Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Émulez des baies PL/SQL associatives Oracle dans Amazon Aurora PostgreSQL et Amazon RDS for PostgreSQL
Rajkumar Raghuwanshi, Bhanu Ganesh Gudivada et Sachin Khanna, Amazon Web Services
Récapitulatif
Ce modèle décrit comment émuler des tableaux PL/SQL associatifs Oracle avec des positions d'index vides dans les environnements Amazon Aurora PostgreSQL et Amazon RDS for PostgreSQL
Nous proposons une alternative PostgreSQL à l'aws_oracle_extutilisation de fonctions pour gérer les positions d'index vides lors de la migration d'une base de données Oracle. Ce modèle utilise une colonne supplémentaire pour stocker les positions des index et il permet à Oracle de gérer les tableaux épars tout en incorporant les fonctionnalités natives de PostgreSQL.
Oracle
Dans Oracle, les collections peuvent être initialisées comme vides et remplies à l'aide de la méthode de EXTEND collecte, qui ajoute NULL des éléments au tableau. Lorsque vous travaillez avec des tableaux PL/SQL associatifs indexés parPLS_INTEGER, la EXTEND méthode ajoute des éléments de manière séquentielle, mais NULL les éléments peuvent également être initialisés à des positions d'index non séquentielles. Toute position d'index qui n'est pas explicitement initialisée reste vide.
Cette flexibilité permet des structures matricielles clairsemées dans lesquelles les éléments peuvent être remplis à des positions arbitraires. Lorsque vous itérez dans des collections à l'aide d'un FOR LOOP with FIRST et LAST d'une limite, seuls les éléments initialisés (qu'ils aient NULL ou non une valeur définie) sont traités, tandis que les positions vides sont ignorées.
PostgreSQL (Amazon Aurora et Amazon RDS)
PostgreSQL gère les valeurs vides différemment des valeurs. NULL Il stocke les valeurs vides sous forme d'entités distinctes qui utilisent un octet de stockage. Lorsqu'un tableau contient des valeurs vides, PostgreSQL attribue des positions d'index séquentielles comme des valeurs non vides. Mais l'indexation séquentielle nécessite un traitement supplémentaire car le système doit itérer sur toutes les positions indexées, y compris les positions vides. Cela rend la création de tableaux traditionnelle inefficace pour les ensembles de données épars.
AWS Schema Conversion Tool
Le AWS Schema Conversion Tool (AWS SCT) gère généralement les Oracle-to-PostgreSQL migrations à l'aide de aws_oracle_ext fonctions. Dans ce modèle, nous proposons une approche alternative qui utilise les fonctionnalités natives de PostgreSQL, qui combine les types de tableaux PostgreSQL avec une colonne supplémentaire pour stocker les positions d'index. Le système peut ensuite itérer dans les tableaux en utilisant uniquement la colonne d'index.
Conditions préalables et limitations
Prérequis
Un actif Compte AWS.
Un utilisateur AWS Identity and Access Management (IAM) doté d'autorisations d'administrateur.
Une instance compatible avec Amazon RDS ou Aurora PostgreSQL.
Compréhension de base des bases de données relationnelles.
Limites
Certains Services AWS ne sont pas disponibles du tout Régions AWS. Pour connaître la disponibilité par région, voir Services AWS par région
. Pour des points de terminaison spécifiques, consultez la page Points de terminaison et quotas du service, puis choisissez le lien vers le service.
Versions du produit
Ce modèle a été testé avec les versions suivantes :
Amazon Aurora PostgreSQL 13.3
Amazon RDS pour PostgreSQL 13.3
AWS SCT 1,0674
Oracle 12c EE 12.2
Architecture
Pile technologique source
Base de données Oracle sur site
Pile technologique cible
Amazon Aurora PostgreSQL
Amazon RDS for PostgreSQL
Architecture cible
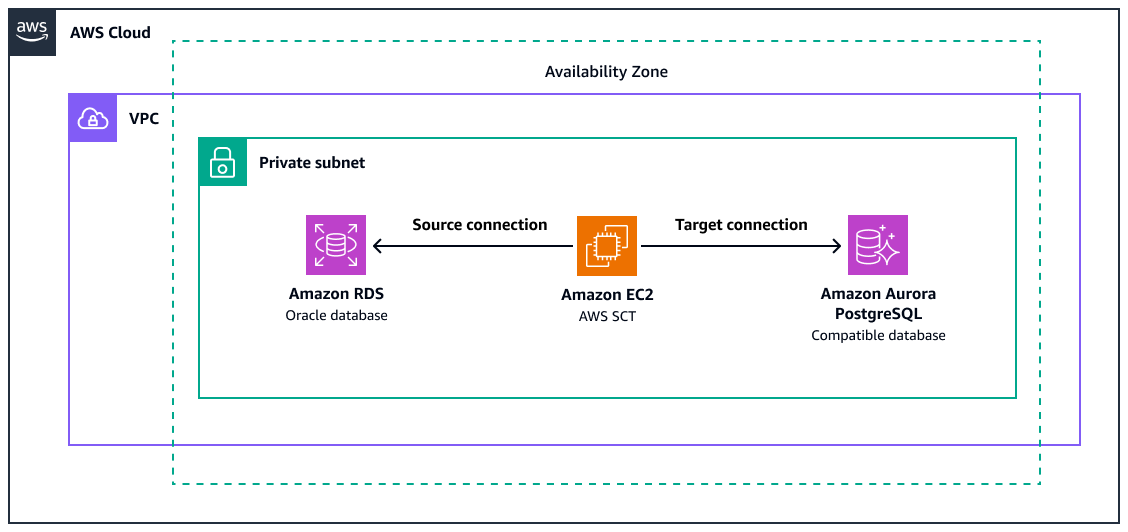
Le diagramme décrit les éléments suivants :
Une instance de base de données Amazon RDS for Oracle source
Une EC2 instance Amazon permettant de convertir AWS SCT les fonctions Oracle en l'équivalent de PostgreSQL
Une base de données cible compatible avec Amazon Aurora PostgreSQL
Outils
Services AWS
Amazon Aurora est un moteur de base de données relationnelle entièrement géré conçu pour le cloud et compatible avec MySQL et PostgreSQL.
