Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
SageMaker JumpStart modèles préentraînés
Amazon SageMaker JumpStart propose des modèles open source préformés pour un large éventail de types de problèmes afin de vous aider à démarrer avec le machine learning. Vous pouvez entraîner et ajuster progressivement ces modèles avant leur déploiement. JumpStart fournit également des modèles de solutions qui configurent l'infrastructure pour les cas d'utilisation courants, ainsi que des exemples de blocs-notes exécutables pour l'apprentissage automatique avec l' SageMaker IA.
Vous pouvez déployer, affiner et évaluer des modèles préentraînés à partir de hubs de modèles populaires via la page JumpStart d'accueil de l'expérience Studio mise à jour.
Vous pouvez également accéder à des modèles préentraînés, à des modèles de solutions et à des exemples via la page JumpStart d'accueil d'Amazon SageMaker Studio Classic.
Les étapes suivantes indiquent comment accéder aux JumpStart modèles à l'aide d'Amazon SageMaker Studio et d'Amazon SageMaker Studio Classic.
Vous pouvez également accéder aux JumpStart modèles à l'aide du SDK SageMaker Python. Pour plus d'informations sur l'utilisation des JumpStart modèles par programmation, voir Utiliser des SageMaker JumpStart algorithmes avec des modèles préentraînés
Ouvrir et utiliser JumpStart dans Studio
Les sections suivantes fournissent des informations sur la façon d'ouvrir, d'utiliser et JumpStart de gérer à partir de l'interface utilisateur de Studio.
Important
Depuis le 30 novembre 2023, l'expérience Amazon SageMaker Studio précédente s'appelle désormais Amazon SageMaker Studio Classic. La section suivante est spécifique à l'utilisation de l'expérience Studio mise à jour. Pour plus d'informations sur l'utilisation de l'application Studio Classic, consultezAmazon SageMaker Studio classique.
Ouvrir JumpStart dans le studio
Dans Amazon SageMaker Studio, ouvrez la page de JumpStart destination via la page d'accueil ou le menu principal sur le panneau de gauche. Cela ouvre la page SageMaker JumpStartd'accueil où vous pouvez explorer les hubs de modèles et rechercher des modèles.
-
Sur la page d'accueil, choisissez JumpStartdans le volet Solutions prédéfinies et automatisées.
-
Dans le menu principal du panneau de gauche, accédez au SageMaker JumpStartnœud.
Pour plus d'informations sur la prise en main d'Amazon SageMaker Studio, consultezAmazon SageMaker Studio.
Important
Avant de télécharger ou d'utiliser un contenu tiers : vous êtes tenu d'examiner et de respecter les conditions de licence applicables et de vous assurer qu'elles sont acceptables pour votre cas d'utilisation.
Utilisation JumpStart en studio
Depuis la page SageMaker JumpStartd'accueil de Studio, vous pouvez découvrir les hubs de modèles proposés par des fournisseurs de modèles propriétaires ou accessibles au public.
