Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Penyiapan diperlukan saat crawler dan lokasi Amazon S3 terdaftar berada di akun yang berbeda (crawling lintas akun)
Untuk mengizinkan crawler mengakses penyimpanan data di akun lain menggunakan kredensil Lake Formation, Anda harus terlebih dahulu mendaftarkan lokasi data Amazon S3 dengan Lake Formation. Kemudian, Anda memberikan izin lokasi data ke akun crawler dengan mengambil langkah-langkah berikut.
Anda dapat menyelesaikan langkah-langkah berikut menggunakan AWS Management Console atau AWS CLI.
- AWS Management Console
-
Di akun tempat lokasi Amazon S3 terdaftar (akun B):
-
Daftarkan jalur Amazon S3 dengan Lake Formation. Untuk informasi selengkapnya, lihat Mendaftarkan lokasi Amazon S3.
-
Berikan izin lokasi Data ke akun (akun A) tempat crawler akan dijalankan. Untuk informasi selengkapnya, lihat Memberikan izin lokasi data.
-
Buat database kosong di Lake Formation dengan lokasi yang mendasarinya sebagai lokasi target Amazon S3. Untuk informasi selengkapnya, lihat Membuat database.
-
Berikan akun A (akun tempat crawler akan dijalankan) akses ke database yang Anda buat pada langkah sebelumnya. Untuk informasi selengkapnya, lihat Memberikan izin database.
-
Di akun tempat crawler dibuat dan akan dijalankan (akun A):
-
Menggunakan AWS RAM konsol, terima database yang dibagikan dari akun eksternal (akun B). Untuk informasi selengkapnya, lihat Menerima undangan berbagi sumber daya dari AWS Resource Access Manager.
-
Buat peran IAM untuk crawler. Tambahkan lakeformation:GetDataAccess kebijakan ke peran.
-
Di konsol Lake Formation (https://console.aws.amazon.com/lakeformation/), berikan izin lokasi Data pada lokasi Amazon S3 target ke peran IAM yang digunakan untuk menjalankan crawler sehingga crawler dapat membaca data dari tujuan di Lake Formation. Untuk informasi selengkapnya, lihat Memberikan izin lokasi data.
-
Buat tautan sumber daya pada database bersama. Untuk informasi selengkapnya, lihat Membuat tautan sumber daya.
-
