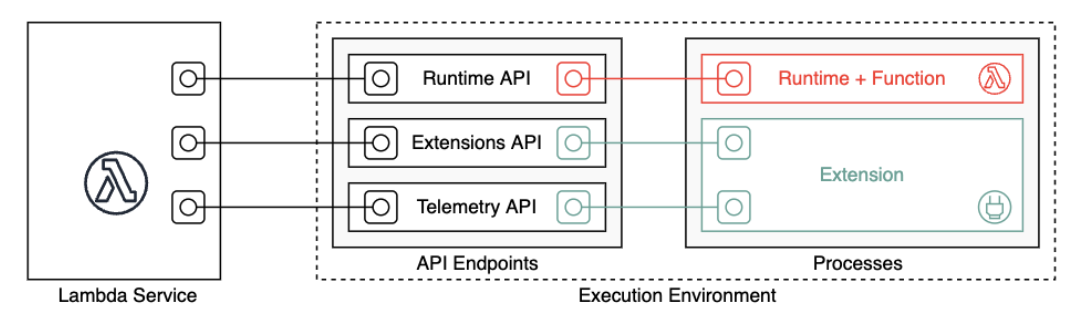
Lambda invoque votre fonction dans un environnement d’exécution, qui fournit un environnement d’exécution sécurisé et isolé. L’environnement d’exécution gère les ressources nécessaires à l’exécution de votre fonction. L’environnement d’exécution prend également en charge le cycle de vie pour l’exécution de la fonction et pour toutes les extensions externes associées à votre fonction.
Le runtime de la fonction communique avec Lambda à l'aide du Runtime. API Les extensions communiquent avec Lambda à l'aide des extensions. API Les extensions peuvent également recevoir des messages de journal et d'autres données télémétriques de la fonction à l'aide de la télémétrie. API
Lorsque vous créez votre fonction Lambda, vous précisez des informations de configuration, telles que la quantité de mémoire disponible et le temps d’exécution maximum autorisé pour votre fonction. Lambda utilise ces informations pour configurer l’environnement d’exécution.
L’exécution de la fonction et chaque extension externe sont des processus qui s’exécutent dans l’environnement d’exécution. Les autorisations, les ressources, les informations d’identification et les variables d’environnement sont partagées entre la fonction et les extensions.
Cycle de vie d’un environnement d’exécution Lambda

Chaque phase commence par un événement que Lambda envoie à l’exécution et à toutes les extensions enregistrées. Le runtime et chaque extension indiquent l'achèvement en envoyant une Next API demande. Lambda gèle l’environnement d’exécution lorsque l’exécution de chaque extension est terminée, et qu’il n’y a pas d’événement en attente.
Rubriques
Phase d’initialisation
Dans la phase Init, Lambda effectue trois tâches :
-
Démarrage de toutes les extensions (
Extension init) -
Amorçage de l’exécution (
Runtime init) -
Exécution du code statique de la fonction (
Function init) -
Exécutez tous les hooks beforeCheckpoint d'exécution (Lambda uniquement SnapStart )
La Init phase se termine lorsque le moteur d'exécution et toutes les extensions signalent qu'elles sont prêtes en envoyant une Next API demande. La phase Init est limitée à 10 secondes. Si les trois tâches ne se terminent pas dans les 10 secondes, Lambda relance la phase Init au moment de la première invocation de fonction avec le délai d’attente de fonction configuré.
Lorsque Lambda SnapStart est activé, la phase Init se produit lorsque vous publiez une version de la fonction. Lambda enregistre un instantané de l’état de la mémoire et du disque de l’environnement d’exécution initialisé, fait persister l’instantané chiffré et le met en cache pour un accès à faible latence. Si vous avez un hook d’exécution beforeCheckpoint, le code s’exécute à la fin de la phase Init.
Note
Le délai de 10 secondes ne s'applique pas aux fonctions qui utilisent la simultanéité provisionnée ou. SnapStart Pour la simultanéité et les SnapStart fonctions configurées, votre code d'initialisation peut s'exécuter pendant 15 minutes maximum. Le délai d’attente est de 130 secondes ou le délai d’expiration de la fonction configurée (900 secondes au maximum), la valeur la plus élevée étant retenue.
Lorsque vous utilisez la simultanéité provisionnée, Lambda initialise l’environnement d’exécution lorsque vous configurez les paramètres du PC pour une fonction. Lambda garantit également que les environnements d’exécution initialisés sont toujours disponibles avant les invocations. Vous pouvez constater des écarts entre les phases d’initialisation et d’invocation de votre fonction. En fonction de la configuration d’environnement d’exécution et de mémoire de votre fonction, vous pouvez également constater une variabilité de latence est possible lors de la première invocation dans un environnement d’exécution initialisé.