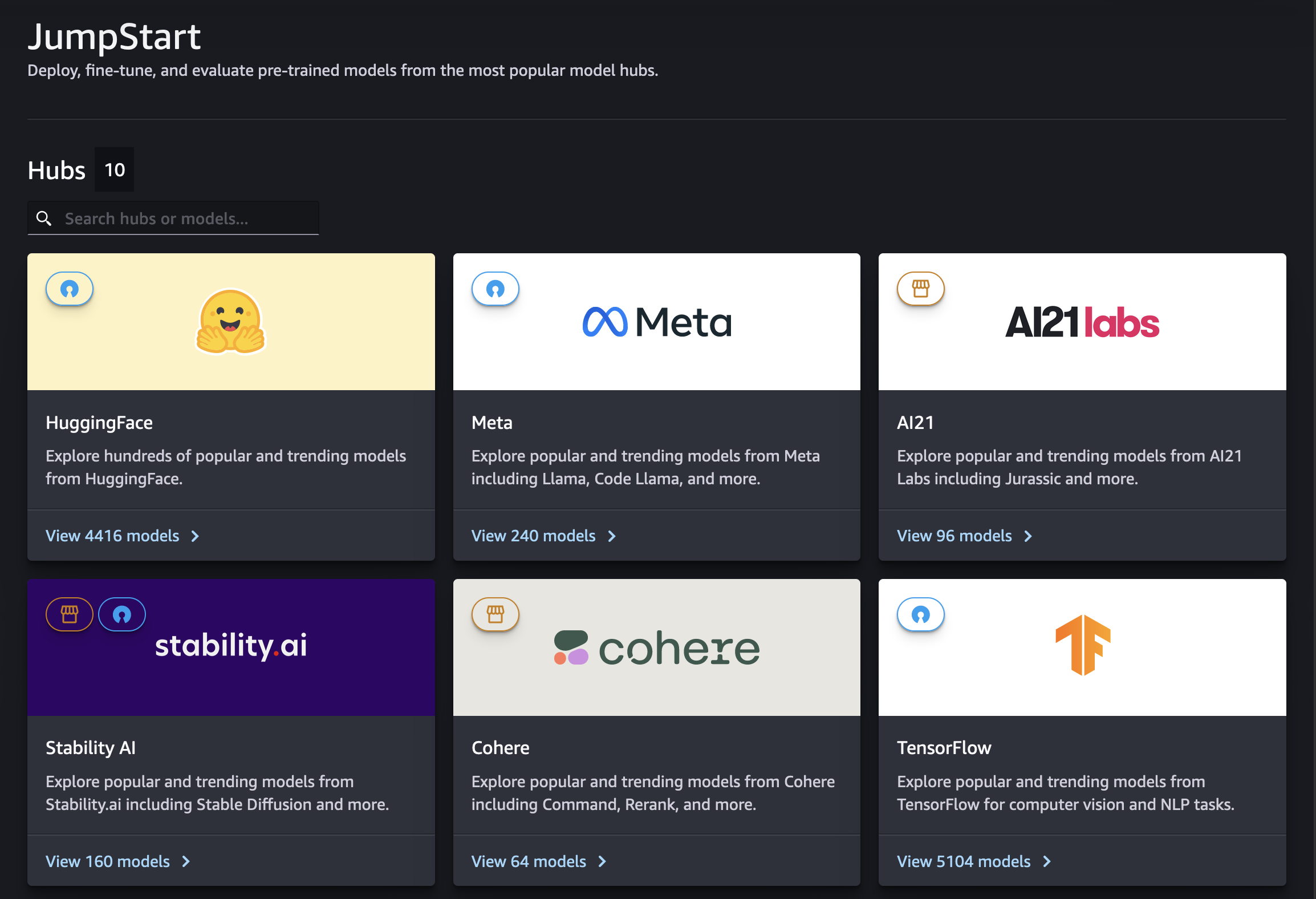
Vous pouvez trouver des hubs ou des modèles spécifiques à l'aide de la barre de recherche. Dans chaque hub de modèles, vous pouvez rechercher directement des modèles, les trier en fonction des attributs fournis ou les filtrer en fonction d'une liste de tâches de modèle fournies.
Gérer JumpStart dans Studio
Choisissez un modèle pour voir sa fiche détaillée. Dans le coin supérieur droit de la fiche détaillée du modèle, choisissez Affiner, Déployer ou Évaluer pour commencer à travailler sur les flux de travail de réglage, de déploiement ou d'évaluation, respectivement. Notez que tous les modèles ne sont pas disponibles pour un réglage précis ou une évaluation. Pour plus d'informations sur chacune de ces options, consultezUtiliser des modèles de base dans Studio.
Ouvrir et utiliser JumpStart dans Studio Classic
Les sections suivantes fournissent des informations sur la façon d'ouvrir, d'utiliser et JumpStart de gérer à partir de l'interface utilisateur Amazon SageMaker Studio Classic.
Important
Depuis le 30 novembre 2023, l'expérience Amazon SageMaker Studio précédente s'appelle désormais Amazon SageMaker Studio Classic. La section suivante est spécifique à l'utilisation de l'application Studio Classic. Pour plus d'informations sur l'utilisation de l'expérience Studio mise à jour, consultezAmazon SageMaker Studio.
