AWS IoT Greengrass Version 1 memasuki fase umur panjang pada 30 Juni 2023. Untuk informasi selengkapnya, lihat kebijakan AWS IoT Greengrass V1 pemeliharaan. Setelah tanggal ini, tidak AWS IoT Greengrass V1 akan merilis pembaruan yang menyediakan fitur, penyempurnaan, perbaikan bug, atau patch keamanan. Perangkat yang berjalan AWS IoT Greengrass V1 tidak akan terganggu dan akan terus beroperasi dan terhubung ke cloud. Kami sangat menyarankan Anda bermigrasi ke AWS IoT Greengrass Version 2, yang menambahkan fitur baru yang signifikan dan dukungan untuk platform tambahan.
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Ekspor konfigurasi untuk tujuan AWS Cloud yang didukung
Fungsi Lambda yang ditentukan pengguna digunakan StreamManagerClient di AWS IoT Greengrass Core SDK untuk berinteraksi dengan pengelola aliran. Ketika fungsi Lambda membuat pengaliran atau memperbarui pengaliran, fungsi ini melewati objek MessageStreamDefinition yang mewakili properti pengaliran, termasuk definisi ekspor. Objek ExportDefinition berisi konfigurasi ekspor yang ditentukan untuk pengaliran. Stream manager menggunakan konfigurasi ekspor ini untuk menentukan di mana dan bagaimana untuk mengekspor aliran tersebut.

Anda dapat menentukan konfigurasi ekspor nol atau lebih pada suatu aliran, termasuk beberapa konfigurasi ekspor untuk satu jenis tujuan. Misalnya, Anda dapat mengekspor aliran ke dua saluran AWS IoT Analytics dan satu Kinesis data stream.
Untuk usaha ekspor yang gagal, stream manager terus-menerus mencoba mengekspor data ke AWS Cloud pada interval hingga lima menit. Jumlah upaya coba lagi tidak memiliki batas maksimum.
catatan
StreamManagerClient juga menyediakan target tujuan yang dapat Anda gunakan untuk mengekspor aliran ke server HTTP. Target ini ditujukan untuk tujuan pengujian saja. Target ini tidak stabil atau didukung untuk digunakan di lingkungan produksi.
AWS Cloud Tujuan yang didukung
Anda bertanggung jawab untuk mempertahankan sumber daya ini AWS Cloud .
AWS IoT Analytics saluran
Manajer aliran mendukung ekspor otomatis ke AWS IoT Analytics. AWS IoT Analytics memungkinkan Anda melakukan analisis lanjutan pada data Anda untuk membantu membuat keputusan bisnis dan meningkatkan model pembelajaran mesin. Untuk informasi lebih lanjut, lihat Apa itu AWS IoT Analytics? dalam AWS IoT Analytics User Guide.
Di AWS IoT Greengrass Core SDK, fungsi Lambda Anda menggunakan untuk IoTAnalyticsConfig menentukan konfigurasi ekspor untuk jenis tujuan ini. Untuk informasi lebih lanjut, lihat referensi SDK untuk bahasa target Anda:
-
Io TAnalytics Config
di Java SDK
Persyaratan
Tujuan ekspor ini memiliki persyaratan sebagai berikut:
-
Saluran target AWS IoT Analytics harus sama Akun AWS dan Wilayah AWS sebagai grup Greengrass.
-
Peran grup Greengrass harus memungkinkan izin
iotanalytics:BatchPutMessageuntuk menargetkan saluran. Sebagai contoh:{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "iotanalytics:BatchPutMessage" ], "Resource": [ "arn:aws:iotanalytics:region:account-id:channel/channel_1_name", "arn:aws:iotanalytics:region:account-id:channel/channel_2_name" ] } ] }Anda dapat memberikan akses terperinci atau bersyarat ke sumber daya, misalnya dengan menggunakan skema penamaan wildcard
*. Untuk informasi lebih lanjut, lihat Menambahkan dan menghapus kebijakan IAM dalam Panduan Pengguna IAM.