Pour les fonctions utilisant la simultanéité à la demande, Lambda peut occasionnellement initialiser les environnements d’exécution avant les demandes d’invocation. Lorsque cela se produit, vous pouvez également observer un intervalle de temps inattendu entre les phases d’initialisation et d’invocation de votre fonction. Nous vous recommandons de ne pas dépendre de ce comportement.
Échecs pendant la phase d’initialisation
Si une fonction se bloque ou expire pendant la phase Init, Lambda émet des informations d’erreur dans le journal INIT_REPORT.
Exemple — INIT _ REPORT enregistre le délai d'expiration
INIT_REPORT Init Duration: 1236.04 ms Phase: init Status: timeout
Exemple — INIT _ REPORT log en cas d'échec de l'extension
INIT_REPORT Init Duration: 1236.04 ms Phase: init Status: error Error Type: Extension.Crash
Si la Init phase est réussie, Lambda n'émet pas le INIT_REPORT journal, sauf s'il est activé. SnapStart SnapStart les fonctions émettent toujoursINIT_REPORT. Pour de plus amples informations, veuillez consulter Surveillance pour Lambda SnapStart.
Phase de restauration (Lambda uniquement SnapStart )
Lorsque vous appelez une SnapStartfonction pour la première fois et que celle-ci évolue, Lambda reprend les nouveaux environnements d'exécution à partir de l'instantané persistant au lieu d'initialiser la fonction à partir de zéro. Si vous avez un hook d’exécution afterRestore(), le code s’exécute à la fin de la phase Restore. Vous êtes facturé pour la durée des hooks d’exécution afterRestore(). Le runtime (JVM) doit se charger et les hooks afterRestore() d'exécution doivent se terminer dans le délai imparti (10 secondes). Sinon, vous obtiendrez un SnapStartTimeoutException. Lorsque la phase Restore se termine, Lambda invoque le gestionnaire de fonction (Phase d’invocation).
Échecs pendant la phase de restauration
Si la phase Restore échoue, Lambda émet des informations d’erreur dans le journal RESTORE_REPORT.
Exemple — RESTORE _ REPORT enregistre le délai d'expiration
RESTORE_REPORT Restore Duration: 1236.04 ms Status: timeout
Exemple — RESTORE _ REPORT log en cas d'échec du hook d'exécution
RESTORE_REPORT Restore Duration: 1236.04 ms Status: error Error Type: Runtime.ExitError
Pour plus d’informations sur le journal RESTORE_REPORT, consultez Surveillance pour Lambda SnapStart.
Phase d’invocation
Lorsqu'une fonction Lambda est invoquée en réponse à une Next API demande, Lambda envoie un Invoke événement au moteur d'exécution et à chaque extension.
Le paramètre d’expiration de la fonction limite la durée de l’ensemble de la phase Invoke. Par exemple, si vous définissez le délai d’expiration de la fonction sur 360 secondes, la fonction et toutes les extensions doivent être terminées dans un délai de 360 secondes. Notez qu’il n’y a pas de phase post-invocation indépendante. La durée correspond à la somme de tous les temps d’invocation (exécution + extensions) et n’est calculée que lorsque l’exécution de la fonction et de toutes les extensions est terminée.
La phase d'appel se termine après l'exécution et toutes les extensions signalent qu'elles sont terminées en envoyant une Next API demande.
Échecs pendant la phase d’invocation
Si la fonction Lambda se bloque ou expire pendant la phase Invoke, Lambda réinitialise l’environnement d’exécution. Le diagramme suivant illustre le comportement de l’environnement d’exécution Lambda en cas d’échec de l’invocation :

Dans le diagramme précédent :
-
La première phase est la INITphase qui s'exécute sans erreur.
-
La deuxième phase est la INVOKEphase qui s'exécute sans erreur.
