Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Menggunakan switchover atau failover di Amazon Aurora Global Database
Fitur Aurora Global Database memberikan lebih banyak perlindungan kontinuitas bisnis dan pemulihan bencana (BCDR) daripada ketersediaan standar tinggi yang disediakan oleh cluster Aurora DB dalam satu. Wilayah AWS Dengan menggunakan Aurora Global Database, Anda dapat merencanakan pemulihan yang lebih cepat dari bencana Regional yang jarang dan tidak direncanakan atau menyelesaikan pemadaman tingkat layanan dengan cepat.
Anda dapat berkonsultasi dengan panduan dan prosedur berikut untuk merencanakan, menguji, dan menerapkan strategi BCDR Anda menggunakan fitur Aurora Global Database.
Topik
Perencanaan untuk kelangsungan bisnis dan pemulihan bencana
Untuk merencanakan kelangsungan bisnis Anda dan strategi pemulihan bencana, sangat membantu untuk memahami terminologi industri berikut dan bagaimana istilah-istilah tersebut berhubungan dengan fitur Aurora Global Database.
Pemulihan dari bencana biasanya didorong oleh dua tujuan bisnis berikut:
-
Sasaran waktu pemulihan (RTO)—Waktu yang diperlukan sistem untuk kembali ke status kerja aktif setelah terjadinya bencana atau pemadaman layanan. Dengan kata lain, RTO mengukur waktu henti operasional. Untuk Aurora Global Database, RTO bisa dalam urutan menit.
-
Sasaran titik pemulihan (RPO)—Jumlah data yang dapat hilang (diukur berdasarkan waktu) setelah terjadinya bencana atau pemadaman layanan. Kehilangan data tersebut biasanya disebabkan oleh keterlambatan replikasi asinkron. Untuk basis data global Aurora, RPO biasanya diukur dalam hitungan detik. Dengan basis data global berbasis Aurora PostgreSQL, Anda dapat menggunakan parameter
rds.global_db_rpountuk mengatur dan melacak batas atas RPO, tetapi melakukannya dapat memengaruhi pemrosesan transaksi pada simpul penulis di klaster primer. Untuk informasi selengkapnya, lihat Mengelola RPOs database global berbasis Aurora PostgreSQL.
Melakukan switchover atau failover dengan Aurora Global Database melibatkan mempromosikan cluster DB sekunder menjadi cluster DB utama. Istilah "pemadaman regional" sering kali digunakan untuk mendeskripsikan berbagai skenario kegagalan. Skenario terburuk dapat berupa pemadaman luas karena peristiwa bencana yang memengaruhi wilayah seluas ratusan mil persegi. Namun, kebanyakan pemadaman sudah jauh lebih terlokalisasi, dengan hanya memengaruhi sebagian kecil subset layanan cloud atau sistem pelanggan. Pertimbangkan cakupan pemadaman secara menyeluruh untuk memastikan bahwa failover lintas Wilayah merupakan solusi yang tepat dan untuk memilih metode failover yang sesuai dengan situasi tersebut. Penggunaan pendekatan failover atau switchover bergantung pada skenario pemadaman tertentu:
-
Failover—Gunakan pendekatan ini untuk melakukan pemulihan dari pemadaman yang tidak direncanakan. Dengan pendekatan ini, Anda melakukan failover lintas Wilayah ke salah satu klaster DB sekunder dalam basis data global Aurora Anda. RPO untuk pendekatan ini biasanya merupakan nilai bukan nol yang diukur dalam hitungan detik. Jumlah kehilangan data tergantung pada kelambatan replikasi database global Aurora Wilayah AWS pada saat kegagalan. Untuk mempelajari selengkapnya, lihat Memulihkan basis data global Amazon Aurora dari pemadaman yang tidak direncanakan.
-
Switchover — Operasi ini sebelumnya disebut “failover terencana terkelola”. Gunakan pendekatan ini untuk skenario terkontrol, seperti pemeliharaan operasional dan prosedur operasional terencana lainnya di mana semua cluster Aurora dan layanan lain yang berinteraksi dengan mereka berada dalam keadaan sehat. Karena fitur ini menyinkronkan klaster DB sekunder dengan primer sebelum membuat perubahan lain, RPO adalah 0 (tidak ada kehilangan data). Untuk mempelajari selengkapnya, lihat Melakukan switchover untuk basis data global Amazon Aurora.
catatan
Sebelum Anda dapat melakukan switchover atau failover ke cluster Aurora DB sekunder tanpa kepala, Anda harus menambahkan instance DB ke dalamnya. Untuk informasi selengkapnya tentang klaster DB headless, lihat Membuat klaster DB Aurora tanpa kepala di Wilayah sekunder.
Melakukan switchover untuk basis data global Amazon Aurora
catatan
Switchover sebelumnya disebut failover terencana terkelola.
Dengan menggunakan switchover, Anda dapat mengubah Wilayah cluster utama Anda secara rutin. Pendekatan ini ditujukan untuk skenario yang terkontrol, seperti pemeliharaan operasional dan prosedur operasional terencana lainnya.
Terdapat tiga kasus umum untuk penggunaan switchover.
-
Untuk persyaratan "rotasi regional" yang diberlakukan pada industri tertentu. Misalnya, peraturan layanan keuangan mungkin menginginkan sistem tier-0 untuk beralih ke Wilayah yang berbeda selama beberapa bulan untuk memastikan prosedur pemulihan bencana dilaksanakan secara teratur.
-
Untuk aplikasi Multi-region follow-the-sun "”. Misalnya, suatu bisnis mungkin ingin menyediakan penulisan dengan latensi lebih rendah di berbagai Wilayah berdasarkan jam kerja di zona waktu yang berbeda.
-
Sebagai zero-data-loss metode untuk gagal kembali ke Wilayah primer asli setelah failover.
catatan
Switchovers dirancang untuk digunakan pada database global Aurora di mana semua cluster Aurora dan layanan lain yang berinteraksi dengan mereka berada dalam keadaan sehat. Untuk pulih dari pemadaman yang tak terduga, ikuti prosedur yang sesuai di Memulihkan basis data global Amazon Aurora dari pemadaman yang tidak direncanakan.
Anda dapat melakukan switchover lintas wilayah terkelola dengan Aurora Global Database hanya jika cluster DB primer dan sekunder memiliki versi mesin mayor dan minor yang sama. Tergantung pada versi mesin dan mesin, level patch mungkin harus identik atau level patch bisa berbeda. Untuk daftar mesin dan versi mesin yang memungkinkan operasi ini antara cluster primer dan sekunder dengan tingkat patch yang berbeda, lihatKompatibilitas tingkat patch untuk switchover dan failover lintas wilayah yang dikelola. Sebelum Anda memulai switchover, periksa versi mesin di klaster global untuk memastikan versi mesin tersebut mendukung switchover lintas Wilayah terkelola, lalu tingkatkan jika diperlukan.
Selama peralihan, Aurora membuat cluster di Wilayah sekunder pilihan Anda menjadi cluster utama Anda. Mekanisme peralihan mempertahankan topologi replikasi database global Anda yang ada: masih memiliki jumlah cluster Aurora yang sama di Wilayah yang sama. Sebelum Aurora memulai proses peralihan, ia menunggu cluster Region sekunder target disinkronkan sepenuhnya dengan cluster Region primer. Kemudian, cluster DB di Region primer menjadi hanya-baca. Cluster sekunder yang dipilih mempromosikan salah satu node hanya-baca ke status penulis penuh, yang memungkinkan cluster sekunder untuk mengambil peran cluster primer. Karena cluster sekunder target disinkronkan dengan primer pada awal proses, primer baru melanjutkan operasi untuk database global Aurora tanpa kehilangan data apa pun. Basis data Anda tidak tersedia untuk sementara selama klaster primer dan klaster sekunder yang dipilih mengambil peran barunya masing-masing.
catatan
Untuk mengelola slot replikasi untuk Aurora PostgreSQL setelah melakukan peralihan, lihat. Mengelola slot logis untuk Aurora PostgreSQL
Untuk mengoptimalkan ketersediaan aplikasi, sebaiknya lakukan hal berikut sebelum menggunakan fitur ini:
-
Lakukan operasi ini di luar jam sibuk atau pada waktu lainnya saat operasi penulisan ke klaster DB primer tidak banyak.