Ouvrir JumpStart dans Studio Classic
Dans Amazon SageMaker Studio Classic, ouvrez la page de JumpStart destination via la page d'accueil ou le menu principal sur le panneau de gauche.
-
Sur la page Home (Accueil), vous pouvez soit :
-
Choisissez JumpStartdans le volet Solutions prédéfinies et automatisées. Cela ouvre la page de SageMaker JumpStartdestination.
-
Choisissez un modèle directement sur la page SageMaker JumpStartd'accueil ou choisissez l'option Tout explorer pour voir les solutions disponibles ou les modèles d'un type spécifique.
-
-
Dans le menu Home (Accueil) du panneau de gauche, vous pouvez :
-
Accédez au SageMaker JumpStartnœud, puis choisissez Modèles, blocs-notes, solutions. Cela ouvre la page de SageMaker JumpStartdestination.
-
Accédez au JumpStartnœud, puis choisissez Launched JumpStart assets.
La page JumpStart Ressources lancées répertorie les solutions actuellement lancées, les modèles de terminaux déployés et les tâches de formation créées avec JumpStart. Vous pouvez accéder à la page de JumpStart destination depuis cet onglet en cliquant sur le JumpStart bouton Parcourir en haut à droite de l'onglet.
-
La page JumpStart d'accueil répertorie les solutions d'apprentissage end-to-end automatique disponibles, les modèles préentraînés et des exemples de blocs-notes. Depuis n'importe quelle page de solution ou de modèle, vous pouvez JumpStart cliquer sur le bouton Parcourir (
 ) en haut à droite de l'onglet pour revenir à la SageMaker JumpStartpage.
) en haut à droite de l'onglet pour revenir à la SageMaker JumpStartpage.

Important
Avant de télécharger ou d'utiliser un contenu tiers : vous êtes tenu d'examiner et de respecter les conditions de licence applicables et de vous assurer qu'elles sont acceptables pour votre cas d'utilisation.
Utilisation JumpStart dans Studio Classic
Depuis la page SageMaker JumpStartd'accueil, vous pouvez rechercher des solutions, des modèles, des blocs-notes et d'autres ressources.
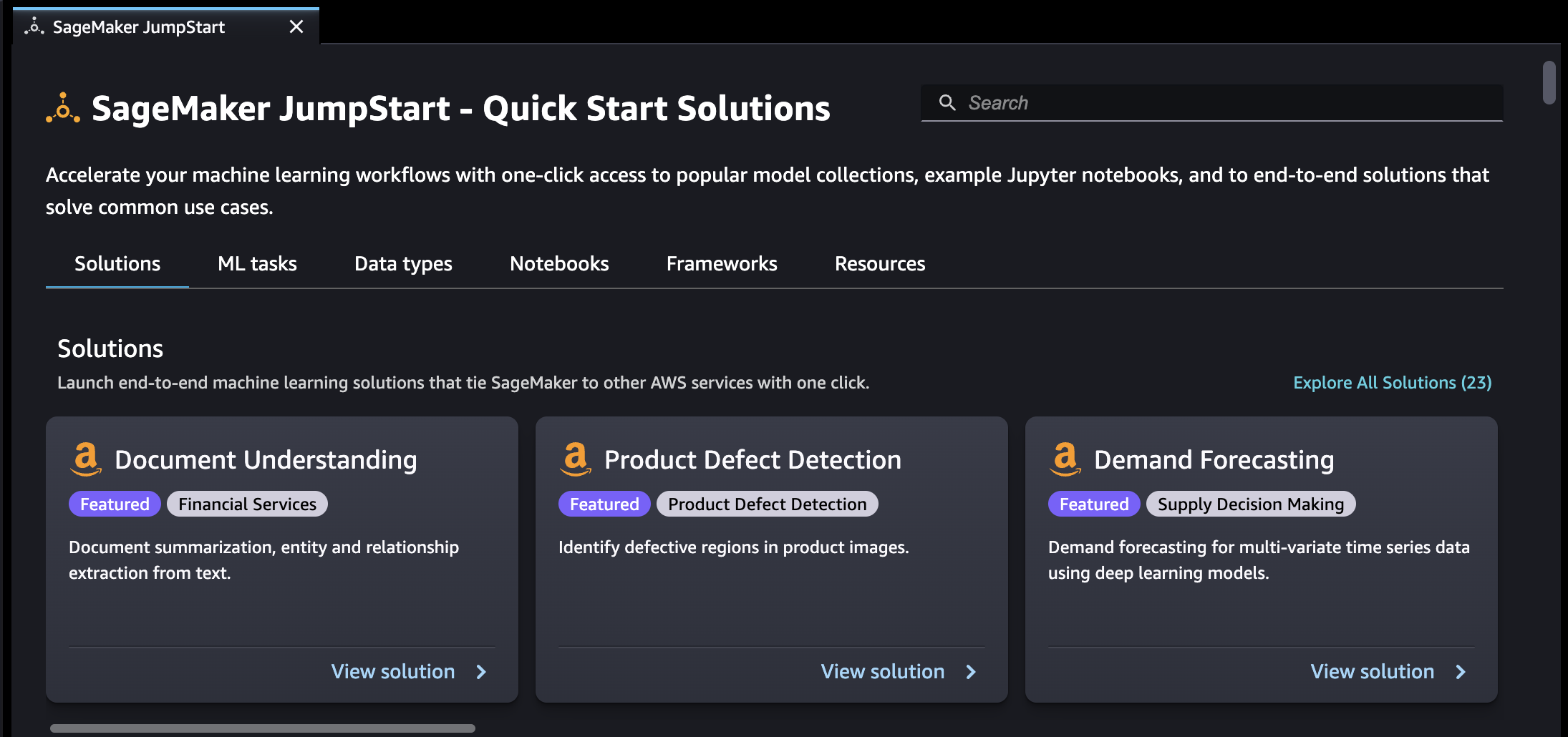
Vous pouvez trouver JumpStart des ressources en utilisant la barre de recherche ou en parcourant chaque catégorie. Utilisez les onglets pour filtrer les solutions disponibles par catégories :
-