Berikan izin akses peran crawler (Create) pada database bersama dan (Describe) tautan sumber daya. Tautan sumber daya ditentukan dalam output untuk crawler.
-
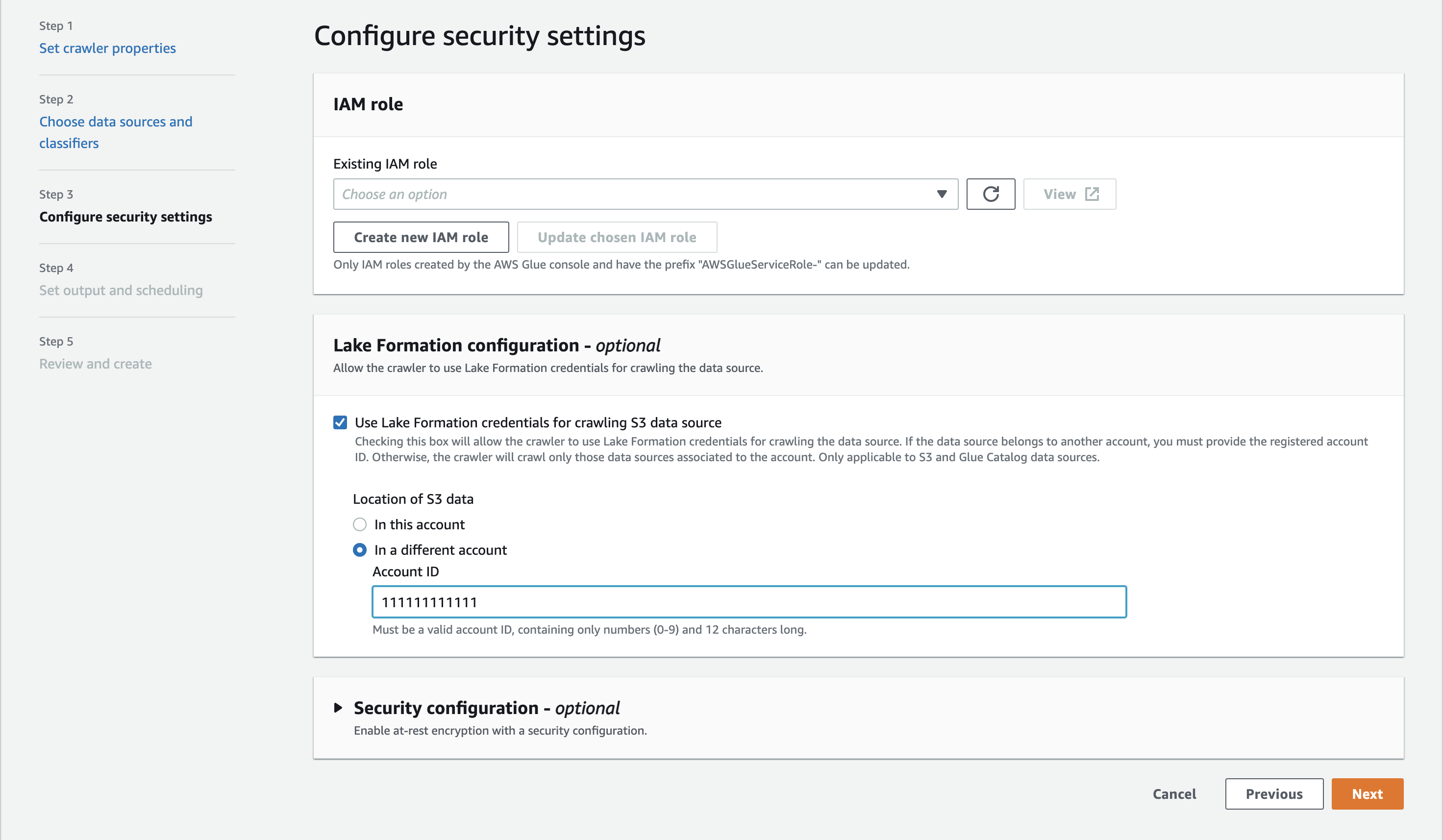
Di AWS Glue console (https://console.aws.amazon.com/glue/), saat mengonfigurasi crawler, pilih opsi Gunakan kredenal Lake Formation untuk merayapi sumber data Amazon S3.
Untuk crawling lintas akun, tentukan Akun AWS ID tempat lokasi Amazon S3 target terdaftar di Lake Formation. Untuk perayapan dalam akun, bidang accountID bersifat opsional.
- AWS CLI
-
aws glue --profile demo create-crawler --debug --cli-input-json '{
"Name": "prod-test-crawler",
"Role": "arn:aws:iam::111122223333:role/service-role/AWSGlueServiceRole-prod-test-run-role",
"DatabaseName": "prod-run-db",
"Description": "",
"Targets": {
"S3Targets":[
{
"Path": "s3://amzn-s3-demo-bucket"
}
]
},
"SchemaChangePolicy": {
"UpdateBehavior": "LOG",
"DeleteBehavior": "LOG"
},
"RecrawlPolicy": {
"RecrawlBehavior": "CRAWL_EVERYTHING"
},
"LineageConfiguration": {
"CrawlerLineageSettings": "DISABLE"
},
"LakeFormationConfiguration": {
"UseLakeFormationCredentials": true,
"AccountId": "111111111111"
},
"Configuration": {
"Version": 1.0,
"CrawlerOutput": {
"Partitions": { "AddOrUpdateBehavior": "InheritFromTable" },
"Tables": {"AddOrUpdateBehavior": "MergeNewColumns" }
},
"Grouping": { "TableGroupingPolicy": "CombineCompatibleSchemas" }
},
"CrawlerSecurityConfiguration": "",
"Tags": {
"KeyName": ""
}
}'
Crawler yang menggunakan kredensi Lake Formation hanya didukung untuk target Amazon S3 dan Katalog Data.
Untuk target yang menggunakan penjual kredensi Lake Formation, lokasi Amazon S3 yang mendasarinya harus termasuk dalam ember yang sama. Misalnya, pelanggan dapat menggunakan beberapa target (s3://amzn-s3-demo-bucket1/folder1, s3://amzn-s3-demo-bucket1/folder2) selama semua lokasi target berada di bawah ember yang sama (amzn-s3-demo-bucket1). Menentukan bucket yang berbeda (s3://amzn-s3-demo-bucket1/folder1, s3://amzn-s3-demo-bucket2/folder2) tidak diperbolehkan.
Saat ini untuk crawler target Katalog Data, hanya satu target katalog dengan satu tabel katalog yang diizinkan.