Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Bonnes pratiques opérationnelles pour Amazon OpenSearch Service
Ce chapitre décrit les meilleures pratiques relatives à l'exploitation des domaines Amazon OpenSearch Service et inclut des directives générales qui s'appliquent à de nombreux cas d'utilisation. Chaque charge de travail est unique, avec des caractéristiques propres, de sorte qu'aucune recommandation générique ne convient exactement à chaque cas d'utilisation. La bonne pratique la plus importante consiste à déployer, tester et régler vos domaines dans un cycle continu pour trouver la configuration, la stabilité et le coût optimaux pour votre charge de travail.
Surveillance et alertes
Les meilleures pratiques suivantes s'appliquent à la surveillance de vos domaines OpenSearch de service.
Configuration des CloudWatch alarmes
OpenSearch Le service transmet des indicateurs de performance à Amazon CloudWatch. Passez régulièrement en revue les métriques de votre cluster et de votre instance et configurez les CloudWatch alarmes recommandées en fonction des performances de votre charge de travail.
Activer la publication des journaux
OpenSearch Le service expose les journaux OpenSearch d'erreurs, les journaux lents de recherche, l'indexation des journaux lents et les journaux d'audit dans Amazon CloudWatch Logs. Les journaux lents de recherche, les journaux lents d'indexation et les journaux d'erreurs permettent de résoudre les problèmes de performances et de stabilité. Les journaux d'audit, qui ne sont disponibles que si vous activez le contrôle précis des accès, suivent l'activité des utilisateurs. Pour plus d'informations, consultez la section Logs
Les journaux lents de recherche et les journaux lents d'indexation sont des outils importants pour comprendre et résoudre les problèmes de performance de vos opérations de recherche et d'indexation. Activez la livraison de journaux lents de recherche et d'indexation pour tous les domaines de production. Vous devez également configurer des seuils de journalisation, sinon les journaux ne CloudWatch seront pas capturés.
Stratégie de partition
Les partitions répartissent votre charge de travail entre les nœuds de données de votre domaine OpenSearch de service. Des index correctement configurés peuvent contribuer à améliorer les performances globales du domaine.
Lorsque vous envoyez des données à OpenSearch Service, vous les envoyez vers un index. Un index est comparable à une table de base de données, les documents étant les lignes et les champs les colonnes. Lorsque vous créez l'index, vous indiquez le OpenSearch nombre de partitions principales que vous souhaitez créer. Les partitions principales sont des partitions indépendantes de l'ensemble de données complet. OpenSearch Le service distribue automatiquement vos données sur les partitions principales d'un index. Vous pouvez également configurer des réplicas de l'index. Chaque partition réplica comprend un jeu complet de copies des partitions principales pour cet index.
OpenSearch Le service mappe les partitions de chaque index sur les nœuds de données de votre cluster. Il garantit que les partitions principales et réplicas de l'index résident sur des nœuds de données différents. Le premier réplica garantit que vous disposez de deux copies des données dans l'index. Vous devez toujours utiliser au moins un réplica. Des réplicas supplémentaires fournissent une redondance et une capacité de lecture supplémentaires.
OpenSearch envoie des demandes d'indexation à tous les nœuds de données contenant des fragments appartenant à l'index. Il envoie les demandes d'indexation d'abord aux nœuds de données contenant des partitions principales, puis aux nœuds de données contenant des partitions de réplica. Les requêtes de recherche sont acheminées par le nœud coordinateur vers une partition principale ou de réplica pour toutes les partitions appartenant à l'index.
Par exemple, pour un index avec cinq partitions principales et un réplica, chaque requête d'indexation implique 10 partitions. En revanche, les requêtes de recherche sont envoyées à n partitions, où n est le nombre de partitions principales. Pour un index avec cinq partitions principales et un réplica, chaque requête de recherche implique cinq partitions (principales ou de réplica) de cet index.
Déterminer le nombre de partitions et de nœuds de données
Utilisez les bonnes pratiques suivantes pour déterminer le nombre de partitions et de nœuds de données pour votre domaine.
