Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Utilisation de l'état de la carte en mode distribué pour des charges de travail parallèles à grande échelle dans Step Functions
Gestion de l'état et transformation des données
Découvrez comment transmettre des données entre états avec des variables et transformer des données avec JSONata.
Avec Step Functions, vous pouvez orchestrer des charges de travail parallèles à grande échelle pour effectuer des tâches telles que le traitement à la demande de données semi-structurées. Ces charges de travail parallèles vous permettent de traiter simultanément des sources de données à grande échelle stockées dans Amazon S3. Par exemple, vous pouvez traiter un seul fichier JSON ou CSV contenant de grandes quantités de données. Vous pouvez également traiter un grand nombre d'objets Amazon S3.
Pour configurer une charge de travail parallèle à grande échelle dans vos flux de travail, incluez un Map état en mode distribué. L'état de la carte traite les éléments d'un jeu de données simultanément. Un Map état défini sur Distribué est appelé état de carte distribuée. En mode distribué, l'Mapétat autorise un traitement à haute simultanéité. En mode distribué, l'MapÉtat traite les éléments de l'ensemble de données par itérations appelées exécutions de flux de travail secondaires. Vous pouvez spécifier le nombre d'exécutions de flux de travail enfants qui peuvent être exécutées en parallèle. Chaque exécution de flux de travail enfant possède son propre historique d'exécution distinct de celui du flux de travail parent. Si vous ne le spécifiez pas, Step Functions exécute 10 000 workflows enfants parallèles en parallèle.
L'illustration suivante explique comment configurer des charges de travail parallèles à grande échelle dans vos flux de travail.
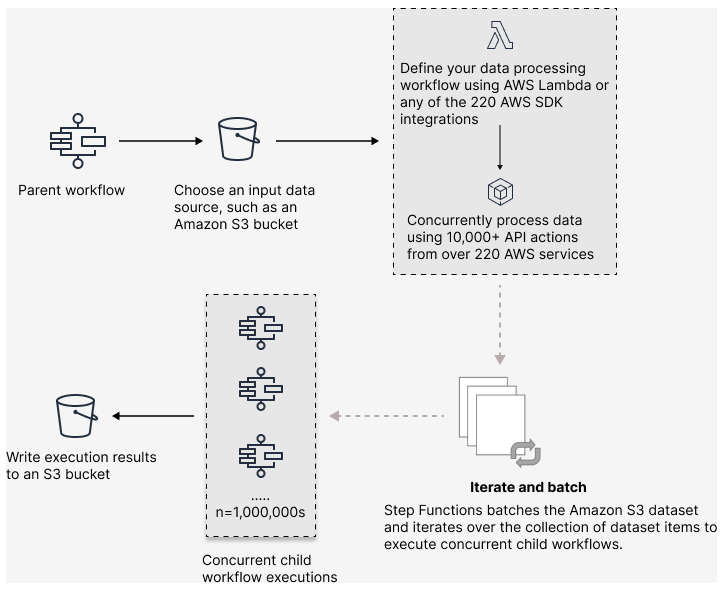
Apprenez dans un atelier
Découvrez comment les technologies sans serveur telles que Step Functions et Lambda peuvent simplifier la gestion et le dimensionnement, décharger des tâches indifférenciées et relever les défis du traitement distribué des données à grande échelle. En cours de route, vous travaillerez avec une carte distribuée pour un traitement à haute simultanéité. L'atelier présente également les meilleures pratiques pour optimiser vos flux de travail, ainsi que des cas d'utilisation pratiques pour le traitement des réclamations, l'analyse des vulnérabilités et la simulation de Monte Carlo.
Atelier : Traitement de données à grande échelle avec Step Functions
Dans cette rubrique
Termes clés
- Mode distribué
-
Mode de traitement de l'état de la carte. Dans ce mode, chaque itération de l'
Mapétat s'exécute comme une exécution de flux de travail secondaire qui permet une simultanéité élevée. Chaque exécution de flux de travail enfant possède son propre historique d'exécution, distinct de l'historique d'exécution du flux de travail parent. Ce mode prend en charge la lecture des entrées provenant de sources de données Amazon S3 à grande échelle. - État de la carte distribuée
-
État de la carte défini sur Mode de traitement distribué.
- Flux de travail cartographique
Ensemble d'étapes exécutées par un
MapÉtat.- Flux de travail parent
-
Un flux de travail qui contient un ou plusieurs états de cartes distribuées.