Solutions — En une seule étape, lancez des solutions complètes d'apprentissage automatique qui relient l' SageMaker IA aux autres Services AWS. Sélectionnez Explore All Solutions (Explorer toutes les solutions) pour afficher toutes les solutions disponibles.
-
Resources (Ressources) - Utilisez des blocs-notes d'exemples, des blogs et des tutoriels vidéo pour apprendre et vous lancer dans la résolution de vos types de problèmes.
-
Blogs : lisez les détails et les solutions des experts en machine learning.
-
Tutoriels vidéo — Regardez des didacticiels vidéo sur les fonctionnalités de l' SageMaker IA et les cas d'utilisation de l'apprentissage automatique élaborés par des experts en apprentissage automatique.
-
Exemples de blocs-notes : exécutez des exemples de blocs-notes qui utilisent des fonctionnalités d' SageMaker intelligence artificielle telles que la formation par instance Spot et des expériences sur une grande variété de types de modèles et de cas d'utilisation.
-
-
Types de données : recherchez un modèle par type de données (par ex., Vision, Texte, Tabulaire, Audio, Génération de texte). Sélectionnez Explore All Models (Explorer tous les modèles) pour afficher tous les modèles disponibles.
-
ML tasks (Tâches de ML) : recherchez un modèle par type de problème [par ex., Image Classification, Image Embedding, Object Detection ou Text Generation (Classification d'images, Intégration d'images, Détection d'objets ou Génération de texte)]. Sélectionnez Explore All Models (Explorer tous les modèles) pour afficher tous les modèles disponibles.
-
Ordinateurs portables : trouvez des exemples de blocs-notes qui utilisent les fonctionnalités de l' SageMaker IA dans différents types de modèles et scénarios d'utilisation. Sélectionnez Explore All Notebooks (Explorer tous les blocs-notes) pour afficher tous les exemples de blocs-notes disponibles.
-
Frameworks — Trouvez un modèle par framework (par exemple PyTorch TensorFlow, Hugging Face).
Gérer JumpStart dans Studio Classic
Dans le menu principal du panneau de gauche, accédez à SageMaker JumpStart, puis choisissez Launched JumpStart assets pour répertorier les solutions actuellement lancées, les modèles de terminaux déployés et les tâches de formation créées avec JumpStart.
Rubriques
