Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Métriques Amazon SageMaker AI sur Amazon CloudWatch
Vous pouvez surveiller Amazon SageMaker AI à l'aide d'Amazon CloudWatch, qui collecte les données brutes et les transforme en indicateurs lisibles en temps quasi réel. Ces statistiques sont conservées pendant 15 mois. Grâce à eux, vous pouvez accéder à des informations historiques et avoir une meilleure idée des performances de votre application ou service Web. Cependant, la CloudWatch console Amazon limite la recherche aux statistiques mises à jour au cours des deux dernières semaines. Cette limitation permet de s'assurer que les tâches les plus récentes sont indiquées dans votre espace de noms.
Pour représenter graphiquement les métriques sans utiliser une recherche, spécifiez son nom exact dans l'affichage de la source. Vous pouvez également définir des alarmes qui surveillent certains seuils et envoient des notifications ou prennent des mesures lorsque ces seuils sont atteints. Pour plus d'informations, consultez le guide de CloudWatch l'utilisateur Amazon.
SageMaker Métriques et dimensions de l'IA
SageMaker Métriques d'invocation des terminaux AI
L'espace de noms AWS/SageMaker inclut les métriques de demandes suivantes des appels vers InvokeEndpoint.
Les métriques sont disponibles à la fréquence d'une (1) minute.
L'illustration suivante montre comment un point de terminaison SageMaker AI interagit avec l'API Amazon SageMaker Runtime. Le délai global entre l'envoi d'une demande à un point de terminaison et la réception d'une réponse dépend des trois composants suivants.
-
Latence du réseau : temps qui s'écoule entre l'envoi d'une demande et la réception d'une réponse de la part de l'API SageMaker Runtime Runtime.
-
Latence de surcharge : temps nécessaire pour transporter une demande vers le conteneur modèle depuis l'API SageMaker Runtime Runtime et pour renvoyer la réponse vers celle-ci.
-
Latence du modèle : temps nécessaire au conteneur de modèle pour traiter la demande et renvoyer une réponse.
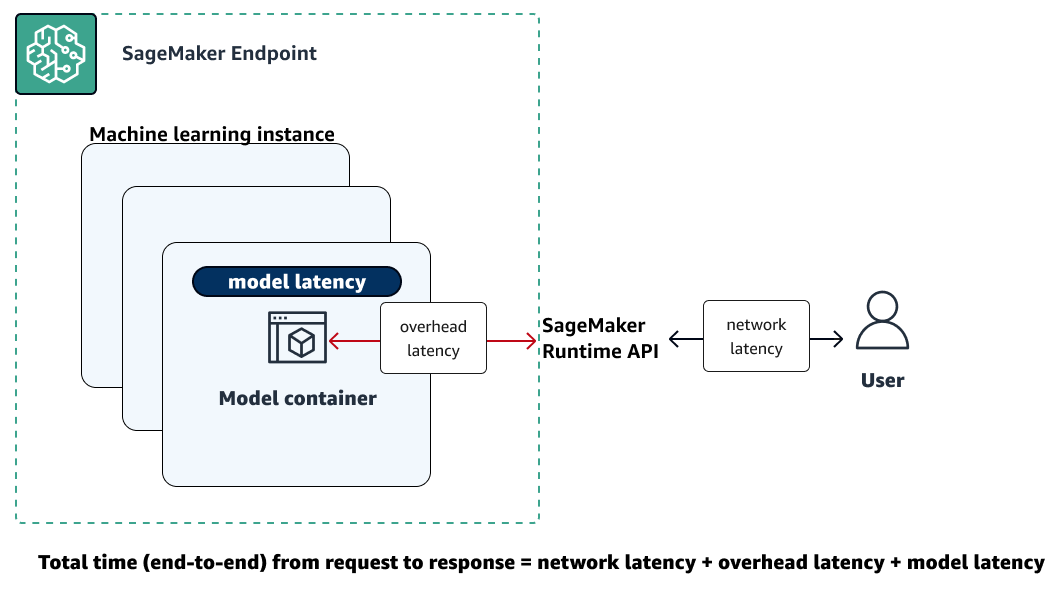
Pour plus d'informations sur la latence totale, consultez les meilleures pratiques pour tester la charge des points de terminaison d'inférence en temps réel Amazon SageMaker AI
Endpoint Invocation Metrics (Métriques d'appel de point de terminaison)
| Métrique | Description |
|---|---|
ConcurrentRequestsPerCopy |
Le nombre de demandes simultanées reçues par le composant d'inférence, normalisé par chaque copie d'un composant d'inférence. Statistiques valides : Min, Max |
ConcurrentRequestsPerModel |
Le nombre de demandes simultanées reçues par le modèle. Statistiques valides : Min, Max |
Invocation4XXErrors |
Nombre de demandes Unités : aucune Statistiques valides : Moyenne, somme |