- Exécution du workflow pour enfants
-
Une itération de l'état de la carte distribuée. L'exécution d'un flux de travail enfant possède son propre historique d'exécution, distinct de l'historique d'exécution du flux de travail parent.
- Map Run
-
Lorsque vous exécutez un
Mapétat en mode distribué, Step Functions crée une ressource Map Run. Une exécution de carte fait référence à un ensemble d'exécutions de flux de travail enfants lancées par un état de carte distribuée, ainsi qu'aux paramètres d'exécution qui contrôlent ces exécutions. Step Functions attribue un Amazon Resource Name (ARN) à votre Map Run. Vous pouvez examiner un Map Run dans la console Step Functions. Vous pouvez également appeler l'actionDescribeMapRunAPI.Les exécutions du flux de travail par des enfants d'un Map Run émettent des métriques vers CloudWatch ;. Ces métriques porteront un ARN State Machine étiqueté au format suivant :
arn:partition:states:region:account:stateMachine:stateMachineName/MapRunLabel or UUIDPour de plus amples informations, veuillez consulter Affichage des séries de cartes.
Exemple de définition de l'état d'une carte distribuée (JSONPath)
Utilisez l'Mapétat en mode distribué lorsque vous devez orchestrer des charges de travail parallèles à grande échelle répondant à une combinaison des conditions suivantes :
La taille de votre ensemble de données dépasse 256 KiB.
L'historique des événements d'exécution du flux de travail dépasserait 25 000 entrées.
Vous avez besoin d'une simultanéité de plus de 40 itérations simultanées.
L'exemple de définition d'état de carte distribuée suivant spécifie l'ensemble de données sous la forme d'un fichier CSV stocké dans un compartiment Amazon S3. Elle spécifie également une fonction Lambda qui traite les données de chaque ligne du fichier CSV. Comme cet exemple utilise un fichier CSV, il indique également l'emplacement des en-têtes de colonne CSV. Pour voir la définition complète de la machine à états de cet exemple, consultez le didacticiel Copier des données CSV à grande échelle à l'aide d'une carte distribuée.
{
"Map": {
"Type": "Map",
"ItemReader": {
"ReaderConfig": {
"InputType": "CSV",
"CSVHeaderLocation": "FIRST_ROW"
},
"Resource": "arn:aws:states:::s3:getObject",
"Parameters": {
"Bucket": "amzn-s3-demo-bucket",
"Key": "csv-dataset/ratings.csv"
}
},
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "DISTRIBUTED",
"ExecutionType": "EXPRESS"
},
"StartAt": "LambdaTask",
"States": {
"LambdaTask": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"Payload.$": "$",
"FunctionName": "arn:aws:lambda:us-east-2:account-id:function:processCSVData"
},
"End": true
}
}
},
"Label": "Map",
"End": true,
"ResultWriter": {
"Resource": "arn:aws:states:::s3:putObject",
"Parameters": {
"Bucket": "amzn-s3-demo-destination-bucket",
"Prefix": "csvProcessJobs"
}
}
}
}Autorisations pour exécuter une carte distribuée
Lorsque vous incluez un état de carte distribuée dans vos flux de travail, Step Functions a besoin des autorisations appropriées pour permettre au rôle de machine à états d'invoquer l'action d'StartExecutionAPI pour l'état de carte distribuée.
L'exemple de politique IAM suivant accorde le minimum de privilèges requis à votre rôle de machine d'état pour exécuter l'état de carte distribuée.
Note
Assurez-vous de stateMachineNamearn:aws:states:.region:account-id:stateMachine:mystateMachine
-
{ "Version":"2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "states:StartExecution" ], "Resource": [ "arn:aws:states:us-east-1:123456789012:stateMachine:myStateMachineName" ] }, { "Effect": "Allow", "Action": [ "states:DescribeExecution" ], "Resource": "arn:aws:states:us-east-1:123456789012:execution:myStateMachineName:*" } ] }
En outre, vous devez vous assurer que vous disposez du minimum de privilèges nécessaires pour accéder aux AWS ressources utilisées dans l'état de la carte distribuée, telles que les buckets Amazon S3. Pour plus d'informations, consultez Politiques IAM pour l'utilisation des états cartographiques distribués.
