Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Métriques et validation
Ce guide présente les métriques et les techniques de validation que vous pouvez utiliser pour mesurer les performances des modèles de machine learning. Amazon SageMaker Autopilot produit des métriques qui mesurent la qualité prédictive des modèles d'apprentissage automatique candidats. Les métriques calculées pour les candidats sont spécifiées à l'aide d'un tableau de types MetricDatum.
Métriques Autopilot
Voici la liste des noms des métriques qui sont actuellement disponibles pour mesurer les performances du modèle dans Autopilot.
Note
Autopilot prend en charge les poids des échantillons. Pour en savoir plus sur les poids d'échantillons et les métriques d'objectif disponibles, consultez Métriques pondérées Autopilot.
Les métriques suivantes sont disponibles.
Accuracy-
Rapport entre le nombre d'éléments correctement classés et le nombre total d'éléments classés (correctement ou non). Elle est utilisée pour la classification binaire et multi-classes. La précision mesure à quel point les valeurs de classe prédites sont proches des valeurs réelles. Les valeurs des métriques de précision varient entre zéro (0) et un (1). La valeur 1 indique une précision parfaite et 0 indique une imprécision parfaite.
AUC-
La métrique de zone sous la courbe (AUC, Area Under the Curve) est utilisée pour comparer et évaluer la classification binaire par des algorithmes qui renvoient des probabilités, comme la régression logistique. Pour mapper les probabilités en classifications, les probabilités sont comparées à une valeur de seuil.
La courbe pertinente est la courbe caractéristique de fonctionnement du récepteur. Cette courbe représente le taux de vrais positifs (TPR, True Positive Rate) des prédictions (ou rappels) par rapport au taux de faux positifs (FPR, False Positive Rate) en fonction de la valeur seuil, au-dessus de laquelle une prédiction est considérée positive. L'augmentation du seuil entraîne moins de faux positifs, mais plus de faux négatifs.
L'AUC est la zone située sous cette courbe caractéristique de fonctionnement du récepteur. Ainsi, l'AUC fournit une métrique regroupée des performances du modèle sur tous les seuils de classification possibles. Les scores de l'AUC varient entre 0 et 1. Un score de 1 indique une précision parfaite, et un score de la moitié (0,5) indique que la prédiction n'est pas meilleure qu'un classificateur aléatoire.
BalancedAccuracy-
BalancedAccuracyest une métrique qui mesure la proportion des prédictions exactes dans l'ensemble des prédictions. Ce rapport est calculé après avoir normalisé les vrais positifs (TP) et les vrais négatifs (TN) par le nombre total de valeurs positives (P) et négatives (N). Il est utilisé à la fois dans la classification binaire et multiclasse et est défini comme suit : 0,5* ((TP/P)+(TN/N)), avec des valeurs comprises entre 0 et 1.BalancedAccuracyfournit une meilleure mesure de précision lorsque le nombre de points positifs ou négatifs est très différent les uns des autres dans un ensemble de données déséquilibré, par exemple lorsque seulement 1 % des e-mails sont des spams. F1-
Le score
F1représente la moyenne harmonique de la précision et du rappel, définie comme suit : F1 = 2 * (précision * rappel)/(précision + rappel). Il est utilisé pour la classification binaire en classes traditionnellement appelées positives et négatives. On dit que les prédictions sont vraies lorsqu'elles correspondent à leur classe réelle (correcte) et fausse lorsqu'elles n'y correspondent pas.La précision désigne le rapport entre les prédictions positives réelles et toutes les prédictions positives. Elle inclut aussi les faux positifs d'un jeu de données. La précision mesure la qualité de la prédiction lorsqu'elle prédit la classe positive.
Le rappel (ou sensibilité) désigne le rapport entre les prédictions positives réelles et toutes les instances positives réelles. Le rappel mesure le degré de précision avec lequel un modèle prédit les membres réels de la classe dans un jeu de données.
Les scores de F1 varient entre 0 et 1. Un score de 1 indique la meilleure performance possible et 0 indique la pire.