Mengekspor ke AWS IoT Analytics
Untuk membuat aliran yang diekspor AWS IoT Analytics, fungsi Lambda Anda membuat aliran dengan definisi ekspor yang menyertakan satu atau IoTAnalyticsConfig beberapa objek. Objek ini menentukan pengaturan ekspor, seperti saluran target, ukuran batch, batch interval, dan prioritas.
Ketika fungsi Lambda Anda menerima data dari perangkat, mereka menambahkan pesan yang berisi gumpalan data ke aliran target.
Kemudian, manajer pengaliran mengekspor data berdasarkan pengaturan batch dan prioritas yang ditentukan di dalam konfigurasi ekspor pengaliran.
Amazon Kinesis data streams
Pengelola pengaliran mendukung ekspor otomatis ke Amazon Kinesis Data Streams. Kinesis Data Streams umumnya digunakan untuk mengumpulkan data volume tinggi dan memuatnya ke dalam gudang data atau klaster map-reduce. Untuk informasi lebih lanjut, lihat Apa itu Amazon Kinesis Data Streams? dalam Panduan Developer Amazon Kinesis.
Di AWS IoT Greengrass Core SDK, fungsi Lambda Anda menggunakan untuk KinesisConfig menentukan konfigurasi ekspor untuk jenis tujuan ini. Untuk informasi lebih lanjut, lihat referensi SDK untuk bahasa target Anda:
-
KinesisConfig
di Python SDK -
KinesisConfig
di Java SDK -
KinesisConfig
di Node.js SDK
Persyaratan
Tujuan ekspor ini memiliki persyaratan sebagai berikut:
-
Aliran target di Kinesis Data Streams harus sama Akun AWS dan Wilayah AWS sebagai grup Greengrass.
-
Peran grup Greengrass harus memungkinkan izin
kinesis:PutRecordsuntuk menargetkan aliran data. Sebagai contoh:{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "kinesis:PutRecords" ], "Resource": [ "arn:aws:kinesis:region:account-id:stream/stream_1_name", "arn:aws:kinesis:region:account-id:stream/stream_2_name" ] } ] }Anda dapat memberikan akses terperinci atau bersyarat ke sumber daya, misalnya dengan menggunakan skema penamaan wildcard
*. Untuk informasi lebih lanjut, lihat Menambahkan dan menghapus kebijakan IAM dalam Panduan Pengguna IAM.
Mengekspor ke Kinesis Data Streams
Untuk membuat pengaliran yang mengeksport ke Kinesis Data Streams, fungsi Lambda anda buat pengaliran dengan definisi ekspor yang mencakup satu atau lebih KinesisConfig objek. Objek ini menentukan pengaturan ekspor, seperti aliran data target, ukuran batch, interval batch, dan prioritas.
Ketika fungsi Lambda Anda menerima data dari perangkat, mereka menambahkan pesan yang berisi gumpalan data ke aliran target. Kemudian, manajer pengaliran mengekspor data berdasarkan pengaturan batch dan prioritas yang ditentukan di dalam konfigurasi ekspor pengaliran.
Stream manager menghasilkan UUID acak yang unik sebagai kunci partisi untuk setiap rekaman yang diunggah ke Amazon Kinesis.
AWS IoT SiteWise properti aset
Manajer aliran mendukung ekspor otomatis ke AWS IoT SiteWise. AWS IoT SiteWise memungkinkan Anda mengumpulkan, mengatur, dan menganalisis data dari peralatan industri dalam skala besar. Untuk informasi lebih lanjut, lihat Apa itu AWS IoT SiteWise? dalam AWS IoT SiteWise User Guide.
Di AWS IoT Greengrass Core SDK, fungsi Lambda Anda menggunakan untuk IoTSiteWiseConfig menentukan konfigurasi ekspor untuk jenis tujuan ini. Untuk informasi lebih lanjut, lihat referensi SDK untuk bahasa target Anda:
-
Io TSite WiseConfig
dalam SDK Python -
Io TSite WiseConfig
di Java SDK -
Io TSite WiseConfig
di Node.js SDK
catatan
AWS juga menyediakanKonektor IoT SiteWise , yang merupakan solusi pra-bangun yang dapat Anda gunakan dengan sumber OPC-UA.