Champs d'état de la carte distribuée
Pour utiliser l'état de la carte distribuée dans vos flux de travail, spécifiez un ou plusieurs de ces champs. Vous spécifiez ces champs en plus des champs d'état courants.
Type(Obligatoire)-
Définit le type d'état, tel que
Map. ItemProcessor(Obligatoire)-
Contient les objets JSON suivants qui spécifient le mode et la définition de traitement de
Mapl'état.-
ProcessorConfig— Objet JSON qui spécifie le mode de traitement des éléments, avec les sous-champs suivants :-
Mode— ParamétréDISTRIBUTEDpour utiliser l'Mapétat en mode distribué.Avertissement
Le mode distribué est pris en charge dans les flux de travail standard, mais pas dans les flux de travail Express.
-
ExecutionType— Spécifie le type d'exécution du flux de travail cartographique : STANDARD ou EXPRESS. Vous devez fournir ce champ si vous l'avez spécifiéDISTRIBUTEDpour leModesous-champ. Pour plus d'informations sur les types de flux de travail, consultezChoix du type de flux de travail dans Step Functions.
-
StartAt— Spécifie une chaîne qui indique le premier état d'un flux de travail. Cette chaîne distingue les majuscules et minuscules et doit correspondre au nom de l'un des objets d'état. Cet état s'exécute d'abord pour chaque élément de l'ensemble de données. Toute entrée d'exécution que vous fournissez à l'Mapétat passe d'abord à l'StartAtétat.States— Objet JSON contenant un ensemble d'états séparés par des virgules. Dans cet objet, vous définissez leMap workflow.
-
ItemReader-
Spécifie un ensemble de données et son emplacement. L'
MapÉtat reçoit ses données d'entrée de l'ensemble de données spécifié.En mode distribué, vous pouvez utiliser soit une charge utile JSON transmise depuis un état précédent, soit une source de données Amazon S3 à grande échelle comme ensemble de données. Pour de plus amples informations, veuillez consulter ItemReader (Carte).
Items(Facultatif, JSONata uniquement)-
Un tableau JSON, un objet JSON ou une JSONata expression qui doit être évaluée en tableau ou en objet.
ItemsPath(Facultatif, JSONPath uniquement)-
Spécifie un chemin de référence à l'aide de la JsonPath
syntaxe permettant de sélectionner le nœud JSON contenant un tableau d'éléments ou un objet avec des paires clé-valeur dans l'entrée d'état. En mode distribué, vous ne spécifiez ce champ que lorsque vous utilisez un tableau ou un objet JSON d'une étape précédente comme entrée d'état. Pour de plus amples informations, veuillez consulter ItemsPath (Carte, JSONPath uniquement).
ItemSelector(Facultatif, JSONPath uniquement)-
Remplace les valeurs des éléments individuels de l'ensemble de données avant qu'elles ne soient transmises à chaque itération
Mapd'état.Dans ce champ, vous spécifiez une entrée JSON valide contenant une collection de paires clé-valeur. Ces paires peuvent être soit des valeurs statiques que vous définissez dans la définition de votre machine à états, soit des valeurs sélectionnées à partir de l'entrée d'état à l'aide d'un chemin, soit des valeurs accessibles depuis l'objet de contexte. Pour de plus amples informations, veuillez consulter ItemSelector (Carte).
ItemBatcher(facultatif)-
Spécifie de traiter les éléments du jeu de données par lots. Chaque exécution du flux de travail enfant reçoit ensuite un lot de ces éléments en entrée. Pour de plus amples informations, veuillez consulter ItemBatcher (Carte).
MaxConcurrency(facultatif)-
Spécifie le nombre d'exécutions de flux de travail enfants qui peuvent être exécutées en parallèle. L'interpréteur n'autorise que le nombre spécifié d'exécutions parallèles de flux de travail enfants. Si vous ne spécifiez pas de valeur de simultanéité ou si vous la définissez sur zéro, Step Functions ne limite pas la simultanéité et exécute 10 000 exécutions parallèles de flux de travail enfants. Dans JSONata les états, vous pouvez spécifier une JSONata expression dont la valeur est un entier.
Note
Bien que vous puissiez spécifier une limite de simultanéité plus élevée pour les exécutions de flux de travail secondaires parallèles, nous vous recommandons de ne pas dépasser la capacité d'un AWS service en aval, tel queAWS Lambda.
