Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Terminologie et concepts relatifs à Amazon Kinesis Data Streams
Avant de commencer à utiliser Amazon Kinesis Data Streams, découvrez son architecture et sa terminologie.
Rubriques
Passez en revue l'architecture de haut niveau de Kinesis Data Streams
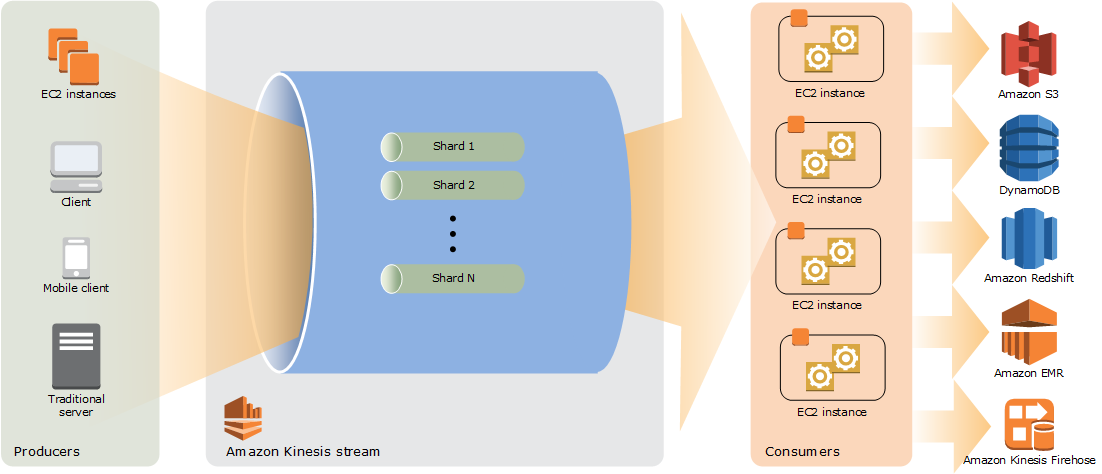
Le diagramme suivant illustre l'architecture de haut niveau de Kinesis Data Streams. Les applications producteur envoient (push) continuellement des données à Kinesis Data Streams et les applications consommateur traitent ces données en temps réel. Les consommateurs (tels qu'une application personnalisée exécutée sur Amazon EC2 ou un flux de diffusion Amazon Data Firehose) peuvent stocker leurs résultats à l'aide d'un AWS service tel qu'Amazon DynamoDB, Amazon Redshift ou Amazon S3.
Familiarisez-vous avec la terminologie de Kinesis Data Streams
Flux de données Kinesis
Un flux de données Kinesis est un ensemble de partitions. Chaque partition comporte une séquence d'enregistrements de données. Chaque enregistrement de données dispose d'un numéro de séquence attribué par Kinesis Data Streams.
Enregistrement de données
Un enregistrement de données est l'unité de données stockée dans un flux de données Kinesis. Les enregistrements de données sont composés d'un numéro de séquence, d'une clé de partition et d'un blob de données, qui est une séquence immuable d'octets. Une fois que vous avez stocké les données dans l'enregistrement, Kinesis Data Streams n'inspecte pas, n'interprète pas ou ne modifie absolument pas le blob. Un blob de données peut atteindre jusqu'à 1 Mo.
Mode de capacité
Un mode de capacité de flux de données détermine comment la capacité est gérée et comment l'utilisation de votre flux de données vous est facturée. Actuellement, dans Kinesis Data Streams, vous pouvez choisir entre un mode à la demande et un mode provisionné pour vos flux de données. Pour de plus amples informations, veuillez consulter Choisissez le mode de capacité du flux de données.
En mode à la demande, Kinesis Data Streams gère automatiquement les partitions afin de fournir le débit nécessaire. Vous n'êtes facturé que pour le débit réel que vous utilisez et Kinesis Data Streams répond automatiquement aux besoins de débit de vos charges de travail à mesure qu'elles augmentent ou diminuent. Pour de plus amples informations, veuillez consulter Fonctionnalités et cas d'utilisation du mode à la demande.
En mode provisionné, vous devez spécifier le nombre de partitions du flux de données. La capacité totale d'un flux de données est la somme des capacités de ses partitions. Vous pouvez augmenter ou diminuer le nombre de partitions dans un flux de données selon vos besoins et le nombre de partitions vous est facturé selon un taux horaire. Pour de plus amples informations, veuillez consulter Fonctionnalités et cas d'utilisation du mode provisionné.
Période de conservation
La période de conservation correspond à la durée pendant laquelle les enregistrements de données sont accessibles après avoir été ajoutés au flux. La période de conservation d'un flux a une valeur par défaut de 24 heures après la création. Vous pouvez augmenter la période de rétention jusqu'à 8760 heures (365 jours) en utilisant l'IncreaseStreamRetentionPeriodopération, et la réduire à un minimum de 24 heures en utilisant l'DecreaseStreamRetentionPeriodopération. Des frais supplémentaires s'appliquent pour les flux dont la période de conservation définie est supérieure à 24 heures. Pour en savoir plus, consultez la Tarification Amazon Kinesis Data Streams
Producer
Les producteurs placent des enregistrements dans Amazon Kinesis Data Streams. Par exemple, un serveur Web qui envoie des données de journal dans un flux est un producteur.