-
Periksa waktu keterlambatan untuk semua klaster DB Aurora sekunder dalam basis data global Aurora. Untuk semua database global berbasis Aurora PostgreSQL dan untuk database global berbasis Aurora MySQL yang dimulai dengan versi mesin 3.04.0 dan lebih tinggi atau 2.12.0 dan lebih tinggi, gunakan Amazon untuk melihat metrik untuk semua cluster DB sekunder. CloudWatch
AuroraGlobalDBRPOLagUntuk basis data global berbasis Aurora MySQL versi minor yang lebih rendah, lihat metrikAuroraGlobalDBReplicationLag. Metrik ini menunjukkan seberapa terlambatnya (dalam milidetik) replikasi ke klaster sekunder dibandingkan ke klaster DB primer. Nilai ini berbanding lurus dengan waktu yang diperlukan Aurora untuk menyelesaikan switchover. Karena itu, semakin besar nilai keterlambatan, semakin lama durasi switchover. Saat Anda memeriksa metrik ini, lakukan dari cluster utama saat ini.Untuk informasi selengkapnya tentang CloudWatch metrik untuk Aurora, lihat. Metrik tingkat klaster untuk Amazon Aurora
-
Cluster DB sekunder yang dipromosikan selama peralihan mungkin memiliki pengaturan konfigurasi yang berbeda dari cluster DB primer lama. Kami menyarankan agar Anda menjaga jenis pengaturan konfigurasi berikut konsisten di semua cluster di cluster database global Aurora Anda. Melakukannya membantu meminimalkan masalah kinerja, ketidakcocokan beban kerja, dan perilaku anomali lainnya setelah peralihan.
-
Konfigurasikan grup parameter cluster Aurora DB untuk primer baru, jika perlu — Saat Anda mempromosikan cluster DB sekunder untuk mengambil alih peran utama, grup parameter dari sekunder mungkin dikonfigurasi secara berbeda dari yang primer. Jika demikian, ubah grup parameter klaster DB sekunder yang dipromosikan agar sesuai dengan pengaturan klaster primer Anda. Untuk mempelajari caranya, lihat Memodifikasi parameter basis data global Aurora.
-
Konfigurasikan alat dan opsi pemantauan, seperti Amazon CloudWatch Events dan alarm — Konfigurasikan cluster DB yang dipromosikan dengan kemampuan logging, alarm, dan sebagainya yang sama sesuai kebutuhan untuk database global. Seperti grup parameter, konfigurasi untuk fitur ini tidak diwariskan dari klaster primer selama proses switchover berlangsung. Beberapa CloudWatch metrik, seperti replikasi lag, hanya tersedia untuk Wilayah sekunder. Karena itu, switchover akan mengubah cara Anda melihat metrik tersebut dan mengatur alarmnya, serta mengharuskan adanya perubahan pada dasbor yang ditentukan sebelumnya. Untuk informasi lebih lanjut tentang cluster dan pemantauan Aurora DB, lihat. Memantau Amazon Aurora dengan Amazon CloudWatch
-
Konfigurasikan integrasi dengan AWS layanan lain — Jika database global Aurora Anda terintegrasi AWS dengan layanan, AWS Secrets Manager seperti, AWS Identity and Access Management Amazon S3, AWS Lambda dan, pastikan untuk mengonfigurasi integrasi Anda dengan layanan ini sesuai kebutuhan. Untuk informasi selengkapnya tentang cara mengintegrasi basis data global Aurora dengan IAM, Amazon S3, dan Lambda, lihat Menggunakan database global Amazon Aurora dengan layanan lain AWS. Untuk mempelajari Secrets Manager selengkapnya, lihat Cara mengotomatiskan replikasi rahasia secara AWS Secrets Manager keseluruhan
. Wilayah AWS
-
Jika Anda menggunakan titik akhir penulis Aurora Global Database, Anda tidak perlu mengubah pengaturan koneksi di aplikasi Anda. Verifikasi bahwa perubahan DNS telah menyebar dan Anda dapat menghubungkan dan melakukan operasi tulis pada cluster utama yang baru. Kemudian Anda dapat melanjutkan operasi penuh aplikasi Anda.
Misalkan koneksi aplikasi Anda menggunakan titik akhir cluster dari cluster primer lama, bukan titik akhir penulis global. Dalam hal ini, pastikan untuk mengubah pengaturan koneksi aplikasi Anda untuk menggunakan titik akhir cluster cluster utama yang baru. Jika Anda menyetujui nama yang disediakan saat membuat basis data global Aurora, Anda dapat mengubah titik akhir dengan menghapus -ro dari string titik akhir klaster yang dipromosikan dalam aplikasi Anda. Sebagai contoh, titik akhir klaster sekunder my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com menjadi my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com ketika klaster tersebut dipromosikan menjadi klaster primer.
Jika Anda menggunakan RDS Proxy, pastikan untuk mengalihkan operasi penulisan aplikasi Anda ke read/write titik akhir proxy yang sesuai yang terkait dengan cluster utama baru. Titik akhir proxy ini mungkin merupakan titik akhir default atau titik akhir kustom read/write . Untuk mengetahui informasi selengkapnya, lihat Cara kerja titik akhir Proksi RDS dengan basis data global.
Anda dapat melakukan peralihan Aurora Global Database menggunakan, API Konsol Manajemen AWS AWS CLI, atau RDS.
Cara melakukan switchover pada basis data global Aurora
Masuk ke Konsol Manajemen AWS dan buka konsol Amazon RDS di https://console.aws.amazon.com/rds/
. -
Pilih Database dan temukan database global Aurora tempat Anda ingin melakukan peralihan.
-
Pilih Alihkan atau lakukan failover basis data global dari menu Tindakan.
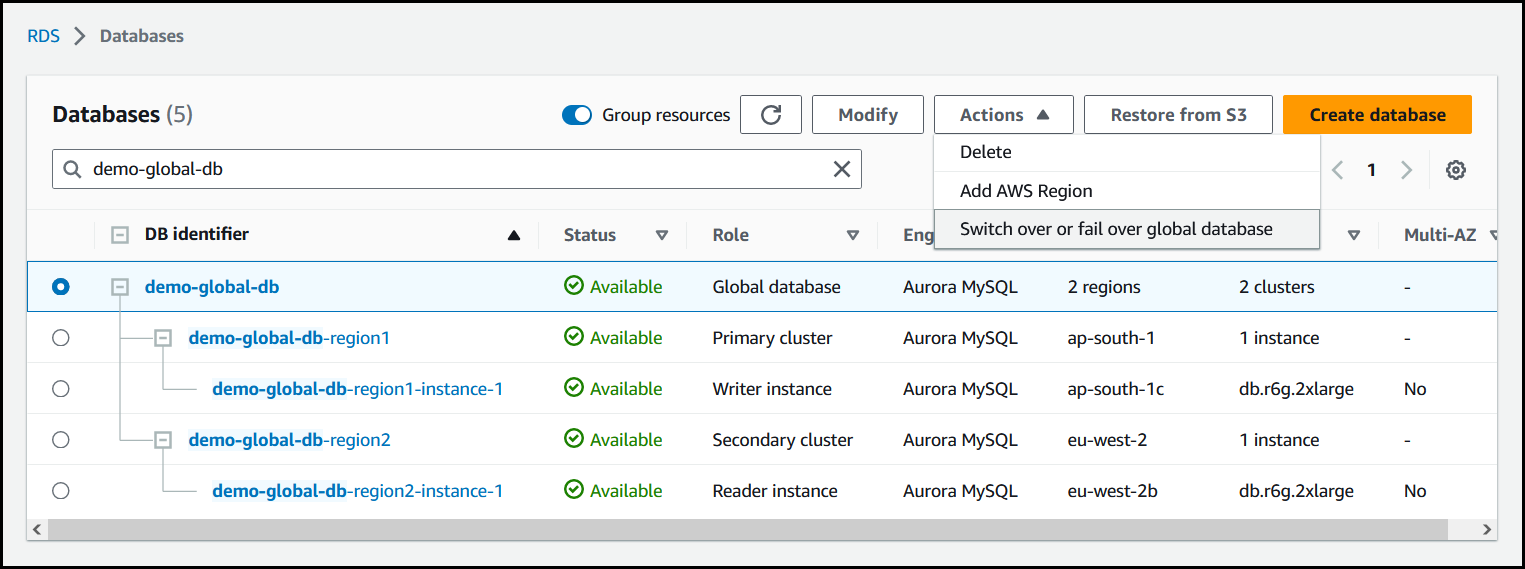
-
Pilih Switchover.