F1macro-
Le score
F1macroapplique le score F1 aux problèmes de classification multi-classes. Pour ce faire, la précision et le rappel sont calculés, puis leur moyenne harmonique est utilisée pour calculer le score F1 pour chaque classe. Enfin,F1macrocalcule la moyenne des scores individuels pour obtenir le scoreF1macro. Les scoresF1macrovarient entre 0 et 1. Un score de 1 indique la meilleure performance possible et 0 indique la pire. InferenceLatency-
La latence d'inférence est le temps approximatif qui s'écoule entre la formulation d'une demande de prédiction de modèle et sa réception à partir d'un point de terminaison en temps réel sur lequel le modèle est déployé. Cette métrique est mesurée en secondes et n'est disponible qu'en mode Ensembling (Assemblage).
LogLoss-
La perte de journaux, également appelée perte d'entropie croisée, est une métrique utilisée pour évaluer la qualité des sorties de probabilité, plutôt que les sorties elles-mêmes. Elle est utilisée pour la classification binaire et multi-classes, ainsi que dans les réseaux neuronaux. C'est également la fonction de coût pour la régression logistique. La perte logistique est une métrique importante pour indiquer quand un modèle fait des prédictions incorrectes avec des probabilités élevées. Les valeurs vont de 0 à l'infini. Une valeur de 0 représente un modèle qui prédit parfaitement les données.
MAE-
L'erreur absolue moyenne (MAE, Mean Absolute Error) est une mesure de la moyenne des différences entre les valeurs prédites et les valeurs réelles, moyenne calculée sur toutes les valeurs. Elle est couramment utilisée dans l'analyse de régression pour comprendre l'erreur de prédiction du modèle. En cas de régression linéaire, la MAE représente la distance moyenne entre une ligne prédite et la valeur réelle. La MAE est définie comme la somme des erreurs absolues divisée par le nombre d'observations. Les valeurs sont comprises entre 0 et l'infini, les plus petits nombres indiquant une meilleure adéquation du modèle aux données.
MSE-
L'erreur quadratique moyenne (MSE, Mean Squarred Error) est la moyenne des différences au carré entre les valeurs prédites et réelles. Elle est utilisée pour la régression. Les valeurs MSE sont toujours positives. Plus un modèle est capable de prédire les valeurs réelles, plus la valeur MSE est faible.
Precision-
La précision mesure l'efficacité avec laquelle un algorithme prédit les vrais positifs (TP) parmi tous les positifs qu'il identifie. Elle est définie comme suit : précision = TP/(TP+FP), avec des valeurs allant de zéro (0) à un (1), et est utilisée dans la classification binaire. La précision est une métrique importante lorsque le coût d'un faux positif est élevé. Par exemple, le coût d'un faux positif est très élevé si le système de sécurité d'un avion est considéré à tort comme sûr pour le vol. Un faux positif (FP) reflète une prédiction positive qui est en fait négative dans les données.
PrecisionMacro-
La macro précision calcule la précision pour les problèmes de classification multi-classes. Pour ce faire, la précision de chaque classe et la moyenne des scores sont calculées pour obtenir la précision de plusieurs classes. Les scores
PrecisionMacrosont compris entre zéro (0) et un (1). Des scores plus élevés reflètent la capacité du modèle à prédire les vrais positifs (TP) parmi tous les positifs qu'il identifie, en calculant la moyenne sur plusieurs classes. R2-
R2, également connu sous le nom de coefficient de détermination, est utilisé en régression pour quantifier dans quelle mesure un modèle peut expliquer l'écart d'une variable dépendante. Les valeurs sont comprises entre un (1) et moins un (-1). Des nombres plus élevés indiquent une fraction plus importante de la variabilité expliquée. Des valeurs
R2proches de zéro (0) indiquent qu'une faible part de la variable dépendante peut être expliquée par le modèle. Les valeurs négatives indiquent un mauvais ajustement et un dépassement du modèle par une fonction constante. Pour une régression linéaire, il s'agit d'une ligne horizontale. Recall-
Le rappel évalue la capacité d'un algorithme à prédire correctement tous les vrais positifs (TP) dans un jeu de données. Un vrai positif est une prédiction positive qui correspond également à une valeur positive réelle dans les données. Le rappel est défini comme suit : rappel = TP/(TP+FN), avec des valeurs allant de 0 à 1. Des scores plus élevés reflètent une meilleure capacité du modèle à prédire les vrais positifs (TP) dans les données. Ils sont utilisés dans la classification binaire.
Le rappel est important lors du dépistage du cancer, car c'est utilisé pour trouver tous les vrais positifs. Un faux positif (FP) reflète une prédiction positive qui est en fait négative dans les données. Il est souvent insuffisant de mesurer uniquement le rappel, car prédire chaque sortie comme un vrai positif donnera un score de rappel parfait.
