Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Gestion d'accès IAM
Les sections suivantes décrivent les exigences AWS Identity and Access Management (IAM) pour Amazon SageMaker Pipelines. Pour obtenir un exemple de la façon dont vous pouvez implémenter ces autorisations, veuillez consulter Prérequis.
Rubriques
Autorisations de rôle de pipeline
Votre pipeline nécessite un rôle d'exécution de pipeline IAM qui est transmis à Pipelines lorsque vous créez un pipeline. Le rôle de l'instance d' SageMaker IA qui crée le pipeline doit être iam:PassRole autorisé à exécuter le pipeline pour pouvoir le transmettre. Pour plus d'informations sur les rôles IAM, consultez la section Rôles IAM.
Votre rôle d'exécution de pipeline nécessite les autorisations suivantes :
-
Pour transférer un rôle à une tâche d' SageMaker IA au sein d'un pipeline,
iam:PassRoleautorisation pour le rôle transféré. -
Les autorisations
CreateetDescribepour chacun des types de tâches dans le pipeline. -
Autorisations Amazon S3 pour l'utilisation de la fonction
JsonGet. Vous contrôlez l'accès à vos ressources Amazon S3 à l'aide de politiques basées sur les ressources et de politiques basées sur l'identité. Une politique basée sur les ressources est appliquée à votre compartiment Amazon S3 et accorde à Pipelines l'accès au compartiment. Une politique basée sur l'identité permet à votre pipeline de passer des appels Amazon S3 à partir de votre compte. Pour plus d'informations sur les politiques basées sur l'identité et les politiques basées sur les ressources, veuillez consulter Politiques basées sur l'identité et politiques basées sur une ressource.{ "Action": [ "s3:GetObject" ], "Resource": "arn:aws:s3:::<your-bucket-name>/*", "Effect": "Allow" }
Autorisations d'étape de pipeline
Les pipelines incluent des étapes qui exécutent des tâches d' SageMaker IA. Pour que les étapes de pipeline puissent exécuter ces tâches, elles nécessitent un rôle IAM dans votre compte qui fournit l'accès à la ressource nécessaire. Ce rôle est transmis au responsable du service SageMaker AI par votre pipeline. Pour plus d'informations sur les rôles IAM, veuillez consulter Rôles IAM.
Par défaut, chaque étape assume le rôle d'exécution du pipeline. Vous pouvez éventuellement transmettre un rôle différent à l'une des étapes de votre pipeline. Cela garantit que le code de chaque étape n'a pas la capacité d'affecter les ressources utilisées dans d'autres étapes, sauf s'il existe une relation directe entre les deux étapes spécifiées dans la définition du pipeline. Vous passez ces rôles lors de la définition du processeur ou de l'estimateur de votre étape. Pour des exemples expliquant comment inclure ces rôles dans ces définitions, consultez la documentation du SDK SageMaker AI Python
Configuration CORS avec des compartiments Amazon S3
Pour garantir que vos images sont importées dans vos pipelines à partir d'un compartiment Amazon S3 de manière prévisible, une configuration CORS doit être ajoutée aux compartiments Amazon S3 d'où les images sont importées. Cette section fournit des instructions sur la façon de définir la configuration CORS requise pour votre compartiment Amazon S3. Le code XML CORSConfiguration requis pour les pipelines est différent de celui contenu dansExigence CORS pour les données d'image d'entrée, sinon vous pouvez utiliser les informations qui s'y trouvent pour en savoir plus sur l'exigence CORS relative aux compartiments Amazon S3.
Utilisez le code de configuration CORS suivant pour les compartiments Amazon S3 qui hébergent vos images. Pour obtenir des instructions sur la configuration de CORS, consultez la section Configuration du partage de ressources entre origines (CORS) dans le guide de l'utilisateur d'Amazon Simple Storage Service. Si vous utilisez la console Amazon S3 pour ajouter la stratégie à votre compartiment, vous devez utiliser le format JSON.