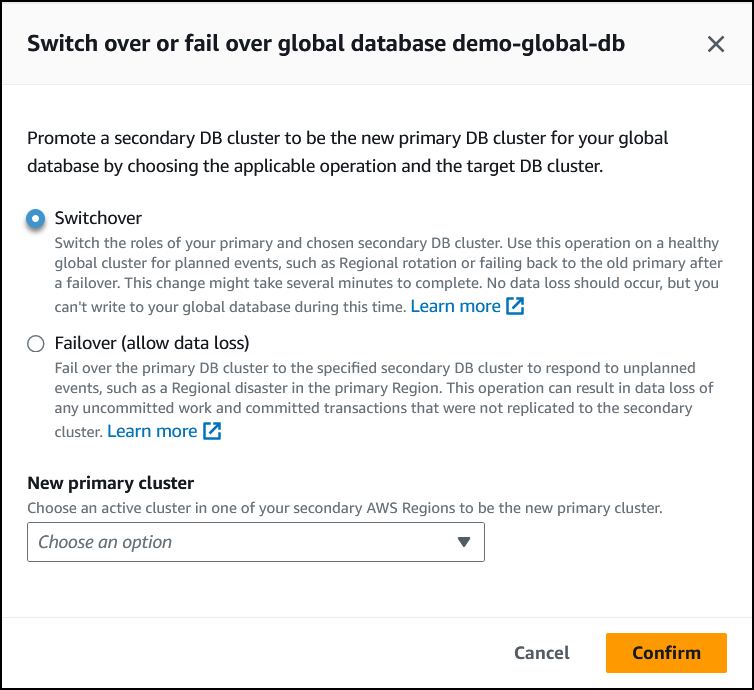
-
Untuk Klaster primer baru, pilih klaster aktif di salah satu Wilayah AWS sekunder untuk dijadikan klaster primer baru.
-
Pilih Konfirmasi.
Setelah switchover selesai, Anda dapat melihat klaster DB Aurora dan perannya saat ini di daftar Basis Data, sebagaimana ditunjukkan pada gambar berikut.
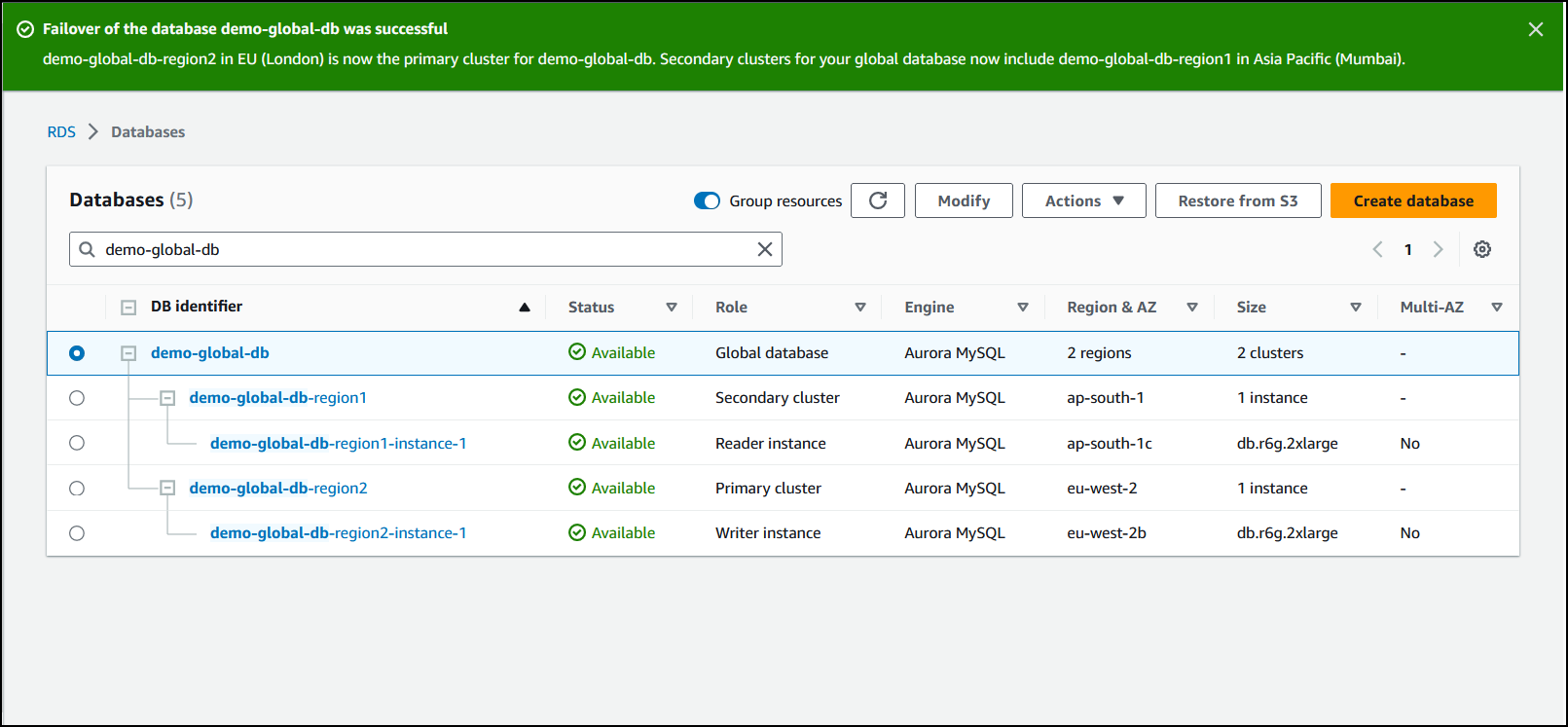
Untuk melakukan switchover pada basis data global Aurora:
Gunakan perintah switchover-global-cluster CLI untuk melakukan peralihan untuk Aurora Global Database. Dengan perintah tersebut, loloskan nilai untuk parameter berikut.
-
--region— Tentukan Wilayah AWS di mana cluster DB utama dari database global Aurora berjalan. -
--global-cluster-identifier—Tentukan nama basis data global Aurora. -
--target-db-cluster-identifier—Tentukan Amazon Resource Name (ARN) untuk klaster DB Aurora yang ingin Anda promosikan menjadi klaster primer basis data global Aurora.
Untuk Linux, macOS, atau Unix:
aws rds --regionregion_of_primary\ switchover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote
Untuk Windows:
aws rds --regionregion_of_primary^ switchover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote
Untuk melakukan peralihan untuk Aurora Global Database, jalankan operasi API. SwitchoverGlobalCluster
Memulihkan basis data global Amazon Aurora dari pemadaman yang tidak direncanakan
Pada kesempatan langka, database global Aurora Anda mungkin mengalami pemadaman tak terduga pada awalnya. Wilayah AWS Jika hal ini terjadi, klaster DB Aurora primer dan simpul penulisnya tidak akan tersedia, dan replikasi antara klaster DB primer dan sekunder akan terhenti. Untuk meminimalkan waktu henti (RTO) dan kehilangan data (RPO), Anda dapat segera melakukan failover lintas Wilayah.