Persyaratan
Tujuan ekspor ini memiliki persyaratan sebagai berikut:
-
Properti aset target AWS IoT SiteWise harus sama Akun AWS dan Wilayah AWS sebagai grup Greengrass.
catatan
Untuk daftar Wilayah yang AWS IoT SiteWise mendukung, lihat AWS IoT SiteWise titik akhir dan kuota di Referensi AWS Umum.
-
Peran grup Greengrass harus memungkinkan izin
iotsitewise:BatchPutAssetPropertyValueuntuk menargetkan properti aset. Kebijakan berikut menggunakan kunci kondisiiotsitewise:assetHierarchyPathuntuk memberikan akses ke aset akar target dan anak-anaknya. Anda dapat menghapusConditiondari kebijakan untuk mengizinkan akses ke semua AWS IoT SiteWise aset Anda atau menentukan ARNs aset individu.{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "iotsitewise:BatchPutAssetPropertyValue", "Resource": "*", "Condition": { "StringLike": { "iotsitewise:assetHierarchyPath": [ "/root node asset ID", "/root node asset ID/*" ] } } } ] }Anda dapat memberikan akses terperinci atau bersyarat ke sumber daya, misalnya dengan menggunakan skema penamaan wildcard
*. Untuk informasi lebih lanjut, lihat Menambahkan dan menghapus kebijakan IAM dalam Panduan Pengguna IAM.Untuk informasi keamanan penting, lihat BatchPutAssetPropertyValue otorisasi di Panduan AWS IoT SiteWise Pengguna.
Mengekspor ke AWS IoT SiteWise
Untuk membuat aliran yang diekspor AWS IoT SiteWise, fungsi Lambda Anda membuat aliran dengan definisi ekspor yang menyertakan satu atau IoTSiteWiseConfig beberapa objek. Objek ini mendefinisikan pengaturan ekspor, seperti ukuran batch, batch interval, dan prioritas.
Ketika fungsi Lambda Anda menerima data properti aset dari perangkat, mereka menambahkan pesan yang berisi data ke pengaliran target. Pesan adalah objek PutAssetPropertyValueEntry serial JSON yang berisi nilai properti untuk satu atau lebih properti aset. Untuk informasi selengkapnya, lihat: Tambahkan pesan untuk tujuan ekspor AWS IoT SiteWise .
catatan
Saat Anda mengirim data ke AWS IoT SiteWise, data Anda harus memenuhi persyaratan BatchPutAssetPropertyValue tindakan. Untuk informasi selengkapnya, lihat BatchPutAssetPropertyValue di dalam Referensi API AWS IoT SiteWise .
Kemudian, stream manager mengekspor data berdasarkan pengaturan batch dan prioritas yang ditentukan dalam konfigurasi ekspor aliran.
Anda dapat menyesuaikan pengaturan pengelola pengaliran dan logika fungsi Lambda untuk merancang strategi ekspor Anda. Sebagai contoh:
-
Untuk ekspor yang mendekati real time, atur ukuran batch dan pengaturan interval yang rendah dan tambahkan data ke aliran saat diterima.
-
Untuk mengoptimalkan batching, mengurangi batasan bandwidth, atau meminimalkan biaya, fungsi Lambda Anda dapat mengumpulkan titik data timestamp-quality-value (TQV) yang diterima untuk satu properti aset sebelum menambahkan data ke aliran. Salah satu strateginya adalah mengelompokkan entri hingga 10 kombinasi aset properti yang berbeda, atau alias properti, dalam satu pesan, dan bukan mengirim lebih dari satu entri untuk properti yang sama. Hal ini membantu manajer pengaliran untuk tetap berada dalam kuota AWS IoT SiteWise.
Objek Amazon S3
Stream manager mendukung ekspor otomatis ke Amazon S3. Sebagai contoh, Anda dapat menggunakan Amazon S3 untuk menyimpan dan mengambil sejumlah besar data. Untuk informasi selengkapnya, lihat Apa itu Amazon S3? dalam Panduan Developer Amazon Simple Storage Service.
