Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Migrez une base de données Oracle sur site vers Amazon RDS for Oracle en utilisant directement Oracle Data Pump Import via un lien de base de données
Rizwan Wangde, Amazon Web Services
Récapitulatif
De nombreux modèles couvrent la migration de bases de données Oracle sur site vers Amazon Relational Database Service (Amazon RDS) pour Oracle à l'aide d'Oracle Data Pump, un utilitaire Oracle natif qui constitue le moyen préféré pour migrer de grandes charges de travail Oracle. Ces modèles impliquent généralement l'exportation de schémas ou de tables d'application dans des fichiers de vidage, le transfert des fichiers de vidage vers un répertoire de base de données sur Amazon RDS for Oracle, puis l'importation des schémas d'application et des données à partir des fichiers de vidage.
Avec cette approche, une migration peut prendre plus de temps en fonction de la taille des données et du temps nécessaire pour transférer les fichiers de vidage vers l'instance Amazon RDS. En outre, les fichiers de vidage se trouvent sur le volume Amazon Elastic Block Store (Amazon EBS) de l'instance Amazon RDS, qui doit être suffisamment grand pour contenir la base de données et les fichiers de vidage. Lorsque les fichiers de vidage sont supprimés après l'importation, l'espace vide ne peut pas être récupéré. Vous continuez donc à payer pour l'espace inutilisé.
Ce modèle atténue ces problèmes en effectuant une importation directe sur l'instance Amazon RDS à l'aide de l'API Oracle Data Pump (DBMS_DATAPUMP) via un lien de base de données. Le modèle lance un pipeline d'exportation et d'importation simultané entre les bases de données source et cible. Ce modèle ne nécessite pas de dimensionner un volume EBS pour les fichiers de vidage car aucun fichier de vidage n'est créé ou stocké sur le volume. Cette approche permet d'économiser le coût mensuel de l'espace disque inutilisé.
Conditions préalables et limitations
Prérequis
Un compte Amazon Web Services (AWS) actif.
Un cloud privé virtuel (VPC) configuré avec des sous-réseaux privés répartis sur au moins deux zones de disponibilité, afin de fournir l'infrastructure réseau pour l'instance Amazon RDS.
Une base de données Oracle dans un centre de données sur site ou autogérée sur Amazon Elastic Compute Cloud (Amazon EC2).
Une instance Amazon RDS pour Oracle existante dans une seule zone de disponibilité. L'utilisation d'une seule zone de disponibilité améliore les performances d'écriture lors de la migration. Un déploiement multi-AZ peut être activé 24 à 48 heures avant le passage au relais.
Cette solution peut également utiliser Amazon RDS Custom for Oracle comme cible.
AWS Direct Connect (recommandé pour les bases de données de grande taille).
Les règles de connectivité réseau et de pare-feu sur site sont configurées pour autoriser une connexion entrante entre l'instance Amazon RDS et la base de données Oracle sur site.
Limites
La limite de taille de base de données sur Amazon RDS for Oracle est de 64 tebioctets (TiB) en décembre 2022.
La taille maximale d'un seul fichier sur une instance de base de données Amazon RDS for Oracle est de 16 TiB. Il est important de le savoir car vous devrez peut-être répartir les tables sur plusieurs tablespaces.
Versions du produit
Base de données source : Oracle Database version 10g version 1 et versions ultérieures.
Base de données cible : pour obtenir la dernière liste des versions et éditions prises en charge sur Amazon RDS, consultez Amazon RDS for Oracle dans la documentation AWS.
Architecture
Pile technologique source
Base de données Oracle autogérée sur site ou dans le cloud
Pile technologique cible
Amazon RDS pour Oracle ou Amazon RDS Custom pour Oracle
Architecture cible
Le schéma suivant montre l'architecture permettant de migrer d'une base de données Oracle sur site vers Amazon RDS for Oracle dans un environnement mono-AZ. Les flèches indiquent le flux de données dans l'architecture. Le schéma ne montre pas quel composant initie la connexion.