Aurora Global Database memiliki dua metode failover yang dapat Anda gunakan dalam situasi pemulihan bencana:
-
Failover terkelola—Metode ini direkomendasikan untuk pemulihan bencana. Jika Anda menggunakan metode ini, Aurora akan secara otomatis menambahkan kembali Wilayah primer yang lama ke basis data global sebagai Wilayah sekunder saat sudah tersedia lagi. Dengan begitu, topologi asli klaster global akan dipertahankan. Untuk mempelajari cara menggunakan metode ini, lihat Melakukan failover terkelola untuk basis data global Aurora.
-
Failover manual—Metode alternatif ini dapat digunakan ketika failover terkelola bukan merupakan pilihan, misalnya, ketika Wilayah primer dan sekunder Anda menjalankan versi mesin yang tidak kompatibel. Untuk mempelajari cara menggunakan metode ini, lihat Melakukan failover manual untuk basis data global Aurora.
penting
Kedua metode failover tersebut dapat mengakibatkan hilangnya data transaksi tulis yang tidak direplikasi ke tujuan sekunder yang dipilih sebelum peristiwa failover terjadi. Namun, proses pemulihan yang mempromosikan instans DB pada klaster DB sekunder pilihan menjadi instans DB penulis primer akan memastikan bahwa data berada dalam kondisi yang konsisten secara transaksional. Kegagalan juga rentan terhadap masalah otak terbelah.
Melakukan failover terkelola untuk basis data global Aurora
Pendekatan ini ditujukan untuk kelangsungan bisnis saat terjadi bencana alam Regional yang riil atau pemadaman tingkat layanan secara menyeluruh.
Selama failover terkelola, klaster sekunder di Region sekunder yang Anda pilih menjadi cluster primer baru. Klaster sekunder yang dipilih mempromosikan salah satu simpul hanya-bacanya ke status penulis penuh. Langkah ini memungkinkan klaster untuk mengambil peran sebagai klaster primer. Basis data Anda tidak akan tersedia untuk sementara saat klaster ini mengambil peran barunya. Segera setelah Wilayah primer lama itu sehat dan tersedia kembali, Aurora secara otomatis menambahkannya kembali ke cluster global sebagai Wilayah sekunder. Dengan demikian, topologi replikasi database global Aurora Anda yang ada dipertahankan.
catatan
Untuk mengelola slot replikasi untuk Aurora PostgreSQL setelah melakukan failover, lihat. Mengelola slot logis untuk Aurora PostgreSQL
catatan
Anda dapat melakukan failover lintas wilayah terkelola dengan Aurora Global Database hanya jika cluster DB primer dan sekunder memiliki versi mesin mayor dan minor yang sama. Tergantung pada versi mesin dan mesin, level patch mungkin harus identik atau level patch bisa berbeda. Untuk daftar mesin dan versi mesin yang memungkinkan operasi ini antara cluster primer dan sekunder dengan tingkat patch yang berbeda, lihatKompatibilitas tingkat patch untuk switchover dan failover lintas wilayah yang dikelola. Sebelum Anda memulai failover, periksa versi mesin di cluster global Anda untuk memastikan bahwa mereka mendukung peralihan lintas wilayah terkelola, dan tingkatkan jika diperlukan. Jika versi mesin Anda memerlukan level patch yang identik tetapi menjalankan level patch yang berbeda, Anda dapat melakukan failover secara manual dengan mengikuti langkah-langkah masukMelakukan failover manual untuk basis data global Aurora.
Failover terkelola tidak menunggu data disinkronkan antara Wilayah sekunder yang dipilih dan Wilayah primer saat ini. Karena Aurora Global Database mereplikasi data secara asinkron, mungkin saja tidak semua transaksi direplikasi ke AWS Wilayah sekunder yang dipilih sebelum dipromosikan untuk menerima kemampuan penuh. read/write
Untuk memastikan data dalam keadaan konsisten, Aurora membuat volume penyimpanan baru untuk Wilayah primer lama setelah pulih. Sebelum membuat volume penyimpanan baru di AWS Wilayah, Aurora mencoba mengambil snapshot dari volume penyimpanan lama pada titik kegagalan. Dengan begitu, Anda dapat memulihkan snapshot dan memulihkan data yang hilang darinya. Jika operasi ini berhasil, Aurora menempatkan snapshot ini yang dinamai rds:unplanned-global-failover- di bagian snapshot. Konsol Manajemen AWS Anda juga dapat menggunakan name-of-old-primary-DB-cluster-timestampdescribe-db-cluster-snapshots AWS CLI perintah atau operasi DescribeDBClusterSnapshots API untuk melihat detail snapshot.
Saat Anda memulai failover terkelola, Aurora juga mencoba menghentikan lalu lintas tulis melalui lapisan penyimpanan Aurora yang sangat tersedia. Kami menyebut mekanisme ini sebagai “tulis pagar”. Jika proses berhasil, Aurora memancarkan Acara RDS yang memberi tahu Anda bahwa penulisan dihentikan. Jika terjadi beberapa kegagalan AZ di suatu Wilayah, ada kemungkinan bahwa proses pagar tulis tidak berhasil tepat waktu. Dalam hal ini, Aurora memancarkan acara RDS yang memberi tahu Anda bahwa proses untuk menghentikan penulisan habis waktunya. Jika cluster primer lama dapat dijangkau di jaringan, Aurora mencatat peristiwa ini di sana. Jika tidak, Aurora merekam peristiwa di cluster primer baru. Untuk mempelajari lebih lanjut tentang peristiwa ini, lihatPeristiwa klaster DB. Karena penulisan pagar adalah upaya terbaik, ada kemungkinan tulisan dapat diterima sebentar di Wilayah primer lama, menyebabkan masalah otak terbelah.
Kami menyarankan Anda menyelesaikan tugas-tugas berikut sebelum Anda melakukan failover dengan Aurora Global Database. Melakukannya meminimalkan kemungkinan masalah otak terbelah, atau memulihkan data yang tidak direplikasi dari snapshot cluster primer lama.
-
Untuk mencegah penulisan dikirim ke cluster utama Aurora Global Database, gunakan aplikasi secara offline.
-
Pastikan bahwa aplikasi apa pun yang terhubung ke cluster DB primer menggunakan titik akhir penulis global. Titik akhir ini memiliki nilai yang tetap sama bahkan ketika Wilayah baru menjadi cluster utama karena peralihan atau failover. Aurora menerapkan perlindungan tambahan untuk meminimalkan kemungkinan kehilangan data untuk operasi tulis yang diajukan melalui titik akhir global. Untuk informasi lebih lanjut tentang titik akhir penulis global, lihatMenghubungkan ke Amazon Aurora Global Database.
-
Jika Anda menggunakan titik akhir penulis global dan nilai DNS cache aplikasi atau lapisan jaringan Anda, kurangi time-to-live (TTL) cache DNS Anda ke nilai rendah seperti 5 detik. Dengan begitu, aplikasi Anda dengan cepat mendaftarkan perubahan DNS dengan titik akhir penulis global. Meskipun Aurora mencoba untuk memblokir tulisan di Wilayah primer lama, tindakan tersebut tidak dijamin akan berhasil. Mengurangi durasi cache DNS semakin mengurangi kemungkinan masalah otak terbelah. Sebagai alternatif, Anda dapat memeriksa peristiwa RDS yang memberi tahu Anda ketika Aurora mengamati perubahan DNS untuk titik akhir penulis global. Dengan begitu, Anda dapat memvalidasi bahwa aplikasi Anda juga mendaftarkan perubahan DNS sebelum memulai ulang lalu lintas tulis aplikasi Anda.
-
Periksa waktu jeda untuk semua cluster Aurora DB sekunder di Aurora Global Database. Memilih Wilayah sekunder dengan keterlambatan replikasi minimum dapat meminimalkan kehilangan data dari Wilayah primer yang mengalami kegagalan.