Di AWS IoT Greengrass Core SDK, fungsi Lambda Anda menggunakan untuk S3ExportTaskExecutorConfig menentukan konfigurasi ekspor untuk jenis tujuan ini. Untuk informasi lebih lanjut, lihat referensi SDK untuk bahasa target Anda:
-
S3 ExportTaskExecutorConfig
di Python SDK -
S3 ExportTaskExecutorConfig
di Java SDK -
S3 ExportTaskExecutorConfig
di Node.js SDK
Persyaratan
Tujuan ekspor ini memiliki persyaratan sebagai berikut:
-
Target ember Amazon S3 harus sama dengan grup Akun AWS Greengrass.
-
Jika kontainerisasi default untuk grup Greengrass adalah kontainer Greengrass, Anda harus mengatur parameter STREAM_MANAGER_READ_ONLY_DIRS untuk menggunakan direktori file input yang berada di bawah
/tmpatau tidak pada sistem file root. -
Jika fungsi Lambda berjalan di kontainer Greengrass mode menulis file input ke direktori file input, Anda harus membuat sumber daya volume lokal untuk direktori dan mount direktori ke kontainer dengan izin menulis. Hal ini memastikan bahwa file ditulis ke sistem file root dan terlihat di luar kontainer. Untuk informasi selengkapnya, lihat Akses sumber daya lokal dengan fungsi dan konektor Lambda.
-
Sebuah Peran grup Greengrass harus mengizinkan izin berikut untuk target bucket. Sebagai contoh:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:AbortMultipartUpload", "s3:ListMultipartUploadParts" ], "Resource": [ "arn:aws:s3:::bucket-1-name/*", "arn:aws:s3:::bucket-2-name/*" ] } ] }Anda dapat memberikan akses terperinci atau bersyarat ke sumber daya, misalnya dengan menggunakan skema penamaan wildcard
*. Untuk informasi lebih lanjut, lihat Menambahkan dan menghapus kebijakan IAM dalam Panduan Pengguna IAM.
Mengekspor ke Amazon S3
Untuk membuat pengaliran yang mengekspor ke Amazon S3, fungsi Lambda Anda menggunakan S3ExportTaskExecutorConfig objek untuk mengonfigurasi kebijakan ekspor. Kebijakan ini mendefinisikan pengaturan ekspor, seperti ambang dan prioritas unggahan multipart. Untuk ekspor Amazon S3, pengelola pengaliran mengunggah data yang dibaca dari file lokal pada perangkat core. Untuk memulai unggahan, fungsi Lambda Anda menambahkan tugas ekspor ke pengaliran target. Tugas ekspor berisi informasi tentang file input dan objek Amazon S3 target. Pengelola pengaliran mengeksekusi tugas dalam urutan yang mereka tambahkan ke pengaliran.
catatan
Ember target harus sudah ada di Anda Akun AWS. Jika sebuah objek untuk kunci tertentu tidak ada, pengelola pengaliran membuat objek untuk Anda.
Alur kerja tingkat tinggi ini ditunjukkan dalam diagram berikut.