Invocation5XXErrors |
Nombre de demandes Unités : aucune Statistiques valides : Moyenne, somme |
InvocationModelErrors |
Le nombre de demandes d'invocation de modèles qui n'ont pas entraîné de réponse HTTP 2XX. Cela inclut les codes d'état 4XX/5XX, les erreurs de socket de bas niveau, les réponses HTTP mal formées et les délais d'expiration des demandes. Pour chaque réponse d'erreur, 1 est envoyé. Dans le cas contraire, la valeur 0 est envoyée. Unités : aucune Statistiques valides : Moyenne, somme |
Invocations |
Le nombre de demandes Pour obtenir le nombre total de demandes envoyées à un point de terminaison de modèle, utilisez la statistique Somme. Unités : aucune Statistiques valides : somme |
InvocationsPerCopy |
Le nombre d'appels normalisés par chaque copie d'un composant d'inférence. Statistiques valides : somme |
InvocationsPerInstance |
Le nombre d'appels envoyés à un modèle, normalisé par Unités : aucune Statistiques valides : somme |
ModelLatency |
Intervalle de temps nécessaire à un modèle pour répondre à une demande SageMaker d'API Runtime. Cet intervalle inclut les temps de communication locaux nécessaires pour envoyer la demande et récupérer la réponse depuis le conteneur modèle. Il inclut également le temps nécessaire pour effectuer l'inférence dans le conteneur. Unités : microsecondes Statistiques valides : moyenne, Somme, Min, Max, Exemple de comptage, Centiles |
ModelSetupTime |
Le temps nécessaire au lancement de nouvelles ressources de calcul pour un point de terminaison sans serveur. Le temps peut varier en fonction de la taille du modèle, du temps nécessaire au téléchargement du modèle et de l'heure de démarrage du conteneur. Unités : microsecondes Statistiques valides : Moyenne, Min, Max, Exemple de comptage, Centiles |
OverheadLatency |
Intervalle de temps ajouté au temps nécessaire pour répondre à une demande client par les responsables de l' SageMaker IA. Cet intervalle est mesuré à partir du moment où l' SageMaker IA reçoit la demande jusqu'à ce qu'elle renvoie une réponse au client, moins le Unités : microsecondes Statistiques valides : Moyenne, Somme, Min, Max, Exemple de comptage |
Dimensions for Endpoint Invocation Metrics (Dimensions des métriques d'appel de point de terminaison)
| Dimension | Description |
|---|---|
EndpointName, VariantName |
Filtre les métriques d'appel de point de terminaison pour un |
InferenceComponentName |
Filtre les métriques d'invocation des composants d'inférence. |
SageMaker Métriques des composants d'inférence de l'IA
L'espace de /aws/sagemaker/InferenceComponents noms inclut les métriques suivantes issues des appels InvokeEndpointdestinés aux points de terminaison hébergeant des composants d'inférence.