Untuk semua versi database global berbasis Aurora PostgreSQL, dan untuk database global berbasis Aurora MySQL yang dimulai dengan versi mesin 3.04.0 dan lebih tinggi atau 2.12.0 dan lebih tinggi, gunakan Amazon untuk melihat metrik untuk semua cluster DB sekunder. CloudWatch
AuroraGlobalDBRPOLagUntuk basis data global berbasis Aurora MySQL versi minor yang lebih rendah, lihat metrikAuroraGlobalDBReplicationLag. Metrik ini menunjukkan seberapa terlambatnya (dalam milidetik) replikasi ke klaster sekunder dibandingkan ke klaster DB primer.Untuk informasi selengkapnya tentang CloudWatch metrik untuk Aurora, lihat. Metrik tingkat klaster untuk Amazon Aurora
Selama failover terkelola, klaster DB sekunder yang dipilih dipromosikan ke peran barunya sebagai klaster primer. Namun, klaster ini tidak mewarisi berbagai opsi konfigurasi klaster DB primer. Ketidakcocokan dalam konfigurasi dapat menyebabkan masalah performa, inkompatibilitas beban kerja, dan perilaku anomali lainnya. Untuk mencegah masalah tersebut, sebaiknya atasi perbedaan di antara klaster basis data global Aurora untuk konfigurasi berikut:
-
Konfigurasikan grup parameter cluster Aurora DB untuk primer baru, jika perlu — Anda dapat mengonfigurasi grup parameter cluster Aurora DB Anda secara independen untuk setiap cluster Aurora di Database Global Aurora Anda. Karena itu, ketika Anda mempromosikan klaster DB sekunder untuk mengambil alih peran sebagai klaster primer, grup parameter dari klaster sekunder mungkin memiliki konfigurasi yang berbeda dengan klaster primer. Jika demikian, ubah grup parameter klaster DB sekunder yang dipromosikan agar sesuai dengan pengaturan klaster primer Anda. Untuk mempelajari caranya, lihat Memodifikasi parameter basis data global Aurora.
-
Konfigurasikan alat dan opsi pemantauan, seperti Amazon CloudWatch Events dan alarm — Konfigurasikan cluster DB yang dipromosikan dengan kemampuan logging, alarm, dan sebagainya yang sama sesuai kebutuhan untuk database global. Seperti grup parameter, konfigurasi untuk fitur ini tidak diwariskan dari klaster primer selama proses failover berlangsung. Beberapa CloudWatch metrik, seperti replikasi lag, hanya tersedia untuk Wilayah sekunder. Karena itu, failover akan mengubah cara Anda melihat metrik tersebut dan mengatur alarmnya, serta mengharuskan adanya perubahan pada dasbor yang ditentukan sebelumnya. Untuk informasi selengkapnya tentang pemantauan klaster Aurora DB, lihat. Memantau Amazon Aurora dengan Amazon CloudWatch
-
Konfigurasikan integrasi dengan AWS layanan lain — Jika Database Global Aurora Anda terintegrasi dengan layanan AWS lain, AWS Secrets Manager seperti, AWS Identity and Access Management Amazon S3, AWS Lambda dan, Anda perlu memastikan bahwa ini dikonfigurasi sesuai kebutuhan untuk akses dari Wilayah sekunder mana pun. Untuk informasi selengkapnya tentang cara mengintegrasi basis data global Aurora dengan IAM, Amazon S3, dan Lambda, lihat Menggunakan database global Amazon Aurora dengan layanan lain AWS. Untuk mempelajari Secrets Manager selengkapnya, lihat Cara mengotomatiskan replikasi rahasia secara AWS Secrets Manager keseluruhan
. Wilayah AWS
Biasanya, klaster sekunder yang dipilih akan mengasumsikan peran primer dalam beberapa menit. Segera setelah instans DB penulis Region utama baru tersedia, Anda dapat menghubungkan aplikasi Anda ke sana dan melanjutkan beban kerja Anda. Setelah mempromosikan klaster primer yang baru, Aurora secara otomatis membangun ulang semua klaster Wilayah sekunder tambahan.
Karena basis data global Aurora menggunakan replikasi asinkron, keterlambatan replikasi di masing-masing Wilayah sekunder dapat bervariasi. Aurora membangun kembali Wilayah sekunder ini untuk memiliki point-in-time data yang sama persis dengan cluster Region primer yang baru. Durasi penyelesaian tugas pembangunan ulang dapat memerlukan waktu beberapa menit hingga beberapa jam, bergantung pada ukuran volume penyimpanan dan jarak di antara Wilayah. Saat klaster Wilayah sekunder selesai dibuat ulang dari Wilayah primer yang baru, klaster ini menjadi tersedia untuk akses baca.
Segera setelah penulis primer baru dipromosikan dan tersedia, klaster Wilayah primer yang baru dapat menangani operasi baca dan tulis untuk basis data global Aurora.
Jika Anda menggunakan titik akhir global, Anda tidak perlu mengubah pengaturan koneksi di aplikasi Anda. Verifikasi bahwa perubahan DNS telah menyebar dan Anda dapat menghubungkan dan melakukan operasi tulis pada cluster utama yang baru. Kemudian Anda dapat melanjutkan operasi penuh aplikasi Anda.
Jika Anda tidak menggunakan titik akhir global, pastikan untuk mengubah titik akhir aplikasi Anda untuk menggunakan titik akhir cluster untuk klaster DB primer yang baru dipromosikan. Jika Anda menyetujui nama yang disediakan saat membuat basis data global Aurora, Anda dapat mengubah titik akhir dengan menghapus -ro dari string titik akhir klaster yang dipromosikan dalam aplikasi Anda.
Sebagai contoh, titik akhir klaster sekunder my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com menjadi my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com ketika klaster tersebut dipromosikan menjadi klaster primer.
Jika Anda menggunakan RDS Proxy, pastikan untuk mengalihkan operasi penulisan aplikasi Anda ke read/write titik akhir proxy yang sesuai yang terkait dengan cluster utama baru. Titik akhir proxy ini mungkin merupakan titik akhir default atau titik akhir kustom read/write . Untuk mengetahui informasi selengkapnya, lihat Cara kerja titik akhir Proksi RDS dengan basis data global.
Untuk memulihkan topologi asli klaster basis data global, Aurora memantau ketersediaan Wilayah primer yang lama. Segera setelah Wilayah tersebut normal dan tersedia kembali, Aurora secara otomatis menambahkannya kembali ke klaster global sebagai Wilayah sekunder. Sebelum membuat volume penyimpanan baru di Wilayah primer yang lama, Aurora mencoba mengambil snapshot dari volume penyimpanan lama pada titik kegagalan. Hal ini dilakukan agar Anda dapat menggunakannya untuk memulihkan setiap data yang hilang. Jika operasi ini berhasil, Aurora membuat snapshot bernama. rds:unplanned-global-failover- Anda dapat menemukan snapshot ini di bagian Snapshots di. Konsol Manajemen AWS Anda juga dapat melihat snapshot ini tercantum dalam informasi yang ditampilkan oleh operasi Deskripsikan DBCluster Snapshots API. name-of-old-primary-DB-cluster-timestamp
catatan
Snapshot dari volume penyimpanan lama adalah snapshot sistem yang tunduk pada periode retensi pencadangan yang dikonfigurasi pada klaster primer yang lama. Untuk mempertahankan snapshot ini di luar periode retensi, Anda dapat menyalin snapshot untuk disimpan sebagai snapshot manual. Untuk mempelajari selengkapnya tentang cara menyalin snapshot, termasuk harga, lihat Penyalinan snapshot cluster DB.
Setelah topologi asli dipulihkan, Anda dapat mengembalikan basis data global ke Wilayah primer asli dengan melakukan operasi switchover jika dianggap sebagai tindakan terbaik untuk bisnis dan beban kerja Anda. Untuk melakukannya, ikuti langkah-langkah yang ada di Melakukan switchover untuk basis data global Amazon Aurora.
Anda dapat melakukan failover dengan Aurora Global Database menggunakan, Konsol Manajemen AWS API, AWS CLI atau RDS.
Untuk melakukan failover terkelola pada basis data global Aurora:
Masuk ke Konsol Manajemen AWS dan buka konsol Amazon RDS di https://console.aws.amazon.com/rds/
. -
Pilih Database dan temukan database global Aurora tempat Anda ingin melakukan failover.
