Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Création d’un modèle de langue personnalisé
Avant de créer votre modèle de langue personnalisé, vous devez effectuer les opérations suivantes :
-
Préparez vos données. Les données doivent être enregistrées au format texte brut et ne peuvent contenir aucun caractère spécial.
-
Téléchargez vos données dans un Amazon S3 bucket. Il est recommandé de créer des dossiers distincts pour les données d’entraînement et de réglage.
-
Assurez-vous d' Amazon Transcribe avoir accès à votre Amazon S3 compartiment. Vous devez spécifier un IAM rôle doté d'autorisations d'accès pour utiliser vos données.
Préparation de vos données
Vous pouvez compiler toutes vos données dans un seul fichier ou les enregistrer dans plusieurs fichiers. Notez que si vous choisissez d’inclure des données de réglage, elles doivent être enregistrées dans un fichier distinct de celui de vos données d’entraînement.
Peu importe le nombre de fichiers texte que vous utilisez pour vos données d’entraînement ou de réglage. Le téléchargement d’un fichier de 100 000 mots produit le même résultat que le téléchargement de 10 fichiers de 10 000 mots. Préparez vos données texte de la manière qui vous convient le mieux.
Assurez-vous que tous vos fichiers de données répondent aux critères suivants :
-
Ils sont tous rédigés dans la même langue que le modèle que vous souhaitez créer. Par exemple, si vous souhaitez créer un modèle de langue personnalisé qui transcrit le son en anglais américain (
en-US), toutes vos données texte doivent être en anglais américain. -
Ils sont au format texte brut avec encodage UTF-8.
-
Ils ne contiennent pas de caractères spéciaux ni de mise en forme, tels que des balises HTML.
-
Ils représentent un total combiné maximal de 2 Go pour les données d’entraînement et de 200 Mo pour les données de réglage.
Si l’un de ces critères n’est pas satisfait, votre modèle échoue.
Téléchargement de vos données
Avant de télécharger vos données, créez un nouveau dossier pour vos données d’entraînement. Si vous utilisez des données de réglage, créez un autre dossier distinct.
URIs Pour vos seaux, cela pourrait ressembler à ceci :
-
s3://amzn-s3-demo-bucket/my-model-training-data/ -
s3://amzn-s3-demo-bucket/my-model-tuning-data/
Téléchargez vos données d’entraînement et de réglage dans les compartiments appropriés.
Vous pourrez ajouter des données supplémentaires à ces compartiments ultérieurement. Toutefois, si c’est le cas, vous devez recréer votre modèle avec les nouvelles données. Les modèles existants ne peuvent pas être mis à jour avec de nouvelles données.
Autorisation d’accès à vos données
Pour créer un modèle de langage personnalisé, vous devez spécifier un IAM rôle autorisé à accéder à votre Amazon S3 bucket. Si vous ne possédez pas encore de rôle ayant accès au Amazon S3 compartiment dans lequel vous avez placé vos données d'entraînement, vous devez en créer un. Une fois que vous avez créé un rôle, vous pouvez attacher une politique pour lui accorder des autorisations. N’attachez pas de politique à un utilisateur.
Pour obtenir des exemples de politiques, consultez Amazon Transcribe exemples de politiques basées sur l'identité.
Pour savoir comment créer une nouvelle IAM identité, consultez IAM Identités (utilisateurs, groupes d'utilisateurs et rôles).
Pour en savoir plus sur les politiques, consultez les sections suivantes :
Création de votre modèle de langue personnalisé
Lorsque vous créez votre modèle de langue personnalisé, vous devez choisir un modèle de base. Il existe deux options de modèle de base :
-
NarrowBand: utilisez cette option pour l’audio dont la fréquence d’échantillonnage est inférieure à 16 000 Hz. Ce type de modèle est généralement utilisé pour les conversations téléphoniques enregistrées à 8 000 Hz. -
WideBand: utilisez cette option pour l’audio dont la fréquence d’échantillonnage est supérieure ou égale à 16 000 Hz.
Vous pouvez créer des modèles de langage personnalisés à l'aide du AWS Management Console AWS CLI, ou AWS SDKs. ; consultez les exemples suivants :
-
Connectez-vous à la AWS Management Console
. -
Dans le volet de navigation, choisissez Modèle de langue personnalisé. La page Modèles de langue personnalisés s’ouvre et vous permet de consulter les modèles de langue personnalisés existants ou d’en entraîner un nouveau.
-
Pour entraîner un nouveau modèle, sélectionnez Entraîner un modèle.

Vous accédez alors à la page Entraîner un modèle. Ajoutez un nom, spécifiez la langue et choisissez le modèle de base que vous souhaitez pour votre modèle. Ajoutez ensuite le chemin pour votre entraînement et éventuellement vos données de réglage. Vous devez inclure un IAM rôle autorisé à accéder à vos données.