-
À un moment donné, supposons que votre fonction rencontre un échec d’invocation (tel qu’un dépassement de délai de la fonction ou une erreur d’exécution). La troisième phase, intitulée INVOKEWITHERROR, illustre ce scénario. Lorsque cela se produit, le service Lambda effectue une réinitialisation. La réinitialisation se comporte comme un événement
Shutdown. Lambda commence par arrêter l’exécution, puis envoie un événementShutdownà chaque extension externe enregistrée. L’événement comprend le motif de l’arrêt. Si cet environnement est utilisé pour une nouvelle invocation, Lambda réinitialise l’extension et l’exécution en même temps que l’invocation suivante.Notez que la réinitialisation Lambda n'efface pas le contenu du
/tmprépertoire avant la phase d'initialisation suivante. Ce comportement est cohérent avec la phase d’arrêt normale.Note
AWS met actuellement en œuvre des modifications du service Lambda. En raison de ces modifications, vous pouvez constater des différences mineures entre la structure et le contenu des messages du journal système et des segments de trace émis par les différentes fonctions Lambda de votre ordinateur. Compte AWS
Si la configuration du journal système de votre fonction est définie sur du texte brut, cette modification affecte les messages de journal capturés dans CloudWatch les journaux lorsque votre fonction rencontre un échec d'appel. Les exemples suivants montrent les sorties des journaux dans les anciens et les nouveaux formats.
Ces modifications seront mises en œuvre au cours des prochaines semaines, et toutes les fonctions, Régions AWS sauf en Chine et dans les GovCloud régions, passeront à l'utilisation du nouveau format des messages de journal et des segments de trace.
Exemple CloudWatch Journalise la sortie du journal (exécution ou crash de l'extension) - ancien style
START RequestId: c3252230-c73d-49f6-8844-968c01d1e2e1 Version: $LATEST RequestId: c3252230-c73d-49f6-8844-968c01d1e2e1 Error: Runtime exited without providing a reason Runtime.ExitError END RequestId: c3252230-c73d-49f6-8844-968c01d1e2e1 REPORT RequestId: c3252230-c73d-49f6-8844-968c01d1e2e1 Duration: 933.59 ms Billed Duration: 934 ms Memory Size: 128 MB Max Memory Used: 9 MBExemple CloudWatch Enregistre la sortie du journal (délai d'expiration de la fonction) - ancien style
START RequestId: b70435cc-261c-4438-b9b6-efe4c8f04b21 Version: $LATEST 2024-03-04T17:22:38.033Z b70435cc-261c-4438-b9b6-efe4c8f04b21 Task timed out after 3.00 seconds END RequestId: b70435cc-261c-4438-b9b6-efe4c8f04b21 REPORT RequestId: b70435cc-261c-4438-b9b6-efe4c8f04b21 Duration: 3004.92 ms Billed Duration: 3000 ms Memory Size: 128 MB Max Memory Used: 33 MB Init Duration: 111.23 msLe nouveau format des CloudWatch journaux inclut un
statuschamp supplémentaire dans laREPORTligne. Dans le cas d'un crash d'exécution ou d'une extension, laREPORTligne inclut également un champErrorType.Exemple CloudWatch Journalise la sortie du journal (exécution ou crash de l'extension) - nouveau style
START RequestId: 5b866fb1-7154-4af6-8078-6ef6ca4c2ddd Version: $LATEST END RequestId: 5b866fb1-7154-4af6-8078-6ef6ca4c2ddd REPORT RequestId: 5b866fb1-7154-4af6-8078-6ef6ca4c2ddd Duration: 133.61 ms Billed Duration: 133 ms Memory Size: 128 MB Max Memory Used: 31 MB Init Duration: 80.00 ms Status: error Error Type: Runtime.ExitErrorExemple CloudWatch Enregistre la sortie du journal (délai d'expiration de la fonction) - nouveau style
START RequestId: 527cb862-4f5e-49a9-9ae4-a7edc90f0fda Version: $LATEST END RequestId: 527cb862-4f5e-49a9-9ae4-a7edc90f0fda REPORT RequestId: 527cb862-4f5e-49a9-9ae4-a7edc90f0fda Duration: 3016.78 ms Billed Duration: 3016 ms Memory Size: 128 MB Max Memory Used: 31 MB Init Duration: 84.00 ms Status: timeout -
La quatrième phase représente la INVOKEphase qui suit immédiatement un échec d'appel. Ici, Lambda initialise à nouveau l'environnement en relançant la phase. INIT Cela s’appelle une init supprimée. Lorsque des initialisations sont supprimées, Lambda ne signale pas explicitement de phase INIT CloudWatch supplémentaire dans Logs. Au lieu de cela, vous remarquerez peut-être que la durée indiquée dans la REPORT ligne inclut une INITdurée supplémentaire + la INVOKEdurée. Supposons, par exemple, que les connexions suivantes s'affichent CloudWatch :
2022-12-20T01:00:00.000-08:00 START RequestId: XXX Version: $LATEST 2022-12-20T01:00:02.500-08:00 END RequestId: XXX 2022-12-20T01:00:02.500-08:00 REPORT RequestId: XXX Duration: 3022.91 ms Billed Duration: 3000 ms Memory Size: 512 MB Max Memory Used: 157 MBDans cet exemple, la différence entre les START horodatages REPORT et est de 2,5 secondes. Cela ne correspond pas à la durée déclarée de 3022,91 millisecondes, car cela ne prend pas en compte le surcroît INIT(initialisation supprimée) effectué par Lambda. Dans cet exemple, vous pouvez déduire que la INVOKEphase réelle a duré 2,5 secondes.
