Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Bonnes pratiques pour la prévision de la demande de nouveaux produits
Cette section décrit les meilleures pratiques suivantes pour la prévision de la demande de nouveaux produits :
Répondez aux exigences de préparation des données pour une prévision de la NPI demande basée sur les données
Pour adopter des approches axées sur les données pour NPI la prévision de la demande, votre organisation doit obtenir le soutien de toutes les parties prenantes concernées, telles que les responsables du département de la science ou de l'analyse des données, de la chaîne d'approvisionnement, du marketing et de l'informatique. Votre organisation doit ensuite identifier les éléments suivants :
-
Les sources des données internes existantes et des données externes pertinentes
-
Les propriétaires de ces sources de données
-
Les procédures et autorisations requises pour utiliser ces sources de données dans le cadre de l'initiative
Vous pouvez évaluer l'état de préparation de vos données par rapport aux types de jeux de données obligatoires et facultatifs suivants. L'utilisation d'autant de jeux de données que possible, y compris le type facultatif, permet aux modèles d'apprentissage automatique de générer des prévisions de NPI demande plus précises.
Voici des exemples de sources de données internes requises :
-
Historique complet des ventes (du lancement du produit à son arrêt) pour tous les produits ou sous-ensembles de produits présentant des caractéristiques similaires à celles du nouveau produit lancé. L'historique des ventes peut provenir de plusieurs canaux de vente ou être combiné à tous les canaux.
-
Mappage des attributs du produit pour identifier le sous-ensemble de produits présentant des attributs similaires à ceux du nouveau produit lancé.
Voici des exemples de sources de données internes facultatives :
-
Données marketing permettant de suivre les promotions et les remises sur des produits similaires. Ces données doivent être égales ou supérieures à la longueur de l'historique des ventes.
-
Évaluations de produits, évaluations et données sur le trafic Web. Ces données doivent être égales ou supérieures à la longueur de l'historique des ventes.
-
Données démographiques sur les consommateurs
Voici des exemples de sources de données externes facultatives qui peuvent compléter vos données internes :
-
Données de l'indice de consommation
-
Données sur les ventes des concurrents
-
Données d'enquête
Créez des mécanismes d'ingestion de données rentables
Une fois que vos exigences en matière de préparation des données sont satisfaites, votre organisation peut choisir les mécanismes d'ingestion et de stockage des données les plus appropriés. Si les principales sources de données de vente de votre organisation sont collectées quotidiennement à partir de différents canaux, envisagez l'ingestion de données par lots. L'ingestion de données en streaming est une autre option si vous souhaitez des prévisions en libre-service qui tirent parti des données les plus récentes.
Le pipeline d'ingestion de données brutes doit utiliser un pipeline extract, transform et load (ETL) pour une transformation légère. Le pipeline doit effectuer des contrôles de qualité des données et stocker les données traitées dans une base de données pour une consommation en aval.
Vous pouvez Services AWS notamment utiliser Amazon Data Firehose et Amazon Simple Storage Service (Amazon S3) pour une ingestion et un stockage de données rentables. AWS GlueAWS Glue Data Catalog AWS Glue est un ETL service sans serveur entièrement géré qui vous aide à classer, nettoyer, transformer et transférer de manière fiable des données entre différents magasins de données. Les composants principaux de AWS Glue sont un référentiel central de métadonnées, connu sous le nom de AWS Glue Data Catalog, et un système de ETL tâches qui génère automatiquement du code Python et Scala et gère les ETL tâches. Amazon Data Firehose vous aide à collecter, traiter et analyser des données de streaming en temps réel à n'importe quelle échelle. Firehose peut fournir des données de streaming en temps réel directement aux lacs de données (tels qu'Amazon S3), aux magasins de données et aux services d'analyse pour un traitement ultérieur. Amazon S3 est un service de stockage d'objets qui offre évolutivité, disponibilité des données, sécurité et performances.
Déterminer les approches de machine learning réalisables pour prévoir NPI la demande
En fonction du cas d'utilisation spécifique, votre organisation peut envisager différentes options de prévision.