Taille de la partition : la taille des données sur le disque est un résultat direct de la taille de vos données source, et elle change au fur et à mesure que vous indexez plus de données. Le source-to-index ratio peut varier énormément, de 1:10 à 10:1 ou plus, mais il se situe généralement autour de 1:1,10. Vous pouvez utiliser ce ratio pour prévoir la taille de l'index sur le disque. Vous pouvez également indexer certaines données et récupérer les tailles d'index réelles pour déterminer le ratio pour votre charge de travail. Une fois que vous avez prédit la taille de l'index, définissez un nombre de partitions de sorte que chaque partition soit comprise entre 10 et 30 Gio (pour les charges de travail de recherche) ou entre 30 et 50 Gio (pour les charges de travail de journaux). 50 Gio devrait être le maximum – assurez-vous de planifier la croissance.
Nombre de partitions : la distribution des partitions aux nœuds de données a un impact important sur les performances d'un domaine. Lorsque vous avez des index contenant plusieurs partitions, essayez de faire en sorte que le nombre de partitions soit un multiple du nombre de nœuds de données. Cela permet de garantir que les partitions sont réparties de manière uniforme entre les nœuds de données et d'éviter les nœuds chauds. Par exemple, si vous avez 12 partitions principales, votre nombre de nœuds de données devrait être de 2, 3, 4, 6 ou 12. Toutefois, le nombre de partitions est secondaire par rapport à la taille des partitions – si vous avez 5 Gio de données, vous devez toujours utiliser une seule partition.
Partitions par nœud de données : le nombre total de partitions qu'un nœud peut contenir est proportionnel à la mémoire de tas Java virtual machine (JVM) du nœud. Visez 25 partitions ou moins par Gio de mémoire de tas. Par exemple, un nœud avec 32 Gio de mémoire de tas ne doit pas contenir plus de 800 partitions. Bien que la distribution des partitions puisse varier en fonction de vos modèles de charge de travail, il existe une limite de 1 000 partitions par nœud pour Elasticsearch, de OpenSearch 1,1 à 2,15 et de 4 000 pour les versions 2.17 et supérieures. OpenSearch L'API cat/allocation
Ratio partition/CPU : lorsqu'une partition est impliquée dans une demande d'indexation ou de recherche, elle utilise un vCPU pour traiter la demande. Comme bonne pratique, utilisez un point d'échelle initial de 1,5 vCPU par partition. Si votre type d'instance est de 8 VCPUs, définissez le nombre de nœuds de données de manière à ce que chaque nœud ne contienne pas plus de six partitions. Notez qu'il s'agit d'une approximation. Assurez-vous de tester votre charge de travail et de mettre votre cluster à l'échelle en conséquence.
Pour des recommandations sur le volume de stockage, la taille des partitions et le type d'instance, consultez les ressources suivantes :
Éviter l'asymétrie de stockage
L'asymétrie de stockage se produit lorsqu'un ou plusieurs nœuds au sein d'un cluster détient une proportion plus élevée de stockage pour un ou plusieurs index que les autres. Les indications d'une asymétrie de stockage comprennent une utilisation inégale de l'UC, une latence intermittente et inégale, et une mise en file d'attente inégale sur les nœuds de données. Pour déterminer si vous avez des problèmes d'asymétrie, consultez les sections de dépannage suivantes :
Stabilité
Les meilleures pratiques suivantes s'appliquent au maintien d'un domaine de OpenSearch service stable et sain.
Tenez-vous au courant de OpenSearch
Mises à jour du logiciel de service
OpenSearch Le service publie régulièrement des mises à jour logicielles qui ajoutent des fonctionnalités ou améliorent vos domaines. Les mises à jour ne modifient pas la OpenSearch version du moteur Elasticsearch. Nous vous recommandons de planifier une période récurrente pour exécuter l'opération d'DescribeDomainAPI et de lancer une mise à jour du logiciel de service si UpdateStatus c'est le casELIGIBLE. Si vous ne mettez pas à jour votre domaine dans un certain délai (généralement deux semaines), le OpenSearch Service effectue automatiquement la mise à jour.
OpenSearch mises à niveau de version
OpenSearch Le service ajoute régulièrement la prise en charge des versions gérées par la communauté de. OpenSearch Effectuez toujours une mise à niveau vers les dernières OpenSearch versions dès qu'elles sont disponibles.
OpenSearch Le service met à niveau simultanément OpenSearch les deux OpenSearch tableaux de bord (ou Elasticsearch et Kibana si votre domaine utilise un ancien moteur). Si le cluster dispose de nœuds maîtres dédiés, les mises à niveau sont exécutées sans temps d'arrêt. Dans le cas contraire, le cluster risque de ne pas répondre pendant plusieurs secondes après la mise à niveau pendant qu'il élit un nœud maître. OpenSearch Les tableaux de bord peuvent être indisponibles pendant une partie ou la totalité de la mise à niveau.