RecallMacro-
La métrique
RecallMacrocalcule le rappel pour les problèmes de classification multi-classes en calculant le rappel pour chaque classe et en faisant la moyenne des scores pour obtenir le rappel pour plusieurs classes. Les scoresRecallMacrovont de 0 à 1. Des scores plus élevés reflètent la capacité du modèle à prédire les vrais positifs (TP) dans un jeu de données, tandis qu'un vrai positif reflète une prédiction positive qui est également une valeur positive réelle dans les données. Il est souvent insuffisant de mesurer uniquement le rappel, car prédire chaque sortie comme un vrai positif donnera un score de rappel parfait. RMSE-
La racine de l'erreur quadratique moyenne (RMSE, Root Mean Squared Error) mesure la racine carrée de la différence au carré entre les valeurs prédites et réelles, moyennée sur l'ensemble des valeurs. Elle est utilisée dans l'analyse de régression pour comprendre l'erreur de prédiction du modèle. Cette métrique est importante pour indiquer la présence d'erreurs et de valeurs aberrantes dans les modèles volumineux. Les valeurs vont de zéro (0) à l'infini, les plus petits nombres indiquant une meilleure adéquation du modèle aux données. La RMSE dépend de l'échelle, et ne doit pas être utilisée pour comparer des jeux de données de tailles différentes.
Les métriques calculées automatiquement pour un modèle candidat sont déterminées par le type de problème à résoudre.
Consultez la documentation de référence de SageMaker l'API Amazon pour obtenir la liste des métriques disponibles prises en charge par Autopilot.
Métriques pondérées Autopilot
Note
Autopilot prend en charge les poids des échantillons en mode ensembliste uniquement pour toutes les métriques disponibles, à l'exception de Balanced Accuracy et InferenceLatency. BalanceAccuracy est doté de son propre schéma de pondération pour les jeux de données déséquilibrés qui ne nécessite pas de poids d'échantillons. InferenceLatency ne prend pas en charge les poids des échantillons. Les métriques d'objectif Balanced Accuracy et InferenceLatency ignorent tous les poids d'échantillon existants lors de l'entraînement et de l'évaluation d'un modèle.
Les utilisateurs peuvent ajouter une colonne de poids d'échantillons à leurs données pour s'assurer que chaque observation utilisée pour entraîner un modèle de machine learning reçoit un poids correspondant à son importance perçue pour le modèle. Cela est particulièrement utile dans les scénarios où les observations du jeu de données ont des degrés d'importance différents, ou dans lesquels un jeu de données contient un nombre disproportionné d'échantillons d'une classe par rapport aux autres. L'attribution d'un poids à chaque observation en fonction de son importance ou de son importance accrue pour une classe minoritaire peut améliorer la performance globale d'un modèle ou garantir qu'un modèle n'est pas biaisé du côté de la classe majoritaire.
Pour plus d'informations sur la façon de transmettre des poids d'échantillon lors de la création d'une expérience dans l'interface utilisateur de Studio Classic, reportez-vous à l'étape 7 de la section Création d'une expérience de pilote automatique à l'aide de Studio Classic.
Pour en savoir plus sur la façon de transmettre des poids d'échantillons par programmation lors de la création d'une expérience Autopilot à l'aide de l'API, consultez Comment ajouter des poids d'échantillons à une tâche AutoML dans Création d'une expérience Autopilot par programmation.
Validation croisée dans Autopilot
La validation croisée permet de réduire le surajustement et le biais dans la sélection des modèles. Elle est également utilisée pour évaluer dans quelle mesure un modèle peut prédire les valeurs d'un jeu de données de validation invisible, si ce dernier est extrait de la même population. Cette méthode est particulièrement importante lors de l'entraînement sur des jeux de données ayant un nombre limité d'instances d'entraînement.
Le Autopilot utilise la validation croisée pour créer des modèles en mode d'optimisation des hyperparamètres (HPO) et d'entraînement d'ensemble. La première étape du processus de validation croisée d'Autopilot consiste à diviser les données en k-folds.
Division en k-folds
La division en k-folds est une méthode qui permet de séparer un jeu de données d'entraînement d'entrée en plusieurs jeux de données d'entraînement et de validation. Le jeu de données est divisé en sous-échantillons k de taille égale nommés folds. Les modèles sont ensuite entraînés sur k-1 folds et testés par rapport au ke fold restant, qui sert de jeu de données de validation. Le processus est répété k fois en utilisant un jeu de données différent pour la validation.