JSON
[ { "AllowedHeaders": [ "*" ], "AllowedMethods": [ "PUT" ], "AllowedOrigins": [ "*" ], "ExposeHeaders": [ "Access-Control-Allow-Origin" ] } ]
XML
<CORSConfiguration> <CORSRule> <AllowedHeader>*</AllowedHeader> <AllowedOrigin>*</AllowedOrigin> <AllowedMethod>PUT</AllowedMethod> <ExposeHeader>Access-Control-Allow-Origin</ExposeHeader> </CORSRule> </CORSConfiguration>
Le fichier GIF suivant présente les instructions contenues dans la documentation Amazon S3 pour ajouter une stratégie d'en-tête CORS à l'aide de la console Amazon S3.
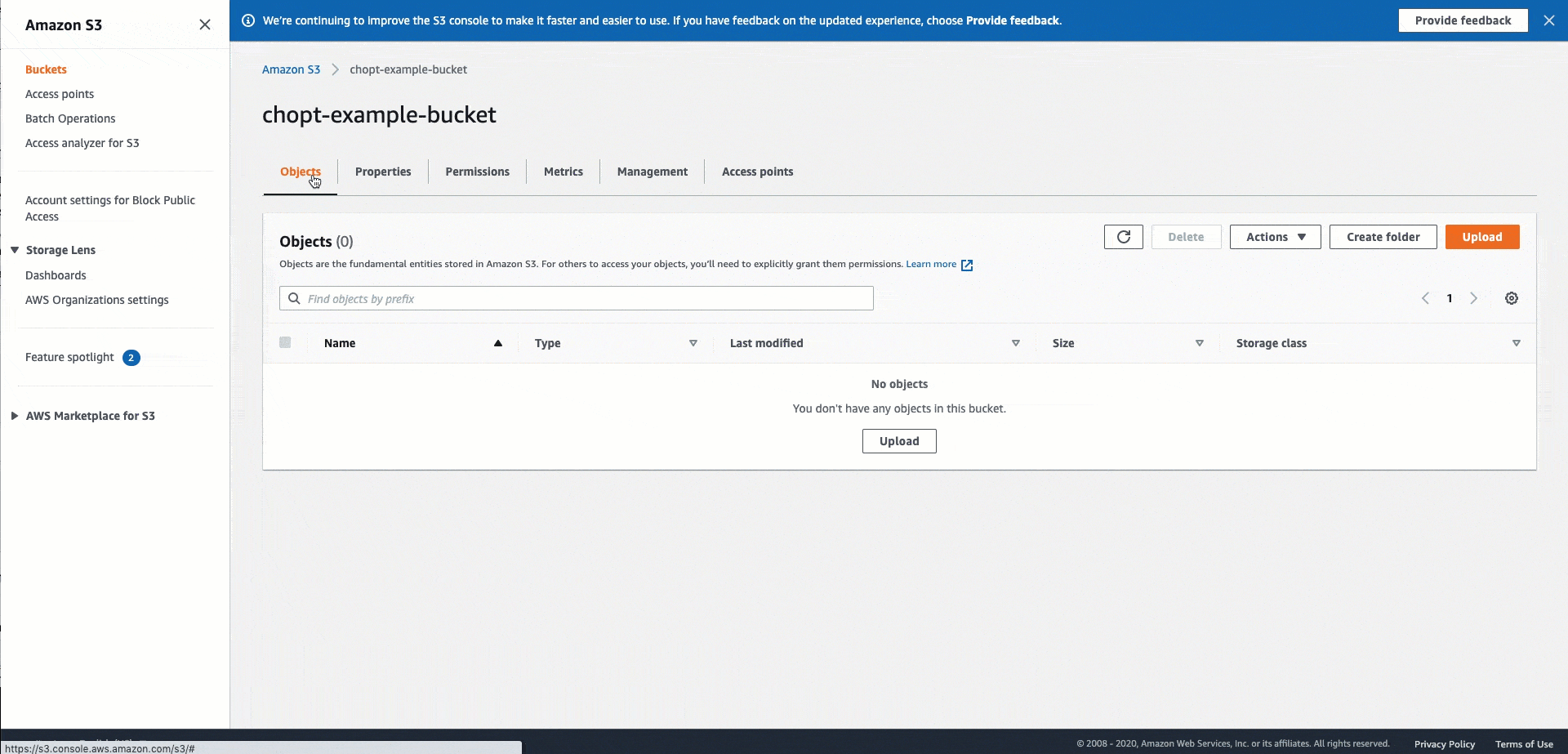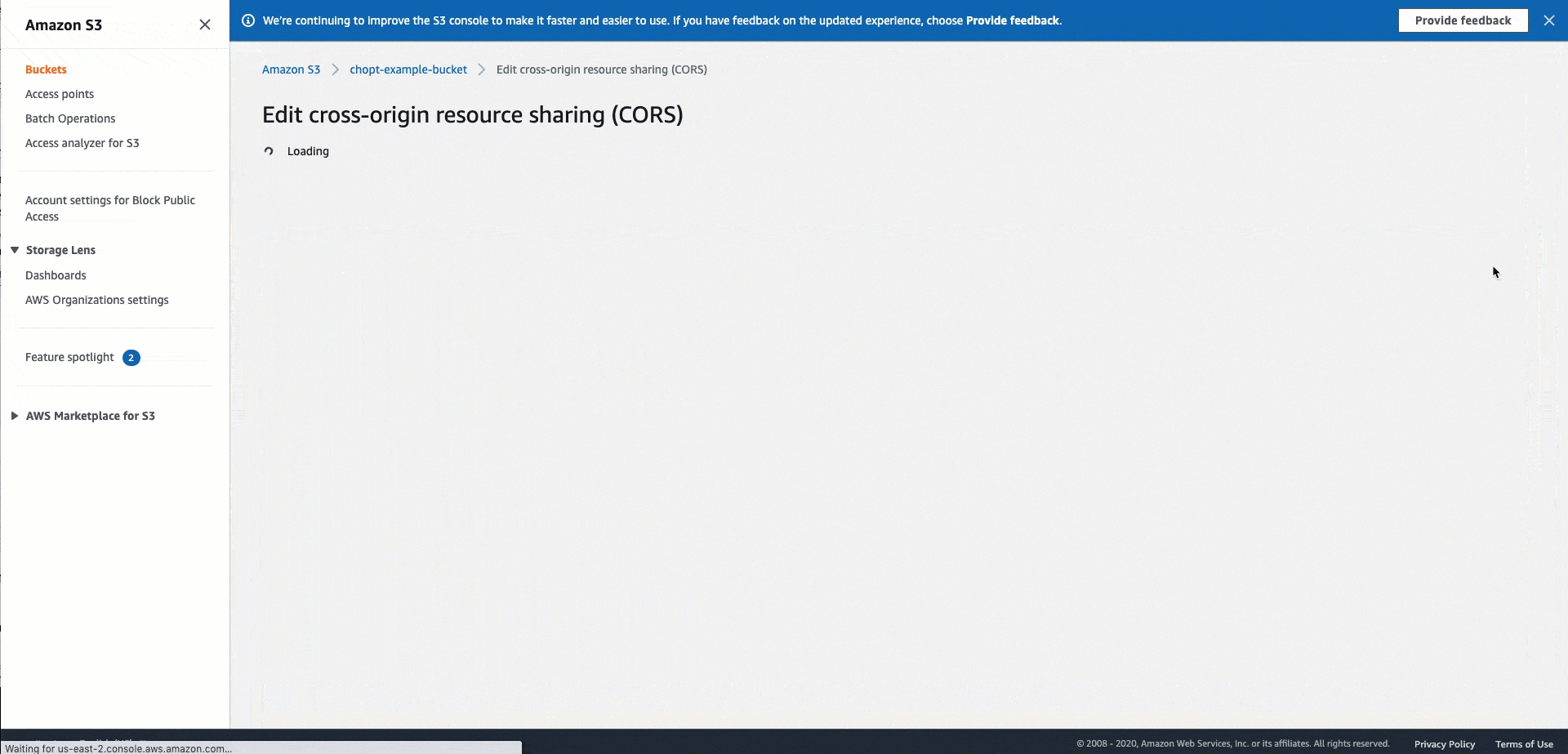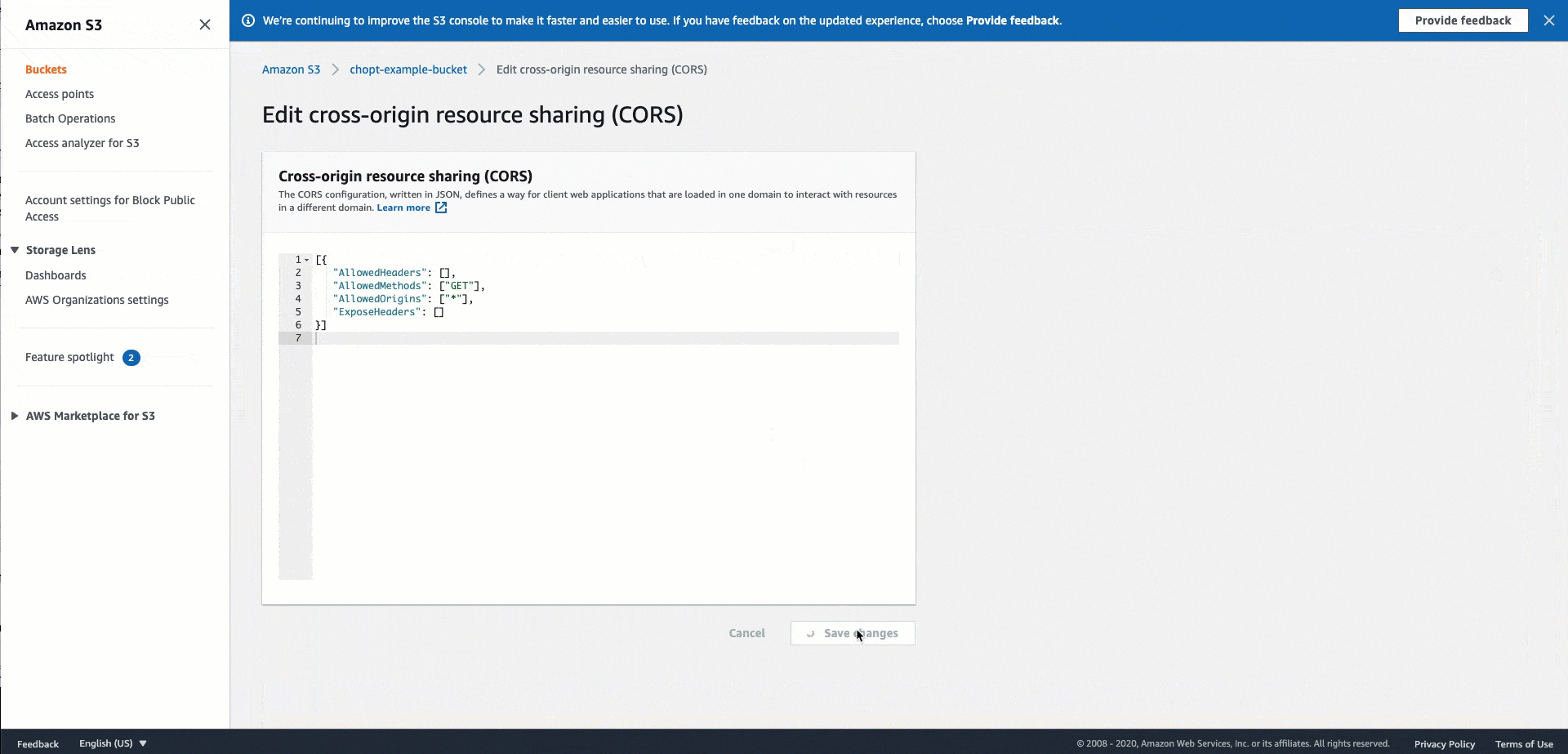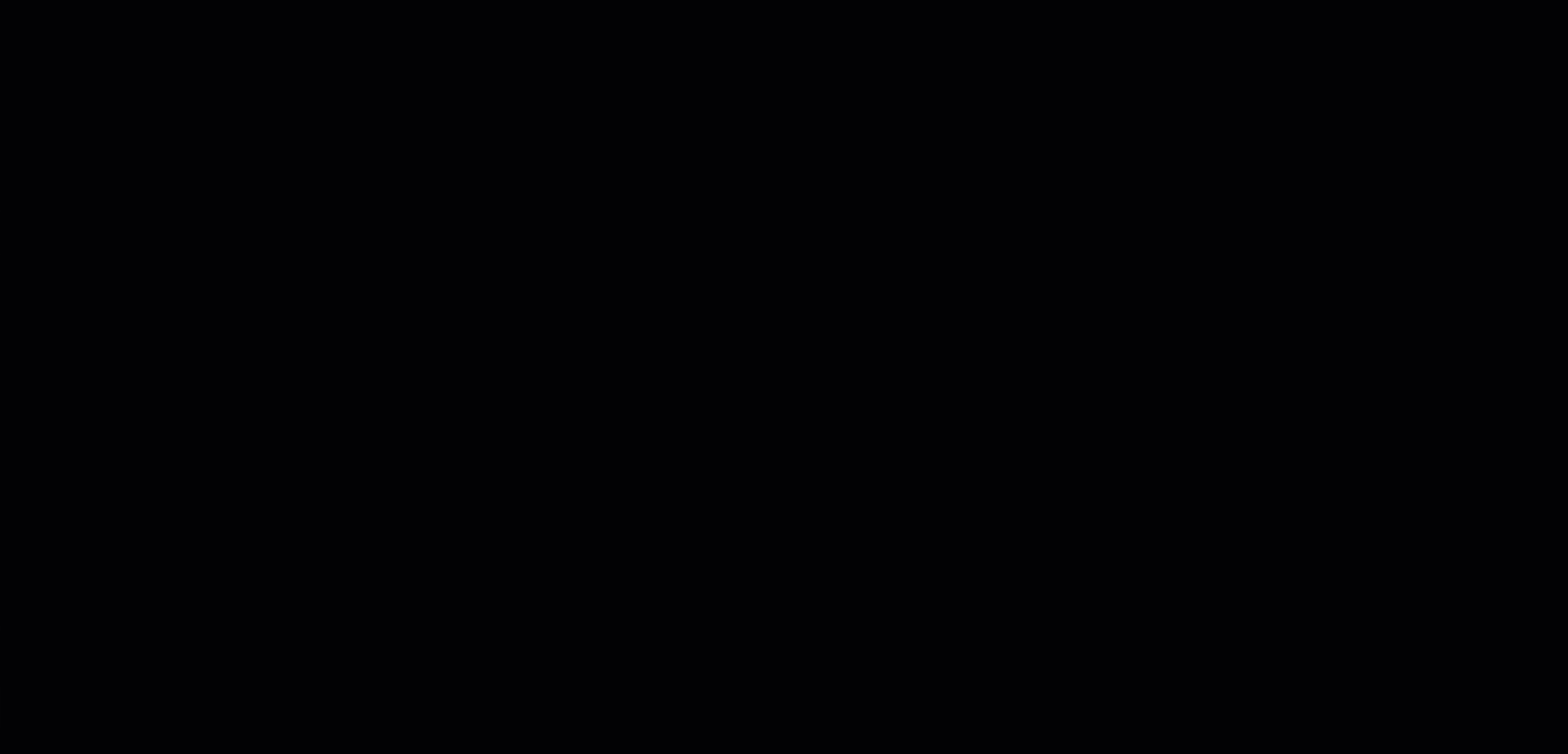
Personnalisez la gestion des accès pour les tâches liées aux pipelines
Vous pouvez personnaliser davantage vos politiques IAM afin que les membres sélectionnés de votre organisation puissent exécuter une ou toutes les étapes de pipeline. Par exemple, vous pouvez autoriser certains utilisateurs à créer des tâches d'entraînement, autoriser un autre groupe d'utilisateurs à créer des tâches de traitement et autoriser tous vos utilisateurs à exécuter les étapes restantes. Pour utiliser cette fonctionnalité, vous devez sélectionner une chaîne personnalisée qui préfixe votre nom de tâche. Votre administrateur ajoute le préfixe autorisé ARNs au préfixe tandis que votre data scientist inclut ce préfixe dans les instanciations de pipeline. Étant donné que la politique IAM pour les utilisateurs autorisés contient un ARN de tâche avec le préfixe spécifié, les tâches suivantes de votre étape de pipeline disposent des autorisations nécessaires pour continuer. Le préfixage des tâches est désactivé par défaut. Vous devez activer cette option dans votre classe Pipeline pour pouvoir l'utiliser.