Il existe deux façons de mettre à niveau un domaine :
-
Mise à niveau sur place : cette option est plus simple car vous conservez le même cluster.
-
Mise à niveau d'instantané/restauration : cette option est bonne pour tester de nouvelles versions sur un nouveau cluster ou pour migrer entre des clusters.
Quel que soit le processus de mise à niveau que vous utilisez, nous vous recommandons de conserver un domaine destiné uniquement au développement et aux tests, et d'en installer la nouvelle version avant de mettre à niveau votre domaine de production. Choisissez Development and testing (Développement et test) pour le type de déploiement lors de la création du domaine de test. Assurez-vous de mettre à niveau tous les clients vers des versions compatibles immédiatement après la mise à niveau du domaine.
Améliorez les performances des instantanés
Pour éviter que votre instantané ne soit bloqué pendant le traitement, le type d'instance du nœud maître dédié doit correspondre au nombre de partitions. Pour de plus amples informations, veuillez consulter Choix des types d'instance pour les nœuds principaux dédiés. En outre, chaque nœud ne doit pas contenir plus de 25 partitions recommandées par GiB de mémoire Java. Pour de plus amples informations, veuillez consulter Choix du nombre de partitions.
Activer les nœuds principaux dédiés
Les nœuds principaux dédiés améliorent la stabilité du cluster. Un nœud principal dédié effectue les tâches de gestion du cluster, mais ne détient pas les données d'index et ne répond pas aux demandes des clients. Ce déchargement des tâches de gestion du cluster augmente la stabilité de votre domaine et permet d'effectuer certaines modifications de configuration sans temps d'arrêt.
Activez et utilisez trois nœuds principaux dédiés pour une stabilité de domaine optimale dans trois zones de disponibilité. Le déploiement avec Multi-AZ with Standby permet de configurer trois nœuds principaux dédiés pour vous. Pour des recommandations sur le type d'instance, consultez Choix des types d'instance pour les nœuds principaux dédiés.
Déployer sur plusieurs zones de disponibilité
Pour éviter la perte de données et minimiser le temps d'arrêt du cluster en cas d'interruption de service, vous pouvez répartir les nœuds sur deux ou trois zones de disponibilité dans la même Région AWS. La meilleure pratique consiste à effectuer un déploiement à l'aide de la technologie Multi-AZ avec veille, qui configure trois zones de disponibilité, dont deux zones sont actives et une sert de veille, et avec deux répliques de fragments par index. Cette configuration permet au OpenSearch Service de distribuer des répliques à des partitions différentes AZs de leurs partitions principales correspondantes. Il n'y a aucun frais de transfert de données entre zones de disponibilité pour les communications entre clusters.
Les zones de disponibilité sont des emplacements isolés au sein de chaque région . Avec une configuration à deux zones de disponibilité, la perte d'une zone signifie que vous perdez la moitié de la capacité totale du domaine. Le passage à trois zones de disponibilité réduit davantage l'impact de la perte d'une seule zone.
Contrôler le flux d'ingestion et la mise en mémoire tampon
Nous vous recommandons de limiter le nombre total de demandes à l'aide de l'opération d'API _bulk_bulk contenant 5 000 documents que d'envoyer 5 000 demandes contenant un seul document.
