Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Formation d'un modèle
Au cours de cette étape, vous devez choisir un algorithme d'apprentissage et exécuter une tâche d'entraînement pour le modèle. Le SDK Amazon SageMaker Python
Choisir l'algorithme d'entraînement
Pour choisir le bon algorithme pour votre jeu de données, vous devez généralement évaluer différents modèles afin de trouver les modèles les plus adaptés à vos données. Pour des raisons de simplicité, l'algorithme XGBoost algorithme avec Amazon SageMaker AI intégré à l' SageMaker IA est utilisé tout au long de ce didacticiel sans qu'il soit nécessaire de pré-évaluer les modèles.
Astuce
Si vous souhaitez que l' SageMaker IA trouve un modèle adapté à votre jeu de données tabulaire, utilisez Amazon SageMaker Autopilot qui automatise une solution d'apprentissage automatique. Pour de plus amples informations, veuillez consulter SageMaker Pilote automatique.
Créer et exécuter une tâche d'entraînement
Après avoir déterminé le modèle à utiliser, commencez à créer un estimateur d' SageMaker IA pour la formation. Ce didacticiel utilise l'algorithme XGBoost intégré pour l'estimateur générique SageMaker AI.
Pour exécuter une tâche d'entraînement du modèle
-
Importez le SDK Amazon SageMaker Python
et commencez par récupérer les informations de base de votre session d' SageMaker IA en cours. import sagemaker region = sagemaker.Session().boto_region_name print("AWS Region: {}".format(region)) role = sagemaker.get_execution_role() print("RoleArn: {}".format(role))Cela renvoie les informations suivantes :
-
region— La AWS région actuelle dans laquelle l'instance de bloc-notes SageMaker AI est exécutée. -
role– Le rôle IAM utilisé par l'instance de bloc-notes.
Note
Vérifiez la version du SDK SageMaker Python en exécutant
sagemaker.__version__. Ce tutoriel est basé sursagemaker>=2.20. Si le kit SDK est obsolète, installez la dernière version en exécutant la commande suivante :! pip install -qU sagemakerSi vous exécutez cette installation dans vos instances SageMaker Studio ou Notebook existantes, vous devez actualiser manuellement le noyau pour terminer l'application de la mise à jour de version.
-
-
Créez un XGBoost estimateur à l'aide de la
sagemaker.estimator.Estimatorclasse. Dans l'exemple de code suivant, l' XGBoost estimateur est nommé.xgb_modelfrom sagemaker.debugger import Rule, ProfilerRule, rule_configs from sagemaker.session import TrainingInput s3_output_location='s3://{}/{}/{}'.format(bucket, prefix, 'xgboost_model') container=sagemaker.image_uris.retrieve("xgboost", region, "1.2-1") print(container) xgb_model=sagemaker.estimator.Estimator( image_uri=container, role=role, instance_count=1, instance_type='ml.m4.xlarge', volume_size=5, output_path=s3_output_location, sagemaker_session=sagemaker.Session(), rules=[ Rule.sagemaker(rule_configs.create_xgboost_report()), ProfilerRule.sagemaker(rule_configs.ProfilerReport()) ] )Pour construire l'estimateur SageMaker AI, spécifiez les paramètres suivants :
-
image_uri– Spécifiez l'URI de l'image du conteneur d'entraînement. Dans cet exemple, l'URI du conteneur XGBoost d'entraînement SageMaker AI est spécifiée à l'aide desagemaker.image_uris.retrieve. -
role— Le rôle AWS Identity and Access Management (IAM) que l' SageMaker IA utilise pour effectuer des tâches en votre nom (par exemple, lire les résultats de formation, appeler les artefacts du modèle depuis Amazon S3 et écrire les résultats de formation sur Amazon S3). -
instance_countetinstance_type— Le type et le nombre d'instances de calcul Amazon EC2 ML à utiliser pour l'entraînement des modèles. Pour cet exercice de formation, vous utilisez uneml.m4.xlargeinstance unique dotée de 4 ou 16 Go de mémoire CPUs, d'un espace de stockage Amazon Elastic Block Store (Amazon EBS) et d'une performance réseau élevée. Pour plus d'informations sur les types d'instances de EC2 calcul, consultez Amazon EC2 Instance Types. Pour plus d'informations sur la facturation, consultez les SageMaker tarifs Amazon . -
volume_size– Taille, en Go, du volume de stockage EBS à attacher à l'instance d'entraînement. Elle doit être suffisamment importante pour stocker des données d'entraînement si vous utilisez le modeFile(le modeFileest activé par défaut). Si vous ne spécifiez pas ce paramètre, il est défini par défaut sur 30. -
output_path— Le chemin d'accès au compartiment S3 dans lequel l' SageMaker IA stocke l'artefact du modèle et les résultats d'entraînement. -
sagemaker_session— L'objet de session qui gère les interactions avec les opérations d' SageMaker API et les autres AWS services utilisés par la tâche de formation. -
rules— Spécifiez une liste de règles intégrées au SageMaker Debugger. Dans cet exemple, lacreate_xgboost_report()règle crée un XGBoost rapport qui fournit des informations sur la progression et les résultats de l'entraînement, et laProfilerReport()règle crée un rapport concernant l'utilisation des ressources EC2 informatiques. Pour de plus amples informations, veuillez consulter SageMaker Rapport interactif du débogueur pour XGBoost.