Les métriques sont disponibles à la fréquence d'une (1) minute.
| Métrique | Description |
|---|---|
CPUUtilizationNormalized |
La valeur de la |
GPUMemoryUtilizationNormalized |
La valeur de la |
GPUUtilizationNormalized |
La valeur de la |
MemoryUtilizationNormalized |
La valeur |
Dimensions pour les métriques des composants d'inférence
| Dimension | Description |
|---|---|
InferenceComponentName |
Filtre les métriques des composants d'inférence. |
SageMaker Indicateurs de terminaux multi-modèles basés sur l'IA
L'espace de AWS/SageMaker noms inclut les métriques de chargement du modèle suivantes à partir d'appels vers InvokeEndpoint.
Les métriques sont disponibles à la fréquence d'une (1) minute.
Pour plus d'informations sur la durée de conservation des CloudWatch métriques, consultez GetMetricStatisticsle Amazon CloudWatch API Reference.
Métriques de chargement du modèle de point de terminaison multimodèle
| Métrique | Description |
|---|---|
ModelLoadingWaitTime |
Intervalle de temps pendant lequel une demande d'invocation attend le téléchargement, le chargement ou les deux du modèle cible afin d'exécuter l'inférence. Unités : microsecondes Statistiques valides : Moyenne, Somme, Min, Max, Exemple de comptage |
ModelUnloadingTime |
Intervalle de temps nécessaire pour décharger le modèle via l'appel d'API Unités : microsecondes Statistiques valides : Moyenne, Somme, Min, Max, Exemple de comptage |
ModelDownloadingTime |
Intervalle de temps nécessaire pour télécharger le modèle depuis Amazon Simple Storage Service (Amazon S3). Unités : microsecondes Statistiques valides : Moyenne, Somme, Min, Max, Exemple de comptage |
ModelLoadingTime |
Intervalle de temps nécessaire pour charger le modèle via l'appel de l'API Unités : microsecondes Statistiques valides : Moyenne, Somme, Min, Max, Exemple de comptage |
ModelCacheHit |
Nombre de demandes La statistique Average (Moyenne) indique le ratio des demandes pour lesquelles le modèle a déjà été chargé. Unités : aucune Statistiques valides : Average (Moyenne), Sum (Somme), Sample Count (Nombre d'exemples) |
Dimensions for Multi-Model Endpoint Model Loading Metrics (Dimensions des métriques de chargement du modèle de point de terminaison multimodèle)
| Dimension | Description |
|---|---|
EndpointName, VariantName |
Filtre les métriques d'appel de point de terminaison pour un |
Les espaces de noms /aws/sagemaker/Endpoints incluent les métriques d'instance suivantes des appels vers InvokeEndpoint.
Les métriques sont disponibles à la fréquence d'une (1) minute.
Pour plus d'informations sur la durée de conservation des CloudWatch métriques, consultez GetMetricStatisticsle Amazon CloudWatch API Reference.
Métriques d'instance de modèle de point de terminaison multimodèle
| Métrique | Description |
|---|---|
LoadedModelCount |
Nombre de modèles chargés dans les conteneurs du point de terminaison multimodèle. Cette métrique est émise par instance. La statistique Average (Moyenne) avec une période de 1 minute indique le nombre moyen de modèles chargés par instance. La statistique Sum (Somme) indique le nombre total de modèles chargés sur toutes les instances du point de terminaison. Les modèles que cette métrique suit ne sont pas nécessairement uniques, car un modèle peut être chargé dans plusieurs conteneurs au point de terminaison. Unités : aucune Statistiques valides : Moyenne, Somme, Min, Max, Exemple de comptage |
Dimensions for Multi-Model Endpoint Model Loading Metrics (Dimensions des métriques de chargement du modèle de point de terminaison multimodèle)
| Dimension | Description |
|---|---|
EndpointName, VariantName |
Filtre les métriques d'appel de point de terminaison pour un |
SageMaker Jobs liés à l'IA et indicateurs des terminaux
Les /aws/sagemaker/Endpoints espaces de noms /aws/sagemaker/ProcessingJobs/aws/sagemaker/TrainingJobs,/aws/sagemaker/TransformJobs, et incluent les métriques suivantes pour les tâches de formation et les instances de point de terminaison.