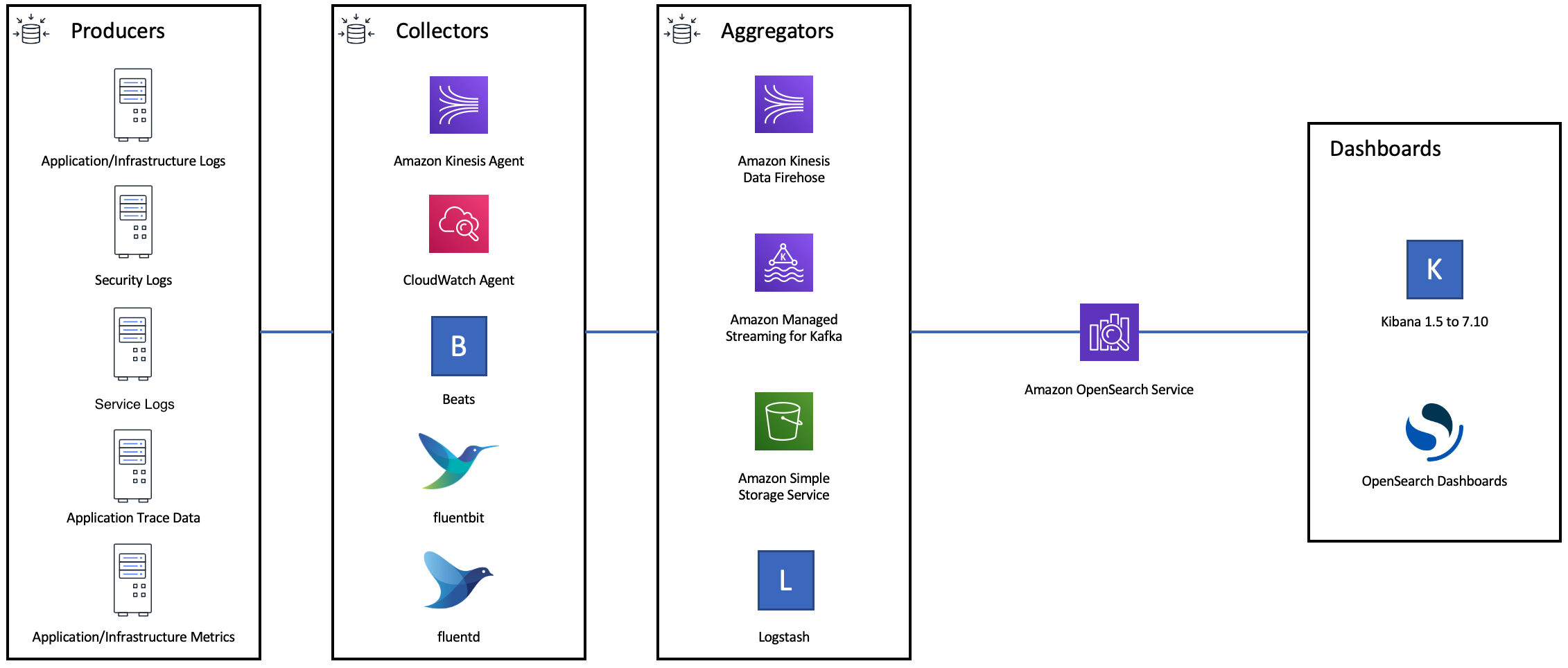
Pour une stabilité opérationnelle optimale, il est parfois nécessaire de limiter ou même de mettre en pause le flux en amont des demandes d'indexation. La limitation du débit des demandes d'indexation est un mécanisme important pour gérer les pics de demandes inattendus ou occasionnels qui pourraient autrement inonder le cluster. Envisagez d'intégrer un mécanisme de contrôle de flux dans votre architecture en amont.
Le diagramme suivant montre plusieurs options de composants pour une architecture d'ingestion de journaux. Configurez la couche d'agrégation afin de disposer d'un espace suffisant pour mettre en mémoire tampon les données entrantes en cas de pic de trafic soudain et de brève maintenance du domaine.
Créer des mappages pour les charges de travail de recherche
Pour les charges de travail de recherche, créez des mappagesdynamic sur strict afin d'éviter l'ajout accidentel de nouveaux champs.
PUT my-index { "mappings": { "dynamic": "strict", "properties": { "title": { "type" : "text" }, "author": { "type" : "integer" }, "year": { "type" : "text" } } } }
Utiliser des modèles d'index
Vous pouvez utiliser un modèle d'index
Les paramètres suivants sont utiles à configurer dans les modèles :
-
Nombre de partitions primaires et de réplica
-
Intervalle d'actualisation (fréquence d'actualisation et de mise à disposition des modifications récentes de l'index pour la recherche)
-
Contrôle de mappage dynamique
-
Mappages de champs explicites
L'exemple de modèle suivant contient chacun de ces paramètres :
{ "index_patterns":[ "index-*" ], "order": 0, "settings": { "index": { "number_of_shards": 3, "number_of_replicas": 1, "refresh_interval": "60s" } }, "mappings": { "dynamic": false, "properties": { "field_name1": { "type": "keyword" } } } }
Même s'ils changent rarement, il OpenSearch est plus simple de gérer la définition centralisée des paramètres et des mappages que la mise à jour de plusieurs clients en amont.