MaxConcurrencyPath(Facultatif, JSONPath uniquement)-
Si vous souhaitez fournir une valeur de simultanéité maximale de manière dynamique à partir de l'entrée d'état à l'aide d'un chemin de référence, utilisez
MaxConcurrencyPath. Une fois résolu, le chemin de référence doit sélectionner un champ dont la valeur est un entier non négatif.Note
Un
Mapétat ne peut pas inclure à la foisMaxConcurrencyetMaxConcurrencyPath. ToleratedFailurePercentage(facultatif)-
Définit le pourcentage d'objets ayant échoué à tolérer lors d'une exécution cartographique. Le Map Run échoue automatiquement s'il dépasse ce pourcentage. Step Functions calcule le pourcentage d'éléments ayant échoué en divisant le nombre total d'éléments défaillants ou ayant dépassé le délai imparti par le nombre total d'éléments. Vous devez spécifier une valeur comprise entre zéro et 100. Pour de plus amples informations, veuillez consulter Définition de seuils de défaillance pour les états des cartes distribuées dans Step Functions.
Dans JSONata les états, vous pouvez spécifier une JSONata expression dont la valeur est un entier.
ToleratedFailurePercentagePath(Facultatif, JSONPath uniquement)-
Si vous souhaitez fournir une valeur de pourcentage de défaillance tolérée de manière dynamique à partir de l'entrée d'état en utilisant un chemin de référence, utilisez
ToleratedFailurePercentagePath. Une fois résolu, le chemin de référence doit sélectionner un champ dont la valeur est comprise entre zéro et 100. ToleratedFailureCount(facultatif)-
Définit le nombre d'objets ayant échoué à tolérer lors d'une exécution de carte. Le Map Run échoue automatiquement s'il dépasse ce nombre. Pour de plus amples informations, veuillez consulter Définition de seuils de défaillance pour les états des cartes distribuées dans Step Functions.
Dans JSONata les états, vous pouvez spécifier une JSONata expression dont la valeur est un entier.
ToleratedFailureCountPath(Facultatif, JSONPath uniquement)-
Si vous souhaitez fournir une valeur de nombre de défaillances tolérées de manière dynamique à partir de l'entrée d'état en utilisant un chemin de référence, utilisez
ToleratedFailureCountPath. Une fois résolu, le chemin de référence doit sélectionner un champ dont la valeur est un entier non négatif. Label(facultatif)-
Chaîne qui identifie un
Mapétat de manière unique. Pour chaque Map Run, Step Functions ajoute l'étiquette à l'ARN Map Run. Voici un exemple d'ARN Map Run avec une étiquette personnalisée nomméedemoLabel:arn:aws:states:region:account-id:mapRun:demoWorkflow/demoLabel:3c39a231-69bb-3d89-8607-9e124eddbb0bSi vous ne spécifiez aucune étiquette, Step Functions génère automatiquement une étiquette unique.
Note
Les étiquettes ne peuvent pas dépasser 40 caractères, doivent être uniques au sein d'une définition de machine à états et ne peuvent contenir aucun des caractères suivants :
-
Espace blanc
-
Caractères génériques ()
? * -
Caractères entre crochets (
< > { } [ ]) -
Caractères spéciaux (
: ; , \ | ^ ~ $ # % & ` ") -
Caractères de contrôle (
\\u0000-\\u001fou\\u007f-\\u009f).
Step Functions accepte les noms des machines à états, des exécutions, des activités et des étiquettes contenant des caractères non ASCII. Dans la mesure où ces caractères empêcheront Amazon CloudWatch d'enregistrer les données, nous vous recommandons de n'utiliser que des caractères ASCII afin de pouvoir suivre les métriques de Step Functions.
-
ResultWriter(facultatif)-
Spécifie l'emplacement Amazon S3 où Step Functions écrit tous les résultats d'exécution du flux de travail enfant.
Step Functions consolide toutes les données d'exécution du flux de travail enfant, telles que les entrées et sorties d'exécution, l'ARN et le statut d'exécution. Il exporte ensuite les exécutions avec le même statut vers leurs fichiers respectifs à l'emplacement Amazon S3 spécifié. Pour de plus amples informations, veuillez consulter ResultWriter (Carte).
