Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Format de chargement de données Gremlin
Pour charger des données TinkerPop Apache G705 au format CSV, vous devez spécifier les sommets et les arêtes dans des fichiers séparés.
Le chargeur peut effectuer le chargement depuis plusieurs fichiers de sommet et plusieurs fichiers d'arc en une seule tâche de chargement.
Pour chaque commande de chargement, l'ensemble de fichiers à charger doit être dans le même dossier au sein du compartiment Amazon S3, et vous devez spécifier le nom du dossier pour le paramètre source. Les noms de fichier et les extensions de nom de fichier ne sont pas importants.
Le format CSV Amazon Neptune respecte la spécification CSV RFC 4180. Pour plus d'informations, consultez Common Format and MIME Type for CSV Files
Note
Tous les fichiers doivent être encodés au format UTF-8.
Chaque fichier comporte une ligne d'en-têtes séparés par des virgules. La ligne d'en-tête se compose d'en-têtes de colonne système et d'en-têtes de colonne de propriété.
En-têtes de colonne système
Les en-têtes de colonne système obligatoires et autorisés sont différents pour les fichiers de sommet et les fichiers d'arc.
Chaque colonne système ne peut apparaître qu'une seule fois dans un en-tête.
Toutes les étiquettes sont sensibles à la casse.
En-têtes de sommet
-
~id- ObligatoireUn ID pour le sommet.
-
~labelUne étiquette pour le sommet. Plusieurs valeurs d'étiquette sont autorisées, séparées par des points-virgules (
;).S'il n'
~labelest pas présent, TinkerPop fournit une étiquette avec la valeurvertex, car chaque sommet doit avoir au moins une étiquette.
En-têtes d'arc
-
~id- ObligatoireUn ID pour l'arc.
-
~from- ObligatoireID de sommet du sommet from.
-
~to- ObligatoireID de sommet du sommet to.
-
~labelÉtiquette de l'arête. Les arêtes ne peuvent avoir qu'une seule étiquette.
S'il n'
~labelest pas présent, TinkerPop fournit une étiquette avec la valeuredge, car chaque bord doit avoir une étiquette.
En-têtes de colonne de propriété
Vous pouvez spécifier une colonne (:) pour une propriété à l'aide de la syntaxe suivante. Les noms de type ne sont pas sensibles à la casse. Notez toutefois que si le signe deux-points figure dans le nom d'une propriété, faites-le précéder d'une barre oblique inverse comme caractère d'échappement : \:.
propertyname:type
Note
Les espaces, les virgules, le retour en chariot et les caractères de nouvelle ligne ne sont pas autorisés dans les en-têtes de colonne. Les noms de propriétés ne peuvent donc pas inclure ces caractères.
Vous pouvez spécifier une colonne pour un type de tableau en ajoutant [] au type :
propertyname:type[]
Note
Les propriétés d'arc ne peuvent avoir qu'une seule valeur et provoquent une erreur si un type de tableau ou une seconde valeur est spécifié.
L'exemple suivant montre l'en-tête de colonne pour une propriété nommée age de type Int.
age:Int
Chaque ligne du fichier doit obligatoirement avoir un nombre entier dans cette position ou rester vide.
Les tableaux de chaînes sont autorisés, mais les chaînes d'un tableau ne peuvent pas inclure le point-virgule (;), à moins qu'une barre oblique inverse n'y soit ajoutée comme caractère d'échappement (\;, par exemple).
Spécification de la cardinalité d'une colonne
À partir de Sortie : 1.0.1.0.200366.0 (26/07/2019), l'en-tête de colonne peut être utilisé pour spécifier la cardinalité pour la propriété identifiée par la colonne. Ceci permet au chargeur en bloc de respecter la cardinalité de manière similaire à la façon dont le font les requêtes Gremlin.
Vous spécifiez la cardinalité d'une colonne comme suit :
propertyname:type(cardinality)
La cardinality valeur peut être single soitset. La valeur par défaut est supposée être set, ce qui signifie que la colonne peut accepter plusieurs valeurs. Dans le cas des fichiers d'arête, la cardinalité est toujours unique (« single ») et si vous spécifiez une autre cardinalité, le chargeur déclenche une exception.