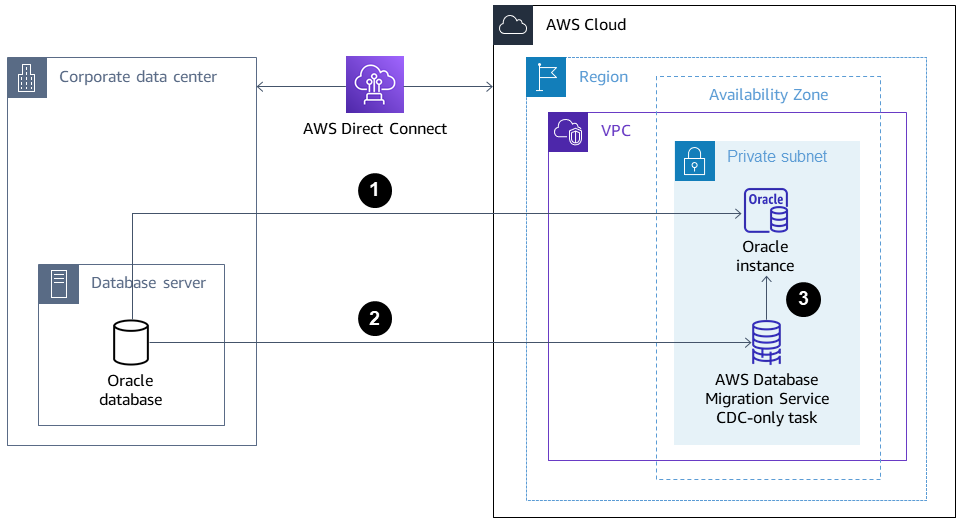
L'instance Amazon RDS for Oracle se connecte à la base de données Oracle source sur site pour effectuer une migration complète via le lien de base de données.
AWS Database Migration Service (AWS DMS) se connecte à la base de données Oracle source sur site pour effectuer une réplication continue à l'aide de la capture des données de modification (CDC).
Les modifications du CDC sont appliquées à la base de données Amazon RDS for Oracle.
Outils
Services AWS
AWS Database Migration Service (AWS DMS) vous aide à migrer les banques de données vers AWS Cloud ou entre des combinaisons de configurations cloud et sur site. Ce modèle utilise le CDC et le paramètre Répliquer les données uniquement change.
AWS Direct Connectrelie votre réseau interne à un AWS Direct Connect emplacement via un câble à fibre optique Ethernet standard. Grâce à cette connexion, vous pouvez créer des interfaces virtuelles directement destinées au public Services AWS tout en contournant les fournisseurs de services Internet sur votre chemin réseau.
Amazon Relational Database Service vous aide à configurer, exploiter et dimensionner une base de données relationnelle Oracle dans le cloud AWS.
Autres outils
Oracle Data Pump
vous aide à déplacer des données et des métadonnées d'une base de données à une autre à grande vitesse. Les outils clients tels qu'Oracle Instant Client
ou SQL Developer sont utilisés pour connecter et exécuter des requêtes SQL sur la base de données.
Bonnes pratiques
Bien qu'il AWS Direct Connect utilise des connexions réseau privées dédiées entre le réseau local AWS, envisagez les options suivantes pour renforcer la sécurité et le chiffrement des données en transit :
Un réseau privé virtuel (VPN) utilisant AWS Site-to-Site VPN ou une connexion IPsec VPN entre le réseau local et le AWS réseau
Chiffrement réseau natif de la base de données Oracle
configuré sur la base de données Oracle locale Chiffrement à l'aide de TLS
Épopées
| Tâche | Description | Compétences requises |
|---|---|---|
Configurez la connectivité réseau entre la base de données cible et la base de données source. | Configurez le réseau et le pare-feu sur site pour autoriser la connexion entrante entre l'instance Amazon RDS cible et la base de données Oracle source sur site. | Administrateur réseau, ingénieur en sécurité |
Créez un utilisateur de base de données doté des privilèges appropriés. | Créez un utilisateur de base de données dans la base de données Oracle source locale avec les privilèges nécessaires pour migrer les données entre la source et la cible à l'aide d'Oracle Data Pump :
| DBA |
Préparez la base de données source sur site pour la migration AWS DMS CDC. | (Facultatif) Préparez la base de données Oracle source sur site pour la migration AWS DMS CDC une fois le chargement complet d'Oracle Data Pump terminé :
| DBA |
Installez et configurez SQL Developer. | Installez et configurez SQL Developer | DBA, ingénieur en migration |
Générez un script pour créer les tablespaces. | Utilisez l'exemple de requête SQL suivant pour générer le script dans la base de données source :
Le script sera appliqué à la base de données cible. | DBA |
Générez un script pour créer des utilisateurs, des profils, des rôles et des privilèges. | Pour générer un script permettant de créer les utilisateurs, les profils, les rôles et les privilèges de la base de données, utilisez les scripts du document de support Oracle How to Extract DDL for User including Privileges and Roles Using dbms_metadata.get_ddl Le script sera appliqué à la base de données cible. | DBA |
| Tâche | Description | Compétences requises |
|---|---|---|
Créez un lien de base de données vers la base de données source et vérifiez la connectivité. | Pour créer un lien de base de données vers la base de données source locale, vous pouvez utiliser l'exemple de commande suivant :
Pour vérifier la connectivité, exécutez la commande SQL suivante :
La connectivité est réussie si la réponse l'est | DBA |