Si vous n'exportez pas les résultats de
Mapl'état, il renvoie un tableau de tous les résultats d'exécution du flux de travail enfant. Par exemple :[1, 2, 3, 4, 5] ResultPath(Facultatif, JSONPath uniquement)-
Spécifie l'endroit de l'entrée où placer la sortie des itérations. L'entrée est ensuite filtrée comme spécifié par le OutputPathchamp s'il est présent, avant d'être transmise comme sortie de l'état. Pour plus d'informations, consultez Traitement des entrées et des sorties.
ResultSelector(facultatif)-
Transmettez une collection de paires clé-valeur, dont les valeurs sont statiques ou sélectionnées à partir du résultat. Pour de plus amples informations, veuillez consulter ResultSelector.
Astuce
Si l'état Parallel ou Map que vous utilisez dans vos machines d'état renvoie un tableau de tableaux, vous pouvez les transformer en tableau plat avec le ResultSelector champ. Pour de plus amples informations, veuillez consulter Aplatir un tableau de tableaux.
Retry(facultatif)-
Tableau d'objets, appelés Retriers, qui définit une politique de nouvelle tentative. Une exécution utilise la politique de nouvelle tentative si l'état rencontre des erreurs d'exécution. Pour de plus amples informations, veuillez consulter Exemples de machines à états utilisant Retry et Catch.
Note
Si vous définissez des récupérateurs pour l'état de la carte distribuée, la politique de nouvelles tentatives s'applique à toutes les exécutions de flux de travail enfants lancées par l'
Mapétat. Par exemple, imaginez que votreMapÉtat a lancé trois exécutions de flux de travail secondaires, dont une échoue. Lorsque l'échec se produit, l'exécution utilise leRetrychamp, s'il est défini, pour l'Mapétat. La politique de nouvelle tentative s'applique à toutes les exécutions de flux de travail secondaires et pas seulement à celles qui ont échoué. Si une ou plusieurs exécutions de flux de travail enfants échouent, le Map Run échoue.Lorsque vous réessayez un
Mapétat, il crée un nouveau Map Run. Catch(facultatif)-
Tableau d'objets, nommés Receveurs, qui définissent un état de secours. Step Functions utilise les Catchers définis dans
Catchsi l'état rencontre des erreurs d'exécution. Lorsqu'une erreur se produit, l'exécution utilise d'abord les récupérateurs définis dansRetry. Si la politique de nouvelle tentative n'est pas définie ou est épuisée, l'exécution utilise ses Catchers, s'ils sont définis. Pour plus d'informations, consultez États de secours. Output(Facultatif, JSONata uniquement)-
Utilisé pour spécifier et transformer la sortie de l'état. Lorsqu'elle est spécifiée, la valeur remplace la valeur par défaut de sortie de l'état.
Le champ de sortie accepte n'importe quelle valeur JSON (objet, tableau, chaîne, nombre, booléen, nul). Toute valeur de chaîne, y compris celles contenues dans des objets ou des tableaux, sera évaluée comme JSONata si elle était entourée de {% %} caractères.
Output accepte également directement une JSONata expression, par exemple : « Output » : « {% jsonata expression %} »
Pour de plus amples informations, veuillez consulter Transformer les données avec JSONata in Step Functions.
-
Assign(facultatif) -
Utilisé pour stocker des variables. Le
Assignchamp accepte un objet JSON avec des key/value paires qui définissent les noms des variables et leurs valeurs assignées. Toute valeur de chaîne, y compris celles contenues dans des objets ou des tableaux, sera évaluée comme JSONata si elle était entourée{% %}de caractèresPour de plus amples informations, veuillez consulter Transmission de données entre états à l'aide de variables.
Définition de seuils de défaillance pour les états des cartes distribuées dans Step Functions
Lorsque vous orchestrez des charges de travail parallèles à grande échelle, vous pouvez également définir un seuil de défaillance toléré. Cette valeur vous permet de spécifier le nombre maximum ou le pourcentage d'éléments ayant échoué comme seuil d'échec pour une exécution cartographique. Selon la valeur que vous spécifiez, votre Map Run échoue automatiquement si elle dépasse le seuil. Si vous spécifiez les deux valeurs, le flux de travail échoue lorsqu’il dépasse l’une ou l’autre des valeurs.
La spécification d'un seuil vous permet d'échouer à un certain nombre d'éléments avant que la totalité de la Map Run échoue. Step Functions renvoie une States.ExceedToleratedFailureThreshold erreur lorsque le Map Run échoue parce que le seuil spécifié est dépassé.