-
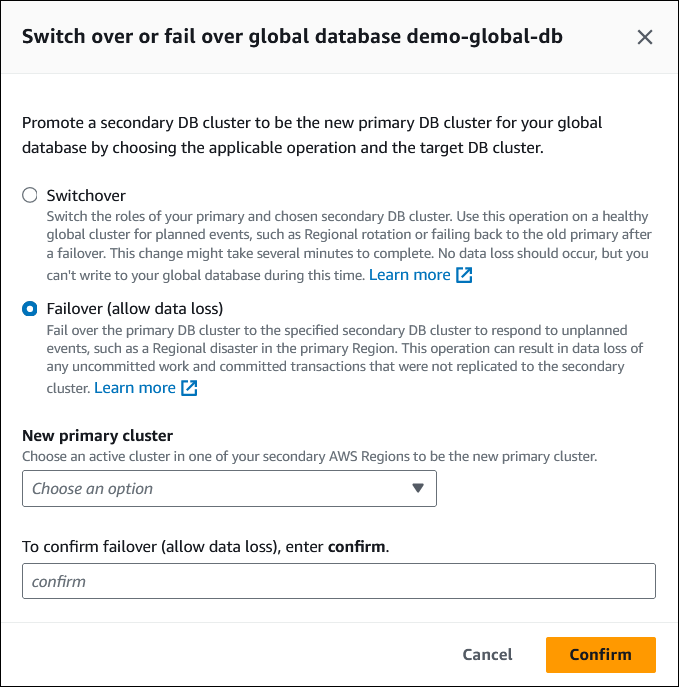
Pilih Alihkan atau lakukan failover basis data global dari menu Tindakan.
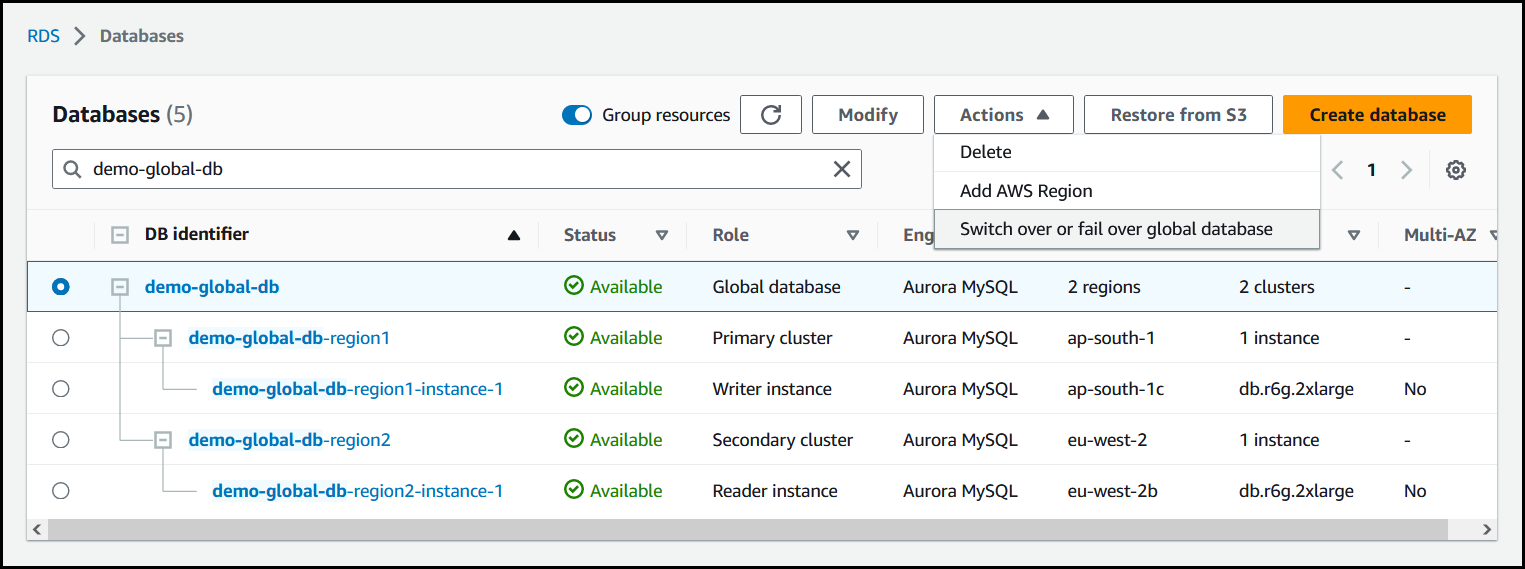
-
Pilih Failover (memungkinkan kehilangan data).
-
Untuk Klaster primer baru, pilih klaster aktif di salah satu Wilayah AWS sekunder untuk dijadikan klaster primer baru.
-
Masukkan
confirm, lalu pilih Konfirmasi.
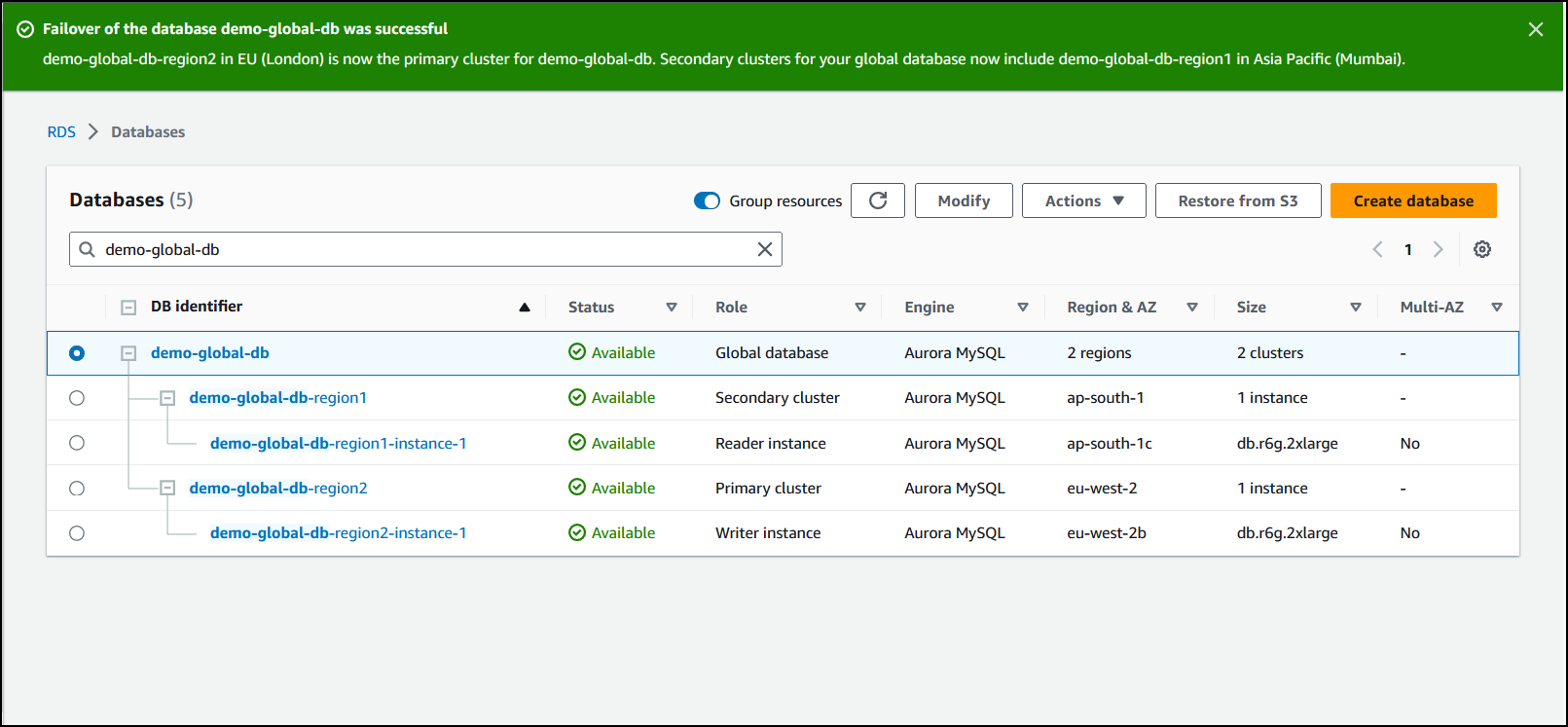
Ketika failover selesai, Anda dapat melihat cluster Aurora DB dan statusnya saat ini dalam daftar Database, seperti yang ditunjukkan pada gambar berikut.