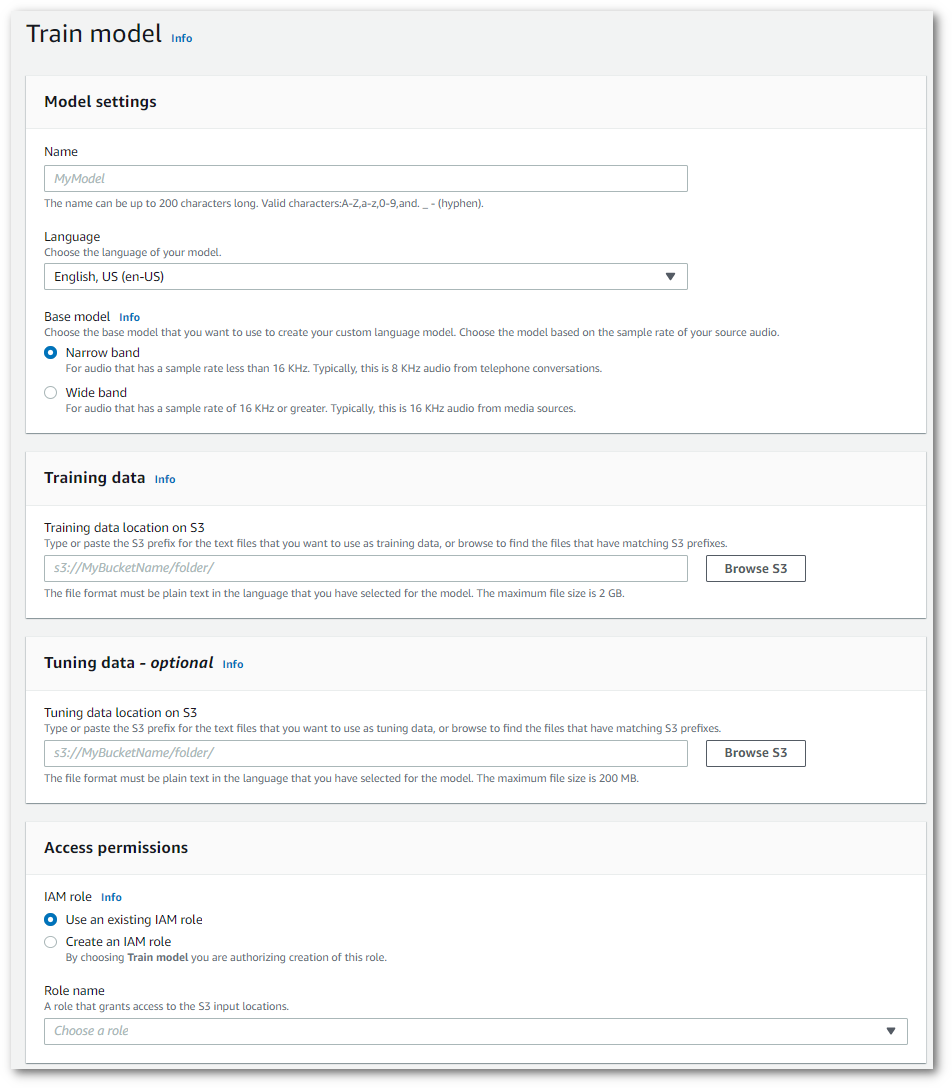
-
Une fois que vous avez rempli tous les champs, sélectionnez Entraîner un modèle en bas de la page.
Cet exemple utilise la create-language-modelCreateLanguageModel et LanguageModel.
aws transcribe create-language-model \ --base-model-nameNarrowBand\ --model-namemy-first-language-model\ --input-data-config S3Uri=s3://amzn-s3-demo-bucket/my-clm-training-data/,TuningDataS3Uri=s3://amzn-s3-demo-bucket/my-clm-tuning-data/,DataAccessRoleArn=arn:aws:iam::111122223333:role/ExampleRole\ --language-codeen-US
Voici un autre exemple d'utilisation de la create-language-model
aws transcribe create-language-model \ --cli-input-json file://filepath/my-first-language-model.json
Le fichier my-first-language-model.json contient le corps de requête suivant.
{ "BaseModelName": "NarrowBand", "ModelName": "my-first-language-model", "InputDataConfig": { "S3Uri": "s3://amzn-s3-demo-bucket/my-clm-training-data/", "TuningDataS3Uri"="s3://amzn-s3-demo-bucket/my-clm-tuning-data/", "DataAccessRoleArn": "arn:aws:iam::111122223333:role/ExampleRole" }, "LanguageCode": "en-US" }
Cet exemple utilise le AWS SDK pour Python (Boto3) pour créer un CLM à l'aide de la méthode create_language_modelCreateLanguageModel et LanguageModel.
Pour des exemples supplémentaires utilisant le AWS SDKs, notamment des exemples spécifiques aux fonctionnalités, des scénarios et des exemples multiservices, reportez-vous au chapitre. Exemples de code pour Amazon Transcribe à l'aide de AWS SDKs
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') model_name = 'my-first-language-model', transcribe.create_language_model( LanguageCode = 'en-US', BaseModelName = 'NarrowBand', ModelName = model_name, InputDataConfig = { 'S3Uri':'s3://amzn-s3-demo-bucket/my-clm-training-data/', 'TuningDataS3Uri':'s3://amzn-s3-demo-bucket/my-clm-tuning-data/', 'DataAccessRoleArn':'arn:aws:iam::111122223333:role/ExampleRole' } ) while True: status = transcribe.get_language_model(ModelName = model_name) if status['LanguageModel']['ModelStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Mise à jour de votre modèle de langue personnalisé
Amazon Transcribe met continuellement à jour les modèles de base disponibles pour les modèles linguistiques personnalisés. Pour bénéficier de ces mises à jour, nous vous recommandons d’entraîner de nouveaux modèles de langue personnalisés tous les 6 à 12 mois.
Pour savoir si votre modèle de langage personnalisé utilise le dernier modèle de base, exécutez une DescribeLanguageModeldemande à l'aide du SDK AWS CLI ou d'un AWS SDK, puis recherchez le UpgradeAvailability champ dans votre réponse.
Si UpgradeAvailability a la valeur true, votre modèle n’exécute pas la dernière version du modèle de base. Pour utiliser le dernier modèle de base dans un modèle de langue personnalisé, vous devez créer un nouveau modèle de langue personnalisé. Les modèles de langue personnalisés ne peuvent pas être mis à niveau.