Les métriques sont disponibles à la fréquence d'une (1) minute.
Note
Amazon CloudWatch prend en charge les métriques personnalisées en haute résolution et sa résolution maximale est d'une seconde. Cependant, plus la résolution est fine, plus la durée de vie des CloudWatch métriques est courte. Pour la résolution de fréquence d'une seconde, les CloudWatch métriques sont disponibles pendant 3 heures. Pour plus d'informations sur la résolution et la durée de vie des CloudWatch métriques, consultez GetMetricStatisticsle Amazon CloudWatch API Reference.
Astuce
Pour établir le profil de votre tâche de formation avec une résolution plus fine, jusqu'à une granularité de 100 millisecondes (0,1 seconde) et pour stocker les indicateurs de formation indéfiniment dans Amazon S3 pour une analyse personnalisée à tout moment, pensez à utiliser Amazon Debugger. SageMaker SageMaker Debugger fournit des règles intégrées pour détecter automatiquement les problèmes d'entraînement courants. Il détecte les problèmes d'utilisation des ressources matérielles (tels que le processeur, le processeur graphique et les goulots d' I/O étranglement). Il détecte également les problèmes de modèle non convergents (tels que le surajustement, la disparition des dégradés et l'explosion des tenseurs). SageMaker Debugger fournit également des visualisations via Studio Classic et son rapport de profilage. Pour explorer les visualisations du Debugger, consultez les rubriques Procédure pas à pas du tableau de bord SageMaker Debugger Insights, Procédure pas à pas du rapport de profilage du Debugger et Analyser les données à l'aide de la bibliothèque cliente. SMDebug
Métriques des tâches de traitement, des tâches d'entraînement, des tâches de transformation par lots et d'instances de point de terminaison
| Métrique | Description |
|---|---|
CPUReservation |
La somme des réserves CPUs réservées par les conteneurs sur une instance. La valeur est comprise entre 0 % et 100 %. Dans les paramètres d'un composant d'inférence, vous définissez la réservation du processeur avec le |
CPUUtilization |
La somme de l'utilisation de chaque cœur de processeur individuel. L'utilisation du processeur de chaque cœur peut aller de 0 à 100. Par exemple, s'il y en a quatre CPUs, la CPUUtilization plage est comprise entre 0 % et 400 %. Pour les tâches de traitement, la valeur est l'utilisation du processeur du conteneur de traitement sur l'instance.Pour les tâches d'entraînement, la valeur est l'utilisation de l'UC du conteneur de l'algorithme sur l'instance. Pour les tâches de transformation par lots, la valeur est l'utilisation de l'UC du conteneur de transformation sur l'instance. Pour les variantes de point de terminaison, la valeur est la somme de l'utilisation de l'UC du conteneur principal et des conteneurs supplémentaires sur l'instance. NotePour les tâches à instances multiples, chaque instance rapporte des métriques d'utilisation d'UC. Cependant, la vue par défaut CloudWatch indique l'utilisation moyenne du processeur sur toutes les instances. Unités : pourcentage |
CPUUtilizationNormalized |
Somme normalisée de l'utilisation de chaque cœur de processeur individuel. La valeur est comprise entre 0 % et 100 %. Par exemple, s'il y en a quatre CPUs et que la |
DiskUtilization |
Le pourcentage d'espace disque utilisé par les conteneurs sur les utilisations d'une instance. Cette plage de valeurs est comprise entre 0 % et 100 %. Cette métrique n'est pas prise en charge pour les tâches de transformation par lots. Pour les tâches de traitement, la valeur est l'utilisation de l'espace disque du conteneur de traitement sur l'instance.Pour les tâches d'entraînement, la valeur est l'utilisation de l'espace disque du conteneur de l'algorithme sur l'instance. Pour les variantes de point de terminaison, la valeur est la somme de l'utilisation de l'espace disque du conteneur principal et des conteneurs supplémentaires sur l'instance. Unités : pourcentage NotePour les tâches à instances multiples, chaque instance rapporte des métriques d'utilisation des disques. Cependant, la vue par défaut CloudWatch indique l'utilisation moyenne du disque sur toutes les instances. |