Une approche de prévision statistique, comme le modèle de diffusion de Bass
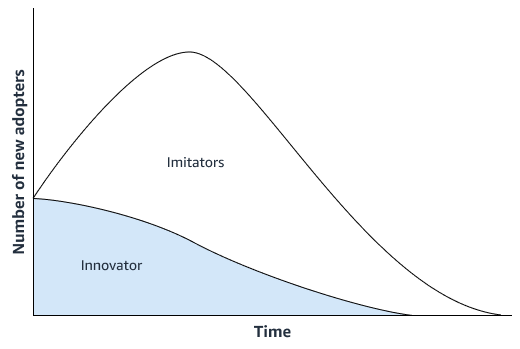
Si le nouveau produit ne présente pas d'innovation significative, votre organisation peut utiliser des modèles de prévision de séries chronologiques qui fonctionnent sur l'historique des ventes du produit le plus similaire au nouveau produit. Vous pouvez utiliser des algorithmes de prévision basés sur le ML, tels que l'algorithme de prévision Amazon AI SageMaker DeePar, qui peuvent utiliser des séries chronologiques de données de ventes provenant de plusieurs produits similaires. Cela convient parfaitement aux scénarios de prévision par démarrage à froid, c'est-à-dire lorsque vous souhaitez générer une prévision pour une série chronologique mais que vous ne disposez que de peu ou pas de données historiques. L'image suivante montre comment utiliser les données de séries chronologiques de produits connexes pour générer une prévision pour un nouveau produit similaire.
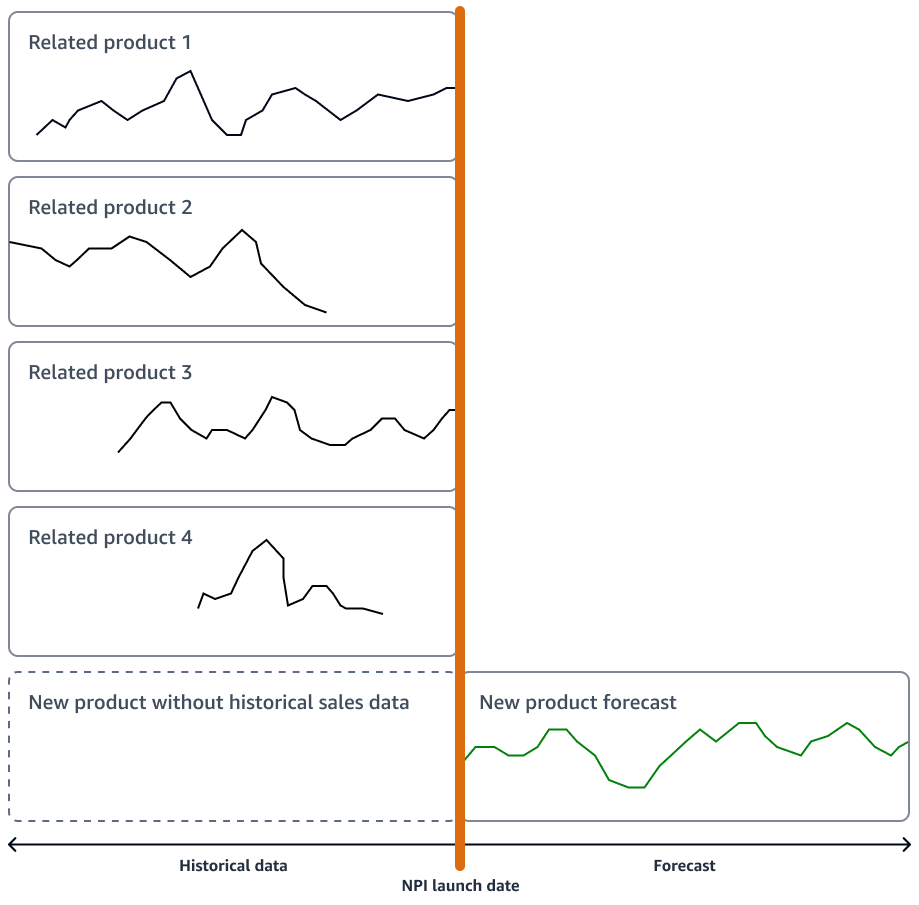
Vous devriez envisager de générer des prévisions qui correspondent au calendrier de lancement de votre nouveau produit. Générez des prévisions bien à l'avance afin de disposer d'une marge de manœuvre suffisante pour toute correction logistique.