Astuce
Si vous souhaitez exécuter un entraînement distribué sur des modèles d'apprentissage profond de grande taille, tels que les réseaux neuronaux convolutifs (CNN) et les modèles de traitement du langage naturel (NLP), utilisez SageMaker AI Distributed pour le parallélisme des données ou le parallélisme des modèles. Pour de plus amples informations, veuillez consulter Formation distribuée sur Amazon SageMaker AI.
-
-
Définissez les hyperparamètres de l' XGBoost algorithme en appelant la
set_hyperparametersméthode de l'estimateur. Pour une liste complète des XGBoost hyperparamètres, voirXGBoost hyperparamètres.xgb_model.set_hyperparameters( max_depth = 5, eta = 0.2, gamma = 4, min_child_weight = 6, subsample = 0.7, objective = "binary:logistic", num_round = 1000 )Astuce
Vous pouvez également régler les hyperparamètres à l'aide de la fonction d'optimisation des hyperparamètres de l' SageMaker IA. Pour de plus amples informations, veuillez consulter Réglage automatique du modèle grâce à l' SageMaker IA.
-
Utilisation de la classe
TrainingInputpour configurer un flux d'entrée de données pour l'entraînement. L'exemple de code suivant montre comment configurer des objetsTrainingInputpour utiliser les jeux de données d'entraînement et de validation que vous avez chargés sur Amazon S3 dans la section Diviser le jeu de données en jeux de données d'entraînement, de validation et de test.from sagemaker.session import TrainingInput train_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/train.csv"), content_type="csv" ) validation_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/validation.csv"), content_type="csv" ) -
Pour démarrer l'entraînement du modèle, appelez la méthode
fitde l'estimateur avec les jeux de données d'entraînement et de validation. En définissantwait=True, la méthodefitaffiche les journaux de progression et attend que l'entraînement se termine.xgb_model.fit({"train": train_input, "validation": validation_input}, wait=True)Pour de plus amples informations sur l'entraînement de modèle, veuillez consulter Entraînez un modèle avec Amazon SageMaker. Cette tâche d'entraînement de tutoriel peut prendre jusqu'à 10 minutes.
Une fois la formation terminée, vous pouvez télécharger un rapport de XGBoost formation et un rapport de profilage générés par SageMaker Debugger. Le rapport d' XGBoost entraînement vous donne un aperçu de la progression et des résultats de l'entraînement, tels que la fonction de perte par rapport à l'itération, l'importance des fonctionnalités, la matrice de confusion, les courbes de précision et les autres résultats statistiques de l'entraînement. Par exemple, vous pouvez trouver la courbe de perte suivante dans le rapport d' XGBoost entraînement, qui indique clairement qu'il existe un problème de surajustement.