Pour les tâches dont le préfixage est désactivé, le nom de tâche est formaté comme indiqué et est une concaténation des champs décrits dans le tableau suivant :
pipelines-<executionId>-<stepNamePrefix>-<entityToken>-<failureCount>
| Champ | Définition |
|---|---|
|
pipelines |
Chaîne statique toujours ajoutée au début. Cette chaîne identifie le service d'orchestration de pipeline comme source de la tâche. |
|
executionId |
Mémoire tampon aléatoire pour l'instance d'exécution du pipeline. |
|
stepNamePrefix |
Nom d'étape spécifié par l'utilisateur (indiqué dans l'argument |
|
entityToken |
Jeton aléatoire pour garantir l'idempotence de l'entité d'étape. |
|
failureCount |
Nombre actuel de nouvelles tentatives pour terminer la tâche. |
Dans ce cas, aucun préfixe personnalisé n'est ajouté au nom de la tâche et la politique IAM correspondante doit correspondre à cette chaîne.
Pour les utilisateurs qui activent le préfixage de tâche, le nom de tâche sous-jacent prend la forme suivante, le préfixe personnalisé étant spécifié en tant que MyBaseJobName :
<MyBaseJobName>-<executionId>-<entityToken>-<failureCount>
Le préfixe personnalisé remplace la pipelines chaîne statique pour vous aider à affiner la sélection d'utilisateurs autorisés à exécuter le job SageMaker AI dans le cadre d'un pipeline.
Restrictions concernant la longueur des préfixes
Les noms des tâches sont soumis à des contraintes de longueur internes spécifiques aux étapes de pipeline individuelles. Cette contrainte limite également la longueur du préfixe autorisé. Les exigences relatives à la longueur du préfixe sont les suivantes :
| Étape de pipeline | Longueur du préfixe |
|---|---|
|
|
38 |
|
6 |
Application de préfixes de tâche à une politique IAM
Votre administrateur crée des politiques IAM permettant aux utilisateurs de préfixes spécifiques de créer des tâches. L'exemple de politique suivant permet aux scientifiques des données de créer des tâches d'entraînement s'ils utilisent le préfixe MyBaseJobName.
{ "Action": "sagemaker:CreateTrainingJob", "Effect": "Allow", "Resource": [ "arn:aws:sagemaker:region:account-id:*/MyBaseJobName-*" ] }
Application de préfixes de tâche aux instanciations de pipeline
Vous spécifiez votre préfixe avec l'argument *base_job_name de la classe d'instances de tâche.
Note
Vous transmettez votre préfixe de tâche avec l'argument *base_job_name à l'instance de tâche avant de créer une étape de pipeline. Cette instance de tâche contient les informations nécessaires pour que la tâche s'exécute en tant qu'étape d'un pipeline. Cet argument varie en fonction de l'instance de tâche utilisée. La liste suivante indique l'argument à utiliser pour chaque type d'étape de pipeline :
-
base_job_namepour les classesEstimator(TrainingStep),Processor(ProcessingStep) etAutoML(AutoMLStep) -
tuning_base_job_namepour la classeTuner(TuningStep) -
transform_base_job_namepour la classeTransformer(TransformStep) -
base_job_nameouCheckJobConfigpour les classesQualityCheckStep(Vérification de la qualité) etClarifyCheckstep(Vérification Clarify) -
Pour la classe
Model, l'argument utilisé diffère si vous exécutezcreateouregistersur votre modèle avant de transmettre le résultat àModelStep.-
Si vous appelez
create, le préfixe personnalisé provient de l'argumentnamelorsque vous construisez votre modèle (c'est-à-dire,Model(name=)) -
Si vous appelez
register, le préfixe personnalisé provient de l'argumentmodel_package_namede votre appel àregister(c'est-à-dire,my_model.register(model_package_name=)
-
L'exemple suivant montre comment spécifier un préfixe pour une nouvelle instance de tâche d'entraînement.