Untuk melakukan failover terkelola pada basis data global Aurora:
Gunakan perintah failover-global-cluster CLI untuk melakukan failover dengan Aurora Global Database. Dengan perintah tersebut, loloskan nilai untuk parameter berikut.
-
--region— Tentukan Wilayah AWS di mana cluster DB sekunder yang Anda inginkan menjadi primer baru untuk database global Aurora berjalan. -
--global-cluster-identifier—Tentukan nama basis data global Aurora. -
--target-db-cluster-identifier—Tentukan Amazon Resource Name (ARN) untuk klaster DB Aurora yang ingin Anda promosikan menjadi klaster primer baru untuk basis data global Aurora. -
--allow-data-loss—Secara eksplisit jadikan tindakan ini sebagai operasi failover, bukan operasi switchover. Operasi failover dapat membuat Anda kehilangan sejumlah data jika komponen replikasi asinkron belum selesai mengirim semua data yang direplikasi ke Wilayah sekunder.
Untuk Linux, macOS, atau Unix:
aws rds --regionregion_of_selected_secondary\ failover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote\ --allow-data-loss
Untuk Windows:
aws rds --regionregion_of_selected_secondary^ failover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote^ --allow-data-loss
Untuk melakukan failover dengan Aurora Global Database, jalankan operasi API FailoverGlobalCluster.
Melakukan failover manual untuk basis data global Aurora
Dalam skenario tertentu, Anda mungkin tidak dapat menggunakan proses failover terkelola. Salah satu contohnya adalah jika klaster DB primer dan sekunder tidak menjalankan versi mesin yang kompatibel. Dalam hal ini, Anda dapat mengikuti proses manual ini untuk melakukan failover ke Wilayah sekunder target Anda.
Tip
Sebaiknya Anda memahami proses ini sebelum menggunakannya. Siapkan rencana untuk segera memulai saat pertama kali muncul tanda masalah tingkat Wilayah. Anda dapat siap mengidentifikasi Wilayah sekunder dengan kelambatan replikasi paling sedikit dengan menggunakan Amazon CloudWatch secara teratur untuk melacak waktu jeda untuk klaster sekunder. Pastikan Anda menguji rencana untuk memastikan prosedur sudah lengkap dan akurat, dan bahwa staf Anda terlatih untuk melakukan failover pemulihan bencana sebelum bencana benar-benar terjadi.
Untuk melakukan failover manual ke cluster sekunder setelah pemadaman yang tidak direncanakan di Wilayah primer
-
Berhenti mengeluarkan pernyataan DML dan operasi tulis lainnya ke klaster DB Aurora primer di Wilayah AWS saat terjadi pemadaman.
-
Identifikasi cluster Aurora DB dari sekunder Wilayah AWS untuk digunakan sebagai cluster DB primer baru. Jika Anda memiliki dua atau lebih sekunder Wilayah AWS dalam database global Aurora Anda, pilih cluster sekunder yang memiliki kelambatan replikasi paling sedikit.
-
Lepaskan klaster DB sekunder pilihan Anda dari basis data global Aurora.
Menghapus cluster DB sekunder dari database global Aurora segera menghentikan replikasi dari primer ke sekunder ini dan mempromosikannya ke cluster Aurora DB yang disediakan mandiri dengan kemampuan penuh. read/write Klaster DB Aurora sekunder lainnya yang terkait dengan klaster primer di Wilayah yang mengalami pemadaman akan tetap tersedia dan dapat menerima panggilan dari aplikasi Anda. Klaster tersebut juga mengonsumsi sumber daya. Karena Anda membuat ulang basis data global Aurora, hapus klaster DB sekunder lainnya sebelum membuat basis data global Aurora yang baru dengan mengikuti langkah-langkah berikut. Tindakan ini akan mencegah inkonsistensi data di antara klaster DB dalam basis data global Aurora (masalah split-brain).
Untuk langkah-langkah pelepasan terperinci, lihat Menghapus klaster dari basis data global Amazon Aurora.
-
Konfigurasi ulang aplikasi Anda untuk mengirim semua operasi tulis ke klaster DB Aurora yang kini berdiri sendiri ini menggunakan titik akhir barunya. Jika Anda menyetujui nama yang disediakan ketika Anda membuat basis data global Aurora, Anda dapat mengubah titik akhir dengan menghapus
-rodari string titik akhir klaster dalam aplikasi Anda.Sebagai contoh, titik akhir klaster sekunder
my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.commenjadimy-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.comsaat klaster tersebut dilepas dari basis data global Aurora.Klaster DB Aurora ini menjadi klaster primer untuk basis data global Aurora yang baru ketika Anda mulai menambahkan Wilayah ke dalamnya pada langkah berikutnya.
Jika Anda menggunakan RDS Proxy, pastikan untuk mengalihkan operasi penulisan aplikasi Anda ke read/write titik akhir proxy yang sesuai yang terkait dengan cluster utama baru. Titik akhir proxy ini mungkin merupakan titik akhir default atau titik akhir kustom read/write . Untuk mengetahui informasi selengkapnya, lihat Cara kerja titik akhir Proksi RDS dengan basis data global.
-
Tambahkan Wilayah AWS ke cluster DB. Saat Anda melakukannya, proses replikasi dari klaster primer ke klaster sekunder akan dimulai. Untuk langkah menambahkan Wilayah secara mendetail, lihat Menambahkan Wilayah AWS ke database global Amazon Aurora.
-
Tambahkan lebih banyak Wilayah AWS sesuai kebutuhan untuk membuat ulang topologi yang diperlukan untuk mendukung aplikasi Anda.
Pastikan penulisan aplikasi dikirim ke klaster DB Aurora yang benar, baik sebelum, selama, maupun sesudah membuat perubahan ini. Tindakan ini akan mencegah inkonsistensi data di antara klaster DB dalam basis data global Aurora (masalah split-brain).
Jika Anda mengonfigurasi ulang sebagai respons terhadap pemadaman di sebuah Wilayah AWS, Anda dapat menjadikannya primer lagi setelah pemadaman diselesaikan. Wilayah AWS Untuk melakukannya, Anda menambahkan yang lama Wilayah AWS ke database global baru Anda, dan kemudian menggunakan proses peralihan untuk beralih perannya. Basis data global Aurora harus menggunakan versi Aurora PostgreSQL atau Aurora MySQL yang mendukung switchover. Untuk informasi selengkapnya, lihat Melakukan switchover untuk basis data global Amazon Aurora.
Mengelola RPOs database global berbasis Aurora PostgreSQL
Dengan basis data global berbasis Aurora PostgreSQL, Anda dapat mengelola sasaran titik pemulihan (RPO) untuk basis data global Aurora menggunakan parameter rds.global_db_rpo. RPO mewakili jumlah maksimum data yang dapat hilang ketika terjadi pemadaman.
Ketika Anda mengatur RPO untuk basis data global berbasis Aurora PostgreSQL, Aurora memantau Waktu keterlambatan RPO dari semua klaster sekunder untuk memastikan bahwa setidaknya satu klaster sekunder tetap dalam jendela target RPO. Waktu keterlambatan RPO adalah salah satu metrik berbasis waktu.
RPO digunakan ketika database Anda melanjutkan operasi di baru Wilayah AWS setelah failover. Aurora mengevaluasi RPO dan waktu keterlambatan RPO untuk melakukan commit (atau memblokir) transaksi pada klaster primer sebagai berikut:
-
Menjalankan commit transaksi jika setidaknya satu klaster DB sekunder memiliki waktu keterlambatan RPO lebih rendah dari RPO.
