Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Création d'images de paquets-modèles
Un package de modèles Amazon SageMaker AI est un modèle préentraîné qui fait des prédictions et ne nécessite aucune formation supplémentaire de la part de l'acheteur. Vous pouvez créer un package modèle dans SageMaker AI et publier votre produit d'apprentissage automatique sur AWS Marketplace. Les sections suivantes expliquent comment créer un modèle de package pour AWS Marketplace. Cela inclut la création de l'image du conteneur, ainsi que la création et le test de l'image localement.
Présentation
Un modèle de package inclut les composants suivants :
-
Une image d'inférence stockée dans Amazon Elastic Container Registry
(Amazon ECR) -
(Facultatif) Artefacts du modèle, stockés séparément dans Amazon S3
Note
Les artefacts du modèle sont des fichiers que votre modèle utilise pour faire des prédictions et sont généralement le résultat de vos propres processus de formation. Les artefacts peuvent être n'importe quel type de fichier requis par votre modèle, mais ils doivent être compressés par use.tar.gz. Pour les packages modèles, ils peuvent être regroupés dans votre image d'inférence ou stockés séparément dans Amazon SageMaker AI. Les artefacts du modèle stockés dans Amazon S3 sont chargés dans le conteneur d'inférence lors de l'exécution. Lorsque vous publiez votre modèle de package, ces artefacts sont publiés et stockés dans des compartiments Amazon S3 AWS Marketplace détenus, auxquels l'acheteur ne peut accéder directement.
Astuce
Si votre modèle d'inférence est construit avec un framework d'apprentissage profond tel que Gluon, Keras,,, MXNet PyTorch, TensorFlow TensorFlow -Lite ou ONNX, pensez à utiliser Amazon AI Neo. SageMaker Neo peut optimiser automatiquement les modèles d'inférence déployés sur une famille spécifique de types d'instances cloud tels queml.c4,ml.p2, et autres. Pour plus d'informations, consultez Optimiser les performances des modèles à l'aide de Neo dans le manuel Amazon SageMaker AI Developer Guide.
Le schéma suivant montre le flux de travail pour la publication et l'utilisation de modèles de packages.
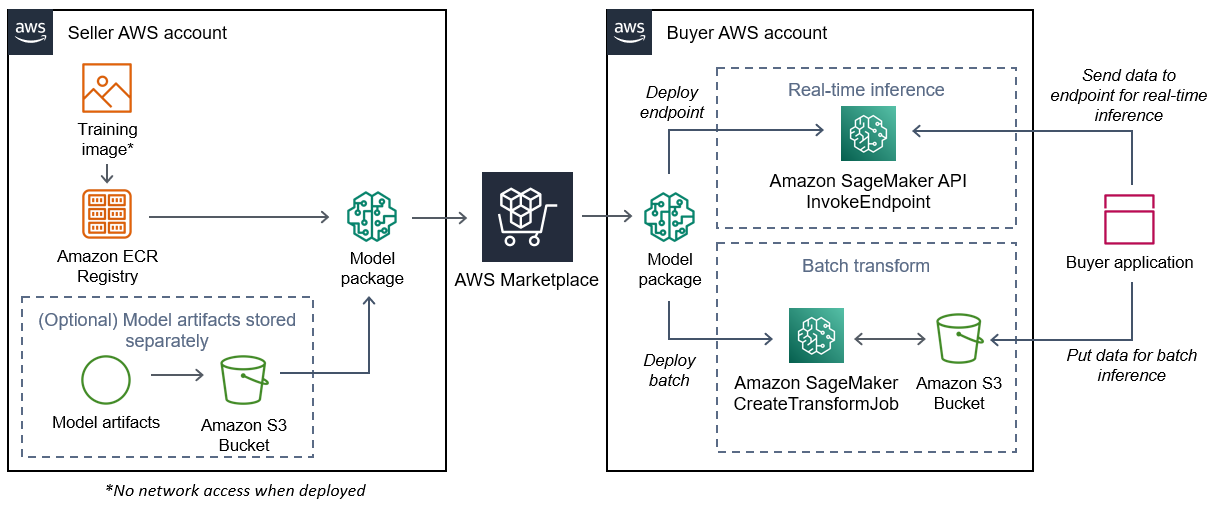
Le processus de création d'un package de modèles d' SageMaker IA pour AWS Marketplace inclut les étapes suivantes :
-
Le vendeur crée une image d'inférence (aucun accès au réseau lors du déploiement) et l'envoie dans le registre Amazon ECR.
Les artefacts du modèle peuvent être regroupés dans l'image d'inférence ou stockés séparément dans S3.
-
Le vendeur crée ensuite une ressource de package modèle dans Amazon SageMaker AI et publie son produit ML sur AWS Marketplace.
-
L'acheteur souscrit au produit ML et déploie le modèle.
Note
Le modèle peut être déployé en tant que point de terminaison pour des inférences en temps réel ou en tant que traitement par lots pour obtenir des prédictions pour un ensemble de données complet en une seule fois. Pour plus d'informations, voir Déployer des modèles à des fins d'inférence.