GPUMemoryUtilization |
Pourcentage de mémoire GPU utilisée par les conteneurs sur une instance. La plage de valeurs est comprise entre 0 et 100 et est multipliée par le nombre de. GPUs Par exemple, s'il y en a quatre GPUs, la Pour les tâches d'entraînement, la valeur est l'utilisation de la mémoire GPU du conteneur de l'algorithme sur l'instance. Pour les tâches de transformation par lots, la valeur est l'utilisation de la mémoire GPU du conteneur de transformation sur l'instance. Pour les variantes de point de terminaison, la valeur est la somme de l'utilisation de la mémoire GPU du conteneur principal et des conteneurs supplémentaires sur l'instance. NotePour les tâches à instances multiples, chaque instance rapporte des métriques d'utilisation de la mémoire GPU. Cependant, la vue par défaut CloudWatch indique l'utilisation moyenne de la mémoire du GPU sur toutes les instances. Unités : pourcentage |
GPUMemoryUtilizationNormalized |
Pourcentage normalisé de mémoire GPU utilisée par les conteneurs d'une instance. La valeur est comprise entre 0 % et 100 %. Par exemple, s'il y en a quatre GPUs et que la |
GPUReservation |
La somme des réserves GPUs réservées par les conteneurs sur une instance. La valeur est comprise entre 0 % et 100 %. Dans les paramètres d'un composant d'inférence, vous définissez la réservation du GPU par |
GPUUtilization |
Pourcentage d'unités GPU utilisées par les conteneurs sur une instance. La valeur peut être comprise entre 0 et 100 et est multipliée par le nombre de. GPUs Par exemple, s'il y en a quatre GPUs, la Pour les tâches d'entraînement, la valeur est l'utilisation de GPU du conteneur de l'algorithme sur l'instance. Pour les tâches de transformation par lots, la valeur est l'utilisation de GPU du conteneur de transformation sur l'instance. Pour les variantes de point de terminaison, la valeur est la somme de l'utilisation d'unités GPU du conteneur principal et des conteneurs supplémentaires sur l'instance. NotePour les tâches à instances multiples, chaque instance rapporte des métriques d'utilisation des GPU. Cependant, la vue par défaut CloudWatch indique l'utilisation moyenne du GPU sur toutes les instances. Unités : pourcentage |
GPUUtilizationNormalized |
Pourcentage normalisé d'unités GPU utilisées par les conteneurs d'une instance. La valeur est comprise entre 0 % et 100 %. Par exemple, s'il y en a quatre GPUs et que la |
MemoryReservation |
La somme de la mémoire réservée par les conteneurs sur une instance. La valeur est comprise entre 0 % et 100 %. Dans les paramètres d'un composant d'inférence, vous définissez la réservation de mémoire avec le |
MemoryUtilization |
Pourcentage de mémoire utilisée par les conteneurs sur une instance. Cette plage de valeurs est comprise entre 0 % et 100 %. Pour les tâches de traitement, la valeur est l'utilisation de la mémoire du conteneur de traitement sur l'instance.Pour les tâches d'entraînement, la valeur est l'utilisation de la mémoire du conteneur de l'algorithme sur l'instance. Pour les tâches de transformation par lots, la valeur est l'utilisation de la mémoire du conteneur de transformation sur l'instance. Pour les variantes de point de terminaison, la valeur est la somme de l'utilisation de la mémoire du conteneur principal et des conteneurs supplémentaires sur l'instance. Unités : pourcentage NotePour les tâches à instances multiples, chaque instance rapporte des métriques d'utilisation de mémoire. Cependant, la vue par défaut CloudWatch indique l'utilisation moyenne de la mémoire sur toutes les instances. |
Dimensions des métriques d'instances de tâches de traitement, de tâches d'entraînement et de tâches de transformation par lots
| Dimension | Description |
|---|---|
Host |
Pour les tâches de traitement, la valeur de cette dimension est au format Pour les tâches d'entraînement, la valeur de cette dimension est au format Pour les tâches de transformation par lots, la valeur de cette dimension est au format |
SageMaker Indicateurs des tâches d'Inference Recommender
L'espace de noms /aws/sagemaker/InferenceRecommendationsJobs inclut les métriques suivantes pour les tâches de recommandation d'inférence.