Consommateur
Les consommateurs récupèrent les enregistrements depuis Amazon Kinesis Data Streams et les traitent. Ces applications consommateur s'appellent Application Amazon Kinesis Data Streams.
Application Amazon Kinesis Data Streams
Une application Amazon Kinesis Data Streams utilise un flux qui s'exécute généralement sur un parc EC2 d'instances.
Il existe deux types de consommateurs que vous pouvez développer : les consommateurs de diffusion partagée et les consommateurs de diffusion améliorée. Pour en savoir plus sur les différences entre ces deux types, et pour savoir comment créer chaque type de consommateur, consultez Lire les données d'Amazon Kinesis Data Streams.
La sortie d'une application Kinesis Data Streams peut servir d'entrée à un autre flux, ce qui vous permet de créer des topologies complexes qui traitent des données en temps réel. Une application peut également envoyer des données à divers autres AWS services. Il peut y avoir plusieurs applications pour un seul flux, et chaque application peut utiliser des données du flux indépendamment et simultanément.
Partition
Une partition est une séquence d'enregistrements de données appartenant à un flux et identifiée de manière unique. Un flux se compose d'une ou plusieurs partitions, chacune fournissant une unité de capacité fixe. Chaque partition peut prendre en charge jusqu'à 5 transactions par seconde pour les lectures, jusqu'à un taux total de lecture de données maximal de 2 Mo par seconde et jusqu'à 1 000 enregistrements par seconde pour les écritures, jusqu'à un taux d'écriture de données total maximal de 1 Mo par seconde (clés de partition incluses). La capacité de données de votre flux dépend du nombre de partitions que vous spécifiez pour le flux. La capacité totale du flux est la somme des capacités de ses shards.
Si votre débit de données augmente, vous pouvez augmenter ou diminuer le nombre de partitions allouées à votre flux. Pour de plus amples informations, veuillez consulter Revisionner un stream.
Clé de partition
Une clé de partition sert à grouper les données par partition dans un flux. Kinesis Data Streams sépare les enregistrements de données appartenant à un flux en plusieurs partitions. Il utilise la clé de partition associée à chaque enregistrement de données pour déterminer à quelle partition un enregistrement de données spécifique appartient. Les clés de partition sont des chaînes Unicode, avec une longueur maximale de 256 caractères pour chaque clé. Une fonction de MD5 hachage est utilisée pour mapper les clés de partition à des valeurs entières de 128 bits et pour mapper les enregistrements de données associés aux partitions en utilisant les plages de clés de hachage des partitions. Lorsqu'une application place des données dans un flux, elle doit spécifier une clé de partition.
Numéro de séquence
Chaque enregistrement de données a un numéro de séquence qui est unique par clé de partition au sein de son groupe de données. Kinesis Data Streams attribue le numéro de séquence une fois que vous avez écrit dans le flux avec client.putRecords ou client.putRecord. Les numéros de séquence correspondant à une même clé de partition deviennent généralement de plus en plus longs au fil du temps. Plus le délai entre les demandes d'écriture est élevé, plus les numéros de séquence sont longs.
Note
Les numéros de séquence ne peuvent pas servir d'index aux ensembles de données d'un même flux. Pour séparer logiquement les ensembles de données, utilisez des clés de partition ou créez un flux distinct pour chaque ensemble de données.
Bibliothèque cliente Kinesis
La bibliothèque cliente Kinesis est compilée dans votre application pour permettre une consommation tolérante aux pannes des données issues du flux. La bibliothèque cliente Kinesis s'assure que pour chaque partition, un processeur d'enregistrement est en cours d'exécution et traite cette partition. La bibliothèque simplifie également la lecture des données dans le flux. La bibliothèque cliente Kinesis utilise les tables Amazon DynamoDB pour stocker les métadonnées relatives à la consommation de données. Il crée trois tables par application qui traite des données. Pour de plus amples informations, veuillez consulter Utiliser la bibliothèque cliente Kinesis.
Nom de l'application
Le nom d'une application Amazon Kinesis Data Streams identifie l'application. Chacune de vos applications doit avoir un nom unique correspondant au AWS compte et à la région utilisés par l'application. Ce nom est utilisé comme nom pour la table de contrôle dans Amazon DynamoDB et comme espace de noms pour les métriques Amazon. CloudWatch
Chiffrement côté serveur
Amazon Kinesis Data Streams peut chiffrer automatiquement des données sensibles lorsqu'un producteur les saisit dans un flux. Kinesis Data Streams utilise des clés principales AWS KMS pour le chiffrement. Pour de plus amples informations, veuillez consulter Protection des données dans Amazon Kinesis Data Streams.
Note
Pour lire un flux chiffré ou écrire sur un flux chiffré, les applications producteur et consommateur doivent disposer d'autorisations pour accéder à la clé principale. Pour plus d'informations sur l'octroi d'autorisations à des applications producteur et consommateur, consultez Autorisations d'utilisation des clés KMS générées par l'utilisateur.
Note
L'utilisation du chiffrement côté serveur entraîne des coûts AWS Key Management Service ()AWS KMS. Pour plus d'informations, consultez Tarification de AWS Key Management Service