Si la cardinalité est single, le chargeur déclenche une erreur si une valeur précédente est déjà présente pendant le chargement d'une valeur ou si plusieurs valeurs sont chargées. Ce comportement peut être ignoré afin qu'une valeur existante soit remplacée lorsqu'une nouvelle valeur est chargée à l'aide de l'indicateur updateSingleCardinalityProperties. Consultez Commande Loader.
Il est possible d'utiliser un paramètre de cardinalité de type tableau, même si ce n'est généralement pas nécessaire. Voici les combinaisons possibles :
name:type: la cardinalité estset, et le contenu est à valeur unique.name:type[]: la cardinalité estset, et le contenu est à valeurs multiples.name:type(single): la cardinalité estsingle, et le contenu est à valeur unique.name:type(set): la cardinalité estset, ce qui est identique à la valeur par défaut, et le contenu est à valeur unique.name:type(set)[]: la cardinalité estset, et le contenu est à valeurs multiples.name:type(single)[]: ce paramètre est contradictoire et génère une erreur.
La section suivante répertorie tous les types de données Gremlin disponibles.
Types de données Gremlin
Il s'agit d'une liste des types de propriété autorisés, avec une description de chaque type.
Bool (ou booléen)
Indique un champ booléen. Valeurs autorisées : false, true
Note
Toute valeur autre que true sera traitée comme false.
Types de nombres entiers
Les valeurs en dehors des plages définies entraînent une erreur.
| Type | Range |
|---|---|
| Octet | -128 à 127 |
| Court | -32768 à 32767 |
| Int | -2^31 à 2^31-1 |
| Long | -2^63 à 2^63-1 |
Types de nombre décimal
Prend en charge la notation décimale ou la notation scientifique. Autorise également les symboles tels que (+/-) Infinity ou NaN. La clause INF n'est pas prise en charge.
| Type | Range |
|---|---|
| Float | Virgule flottante IEEE 754 32 bits |
| Double | Virgule flottante IEEE 754 64 bits |
Les valeurs à virgule flottante et doubles qui sont trop longues sont chargées et arrondie à la valeur la plus proche pour la précision 24 bits (virgule flottante) et 53 bits (double). Une valeur du milieu est arrondie à 0 pour le dernier chiffre restant au niveau du bit.
Chaîne
Les guillemets sont facultatifs. Les virgules, et les caractères de saut de ligne et de retour à la ligne font automatiquement l'objet d'un échappement s'ils sont inclus dans une chaîne entourée de guillemets ("). Exemple : "Hello,
World"
Pour inclure des guillemets dans une chaîne entre guillemets, vous pouvez échapper les guillemets en utilisant deux guillemets dans une ligne : Exemple : "Hello
""World"""
Les tableaux de chaînes sont autorisés, mais les chaînes d'un tableau ne peuvent pas inclure le point-virgule (;), à moins qu'une barre oblique inverse n'y soit ajoutée comme caractère d'échappement (\;, par exemple).
Si vous souhaitez placer des chaînes d'un tableau entre guillemets, vous devez entourer la totalité du tableau par un ensemble de guillemets. Exemple : "String one; String 2; String 3"
Date
Date Java au format ISO 8601. Supporte les formats suivants :yyyy-MM-dd,yyyy-MM-ddTHH:mm,yyyy-MM-ddTHH:mm:ss,yyyy-MM-ddTHH:mm:ssZ. Les valeurs sont converties en heure d'époque et stockées.
Datetime
Date Java au format ISO 8601. Supporte les formats suivants :yyyy-MM-dd,yyyy-MM-ddTHH:mm,yyyy-MM-ddTHH:mm:ss,yyyy-MM-ddTHH:mm:ssZ. Les valeurs sont converties en heure d'époque et stockées.
Format de ligne Gremlin
Délimiteurs
Les champs dans une ligne sont séparés par une virgule. Les enregistrements sont séparés par un saut de ligne ou par un saut de ligne suivi d'un retour chariot.