Exécutez les scripts pour préparer l'instance cible. | Exécutez les scripts générés précédemment pour préparer l'instance Amazon RDS for Oracle cible :
Cela permet de garantir que la migration d'Oracle Data Pump peut créer les schémas et leurs objets. | DBA, ingénieur en migration |
| Tâche | Description | Compétences requises |
|---|---|---|
Migrez les schémas requis. | Pour migrer les schémas requis de la base de données source sur site vers l'instance Amazon RDS cible, utilisez le code de la section Informations supplémentaires :
Pour optimiser les performances de la migration, vous pouvez ajuster le nombre de processus parallèles en exécutant la commande suivante :
| DBA |
Collectez des statistiques de schéma pour améliorer les performances. | La commande Gather Schema Statistics renvoie les statistiques de l'optimiseur de requêtes Oracle collectées pour les objets de base de données. À l'aide de ces informations, l'optimiseur peut sélectionner le meilleur plan d'exécution pour toute requête portant sur les objets suivants :
| DBA |
| Tâche | Description | Compétences requises |
|---|---|---|
Capturez le SCN sur la base de données Oracle locale source. | Capturez le numéro de modification du système (SCN) Pour générer le SCN actuel sur la base de données source, exécutez l'instruction SQL suivante :
| DBA |
Effectuez la migration complète des schémas. | Pour migrer les schémas requis (
Dans le code, remplacez-le
Pour optimiser les performances de la migration, vous pouvez ajuster le nombre de processus parallèles :
| DBA |
Désactivez les déclencheurs dans les schémas migrés. | Avant de commencer la tâche AWS DMS réservée aux CDC, désactivez-les | DBA |
Collectez des statistiques de schéma pour améliorer les performances. | La commande Gather Schema Statistics renvoie les statistiques de l'optimiseur de requêtes Oracle collectées pour les objets de base de données :
À l'aide de ces informations, l'optimiseur peut sélectionner le meilleur plan d'exécution pour toute requête portant sur ces objets. | DBA |
AWS DMS À utiliser pour effectuer une réplication continue de la source vers la cible. | AWS DMS À utiliser pour effectuer une réplication continue de la base de données Oracle source vers l'instance Amazon RDS for Oracle cible. Pour plus d'informations, consultez la section Création de tâches pour une réplication continue à l'aide AWS DMS et le billet de blog How to work with native CDC support in AWS DMS | DBA, ingénieur en migration |
| Tâche | Description | Compétences requises |
|---|---|---|
Activez le mode Multi-AZ sur l'instance 48 heures avant le passage à une autre instance. | S'il s'agit d'une instance de production, nous recommandons d'activer le déploiement multi-AZ sur l'instance Amazon RDS afin de bénéficier des avantages de la haute disponibilité (HA) et de la reprise après sinistre (DR). | DBA, ingénieur en migration |
Arrêtez la tâche AWS DMS uniquement sur le CDC (si le CDC était activé). |
| DBA |
Activez les déclencheurs. | Activez celle | DBA |
Ressources connexes
AWS
Documentation Oracle
Informations supplémentaires
Code 1 : migration à chargement complet uniquement, schéma d'application unique
DECLARE v_hdnl NUMBER; BEGIN v_hdnl := DBMS_DATAPUMP.OPEN(operation => 'IMPORT', job_mode => 'SCHEMA', remote_link => '<DB LINK Name to Source Database>', job_name => null); DBMS_DATAPUMP.ADD_FILE( handle => v_hdnl, filename => 'import_01.log', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_log_file); DBMS_DATAPUMP.METADATA_FILTER(v_hdnl,'SCHEMA_EXPR','IN (''<schema_name>'')'); -- To migrate one selected schema DBMS_DATAPUMP.METADATA_FILTER (hdnl, 'EXCLUDE_PATH_EXPR','IN (''STATISTICS'')'); -- To prevent gathering Statistics during the import DBMS_DATAPUMP.SET_PARALLEL (handle => v_hdnl, degree => 4); -- Number of parallel processes performing export and import DBMS_DATAPUMP.START_JOB(v_hdnl); END; /
Code 2 : migration à chargement complet uniquement, schémas d'applications multiples