# Create a job instance xgb_train = Estimator( image_uri=image_uri, instance_type="ml.m5.xlarge", instance_count=1, output_path=model_path, role=role, subnets=["subnet-0ab12c34567de89f0"], base_job_name="MyBaseJobName" security_group_ids=["sg-1a2bbcc3bd4444e55"], tags = [ ... ] encrypt_inter_container_traffic=True, ) # Attach your job instance to a pipeline step step_train = TrainingStep( name="TestTrainingJob", estimator=xgb_train, inputs={ "train": TrainingInput(...), "validation": TrainingInput(...) } )
Le préfixage de tâche est désactivé par défaut. Pour activer cette fonctionnalité, utilisez l'option use_custom_job_prefix de PipelineDefinitionConfig comme indiqué dans l'extrait suivant :
from sagemaker.workflow.pipeline_definition_config import PipelineDefinitionConfig # Create a definition configuration and toggle on custom prefixing definition_config = PipelineDefinitionConfig(use_custom_job_prefix=True); # Create a pipeline with a custom prefix pipeline = Pipeline( name="MyJobPrefixedPipeline", parameters=[...] steps=[...] pipeline_definition_config=definition_config )
Créez et exécutez votre pipeline. L'exemple suivant crée et exécute un pipeline, et il montre également comment désactiver le préfixage des tâches et réexécuter votre pipeline.
pipeline.create(role_arn=sagemaker.get_execution_role()) # Optionally, call definition() to confirm your prefixed job names are in the built JSON pipeline.definition() pipeline.start() # To run a pipeline without custom-prefixes, toggle off use_custom_job_prefix, update the pipeline # via upsert() or update(), and start a new run definition_config = PipelineDefinitionConfig(use_custom_job_prefix=False) pipeline.pipeline_definition_config = definition_config pipeline.update() execution = pipeline.start()
De même, vous pouvez activer cette fonctionnalité pour les pipelines existants et démarrer une nouvelle exécution utilisant des préfixes de tâche.
definition_config = PipelineDefinitionConfig(use_custom_job_prefix=True) pipeline.pipeline_definition_config = definition_config pipeline.update() execution = pipeline.start()
Enfin, vous pouvez consulter votre tâche préfixée de façon personnalisée en appelant list_steps sur l'exécution du pipeline.
steps = execution.list_steps() prefixed_training_job_name = steps['PipelineExecutionSteps'][0]['Metadata']['TrainingJob']['Arn']
Personnaliser l'accès aux versions du pipeline
Vous pouvez accorder un accès personnalisé à des versions spécifiques d'Amazon SageMaker Pipelines à l'aide de la clé de sagemaker:PipelineVersionId condition. Par exemple, la politique ci-dessous autorise l'accès pour démarrer des exécutions ou mettre à jour la version du pipeline uniquement pour les versions ID 6 et supérieures.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowStartPipelineExecution", "Effect": "Allow", "Action": [ "sagemaker:StartPipelineExecution", "sagemaker:UpdatePipelineVersion" ], "Resource": "*", "Condition": { "NumericGreaterThanEquals": { "sagemaker:PipelineVersionId": 6 } } } }
Pour plus d'informations sur les clés de condition prises en charge, consultez Clés de condition pour Amazon SageMaker AI.
Politiques de contrôle des services avec les pipelines
Les politiques de contrôle des services (SCPs) sont un type de politique d'organisation que vous pouvez utiliser pour gérer les autorisations au sein de votre organisation. SCPs offrent un contrôle centralisé des autorisations maximales disponibles pour tous les comptes de votre organisation. En utilisant des pipelines au sein de votre organisation, vous pouvez vous assurer que les data scientists gèrent les exécutions de vos pipelines sans avoir à interagir avec la AWS console.
Si vous utilisez un VPC avec votre SCP qui restreint l'accès à Amazon S3, vous devez prendre des mesures pour autoriser votre pipeline à accéder à d'autres ressources Amazon S3.
Pour autoriser les pipelines à accéder à Amazon S3 en dehors de votre VPC avec cette JsonGet fonction, mettez à jour le SCP de votre organisation afin de vous assurer que le rôle utilisant des pipelines peut accéder à Amazon S3. Pour ce faire, créez une exception pour les rôles utilisés par l'exécuteur de pipelines via le rôle d'exécution de pipeline à l'aide d'une balise principale et d'une clé de condition.
Pour autoriser les pipelines à accéder à Amazon S3 en dehors de votre VPC
-
Créez une balise unique pour votre rôle d'exécution de pipeline en suivant les étapes décrites dans Balisage des utilisateurs et des rôles IAM.
-
Accordez une exception dans votre SCP à l'aide de la clé de condition
Aws:PrincipalTag IAMpour la balise que vous avez créée. Pour de plus amples informations, veuillez consulter Création, mise à jour et suppression de politiques de contrôle des services.