Champs vides
Des champs vides sont autorisés pour les colonnes non obligatoires (comme des propriétés définies par l'utilisateur). Un champ vide a quand même besoin d'une virgule comme séparateur. Les champs vides sur les colonnes obligatoires entraîneront une erreur d'analyse. Les valeurs de chaîne vides sont interprétées comme des valeurs de chaîne vides pour le champ, et non comme un champ vide. L'exemple de la section suivante comporte un champ vide dans chaque exemple de sommet.
Sommet IDs
Les valeurs ~id doivent être uniques pour tous les sommets dans chaque fichier de sommets. Plusieurs lignes de sommet avec des valeurs ~id identiques sont appliquées à un seul sommet dans le graphique. Une chaîne vide ("") est un identifiant valide, et le sommet est créé avec une chaîne vide comme identifiant.
Bord IDs
En outre, les valeurs ~id doivent être uniques pour toutes les arêtes dans chaque fichier d'arête. Plusieurs lignes d'arête avec des valeurs ~id identiques sont appliquées à la seule arête du graphe. La chaîne vide ("") est un identifiant valide, et le bord est créé avec une chaîne vide comme identifiant.
Étiquettes
Les étiquettes distinguent les majuscules et minuscules et ne peuvent pas être vides. Une valeur de "" provoquera une erreur.
Valeurs de chaîne
Les guillemets sont facultatifs. Les virgules, et les caractères de saut de ligne et de retour à la ligne font automatiquement l'objet d'un échappement s'ils sont inclus dans une chaîne entourée de guillemets ("). ("")Les valeurs de chaîne vides sont interprétées comme une valeur de chaîne vide pour le champ, et non comme un champ vide.
Spécification du format CSV
Le format CSV Neptune respecte la spécification CSV RFC 4180, y compris les exigences suivantes.
Les fins de ligne de style Unix et Windows sont prises en charge (\n ou \r\n).
Tout champ peut être placé entre guillemets.
Les champs contenant un saut de ligne, des guillemets ou des virgules doivent être placés entre guillemets. (Si ce n'est pas le cas, le chargement s'interrompt immédiatement.)
Les guillemets (
") dans un champ doit être représentés par des guillemets doubles. Par exemple, une chaîneHello "World"doit figurer sous la forme"Hello ""World"""dans les données.Les espaces entre les délimiteurs sont ignorés. Si une ligne est présente sous forme
value1, value2, elle est stockée sous forme"value1"et"value2".Tous les autres caractères d'échappement sont stockés tels quels. Par exemple,
"data1\tdata2"est stocké comme suit :"data1\tdata2". Aucun autre échappement n'est nécessaire dans la mesure où ces caractères sont placés entre guillemets.Les champs vides sont autorisés. Un champ vide est considéré comme une valeur vide.
Plusieurs valeurs pour un champ sont spécifiées séparées par un point-virgule (
;).
Pour plus d'informations, consultez Common Format and MIME Type for CSV Files
Exemple Gremlin
Le schéma suivant montre un exemple de deux sommets et d'une arête extraits du graphe TinkerPop moderne.
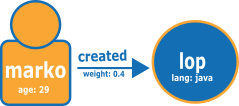
Voici le graphe au format de chargement CSV Neptune.
Fichier de sommets :
~id,name:String,age:Int,lang:String,interests:String[],~label v1,"marko",29,,"sailing;graphs",person v2,"lop",,"java",,software
Vue tabulaire du fichier de sommets :
| ~id | name:String | age:Int | lang:String | Intérêts:string [] | ~étiquette |
| v1 | "marko" | 29 | ["navigation », « graphes"] | personne | |
| v2 | "lop" | "java" | logiciel |
Fichier d'arête :
~id,~from,~to,~label,weight:Double e1,v1,v2,created,0.4
Vue tabulaire du fichier d'arête :
| ~id | ~de | ~sur | ~étiquette | weight:Double |
| e1 | v1 | v2 | créé | 0.4 |
Étapes suivantes
Maintenant que vous en savez plus sur les formats de chargement, consultez Exemple : chargement de données dans une instance de base de données Neptune.