Amazon Aurora PostgreSQL Compatible Edition est un moteur de base de données relationnelle entièrement géré et compatible ACID qui vous aide à configurer, exploiter et dimensionner les déploiements PostgreSQL.
Amazon Elastic Compute Cloud (Amazon EC2) fournit une capacité de calcul évolutive dans le AWS Cloud. Vous pouvez lancer autant de serveurs virtuels que vous le souhaitez et les augmenter ou les diminuer rapidement.
Amazon Relational Database Service (Amazon RDS) vous aide à configurer, exploiter et dimensionner une base de données relationnelle dans le. AWS Cloud
Amazon Relational Database Service (Amazon RDS) pour Oracle vous aide à configurer, exploiter et dimensionner une base de données relationnelle Oracle dans le. AWS Cloud
Amazon Relational Database Service (Amazon RDS) pour PostgreSQL vous aide à configurer, exploiter et dimensionner une base de données relationnelle PostgreSQL dans le. AWS Cloud
AWS Schema Conversion Tool (AWS SCT) prend en charge les migrations de bases de données hétérogènes en convertissant automatiquement le schéma de base de données source et la majorité du code personnalisé dans un format compatible avec la base de données cible.
Autres outils
Oracle SQL Developer
est un environnement de développement intégré qui simplifie le développement et la gestion des bases de données Oracle dans les déploiements traditionnels et basés sur le cloud. pgAdmin
est un outil de gestion open source pour PostgreSQL. Il fournit une interface graphique qui vous permet de créer, de gérer et d'utiliser des objets de base de données. Dans ce modèle, pgAdmin se connecte à l'instance de base de données RDS pour PostgreSQL et interroge les données. Vous pouvez également utiliser le client de ligne de commande psql.
Bonnes pratiques
Testez les limites des ensembles de données et les scénarios périphériques.
Envisagez d'implémenter la gestion des erreurs pour les conditions d' out-of-boundsindex.
Optimisez les requêtes pour éviter de scanner des ensembles de données fragmentés.
Épopées
| Tâche | Description | Compétences requises |
|---|---|---|
Créez un PL/SQL bloc source dans Oracle. | Créez un PL/SQL bloc source dans Oracle qui utilise le tableau associatif suivant :
| DBA |
Exécutez le PL/SQL bloc. | Exécutez le PL/SQL bloc source dans Oracle. S'il existe des écarts entre les valeurs d'index d'un tableau associatif, aucune donnée n'est stockée dans ces espaces. Cela permet à la boucle Oracle d'itérer uniquement sur les positions de l'index. | DBA |
Vérifiez la sortie. | Cinq éléments ont été insérés dans le tableau (
| DBA |
| Tâche | Description | Compétences requises |
|---|---|---|
Créez un PL/pgSQL bloc cible dans PostgreSQL. | Créez un PL/pgSQL bloc cible dans PostgreSQL qui utilise le tableau associatif suivant :
| DBA |
Exécutez le PL/pgSQL bloc. | Exécutez le PL/pgSQL bloc cible dans PostgreSQL. S'il existe des écarts entre les valeurs d'index d'un tableau associatif, aucune donnée n'est stockée dans ces espaces. Cela permet à la boucle Oracle d'itérer uniquement sur les positions de l'index. | DBA |
Vérifiez la sortie. | La longueur du tableau est supérieure à 5 car elle
| DBA |
| Tâche | Description | Compétences requises |
|---|---|---|
Créez un PL/pgSQL bloc cible avec un tableau et un type défini par l'utilisateur. | Pour optimiser les performances et correspondre aux fonctionnalités d'Oracle, nous pouvons créer un type défini par l'utilisateur qui stocke à la fois les positions de l'indice et les données correspondantes. Cette approche réduit les itérations inutiles en maintenant des associations directes entre les indices et les valeurs.
| DBA |
Exécutez le PL/pgSQL bloc. | Exécutez le PL/pgSQL bloc cible. S'il existe des écarts entre les valeurs d'index d'un tableau associatif, aucune donnée n'est stockée dans ces espaces. Cela permet à la boucle Oracle d'itérer uniquement sur les positions de l'index. | DBA |
Vérifiez la sortie. | Comme indiqué dans le résultat suivant, le type défini par l'utilisateur ne stocke que les éléments de données renseignés, ce qui signifie que la longueur du tableau correspond au nombre de valeurs. Par conséquent,
| DBA |
Ressources connexes
AWS documentation
Autres documentations