Gérer les index avec Index State Management
Si vous gérez des journaux ou des données de séries temporelles, nous vous recommandons d'utiliser Index State Management (ISM). ISM vous permet d'automatiser les tâches régulières de gestion du cycle de vie des index. Avec ISM, vous pouvez créer des stratégies qui déclenchent les renouvellements d'alias d'index, la prise d'instantanés d'index, le déplacement d'index entre les niveaux de stockage et la suppression d'anciens index. Vous pouvez même utiliser l'opération de renouvellement
Tout d'abord, configurez une stratégie ISM. Pour obtenir un exemple, consultez Exemples de politiques. Ensuite, attachez la stratégie à un ou plusieurs index. Si vous incluez un champ de modèle ISM dans la politique, OpenSearch Service applique automatiquement la politique à tout index correspondant au modèle spécifié.
Supprimez les index inutilisés
Examinez régulièrement les index de votre cluster et identifiez ceux qui ne sont pas utilisés. Prenez un instantané de ces index pour qu'ils soient stockés dans S3, puis supprimez-les. Lorsque vous supprimez des index inutilisés, vous réduisez le nombre de partitions et vous permettez une distribution du stockage et une utilisation des ressources plus équilibrées entre les nœuds. Même lorsqu'ils sont inutilisés, les index consomment certaines ressources pendant les activités internes de maintenance des index.
Plutôt que de supprimer manuellement les index inutilisés, vous pouvez utiliser ISM pour prendre automatiquement un instantané et supprimer les index après un certain temps.
Utiliser plusieurs domaines pour une haute disponibilité
Pour obtenir une haute disponibilité supérieure à 99,9 %
Concevez vos applications en amont et en aval en tenant compte du basculement. Assurez-vous de tester le processus de basculement en même temps que les autres processus de reprise après sinistre.
Performances
Les bonnes pratiques suivantes s'appliquent au réglage de vos domaines pour des performances optimales.
Optimiser la taille et la compression des demandes groupées
La taille des groupes dépend de vos données, des analyses et de la configuration du cluster, mais un bon point de départ est de 3-5 Mio par demande groupée.
Envoyez des demandes et recevez des réponses de la part de vos OpenSearch domaines en utilisant la compression gzip pour réduire la taille de la charge utile des demandes et des réponses. Vous pouvez utiliser la compression gzip avec le client OpenSearch Python ou en incluant les en-têtes suivants du côté client :
-
'Accept-Encoding': 'gzip' -
'Content-Encoding': 'gzip'
Pour optimiser la taille de vos demandes groupées, commencez par une taille de 3 Mio. Augmentez ensuite lentement la taille de la demande jusqu'à ce que les performances d'indexation cessent de s'améliorer.
Note
Pour activer la compression gzip dans les domaines exécutant Elasticsearch version 6.x, vous devez définir http_compression.enabled au niveau du cluster. Ce paramètre est vrai par défaut dans les versions 7.x d'Elasticsearch et dans toutes les versions de. OpenSearch
Réduire la taille des réponses aux demandes groupées
Pour réduire la taille des OpenSearch réponses, excluez les champs inutiles à l'aide du filter_path paramètre. Assurez-vous de ne pas filtrer les champs qui sont nécessaires pour identifier ou relancer les demandes ayant échoué. Pour plus d’informations et d’exemples, consultez Réduction de la taille des réponses.
Régler les intervalles d'actualisation
OpenSearch les index ont finalement une cohérence de lecture. Une opération d'actualisation rend toutes les mises à jour effectuées sur un index disponibles pour la recherche. L'intervalle d'actualisation par défaut est d'une seconde, ce qui OpenSearch signifie qu'une actualisation est effectuée toutes les secondes pendant l'écriture d'un index.
Moins vous actualisez un index (intervalle d'actualisation plus élevé), meilleures sont les performances globales de l'indexation. L'augmentation de l'intervalle d'actualisation entraîne un délai plus long entre la mise à jour de l'index et le moment où les nouvelles données sont disponibles pour la recherche. Définissez un intervalle d'actualisation aussi haut que possible pour améliorer les performances globales.
Nous vous recommandons de définir le paramètre refresh_interval pour tous vos index sur 30 secondes ou plus.