L'image suivante montre une division en k-folds avec k = 4 folds. Chaque fold est représenté par une ligne. Les cases foncées représentent les parties des données utilisées lors de l'entraînement. Les cases claires restantes indiquent les jeux de données de validation.

Autopilot utilise la validation croisée k-fold pour le mode d'optimisation des hyperparamètres (HPO) et le mode assemblage.
Vous pouvez déployer des modèles de pilote automatique conçus à l'aide de la validation croisée, comme vous le feriez avec n'importe quel autre modèle de pilote automatique ou d'IA. SageMaker
Mode HPO
La validation croisée k-fold utilise la méthode de divison k-fold pour la validation croisée. En mode HPO, Autopilot met automatiquement en œuvre une validation croisée k-fold pour les petits jeux de données, comportant 50 000 instances d'entraînement ou moins. La validation croisée est particulièrement importante lors de l'entraînement sur de petits jeux de données, car elle protège contre le surajustement et les biais de sélection.
Le mode HPO utilise une valeur k de 5 sur les algorithmes candidats utilisés pour modéliser le jeu de données. Plusieurs modèles sont entraînés sur différentes divisions et les modèles sont stockés séparément. Lorsque l'entraînement est terminé, la moyenne des métriques de validation de chacun des modèles est calculée pour produire une seule métrique d'estimation. Enfin, Autopilot combine les modèles de l'essai ayant la meilleure métrique de validation pour former un modèle d'ensemble. Autopilot utilise ce modèle d'ensemble pour faire des prédictions.
La métrique de validation des modèles entraînés par Autopilot est présentée comme la métrique objective dans le leaderboard du modèle. Sauf indication contraire, Autopilot utilise la métrique de validation par défaut pour chaque type de problème qu'il gère. Pour obtenir la liste de toutes les métriques utilisées par Autopilot, consultez Métriques Autopilot.
Par exemple, le jeu de données Boston Housing
La validation croisée peut augmenter les temps de formation de 20 % en moyenne. Les temps de formation peuvent également augmenter de manière significative pour les jeux de données complexes.
Note
En mode HPO, vous pouvez consulter les indicateurs de formation et de validation de chaque volet dans vos /aws/sagemaker/TrainingJobs CloudWatch journaux. Pour plus d'informations sur CloudWatch les journaux, consultezCloudWatch Journaux pour Amazon SageMaker AI.
Mode d'assemblage
Note
Autopilot prend en charge les poids d'échantillons en mode ensembliste. Pour obtenir la liste des métriques disponibles prenant en charge les poids d'échantillons, consultez Métriques Autopilot.
En mode ensembliste, la validation croisée est effectuée quelle que soit la taille du jeu de données. Les clients peuvent soit fournir leur propre jeu de données de validation et un ratio de répartition des données personnalisé, soit laisser Autopilot diviser automatiquement le jeu de données en un ratio de répartition 80-20 %. Les données d'entraînement sont ensuite divisées en plusieurs k fois pour une validation croisée, la valeur de k étant déterminée par le AutoGluon moteur. Un ensemble se compose de plusieurs modèles de machine learning, chaque modèle étant nommé modèle de base. Un modèle de base unique est entraîné sur (k-1) plis et fait des out-of-fold prédictions sur le pli restant. Ce processus est répété pour tous les k plis, et les prédictions out-of-fold (OOF) sont concaténées pour former un seul ensemble de prédictions. Tous les modèles de base de l'ensemble suivent le même processus de génération de prédictions OOF.
L'image suivante montre une validation en k-fold avec k = 4 folds. Chaque fold est représenté par une ligne. Les cases foncées représentent les parties des données utilisées lors de l'entraînement. Les cases claires restantes indiquent les jeux de données de validation.
Dans la partie supérieure de l'image, à chaque fold, le premier modèle de base fait des prédictions sur le jeu de données de validation après un entraînement sur les jeux de données d'entraînement. À chaque fold suivant, les jeux de données changent de rôle. Un jeu de données qui était auparavant utilisé pour la formation est désormais utilisé pour la validation, et vice versa. À la fin des k plis, toutes les prédictions sont concaténées pour former un seul ensemble de prédictions appelé prédiction out-of-fold (OOF). Ce processus est répété pour chaque modèle de base n.
