Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Consommateurs de données
Les consommateurs de données consomment les données du producteur de données une fois que le catalogue centralisé les a partagées à l'aide de celles-ci AWS Lake Formation. Le schéma suivant montre deux consommateurs de données dans le lac de données.
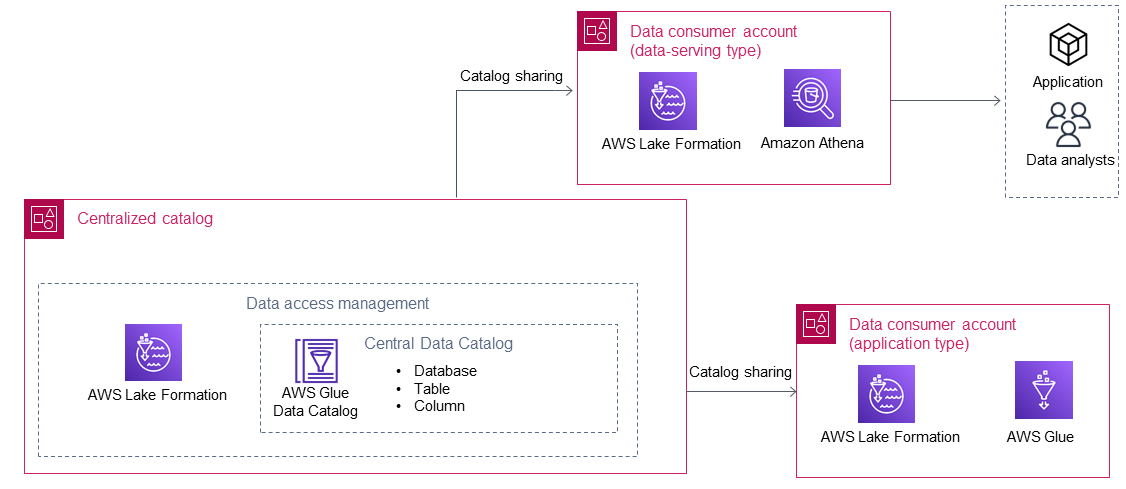
Il existe deux types de consommateurs de données : les applications et les serveurs de données. Le tableau suivant décrit ces deux types.
| Type de demande |
Les consommateurs de données d'applications exécutent leurs propres applications Comptes AWS. Les applications utilisent les rôles AWS Identity and Access Management (IAM) pour accéder aux données partagées par un producteur de données, puis les traiter conformément à leur logique. Généralement, ce type de consommateur de données a des exigences prescriptives en matière de données pour répondre aux besoins d'une application. |
| Type de service de données |
Les consommateurs de données au service de données sont généralement destinés aux particuliers (par exemple, les analystes de données ou les scientifiques des données) et aux applications (par exemple, une application de business intelligence) qui ne disposent pas de leur propre Comptes AWS application. Plusieurs consommateurs de données au service des données peuvent exister dans le lac de données d'une entreprise. Par exemple, différents secteurs d'activité peuvent choisir de configurer leurs propres consommateurs de données pour aider les utilisateurs à utiliser les données du lac de données. Ces consommateurs de données ont leurs propres principes de rôle IAM configurés dans leurs propres rôles Compte AWS (par exemple, les rôles IAM associés AWS IAM Identity Center) qui sont utilisés par les utilisateurs finaux dans le compte du consommateur de données pour accéder aux données partagées via des AWS services (par exemple, Amazon Athena). Généralement, ce type de consommateur de données a des besoins en données très variés et en constante augmentation. |
AWS Lake Formation est le AWS service le plus important utilisé par un consommateur de données pour le partage de données entre comptes et l'accès au catalogue centralisé. Une fois les bases de données partagées par le catalogue centralisé, les ressources partagées sont disponibles dans Lake Formation dans le compte du consommateur de données. L'accès aux données peut ensuite être accordé aux responsables IAM locaux dans le compte du consommateur de données, avec l'autorisation du producteur de données, si nécessaire. Les données partagées peuvent ensuite être utilisées par AWS des services intégrés à Lake Formation (par exemple, Amazon Athena et AWS Glue). Vous pouvez utiliser les AWS services suivants pour accéder aux données partagées dans le compte du consommateur de données :
-
Amazon Athena est un service de requête interactif qui permet d'analyser directement les données dans Amazon Simple Storage Service (Amazon S3) à l'aide du SQL standard. Pour plus d'informations sur Athéna et Lake Formation, consultez la section Comment Athena accède aux données enregistrées auprès de Lake Formation dans la documentation Amazon Athena.
-
Amazon Redshift Spectrum vous aide à interroger et à récupérer efficacement des données structurées et semi-structurées à partir de fichiers dans Amazon S3 sans avoir à les charger dans des tables Amazon Redshift. Pour plus d'informations sur Redshift Spectrum et Lake Formation, consultez la section Using Redshift Spectrum with Lake Formation dans la documentation Amazon Redshift.
-
AWS Glueest un service d'extraction, de transformation et de chargement (ETL) entièrement géré qui permet de classer vos données de manière simple et rentable, de les nettoyer, de les enrichir et de les déplacer de manière fiable entre différents magasins de données et flux de données. Le rôle IAM associé à une tâche AWS Glue ETL peut accéder aux données du lac de données géré par Lake Formation s'il dispose des autorisations d'accès requises.
-
Amazon EMR permet d'exécuter des infrastructures de mégadonnées (par exemple, Apache Hadoop
et Apache Spark ) pour traiter et analyser de grandes quantités de données. Pour plus d'informations sur Amazon EMR et Lake Formation, consultez la section Intégrer Amazon EMR à Lake Formation dans la documentation Amazon EMR. -
Amazon QuickSight est un service de business intelligence évolutif, sans serveur, intégrable et basé sur le machine learning (ML) que vous pouvez utiliser pour analyser et visualiser les données de votre lac de données. Pour plus d'informations sur QuickSight Lake Formation, consultez la section Autorisation des connexions via Lake Formation dans la QuickSight documentation.
-
Amazon SageMaker AI Data Wrangler (Data Wrangler) réduit le temps nécessaire pour agréger et préparer les données pour le ML. Pour plus d'informations sur Data Wrangler et Lake Formation, consultez Prepare ML Data with Amazon SageMaker AI Data Wrangler dans la documentation Amazon AI. SageMaker