Inference Recommender Metrics (Métriques Inference Recommender)
| Métrique | Description |
|---|---|
ClientInvocations |
Le nombre de demandes Unités : aucune Statistiques valides : somme |
ClientInvocationErrors |
Le nombre de demandes Unités : aucune Statistiques valides : somme |
ClientLatency |
L'intervalle de temps requis entre l'envoi d'un appel Unités : millisecondes Statistiques valides : moyenne, Somme, Min, Max, Exemple de comptage, Centiles |
NumberOfUsers |
Le nombre d'utilisateurs simultanés envoyant des demandes Unités : aucune Statistiques valides : maximum, minimum, moyenne |
Dimensions des métriques de tâche Inference Recommender
| Dimension | Description |
|---|---|
JobName |
Filtre les métriques de tâche Inference Recommender pour la tâche Inference Recommender spécifiée. |
EndpointName |
Filtre les métriques de tâche Inference Recommender pour le point de terminaison spécifié. |
SageMaker Métriques de Ground Truth
Métriques Ground Truth
| Métrique | Description |
|---|---|
ActiveWorkers |
Un seul employé actif au sein d'une équipe de travail privée a envoyé, publié ou refusé une tâche. Pour obtenir le nombre total d'employés actifs, utilisez la statistique Somme. Ground Truth essaie de proposer chaque Unités : aucune Statistiques valides : Somme, Exemple de comptage |
DatasetObjectsAutoAnnotated |
Le nombre d'objets de jeux de données annotés automatiquement dans une tâche d'étiquetage. Cette métrique est émise uniquement lorsque l'étiquetage automatique est activé. Pour afficher la progression de la tâche d'étiquetage, utilisez la métrique Max. Unités : aucune Statistiques valides : Max |
DatasetObjectsHumanAnnotated |
Le nombre d'objets de jeux de données annotés manuellement dans une tâche d'étiquetage. Pour afficher la progression de la tâche d'étiquetage, utilisez la métrique Max. Unités : aucune Statistiques valides : Max |
DatasetObjectsLabelingFailed |
Le nombre d'objets de jeux de données pour lesquels l'étiquetage a échoué dans une tâche d'étiquetage. Pour afficher la progression de la tâche d'étiquetage, utilisez la métrique Max. Unités : aucune Statistiques valides : Max |
JobsFailed |
Une seule tâche d'étiquetage a échoué. Pour obtenir le nombre total des tâches d'étiquetage qui ont échoué, utilisez la statistique Somme. Unités : aucune Statistiques valides : Somme, Exemple de comptage |
JobsSucceeded |
Une seule tâche d'étiquetage a réussi. Pour obtenir le nombre total des tâches d'étiquetage qui ont réussi, utilisez la statistique Somme. Unités : aucune Statistiques valides : Somme, Exemple de comptage |
JobsStopped |
Une seule tâche d'étiquetage a été arrêtée. Pour obtenir le nombre total des tâches d'étiquetage qui ont été arrêtées, utilisez la statistique Somme. Unités : aucune Statistiques valides : Somme, Exemple de comptage |
TasksAccepted |
Une seule tâche a été acceptée par un employé. Pour obtenir le nombre total des tâches acceptées par les employés, utilisez la statistique Somme. Ground Truth s'efforce de n'envoyer chaque événement Unités : aucune Statistiques valides : Somme, Exemple de comptage |
TasksDeclined |
Une seule tâche a été refusée par un employé. Pour obtenir le nombre total des tâches refusées par les employés, utilisez la statistique Somme. Ground Truth s'efforce de n'envoyer chaque événement Unités : aucune Statistiques valides : Somme, Exemple de comptage |
TasksReturned |
Une seule tâche a été renvoyée. Pour obtenir le nombre total des tâches renvoyées, utilisez la statistique Somme. Ground Truth s'efforce de n'envoyer chaque événement Unités : aucune Statistiques valides : Somme, Exemple de comptage |