Note
Step Functions peut continuer à exécuter des flux de travail secondaires dans un Map Run même après le dépassement du seuil d'échec toléré, mais avant que le Map Run échoue.
Pour spécifier la valeur du seuil dans Workflow Studio, sélectionnez Définir un seuil d'échec toléré dans Configuration supplémentaire dans le champ Paramètres d'exécution.
- Pourcentage de défaillances tolérées
-
Définit le pourcentage d'éléments défaillants à tolérer. Votre Map Run échoue si cette valeur est dépassée. Step Functions calcule le pourcentage d'éléments ayant échoué en divisant le nombre total d'éléments défaillants ou ayant dépassé le délai imparti par le nombre total d'éléments. Vous devez spécifier une valeur comprise entre zéro et 100. La valeur en pourcentage par défaut est zéro, ce qui signifie que le flux de travail échoue si l'une de ses exécutions de flux de travail enfant échoue ou expire. Si vous spécifiez le pourcentage comme 100, le flux de travail n'échouera pas même si toutes les exécutions de flux de travail enfants échouent.
Vous pouvez également spécifier le pourcentage comme chemin de référence vers une paire clé-valeur existante dans l'entrée d'état de votre carte distribuée. Ce chemin doit être résolu en un entier positif compris entre 0 et 100 au moment de l'exécution. Vous spécifiez le chemin de référence dans le
ToleratedFailurePercentagePathsous-champ.Par exemple, avec les données d'entrée suivantes :
{"percentage":15}Vous pouvez spécifier le pourcentage en utilisant un chemin de référence vers cette entrée comme suit :
{ ... "Map": { "Type": "Map", ..."ToleratedFailurePercentagePath":"$.percentage"... } }Important
Vous pouvez spécifier l'un
ToleratedFailurePercentageou l'autreToleratedFailurePercentagePath, mais pas les deux dans la définition de l'état de votre carte distribuée. - Nombre de défaillances tolérées
-
Définit le nombre d'éléments défaillants à tolérer. Votre Map Run échoue si cette valeur est dépassée.
Vous pouvez également spécifier le nombre comme chemin de référence vers une paire clé-valeur existante dans l'entrée d'état de votre carte distribuée. Ce chemin doit être résolu en un entier positif au moment de l'exécution. Vous spécifiez le chemin de référence dans le
ToleratedFailureCountPathsous-champ.Par exemple, avec les données d'entrée suivantes :
{"count":10}Vous pouvez spécifier le nombre à l'aide d'un chemin de référence vers cette entrée comme suit :
{ ... "Map": { "Type": "Map", ..."ToleratedFailureCountPath":"$.count"... } }Important
Vous pouvez spécifier l'un
ToleratedFailureCountou l'autreToleratedFailureCountPath, mais pas les deux dans la définition de l'état de votre carte distribuée.
En savoir plus sur les cartes distribuées
Pour en savoir plus sur l'état des cartes distribuées, consultez les ressources suivantes :
-
Traitement des entrées et des sorties
Pour configurer l'entrée qu'un état de carte distribuée reçoit et la sortie qu'il génère, Step Functions fournit les champs suivants :
Outre ces champs, Step Functions vous permet également de définir un seuil d'échec toléré pour Distributed Map. Cette valeur vous permet de spécifier le nombre maximum ou le pourcentage d'éléments ayant échoué comme seuil d'échec pour une exécution cartographique. Pour plus d'informations sur la configuration du seuil de défaillance toléré, consultezDéfinition de seuils de défaillance pour les états des cartes distribuées dans Step Functions.
-
Utilisation de l'état de la carte distribuée
Reportez-vous aux didacticiels et exemples de projets suivants pour commencer à utiliser l'état des cartes distribuées.
-
Traitement de données par lots avec une fonction Lambda dans Step Functions
-
Traitement d'éléments individuels avec une fonction Lambda dans Step Functions
-
Exemple de projet : traitement d'un fichier CSV avec une carte distribuée
-
Exemple de projet : traiter des données dans un compartiment Amazon S3 avec Distributed Map
-
Examiner l'exécution de l'état des cartes distribuées
La console Step Functions fournit une page Map Run Details, qui affiche toutes les informations relatives à l'exécution d'un état de carte distribuée. Pour plus d'informations sur la façon d'examiner les informations affichées sur cette page, consultezAffichage des séries de cartes.