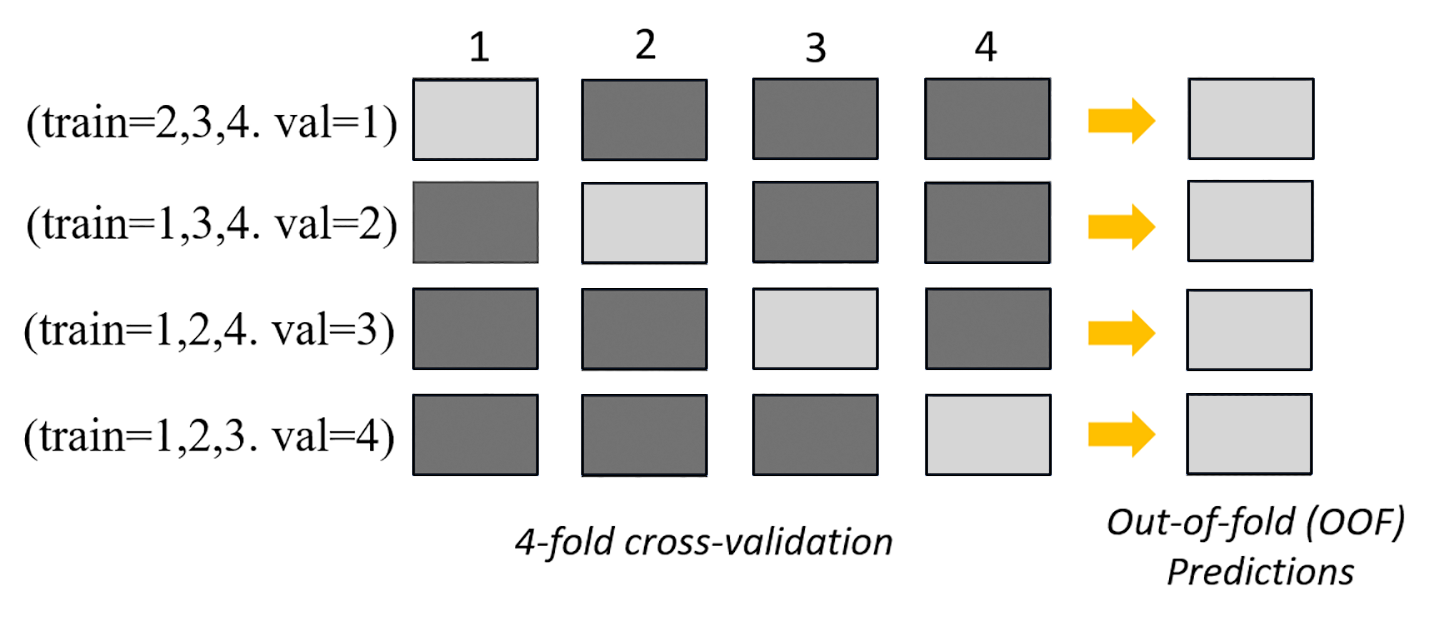
Les prédictions OOF pour chaque modèle de base sont ensuite utilisées comme caractéristiques pour entraîner un modèle d'empilement. Le modèle d'empilement apprend les pondérations d'importance pour chaque modèle de base. Ces pondérations sont utilisées pour combiner les prédictions OOF afin de former la prédiction finale. Les performances du jeu de données de validation déterminent quel modèle de base ou d'empilement est le meilleur, et ce modèle est renvoyé en tant que modèle final.
En mode ensemble, vous pouvez soit fournir votre propre jeu de données de validation, soit laisser Autopilot diviser automatiquement l'ensemble de données d'entrée en ensembles de données de formation à 80 % et de validation à 20 %. Les données d'apprentissage sont ensuite divisées en k folds à des fins de validation croisée et produisent une prédiction OOF et un modèle de base pour chaque fold.
Ces prédictions OOF sont utilisées comme fonctionnalités pour entraîner un modèle d'empilement, qui apprend simultanément les pondérations de chaque modèle de base. Ces pondérations sont utilisées pour combiner les prédictions OOF afin de former la prédiction finale. Les jeux de données de validation pour chaque fold sont utilisés pour le réglage des hyperparamètres de tous les modèles de base et du modèle d'empilement. Les performances du jeu de données de validation déterminent quel modèle de base ou d'empilement est le meilleur, et ce modèle est renvoyé en tant que modèle final.