TasksSubmitted |
Une seule tâche a été submitted/completed confiée à un travailleur privé. Pour obtenir le nombre total des tâches envoyées par les employés, utilisez la statistique Somme. Ground Truth s'efforce de n'envoyer chaque événement Unités : aucune Statistiques valides : Somme, Exemple de comptage |
TimeSpent |
Temps passé sur une tâche terminée par un employé privé. Cette métrique n'inclut pas l'heure à laquelle un employé s'est mis en pause ou a pris une pause. Ground Truth s'efforce de n'envoyer chaque événement Unités : secondes Statistiques valides : Somme, Exemple de comptage |
TotalDatasetObjectsLabeled |
Le nombre d'objets de jeux de données étiquetés avec succès dans une tâche d'étiquetage. Pour afficher la progression de la tâche d'étiquetage, utilisez la métrique Max. Unités : aucune Statistiques valides : Max |
Dimensions des métriques d'objets de jeux de données
| Dimension | Description |
|---|---|
LabelingJobName |
Filtre les métriques de nombre d'objets de jeu de données pour une tâche d'étiquetage. |
Statistiques de l'Amazon SageMaker Feature Store
Métriques de consommation de Feature Store
| Métrique | Description |
|---|---|
ConsumedReadRequestsUnits |
Nombre d'unités de lecture consommées durant la période spécifiée. Vous pouvez récupérer les unités de lecture consommées pour une opération d'exécution de Feature Store et son groupe de fonctions correspondant. Unités : aucune Statistiques valides : toutes |
ConsumedWriteRequestsUnits |
Nombre d'unités d'écriture consommées durant la période spécifiée. Vous pouvez récupérer les unités d'écriture consommées pour une opération d'exécution de Feature Store et son groupe de fonctions correspondant. Unités : aucune Statistiques valides : toutes |
ConsumedReadCapacityUnits |
Nombre d'unités de capacité de lecture allouées consommées au cours de la période spécifiée. Vous pouvez récupérer les unités de capacité de lecture consommées pour une opération d'exécution du feature store et le groupe de fonctionnalités correspondant. Unités : aucune Statistiques valides : toutes |
ConsumedWriteCapacityUnits |
Nombre d'unités de capacité d'écriture allouées consommées au cours de la période spécifiée. Vous pouvez récupérer les unités de capacité d'écriture consommées pour une opération d'exécution du feature store et le groupe de fonctionnalités correspondant. Unités : aucune Statistiques valides : toutes |
Dimensions des métriques de consommation de Feature Store
| Dimension | Description |
|---|---|
FeatureGroupName, OperationName |
Filtre les métriques d'opération d'exécution de Feature Store du groupe de fonctionnalités et de l'opération spécifiés. |
Métriques opérationnels de Feature Store
| Métrique | Description |
|---|---|
Invocations |
Nombre de demandes faites aux opérations d'exécution de feature store au cours de la période spécifiée. Unités : aucune Statistiques valides : somme |
Operation4XXErrors |
Nombre de demandes faites aux opérations d'exécution de Feature Store dans lesquelles l'opération a retourné un code de réponse HTTP 4xx. Pour chaque réponse 4xx, 1 est envoyé ; sinon, 0 est envoyé. Unités : aucune Statistiques valides : Moyenne, somme |
Operation5XXErrors |
Nombre de demandes faites aux opérations d'exécution de feature store dans lesquelles l'opération a retourné un code de réponse HTTP 5xx. Pour chaque réponse 5xx, 1 est envoyé ; sinon, 0 est envoyé. Unités : aucune Statistiques valides : Moyenne, somme |
ThrottledRequests |