DECLARE v_hdnl NUMBER; BEGIN v_hdnl := DBMS_DATAPUMP.OPEN(operation => 'IMPORT', job_mode => 'SCHEMA', remote_link => '<DB LINK Name to Source Database>', job_name => null); DBMS_DATAPUMP.ADD_FILE( handle => v_hdnl, filename => 'import_01.log', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_log_file); DBMS_DATAPUMP.METADATA_FILTER (v_hdnl, 'SCHEMA_LIST', '''<SCHEMA_1>'',''<SCHEMA_2>'', ''<SCHEMA_3>'''); -- To migrate multiple schemas DBMS_DATAPUMP.METADATA_FILTER (v_hdnl, 'EXCLUDE_PATH_EXPR','IN (''STATISTICS'')'); -- To prevent gathering Statistics during the import DBMS_DATAPUMP.SET_PARALLEL (handle => v_hdnl, degree => 4); -- Number of parallel processes performing export and import DBMS_DATAPUMP.START_JOB(v_hdnl); END; /
Code 3 : migration à chargement complet avant une tâche uniquement pour le CDC, schéma d'application unique
DECLARE v_hdnl NUMBER; BEGIN v_hdnl := DBMS_DATAPUMP.OPEN(operation => 'IMPORT', job_mode => 'SCHEMA', remote_link => '<DB LINK Name to Source Database>', job_name => null); DBMS_DATAPUMP.ADD_FILE( handle => v_hdnl, filename => 'import_01.log', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_log_file); DBMS_DATAPUMP.METADATA_FILTER(v_hdnl,'SCHEMA_EXPR','IN (''<schema_name>'')'); -- To migrate one selected schema DBMS_DATAPUMP.METADATA_FILTER (v_hdnl, 'EXCLUDE_PATH_EXPR','IN (''STATISTICS'')'); -- To prevent gathering Statistics during the import DBMS_DATAPUMP.SET_PARAMETER (handle => v_hdnl, name => 'FLASHBACK_SCN', value => <CURRENT_SCN_VALUE_IN_SOURCE_DATABASE>); -- SCN required for AWS DMS CDC only task. DBMS_DATAPUMP.SET_PARALLEL (handle => v_hdnl, degree => 4); -- Number of parallel processes performing export and import DBMS_DATAPUMP.START_JOB(v_hdnl); END; /
Code 4 : Migration à chargement complet avant une tâche uniquement sur le CDC, plusieurs schémas d'application
DECLARE v_hdnl NUMBER; BEGIN v_hdnl := DBMS_DATAPUMP.OPEN (operation => 'IMPORT', job_mode => 'SCHEMA', remote_link => '<DB LINK Name to Source Database>', job_name => null); DBMS_DATAPUMP.ADD_FILE (handle => v_hdnl, filename => 'import_01.log', directory => 'DATA_PUMP_DIR', filetype => dbms_datapump.ku$_file_type_log_file); DBMS_DATAPUMP.METADATA_FILTER (v_hdnl, 'SCHEMA_LIST', '''<SCHEMA_1>'',''<SCHEMA_2>'', ''<SCHEMA_3>'''); -- To migrate multiple schemas DBMS_DATAPUMP.METADATA_FILTER (v_hdnl, 'EXCLUDE_PATH_EXPR','IN (''STATISTICS'')'); -- To prevent gathering Statistics during the import DBMS_DATAPUMP.SET_PARAMETER (handle => v_hdnl, name => 'FLASHBACK_SCN', value => <CURRENT_SCN_VALUE_IN_SOURCE_DATABASE>); -- SCN required for AWS DMS CDC only task. DBMS_DATAPUMP.SET_PARALLEL (handle => v_hdnl, degree => 4); -- Number of parallel processes performing export and import DBMS_DATAPUMP.START_JOB(v_hdnl); END; /
Scénario dans lequel une approche de migration mixte peut mieux fonctionner
Dans de rares cas où la base de données source contient des tables comportant des millions de lignes et des colonnes LOBSEGMENT de très grande taille, ce modèle ralentira la migration. Oracle effectue la migration LOBSEGMENTs sur le lien réseau un par un. Il extrait une seule ligne (ainsi que les données de la colonne LOB) de la table source et insère la ligne dans la table cible, en répétant le processus jusqu'à ce que toutes les lignes soient migrées. Oracle Data Pump via le lien de base de données ne prend pas en charge les mécanismes de chargement groupé ou de chargement par chemin direct pour LOBSEGMENTs.
Dans ce cas, nous recommandons ce qui suit :
Ignorez les tables identifiées lors de la migration d'Oracle Data Pump en ajoutant le filtre de métadonnées suivant :
dbms_datapump.metadata_filter(handle =>h1, name=>'NAME_EXPR', value => 'NOT IN (''TABLE_1'',''TABLE_2'')');Utilisez une AWS DMS tâche (migration à charge complète, avec réplication CDC si nécessaire) pour migrer les tables identifiées. AWS DMS extraira plusieurs lignes de la base de données Oracle source et les insérera par lots dans l'instance Amazon RDS cible, ce qui améliore les performances.