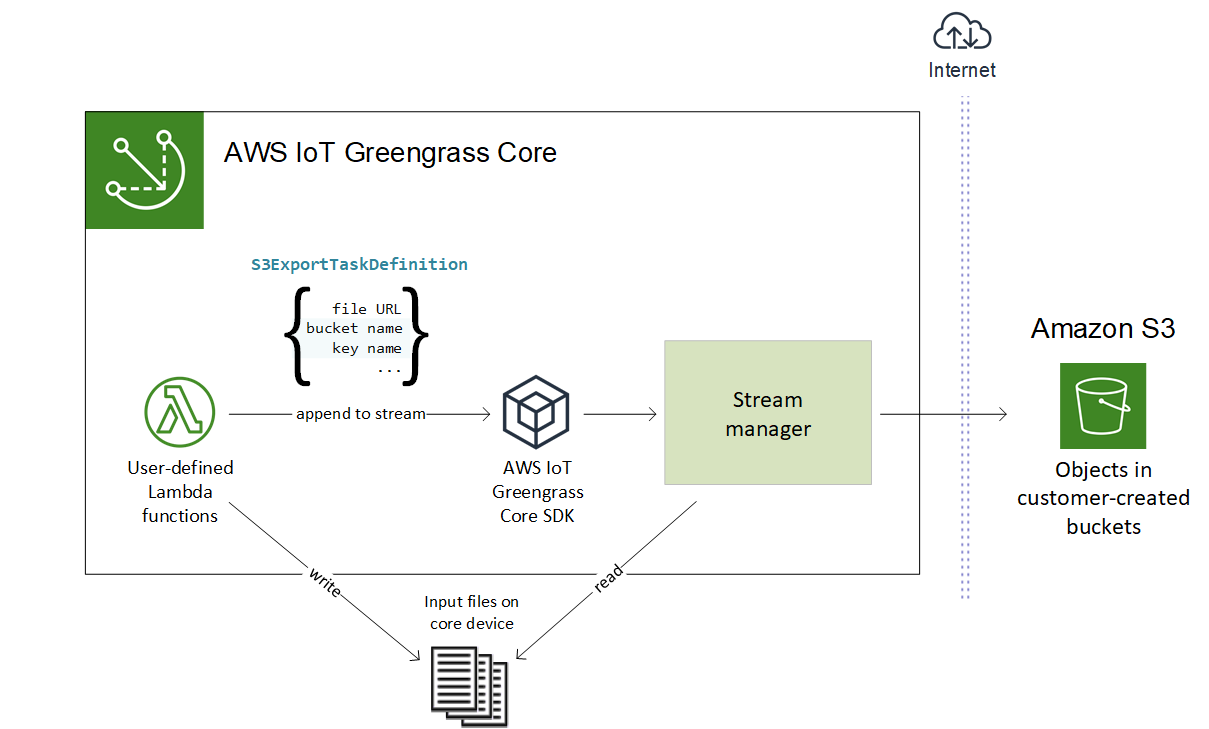
Pengelola pengaliran menggunakan unggahan multipart ambang properti, ukuran bagian minimum pengaturan, dan ukuran file input untuk menentukan cara untuk mengunggah data. Ambang batas unggahan multipart harus lebih besar atau sama dengan ukuran bagian minimum. Jika Anda ingin meng-upload data secara paralel, Anda dapat membuat beberapa aliran.
Kunci yang menentukan objek Amazon S3 target Anda dapat menyertakan DateTimeFormatter string Java!{timestamp: Anda dapat menggunakan placeholder stempel waktu ini untuk membagi data di Amazon S3 berdasarkan waktu data file input tersebut diunggah. Sebagai contoh, nama kunci berikut memutuskan untuk nilai seperti value}my-key/2020/12/31/data.txt.
my-key/!{timestamp:YYYY}/!{timestamp:MM}/!{timestamp:dd}/data.txt
catatan
Jika Anda ingin memantau status ekspor untuk suatu aliran, pertama-tama buat status aliran dan kemudian konfigurasi aliran ekspor untuk menggunakannya. Untuk informasi selengkapnya, lihat Pantau tugas ekspor.
Kelola data input
Anda dapat penulis kode yang digunakan aplikasi IoT untuk mengelola siklus hidup dari input data. Contoh alur kerja berikut menunjukkan cara Anda mungkin menggunakan fungsi Lambda untuk mengelola data ini.
-
Proses lokal menerima data dari perangkat atau periferal, lalu menulis data ke file dalam direktori pada perangkat core. Ini adalah file input untuk pengelola pengaliran.
catatan
Untuk menentukan apakah Anda harus mengonfigurasi akses ke direktori file input, lihat parameter STREAM_MANAGER_READ_ONLY_DIRS ini.
Proses yang menjalankan pengelola pengaliran dalam mewarisi semua izin sistem file identitas akses default untuk grup. Pengelola pengaliran harus memiliki izin untuk mengakses file input. Anda dapat menggunakan
chmod(1)perintah untuk mengubah izin dari file, jika perlu. -
Sebuah fungsi Lambda memindai direktori dan menambahkan tugas ekspor ke pengaliran target ketika file baru dibuat. Tugas adalah JSON-serialized
S3ExportTaskDefinitionobjek yang menentukan URL dari file input, bucket dan kunci Amazon S3 target, dan metadata pengguna opsional. -
Stream manager membaca file input dan mengekspor data ke Amazon S3 dalam urutan tugas yang ditambahkan. Ember target harus sudah ada di Anda Akun AWS. Jika sebuah objek untuk kunci tertentu tidak ada, pengelola pengaliran membuat objek untuk Anda.