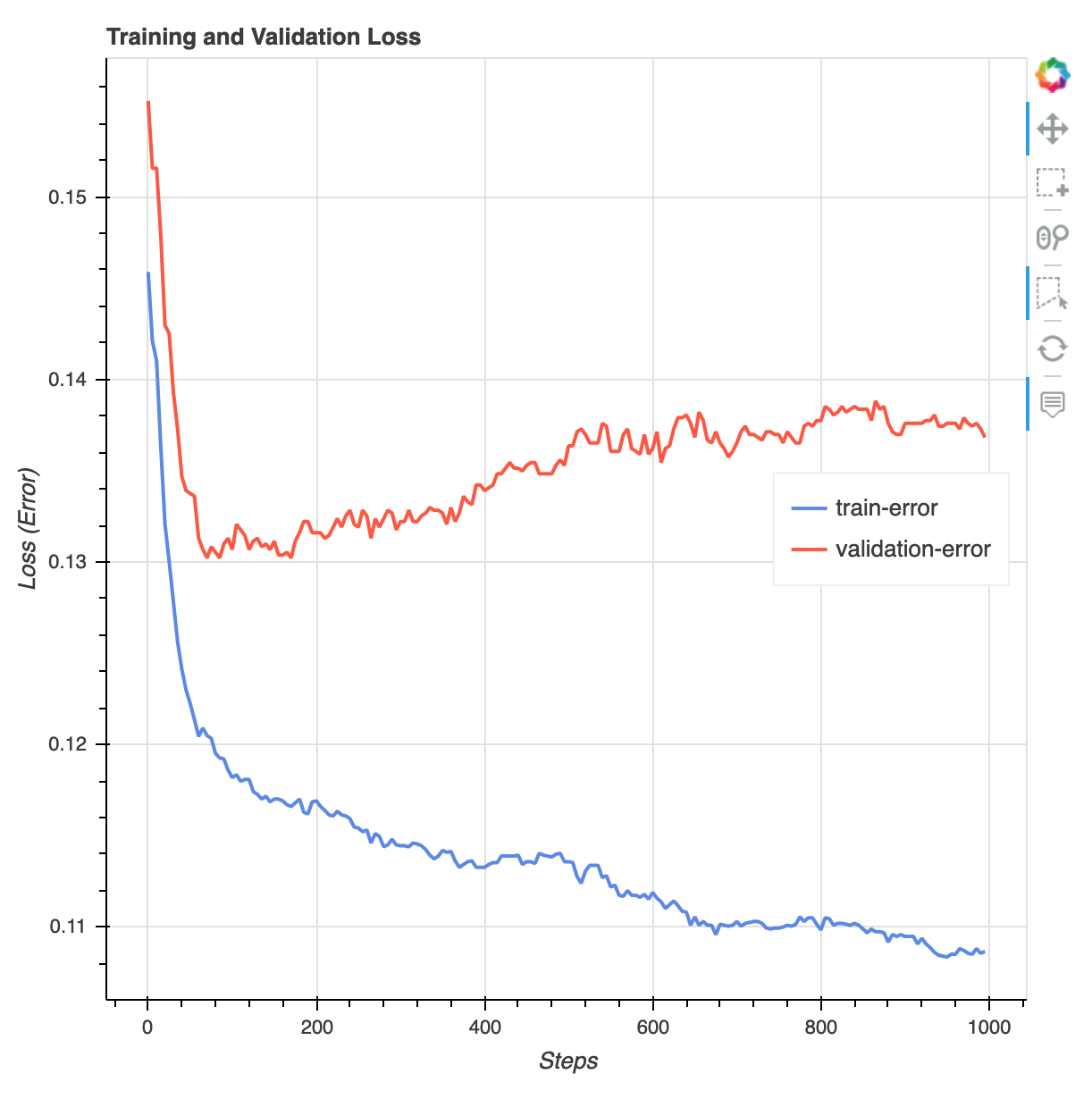
Exécutez le code suivant pour spécifier l'URI du compartiment S3 dans lequel les rapports d'entraînement de Debugger sont générés et vérifiez si les rapports existent.
rule_output_path = xgb_model.output_path + "/" + xgb_model.latest_training_job.job_name + "/rule-output" ! aws s3 ls {rule_output_path} --recursiveTéléchargez les rapports de XGBoost formation et de profilage du Debugger dans l'espace de travail actuel :
! aws s3 cp {rule_output_path} ./ --recursiveExécutez le IPython script suivant pour obtenir le lien vers le fichier du rapport de XGBoost formation :
from IPython.display import FileLink, FileLinks display("Click link below to view the XGBoost Training report", FileLink("CreateXgboostReport/xgboost_report.html"))Le IPython script suivant renvoie le lien du fichier du rapport de profilage du Debugger qui présente des résumés et des détails sur l'utilisation des ressources de l' EC2 instance, les résultats de détection des goulots d'étranglement du système et les résultats du profilage des opérations Python :
profiler_report_name = [rule["RuleConfigurationName"] for rule in xgb_model.latest_training_job.rule_job_summary() if "Profiler" in rule["RuleConfigurationName"]][0] profiler_report_name display("Click link below to view the profiler report", FileLink(profiler_report_name+"/profiler-output/profiler-report.html"))Astuce
Si les rapports HTML n'affichent pas de tracés dans la JupyterLab vue, vous devez sélectionner Trust HTML en haut des rapports.
Pour identifier les problèmes d'entraînement, tels que le surajustement, la disparition des dégradés et les autres problèmes qui empêchent la convergence de votre modèle, utilisez SageMaker Debugger et effectuez des actions automatisées lors du prototypage et de l'entraînement de vos modèles ML. Pour de plus amples informations, veuillez consulter SageMaker Débogueur Amazon. Pour obtenir une analyse complète des paramètres du modèle, consultez l'exemple de bloc-notes Explainability with Amazon SageMaker Debugger
.
Vous avez maintenant un XGBoost modèle entraîné. SageMaker L'IA stocke l'artefact du modèle dans votre compartiment S3. Pour trouver l'emplacement de l'artefact du modèle, exécutez le code suivant pour imprimer l'attribut model_data de l'estimateur xgb_model :
xgb_model.model_data
Astuce
Pour mesurer les biais qui peuvent survenir à chaque étape du cycle de vie du machine learning (collecte de données, apprentissage et réglage des modèles, surveillance des modèles de machine learning déployés à des fins de prédiction), utilisez SageMaker Clarify. Pour de plus amples informations, veuillez consulter Explicabilité du modèle. Pour un end-to-end exemple, consultez l'exemple de bloc-notes Équité et explicabilité avec SageMaker Clarify