-
SageMaker L'IA exécute l'image d'inférence. Tous les artefacts de modèle fournis par le vendeur qui ne sont pas regroupés dans l'image d'inférence sont chargés dynamiquement lors de l'exécution.
-
SageMaker L'IA transmet les données d'inférence de l'acheteur au conteneur en utilisant les points de terminaison HTTP du conteneur et renvoie les résultats des prédictions.
Création d'une image d'inférence pour les packages modèles
Cette section fournit une procédure pas à pas pour intégrer votre code d'inférence dans une image d'inférence pour votre modèle de produit. Le processus comprend les étapes suivantes :
L'image d'inférence est une image Docker contenant votre logique d'inférence. Au moment de l'exécution, le conteneur expose les points de terminaison HTTP pour permettre à l' SageMaker IA de transmettre des données vers et depuis votre conteneur.
Note
Ce qui suit n'est qu'un exemple de code d'emballage pour une image d'inférence. Pour plus d'informations, consultez la section Utilisation de conteneurs Docker avec l' SageMaker IA et les exemples d'AWS Marketplace
SageMaker IA
L'exemple suivant utilise un service Web, Flask
Étape 1 : Création de l'image du conteneur
Pour que l'image d'inférence soit compatible avec l' SageMaker IA, l'image Docker doit exposer les points de terminaison HTTP. Pendant le fonctionnement de votre conteneur, l'SageMaker IA transmet les données de l'acheteur au point de terminaison HTTP du conteneur à des fins d'inférence. Les résultats de l'inférence sont renvoyés dans le corps de la réponse HTTP.
La procédure pas à pas suivante utilise la CLI Docker dans un environnement de développement utilisant une distribution Linux Ubuntu.
Création du script du serveur Web
Cet exemple utilise un serveur Python appelé Flask
Note
Le flacon
Créez un script de serveur Web Flask qui dessert les deux points de terminaison HTTP sur le port TCP 8080 utilisé par AI. SageMaker Les deux paramètres attendus sont les suivants :
-
/ping— SageMaker L'IA envoie des requêtes HTTP GET à ce point de terminaison pour vérifier si votre conteneur est prêt. Lorsque votre conteneur est prêt, il répond aux requêtes HTTP GET sur ce point de terminaison avec un code de réponse HTTP 200. -
/invocations— SageMaker L'IA envoie des requêtes HTTP POST à ce point de terminaison à des fins d'inférence. Les données d'entrée à des fins d'inférence sont envoyées dans le corps de la demande. Le type de contenu spécifié par l'utilisateur est transmis dans l'en-tête HTTP. Le corps de la réponse est le résultat d'inférence. Pour plus de détails sur les délais d'expiration, consultezExigences et meilleures pratiques pour la création de produits d'apprentissage automatique.
./web_app_serve.py
# Import modules import json import re from flask import Flask from flask import request app = Flask(__name__) # Create a path for health checks @app.route("/ping") def endpoint_ping(): return "" # Create a path for inference @app.route("/invocations", methods=["POST"]) def endpoint_invocations(): # Read the input input_str = request.get_data().decode("utf8") # Add your inference code between these comments. # # # # # # Add your inference code above this comment. # Return a response with a prediction response = {"prediction":"a","text":input_str} return json.dumps(response)
Dans l'exemple précédent, il n'existe aucune logique d'inférence réelle. Pour votre image d'inférence réelle, ajoutez la logique d'inférence dans l'application Web afin qu'elle traite l'entrée et renvoie la prédiction réelle.
Votre image d'inférence doit contenir toutes les dépendances requises, car elle n'aura pas accès à Internet et ne pourra pas passer d'appels vers aucune Services AWS d'entre elles.
Note
Ce même code est utilisé pour les inférences en temps réel et par lots
Créez le script pour l'exécution du conteneur
Créez un script nommé serve que l' SageMaker IA exécute lorsqu'elle exécute l'image du conteneur Docker. Le script suivant démarre le serveur Web HTTP.
./serve
#!/bin/bash # Run flask server on port 8080 for SageMaker flask run --host 0.0.0.0 --port 8080
Créer le Dockerfile
Créez un Dockerfile dans votre contexte de construction. Cet exemple utilise Ubuntu 18.04, mais vous pouvez commencer à partir de n'importe quelle image de base adaptée à votre framework.
./Dockerfile
FROM ubuntu:18.04 # Specify encoding ENV LC_ALL=C.UTF-8 ENV LANG=C.UTF-8 # Install python-pip RUN apt-get update \ && apt-get install -y python3.6 python3-pip \ && ln -s /usr/bin/python3.6 /usr/bin/python \ && ln -s /usr/bin/pip3 /usr/bin/pip; # Install flask server RUN pip install -U Flask; # Add a web server script to the image # Set an environment to tell flask the script to run COPY /web_app_serve.py /web_app_serve.py ENV FLASK_APP=/web_app_serve.py # Add a script that Amazon SageMaker AI will run # Set run permissions # Prepend program directory to $PATH COPY /serve /opt/program/serve RUN chmod 755 /opt/program/serve ENV PATH=/opt/program:${PATH}
DockerfileAjoute les deux scripts créés précédemment à l'image. Le répertoire du serve script est ajouté au PATH afin qu'il puisse s'exécuter lorsque le conteneur s'exécute.