-
Fungsi Lambda membaca pesan dari pengaliran status untuk memantau status ekspor. Setelah tugas ekspor selesai, fungsi Lambda dapat menghapus file input yang sesuai. Untuk informasi selengkapnya, lihat Pantau tugas ekspor.
Pantau tugas ekspor
Anda dapat penulis kode yang digunakan aplikasi IoT untuk memantau status ekspor Amazon S3 Anda. Fungsi Lambda Anda harus membuat status pengaliran lalu mengonfigurasi pengaliran ekspor untuk menulis pembaruan ke status untuk status pengaliran. Pengaliran status tunggal dapat menerima pembaruan status dari beberapa pengaliran yang mengekspor ke Amazon S3.
Pertama-tama, buat aliran yang akan digunakan sebagai status aliran. Anda dapat mengonfigurasi kebijakan ukuran dan penyimpanan bagi aliran tersebut untuk mengontrol umur pesan status. Sebagai contoh:
-
Tetapkan
PersistencekeMemoryjika Anda tidak ingin menyimpan pesan status. -
Tetapkan
StrategyOnFullkeOverwriteOldestDataagar pesan status baru tidak hilang.
Kemudian, buat atau perbarui aliran ekspor untuk menggunakan status aliran. Secara khusus, atur properti konfigurasi status dari konfigurasi ekspor S3ExportTaskExecutorConfig pengaliran. Ini memberitahu pengelola pengaliran untuk menulis pesan status tentang tugas ekspor ke pengaliran status. Di StatusConfig objek, tentukan nama pengaliran status dan tingkat verbositas. Nilai yang didukung berikut berkisar dari verbositas paling kecil (ERROR) hingga verbositas tertinggi (TRACE). Default-nya adalah INFO.
-
ERROR -
WARN -
INFO -
DEBUG -
TRACE
Contoh alur kerja berikut menunjukkan cara fungsi Lambda mungkin menggunakan status pengaliran untuk memantau status ekspor.
-
Seperti yang dijelaskan dalam alur kerja sebelumnya, fungsi Lambda menambahkan tugas ekspor ke pengaliran yang dikonfigurasi untuk menulis pesan status tentang tugas ekspor ke pengaliran status. Operasi penambahan mengembalikan nomor urut yang mewakili ID tugas.
-
Sebuah fungsi Lambda membaca pesan secara berurutan dari pengaliran status, lalu menyaring pesan berdasarkan nama pengaliran dan ID tugas atau berdasarkan properti tugas ekspor dari konteks pesan. Sebagai contoh, fungsi Lambda dapat difilter oleh URL file input dari tugas ekspor, yang diwakili oleh
S3ExportTaskDefinitionobjek dalam konteks pesan.Kode status berikut menunjukkan bahwa tugas ekspor telah mencapai keadaan selesai:
-
Success. Upload berhasil diselesaikan. -
Failure. Stream manager mengalami kesalahan, misalnya, bucket yang ditentukan tidak ada. Setelah menyelesaikan masalah, Anda dapat menambahkan tugas ekspor ke aliran lagi. -
Canceled. Tugas dibatalkan karena definisi aliran atau ekspor telah dihapus, atau periode time-to-live (TTL) tugas berakhir.
catatan
Tugas mungkin juga memiliki status
InProgressatauWarning. Pengelola pengaliran mengeluarkan peringatan ketika suatu peristiwa mengembalikan kesalahan yang tidak memengaruhi pelaksanaan tugas. Sebagai contoh, kegagalan untuk membersihkan unggahan parsial dibatalkan mengembalikan peringatan. -
-
Setelah tugas ekspor selesai, fungsi Lambda dapat menghapus file input yang sesuai.
Contoh berikut menunjukkan cara fungsi Lambda mungkin membaca dan memproses pesan status.