-
Memblokir transaksi jika semua klaster DB sekunder memiliki waktu keterlambatan RPO yang lebih tinggi dari RPO. Aurora juga mencatat peristiwa ke file log PostgreSQL dan mengeluarkan peristiwa "tunggu" yang menunjukkan sesi terblokir.
Dengan kata lain, jika semua klaster sekunder berada di belakang RPO target, Aurora akan menjeda transaksi pada klaster primer hingga setidaknya satu klaster sekunder mengimbangi. Transaksi yang dijeda akan dilanjutkan dan di-commit segera setelah waktu keterlambatan dari setidaknya satu klaster DB sekunder menjadi lebih rendah dari RPO. Hasilnya adalah bahwa tidak ada transaksi yang dapat di-commit hingga RPO terpenuhi.
Parameter rds.global_db_rpo bersifat dinamis. Jika Anda memutuskan untuk tidak menghentikan semua transaksi tulis hingga keterlambatan cukup berkurang, Anda dapat meresetnya dengan cepat. Dalam kasus ini, Aurora akan menerima dan mengimplementasikan perubahan setelah beberapa saat.
penting
Dalam database global dengan hanya dua AWS Wilayah, kami sarankan untuk menjaga nilai default rds.global_db_rpo parameter di grup parameter Region sekunder. Jika tidak, melakukan failover karena hilangnya AWS Wilayah utama dapat menyebabkan Aurora menghentikan transaksi. Sebagai gantinya, tunggu hingga Aurora menyelesaikan pembangunan kembali cluster di AWS Wilayah lama yang gagal sebelum mengubah parameter ini untuk menerapkan RPO maksimum.
Jika Anda mengatur parameter ini seperti yang diuraikan di bawah ini, Anda juga dapat memantau metrik yang dihasilkannya. Anda dapat melakukannya menggunakan psql atau alat lain untuk membuat kueri klaster DB primer basis data global Aurora dan mendapatkan informasi terperinci tentang operasi basis data global berbasis Aurora PostgreSQL. Untuk mempelajari caranya, lihat Memantau basis data global berbasis Aurora PostgreSQL.
Topik
Mengatur sasaran titik pemulihan
Parameter rds.global_db_rpo mengontrol pengaturan RPO untuk basis data PostgreSQL. Parameter ini didukung oleh Aurora PostgreSQL. Nilai yang valid untuk rds.global_db_rpo berkisar dari 20 detik hingga 2.147.483.647 detik (68 tahun). Pilih nilai yang realistis untuk memenuhi kasus penggunaan dan kebutuhan bisnis Anda. Misalnya, Anda mungkin ingin mengizinkan durasi RPO hingga 10 menit, sehingga Anda menetapkan nilai ke 600.
Anda dapat menetapkan nilai ini untuk basis data global berbasis Aurora PostgreSQL menggunakan Konsol Manajemen AWS, AWS CLI, atau API RDS.
Cara mengatur RPO
Masuk ke Konsol Manajemen AWS dan buka konsol Amazon RDS di https://console.aws.amazon.com/rds/
. -
Pilih klaster primer basis data global Aurora, lalu buka tab Konfigurasi untuk menemukan grup parameter klaster DB. Sebagai contoh, grup parameter default untuk klaster DB primer yang menjalankan Aurora PostgreSQL 11.7 adalah
default.aurora-postgresql11.Grup parameter tidak dapat diedit secara langsung. Sebaliknya, lakukan hal berikut:
-
Buat grup parameter klaster DB kustom menggunakan grup parameter default yang sesuai sebagai titik awal. Misalnya, buat grup parameter klaster DB kustom berdasarkan
default.aurora-postgresql11. -
Pada grup parameter klaster DB kustom, tetapkan nilai parameter rds.global_db_rpo agar sesuai dengan kasus penggunaan Anda. Nilai yang valid berkisar dari 20 detik hingga nilai integer maksimum sebesar 2.147.483.647 (68 tahun).
-
Terapkan grup parameter klaster DB yang telah dimodifikasi ke klaster DB Aurora Anda.
-
Untuk informasi selengkapnya, lihat Memodifikasi parameter dalam grup parameter cluster DB di Amazon Aurora.
Untuk mengatur rds.global_db_rpo parameter, gunakan perintah modify-db-cluster-parameter-group CLI. Dalam perintahnya, tentukan nama grup parameter klaster primer dan nilai untuk parameter RPO.
Contoh berikut mengatur RPO ke 600 detik (10 menit) untuk grup parameter klaster DB primer, my_custom_global_parameter_group.
Untuk Linux, macOS, atau Unix:
aws rds modify-db-cluster-parameter-group \ --db-cluster-parameter-group-namemy_custom_global_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
Untuk Windows:
aws rds modify-db-cluster-parameter-group ^ --db-cluster-parameter-group-namemy_custom_global_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
Untuk memodifikasi rds.global_db_rpo parameter, gunakan operasi Amazon RDS Modify DBCluster ParameterGroup API.
Melihat sasaran titik pemulihan
Sasaran titik pemulihan (RPO) dari basis data global disimpan di parameter rds.global_db_rpo untuk setiap klaster DB. Anda dapat terhubung ke titik akhir klaster sekunder yang ingin Anda lihat dan menggunakan psql untuk membuat kueri instans bagi nilai ini.
show rds.global_db_rpo;db-name=>
Jika parameter ini belum diatur, kueri akan menampilkan sebagai berikut:
rds.global_db_rpo
-------------------
-1
(1 row)Respons selanjutnya ini berasal dari klaster DB sekunder yang memiliki pengaturan RPO 1 menit.
rds.global_db_rpo
-------------------
60
(1 row) Anda juga dapat menggunakan CLI untuk memperoleh nilai guna mengetahui apakah rds.global_db_rpo aktif pada salah satu klaster DB Aurora dengan menggunakan CLI untuk memperoleh nilai semua parameter user untuk klaster tersebut.
Untuk Linux, macOS, atau Unix:
aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-namelab-test-apg-global\ --source user
Untuk Windows:
aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-namelab-test-apg-global* --source user
Perintah akan menampilkan output serupa dengan yang berikut untuk semua parameter user selain parameter klaster DB default-engine atau system.
{
"Parameters": [
{
"ParameterName": "rds.global_db_rpo",
"ParameterValue": "60",
"Description": "(s) Recovery point objective threshold, in seconds, that blocks user commits when it is violated.",
"Source": "user",
"ApplyType": "dynamic",
"DataType": "integer",
"AllowedValues": "20-2147483647",
"IsModifiable": true,
"ApplyMethod": "immediate",
"SupportedEngineModes": [
"provisioned"
]
}
]
}
Untuk mempelajari selengkapnya tentang cara melihat parameter dari grup parameter klaster, lihat Melihat nilai parameter untuk grup parameter cluster DB di Amazon Aurora.
Menonaktifkan sasaran titik pemulihan
Untuk menonaktifkan RPO, reset parameter rds.global_db_rpo. Anda dapat mereset parameter menggunakan Konsol Manajemen AWS, AWS CLI, atau API RDS.
Cara menonaktifkan RPO
Masuk ke Konsol Manajemen AWS dan buka konsol Amazon RDS di https://console.aws.amazon.com/rds/
. -
Di panel navigasi, pilih Grup parameter.
-
Dalam daftar, pilih grup parameter klaster DB primer Anda.
-
Pilih Edit parameter.
-
Pilih kotak di sebelah parameter rds.global_db_rpo.
-
Pilih Reset.
-
Saat layar menampilkan Reset parameter dalam grup parameter DB, pilih Reset parameter.
Untuk informasi selengkapnya tentang cara mereset parameter dengan konsol, lihat Memodifikasi parameter dalam grup parameter cluster DB di Amazon Aurora.
Untuk mengatur ulang rds.global_db_rpo parameter, gunakan perintah reset-db-cluster-parameter-group.
Untuk Linux, macOS, atau Unix:
aws rds reset-db-cluster-parameter-group \ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
Untuk Windows:
aws rds reset-db-cluster-parameter-group ^ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
Untuk mengatur ulang rds.global_db_rpo parameter, gunakan DBCluster ParameterGroup operasi Amazon RDS API Reset.