Mesurer et suivre les effets des prévisions
Après avoir terminé une validation de principe pour NPI la prévision de la demande, la solution devrait éventuellement être étendue pour inclure des produits supplémentaires et plusieurs régions. Utilisez un cadre d'intelligence artificielle et d'apprentissage automatique (IA/ML) pour préparer les données et développer, déployer et surveiller le modèle.
Le schéma suivant illustre la stratégie de lancement et de mise à l'échelle au fur et à mesure que la solution de NPI prévision de l'organisation arrive à maturité.
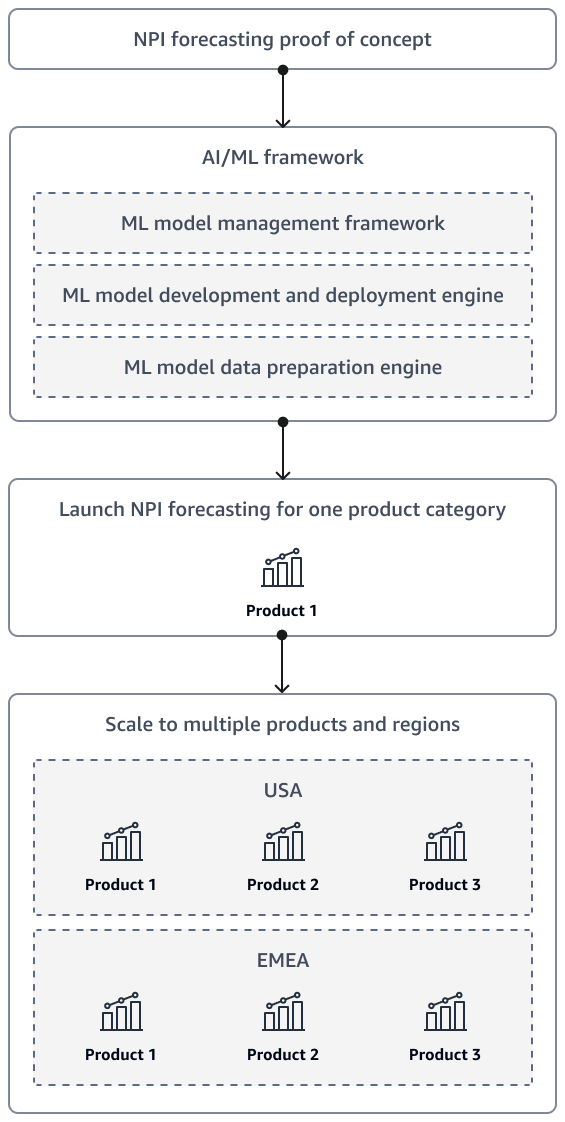
Il est également recommandé de concevoir la solution de manière à ce que les dirigeants et les parties prenantes puissent établir des prévisions en libre-service. Par exemple, vous pouvez créer des QuickSighttableaux de bord Amazon afin que les parties prenantes puissent accéder aux dernières prévisions à la demande.
Surveillez de près la précision des prévisions et étudiez de manière approfondie les écarts afin de garantir un retour sur investissement raisonnable (ROI). Si vous configurez la surveillance des modèles avec Amazon SageMaker AI Model Monitor, vous pouvez suivre les performances de vos modèles lorsqu'ils font des prédictions en temps réel sur des données en temps réel. Vous pouvez utiliser le tableau de bord Amazon SageMaker Model pour identifier les modèles qui ne respectent pas les seuils que vous avez définis en matière de qualité des données, de qualité du modèle, de biais et d'explicabilité. Pour plus d'informations, consultez Utiliser la gouvernance pour gérer les autorisations et suivre les performances des modèles dans la documentation Amazon SageMaker AI.