Pour plus d’informations sur ce comportement, vous pouvez utiliser la Accès aux données de télémétrie en temps réel pour les extensions à l'aide de la télémétrie API. La télémétrie API émet
INIT_STARTdesINIT_REPORTévénementsphase=invokechaque fois queINIT_RUNTIME_DONEdes initialisations supprimées se produisent entre les phases d'appel. -
La cinquième phase représente la SHUTDOWNphase qui s'exécute sans erreur.
Phase d’arrêt
Quand Lambda est sur le point d’arrêter l’exécution, il envoie un événement Shutdown à chaque extension externe enregistrée. Les extensions peuvent utiliser ce temps pour les tâches de nettoyage final. L'Shutdownévénement est une réponse à une Next API demande.
Durée : l’ensemble de la phase Shutdown est limitée à 2 secondes. Si l’exécution ou une extension ne répondent pas, Lambda y met fin via un signal (SIGKILL).
Lorsque la fonction et toutes les extensions ont pris fin, Lambda conserve l’environnement d’exécution pendant un certain temps en prévision d’une autre invocation de fonction. Cependant, Lambda met fin aux environnements d'exécution toutes les quelques heures pour permettre les mises à jour et la maintenance de l'exécution, même pour les fonctions invoquées en continu. Vous ne devez pas partir du principe que l'environnement d'exécution persistera indéfiniment. Pour de plus amples informations, veuillez consulter Intégrer l'apatridie dans les fonctions.
Lorsque la fonction est invoquée à nouveau, Lambda réactive l’environnement pour la réutilisation. La réutilisation de l’environnement d’exécution a les conséquences suivantes :
-
Les objets déclarés en dehors de la méthode de gestionnaire de la fonction restent initialisés, ce qui fournit une optimisation supplémentaire lorsque la fonction est invoquée à nouveau. Par exemple, si votre fonction Lambda établit une connexion de base de données, au lieu de rétablir la connexion, la connexion d’origine est utilisée dans les invocations suivantes. Nous vous recommandons d’ajouter une logique dans votre code pour vérifier s’il existe une connexion avant d’en créer une nouvelle.
-
Chaque environnement d’exécution fournit entre 512 Mo et 10 240 Mo, par incréments de 1 Mo d’espace disque dans le répertoire
/tmp. Le contenu du répertoire est conservé lorsque l’environnement d’exécution est gelé, fournissant ainsi un cache temporaire qui peut servir à plusieurs invocations. Vous pouvez ajouter du code pour vérifier si le cache contient les données que vous avez stockées. Pour de plus amples informations sur les limites de taille de déploiement, veuillez consulter Quotas Lambda. -
Les processus en arrière-plan ou les rappels qui ont été initiés par votre fonction Lambda et qui ne sont pas terminés à la fin de l’exécution de la fonction reprennent si Lambda réutilise l’environnement d’exécution. Assurez-vous que les processus d’arrière-plan ou les rappels dans votre code se terminent avant que l’exécution du code ne prenne fin.
Intégrer l'apatridie dans les fonctions
Lorsque vous écrivez le code de votre fonction Lambda, considérez l'environnement d'exécution comme étant apatride, en supposant qu'il n'existe que pour un seul appel. Lambda met fin aux environnements d'exécution toutes les quelques heures pour permettre les mises à jour et la maintenance de l'exécution, même pour les fonctions invoquées en continu. Initialisez tout état requis (par exemple, récupérer un panier d'achat depuis une table Amazon DynamoDB) lorsque votre fonction démarre. Avant de quitter, apportez des modifications permanentes aux données dans des magasins durables tels qu'Amazon Simple Storage Service (Amazon S3), DynamoDB ou Amazon Simple Queue Service (Amazon). SQS Évitez de vous fier à des structures de données existantes, à des fichiers temporaires ou à des états couvrant plusieurs invocations, tels que des compteurs ou des agrégats. Cela garantit que votre fonction gère chaque appel indépendamment.