Activer Auto-Tune
Auto-Tune utilise les indicateurs de performance et d'utilisation de votre OpenSearch cluster pour suggérer des modifications de la taille des files d'attente, de la taille du cache et des paramètres de machine virtuelle Java (JVM) sur vos nœuds. Ces modifications facultatives améliorent la vitesse et la stabilité du cluster. Vous pouvez revenir aux paramètres de OpenSearch service par défaut à tout moment. Auto-Tune est activé par défaut sur les nouveaux domaines, sauf si vous le désactivez volontairement.
Nous vous recommandons d'activer Auto-Tune sur tous les domaines et de définir une fenêtre de maintenance récurrente ou de revoir périodiquement ses recommandations.
Sécurité
Les bonnes pratiques suivantes s'appliquent à la sécurisation de vos domaines.
Activer le contrôle précis des accès
Le contrôle d'accès détaillé vous permet de contrôler qui peut accéder à certaines données au sein d'un domaine de OpenSearch service. Par rapport au contrôle d'accès généralisé, le contrôle précis des accès attribue à chaque cluster, index, document et champ sa propre stratégie d'accès. Les critères d'accès peuvent être basés sur un certain nombre de facteurs, notamment le rôle de la personne qui demande l'accès et l'action qu'elle compte effectuer sur les données. Par exemple, vous pouvez accorder à un utilisateur l'accès à l'écriture dans un index, et à un autre utilisateur l'accès uniquement pour lire les données de l'index sans y apporter de modifications.
Le contrôle précis des accès permet aux données ayant des exigences d'accès différentes d'exister dans le même espace de stockage sans rencontrer de problèmes de sécurité ou de conformité.
Nous vous recommandons d'activer le contrôle précis des accès sur vos domaines.
Déployer des domaines dans un VPC
Le fait de placer votre domaine de OpenSearch service dans un cloud privé virtuel (VPC) permet de sécuriser les communications entre le OpenSearch service et les autres services au sein du VPC, sans avoir besoin d'une passerelle Internet, d'un périphérique NAT ou d'une connexion VPN. Tout le trafic reste sécurisé dans le AWS cloud. En raison de leur isolement logique, les domaines résidant au sein d'un VPC possèdent une couche de sécurité supplémentaire par rapport aux domaines qui utilisent des points de terminaison publics.
Nous vous recommandons de créer vos domaines au sein d'un VPC.
Appliquer une stratégie d'accès restrictive
Même si votre domaine est déployé au sein d'un VPC, la meilleure pratique consiste à mettre en œuvre la sécurité par couches. Assurez-vous de vérifier la configuration de vos stratégies d'accès actuelles.
Appliquez une politique d'accès restrictive basée sur les ressources à vos domaines et suivez le principe du moindre privilège lorsque vous accordez l'accès à l'API de configuration et aux opérations de l' OpenSearch API. En règle générale, évitez d'utiliser le principal utilisateur anonyme "Principal": {"AWS": "*" } dans vos stratégies d'accès.
Cependant, dans certaines situations, il est acceptable d'utiliser une stratégie d'accès ouverte, par exemple lorsque vous activez le contrôle précis des accès. Une stratégie d'accès ouverte peut vous permettre d'accéder au domaine dans les cas où la signature de la demande est difficile ou impossible, par exemple à partir de certains clients et outils.
Activer le chiffrement au repos
OpenSearch Les domaines de service permettent de chiffrer les données au repos afin d'empêcher tout accès non autorisé à vos données. Le chiffrement au repos utilise AWS Key Management Service (AWS KMS) pour stocker et gérer vos clés de chiffrement, et l'algorithme Advanced Encryption Standard avec des clés de 256 bits (AES-256) pour effectuer le chiffrement.
Si votre domaine stocke des données sensibles, activez le chiffrement des données au repos.
Activer node-to-node le chiffrement
Node-to-node le chiffrement fournit une couche de sécurité supplémentaire en plus des fonctionnalités de sécurité par défaut du OpenSearch Service. Il implémente le protocole TLS (Transport Layer Security) pour toutes les communications entre les nœuds qui y sont provisionnés. OpenSearch Node-to-nodechiffrement : toutes les données envoyées à votre domaine de OpenSearch service via HTTPS restent cryptées en transit pendant leur distribution et leur réplication entre les nœuds.
Si votre domaine stocke des données sensibles, activez node-to-node le chiffrement.