Package ou téléchargement des artefacts du modèle
Les deux manières de fournir les artefacts du modèle depuis l'entraînement du modèle jusqu'à l'image d'inférence sont les suivantes :
-
Emballé statiquement avec l'image d'inférence.
-
Chargé dynamiquement au moment de l'exécution. Comme elle est chargée dynamiquement, vous pouvez utiliser la même image pour empaqueter différents modèles de machine learning.
Si vous souhaitez empaqueter les artefacts de votre modèle avec l'image d'inférence, incluez-les dans leDockerfile.
Si vous souhaitez charger les artefacts de votre modèle de manière dynamique, stockez-les séparément dans un fichier compressé (.tar.gz) dans Amazon S3. Lors de la création du package modèle, spécifiez l'emplacement du fichier compressé, et SageMaker AI extrait et copie le contenu dans le répertoire du conteneur /opt/ml/model/ lors de l'exécution de votre conteneur. Lorsque vous publiez votre modèle de package, ces artefacts sont publiés et stockés dans des compartiments Amazon S3 AWS Marketplace
détenus, auxquels l'acheteur ne peut accéder directement.
Étape 2 : Création et test de l'image localement
Dans le contexte de construction, les fichiers suivants existent désormais :
-
./Dockerfile -
./web_app_serve.py -
./serve -
Votre logique d'inférence et vos dépendances (facultatives)
Créez, exécutez et testez ensuite l'image du conteneur.
Construisez l'image
Exécutez la commande Docker dans le contexte de construction pour créer et étiqueter l'image. Cet exemple utilise la balisemy-inference-image.
sudo docker build --tag my-inference-image ./
Après avoir exécuté cette commande Docker pour créer l'image, vous devriez voir une sortie car Docker crée l'image en fonction de chaque ligne de votre. Dockerfile Une fois l'opération terminée, vous devriez voir quelque chose de similaire à ce qui suit.
Successfully built abcdef123456
Successfully tagged my-inference-image:latestExécuter localement
Une fois votre compilation terminée, vous pouvez tester l'image localement.
sudo docker run \ --rm \ --publish 8080:8080/tcp \ --detach \ --name my-inference-container \ my-inference-image \ serve
Vous trouverez ci-dessous des informations sur la commande :
-
--rm— Retirez automatiquement le contenant une fois qu'il s'est arrêté. -
--publish 8080:8080/tcp— Exposez le port 8080 pour simuler le port auquel SageMaker AI envoie des requêtes HTTP. -
--detach— Lancez le conteneur en arrière-plan. -
--name my-inference-container— Donnez un nom à ce conteneur en cours d'exécution. -
my-inference-image— Exécute l'image créée. -
serve— Exécutez le même script que celui que SageMaker l'IA exécute lors de l'exécution du conteneur.
Après avoir exécuté cette commande, Docker crée un conteneur à partir de l'image d'inférence que vous avez créée et l'exécute en arrière-plan. Le conteneur exécute le serve script, qui lance votre serveur Web à des fins de test.
Testez le point de terminaison HTTP ping
Lorsque SageMaker l'IA gère votre conteneur, elle envoie régulièrement un ping au point de terminaison. Lorsque le point de terminaison renvoie une réponse HTTP avec le code d'état 200, il indique à l' SageMaker IA que le conteneur est prêt pour l'inférence. Vous pouvez le tester en exécutant la commande suivante, qui teste le point de terminaison et inclut l'en-tête de réponse.
curl --include http://127.0.0.1:8080/ping
L'exemple de sortie est le suivant.
HTTP/1.0 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 0
Server: MyServer/0.16.0 Python/3.6.8
Date: Mon, 21 Oct 2019 06:58:54 GMTTester le point de terminaison HTTP d'inférence
Lorsque le conteneur indique qu'il est prêt en renvoyant un code d'état 200 à votre ping, SageMaker AI transmet les données d'inférence au point de terminaison /invocations HTTP via une POST requête. Testez le point d'inférence en exécutant la commande suivante.
curl \ --request POST \ --data "hello world" \ http://127.0.0.1:8080/invocations
L'exemple de sortie est le suivant.
{"prediction": "a", "text": "hello
world"}
Ces deux points de terminaison HTTP fonctionnant, l'image d'inférence est désormais compatible avec SageMaker l'IA.
Note
Le modèle de votre modèle de package peut être déployé de deux manières : en temps réel et par lots. Dans les deux déploiements, l' SageMaker IA utilise les mêmes points de terminaison HTTP lors de l'exécution du conteneur Docker.
Pour arrêter le conteneur, exécutez la commande suivante.
sudo docker container stop my-inference-container
Lorsque votre image d'inférence est prête et testée, vous pouvez continuerTéléchargement de vos images sur Amazon Elastic Container Registry.