Nombre de demandes faites aux opérations d'exécution de feature store dans lesquelles la demande a été limitée. Pour chaque demande limitée, 1 est envoyé ; sinon, 0 est envoyé. Unités : aucune Statistiques valides : Moyenne, somme |
Latency |
L'intervalle de temps nécessaire pour traiter les demandes adressées aux opérations d'exécution du Feature Store. Cet intervalle est mesuré à partir du moment où SageMaker AI reçoit la demande jusqu'à ce qu'il renvoie une réponse au client. Unités : microsecondes Statistiques valides : moyenne, Somme, Min, Max, Exemple de comptage, Centiles |
Dimensions des métriques opérationnelles de Feature Store
| Dimension | Description |
|---|---|
|
|
Filtre les métriques d'opération d'exécution de Feature Store du groupe de fonctionnalités et de l'opération spécifiés. Vous pouvez utiliser ces dimensions pour des opérations non groupées, telles que GetRecord PutRecord, et DeleteRecord. |
OperationName |
Filtre les métriques d'opération d'exécution de Feature Store de l'opération spécifiée. Vous pouvez utiliser cette dimension pour des opérations par lots telles que BatchGetRecord. |
SageMaker métriques des pipelines
L'espace de noms AWS/Sagemaker/ModelBuildingPipeline inclut les métriques suivantes pour les exécutions de pipeline.
Deux catégories de métriques d'exécution de pipelines sont disponibles :
-
Les métriques d'exécution sur tous les pipelines, qui sont les métriques d'exécution de pipeline au niveau du compte (pour tous les pipelines du compte courant)
-
Les métriques d'exécution par pipeline, qui sont les métriques d'exécution de pipeline par pipeline
Les métriques sont disponibles à la fréquence d'une (1) minute.
Métriques d'exécution de pipelines
| Métrique | Description |
|---|---|
ExecutionStarted |
Nombre d'exécutions de pipeline qui ont démarré. Unités : nombre Statistiques valides : Moyenne, somme |
ExecutionFailed |
Nombre d'exécutions de pipeline qui ont échoué. Unités : nombre Statistiques valides : Moyenne, somme |
ExecutionSucceeded |
Nombre d'exécutions de pipeline qui ont réussi. Unités : nombre Statistiques valides : Moyenne, somme |
ExecutionStopped |
Nombre d'exécutions de pipeline qui se sont arrêtées. Unités : nombre Statistiques valides : Moyenne, somme |
ExecutionDuration |
Durée en millisecondes de l'exécution du pipeline. Unités : millisecondes Statistiques valides : Moyenne, Somme, Min, Max, Exemple de comptage |
Dimensions des métriques d'exécution par pipeline
| Dimension | Description |
|---|---|
PipelineName |
Filtre les métriques d'exécution de pipeline pour un pipeline spécifié. |
Métriques d'étapes de pipeline
L'espace de noms AWS/Sagemaker/ModelBuildingPipeline inclut les métriques suivantes pour les étapes de pipeline.
Les métriques sont disponibles à la fréquence d'une (1) minute.
| Métrique | Description |
|---|---|
StepStarted |
Nombre d'étapes qui ont démarré. Unités : nombre Statistiques valides : Moyenne, somme |
StepFailed |
Nombre d'étapes qui ont échoué. Unités : nombre Statistiques valides : Moyenne, somme |
StepSucceeded |
Nombre d'étapes qui ont réussi. Unités : nombre Statistiques valides : Moyenne, somme |
StepStopped |
Nombre d'étapes qui se sont arrêtées. Unités : nombre Statistiques valides : Moyenne, somme |
StepDuration |
Durée en millisecondes de l'exécution de l'étape. Unités : millisecondes Statistiques valides : Moyenne, Somme, Min, Max, Exemple de comptage |
Dimensions des métriques d'étape de pipeline
| Dimension | Description |
|---|---|
PipelineName, StepName |
Filtre les métriques d'étape pour un pipeline et une étape spécifiés. |