Moniteur avec AWS Security Hub
Surveillez votre utilisation du OpenSearch Service en ce qui concerne les meilleures pratiques de sécurité en utilisant AWS Security Hub. Security Hub utilise des contrôles de sécurité pour évaluer les configurations des ressources et les normes de sécurité afin de vous aider à respecter divers cadres de conformité. Pour plus d'informations sur l'utilisation de Security Hub pour évaluer les ressources OpenSearch du service, consultez la section Amazon OpenSearch Service Contrôles du Guide de AWS Security Hub l'utilisateur.
Optimisation des coûts
Les meilleures pratiques suivantes s'appliquent à l'optimisation et à la réduction de vos coûts OpenSearch de service.
Utiliser les types d'instance de dernière génération
OpenSearch Le service adopte constamment de nouveaux types d' EC2 instances Amazon qui offrent de meilleures performances à moindre coût. Nous vous recommandons de toujours utiliser les instances de dernière génération.
Évitez d'utiliser des instances T2 ou t3.small pour les domaines de production, car elles peuvent devenir instables sous une charge élevée soutenue. Les instances r6g.large constituent une bonne option pour les petites charges de travail de production (à la fois en tant que nœuds de données et en tant que nœuds principaux dédiés).
Utilisation des derniers volumes Amazon EBS gp3
OpenSearch les nœuds de données nécessitent une faible latence et un stockage à haut débit pour permettre une indexation et des requêtes rapides. Grâce aux volumes Amazon EBS gp3, vous obtenez des performances de base supérieures (IOPS et débit) à un coût inférieur de 9,6 % à celui du type de volume Amazon EBS gp2 proposé précédemment. Vous pouvez fournir des IOPS et des débits supplémentaires indépendamment de la taille du volume à l'aide de gp3. Ces volumes sont également plus stables que ceux de la génération précédente, car ils n'utilisent pas de crédits en rafale. Le type de volume gp3 double également les limites de taille de per-data-node volume du type de volume gp2. Grâce à ces volumes plus importants, vous pouvez réduire le coût des données passives en augmentant la quantité de stockage par nœud de données.
Utilisation UltraWarm et stockage à froid pour les données des journaux de séries chronologiques
Si vous OpenSearch les utilisez pour l'analyse des journaux, déplacez vos données vers un UltraWarm stockage à froid afin de réduire les coûts. Utilisez Index State Management (ISM) pour migrer les données entre les niveaux de stockage et gérer la conservation des données.
UltraWarmconstitue un moyen rentable de stocker de grandes quantités de données en lecture seule dans OpenSearch Service. UltraWarm utilise Amazon S3 pour le stockage, ce qui signifie que les données sont immuables et qu'une seule copie est nécessaire. Vous ne payez que pour un stockage équivalent à la taille des partitions principales de vos index. Les latences des UltraWarm requêtes augmentent en fonction de la quantité de données S3 nécessaires pour traiter la requête. Une fois les données mises en cache sur les nœuds, les requêtes vers les UltraWarm index fonctionnent de la même manière que les requêtes vers les index actifs.
Le stockage cold est également basé sur S3. Lorsque vous devez interroger des données confidentielles, vous pouvez les associer de manière sélective à des UltraWarm nœuds existants. Le coût du stockage géré pour les données froides est le même que pour le stockage à froid UltraWarm, mais les objets stockés à froid ne consomment pas les ressources des UltraWarm nœuds. Par conséquent, le stockage à froid fournit une capacité de stockage significative sans impact sur la taille ou le nombre de UltraWarm nœuds.
UltraWarm devient rentable lorsque vous avez environ 2,5 TiB de données à migrer depuis le stockage à chaud. Surveillez votre taux de remplissage et prévoyez de déplacer les index UltraWarm avant d'atteindre ce volume de données.
Examiner les recommandations pour les instances réservées
Envisagez d'acheter des instances réservées (RIs) une fois que vous aurez une bonne base de référence sur vos performances et votre consommation de calcul. Les remises commencent aux alentours de 30 % pour les réservations d'un an sans versement initial et peuvent augmenter jusqu'à 50 % pour les engagements initiaux de trois ans.
Après avoir observé un fonctionnement stable pendant au moins 14 jours, consultez la section Accès aux recommandations de réservation dans le guide de AWS Cost Management l'utilisateur. L'en-tête Amazon OpenSearch Service affiche des recommandations d'achat spécifiques au RI et des économies prévues.
