Pemberitahuan akhir dukungan: Pada 31 Mei 2026, AWS akan mengakhiri dukungan untuk AWS Panorama. Setelah 31 Mei 2026, Anda tidak akan lagi dapat mengakses AWS Panorama konsol atau AWS Panorama sumber daya. Untuk informasi lebih lanjut, lihat AWS Panorama akhir dukungan.
Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Model visi komputer
Model visi komputer adalah program perangkat lunak yang dilatih untuk mendeteksi objek dalam gambar. Sebuah model belajar mengenali satu set objek dengan terlebih dahulu menganalisis gambar objek tersebut melalui pelatihan. Model visi komputer mengambil gambar sebagai input dan output informasi tentang objek yang dideteksi, seperti jenis objek dan lokasinya. AWS Panorama mendukung model visi komputer yang dibangun dengan PyTorch, Apache MXNet, dan. TensorFlow
catatan
Untuk daftar model pra-bangun yang telah diuji dengan AWS Panorama, lihat
Menggunakan model dalam kode
Sebuah model mengembalikan satu atau lebih hasil, yang dapat mencakup probabilitas untuk kelas terdeteksi, informasi lokasi, dan data lainnya.Contoh berikut menunjukkan bagaimana menjalankan inferensi pada gambar dari aliran video dan mengirim output model ke fungsi pemrosesan.
contoh application.py
def process_media(self, stream): """Runs inference on a frame of video.""" image_data = preprocess(stream.image,self.MODEL_DIM) logger.debug('Image data: {}'.format(image_data)) # Run inference inference_start = time.time()inference_results = self.call({"data":image_data}, self.MODEL_NODE)# Log metrics inference_time = (time.time() - inference_start) * 1000 if inference_time > self.inference_time_max: self.inference_time_max = inference_time self.inference_time_ms += inference_time # Process results (classification)self.process_results(inference_results, stream)
Contoh berikut menunjukkan fungsi yang memproses hasil dari model klasifikasi dasar. Model sampel mengembalikan array probabilitas, yang merupakan nilai pertama dan satu-satunya dalam array hasil.
contoh application.py
def process_results(self, inference_results, stream): """Processes output tensors from a computer vision model and annotates a video frame.""" if inference_results is None: logger.warning("Inference results are None.") return max_results = 5 logger.debug('Inference results: {}'.format(inference_results)) class_tuple = inference_results[0] enum_vals = [(i, val) for i, val in enumerate(class_tuple[0])] sorted_vals = sorted(enum_vals, key=lambda tup: tup[1]) top_k = sorted_vals[::-1][:max_results] indexes = [tup[0] for tup in top_k] for j in range(max_results): label = 'Class [%s], with probability %.3f.'% (self.classes[indexes[j]], class_tuple[0][indexes[j]]) stream.add_label(label, 0.1, 0.1 + 0.1*j)
Kode aplikasi menemukan nilai dengan probabilitas tertinggi dan memetakannya ke label dalam file sumber daya yang dimuat selama inisialisasi.
Membangun model khusus
Anda dapat menggunakan model yang Anda buat PyTorch, Apache MXNet, dan TensorFlow dalam aplikasi AWS Panorama. Sebagai alternatif untuk membangun dan melatih model dalam SageMaker AI, Anda dapat menggunakan model terlatih atau membangun dan melatih model Anda sendiri dengan kerangka kerja yang didukung dan mengekspornya di lingkungan lokal atau di Amazon EC2.
catatan
Untuk detail tentang versi framework dan format file yang didukung oleh SageMaker AI Neo, lihat Kerangka Kerja yang Didukung di Panduan Pengembang Amazon SageMaker AI.
Repositori untuk panduan ini menyediakan contoh aplikasi yang menunjukkan alur kerja ini untuk model Keras dalam format. TensorFlow SavedModel Ini menggunakan TensorFlow 2 dan dapat berjalan secara lokal di lingkungan virtual atau dalam wadah Docker. Aplikasi sampel juga menyertakan templat dan skrip untuk membuat model pada EC2 instance Amazon.
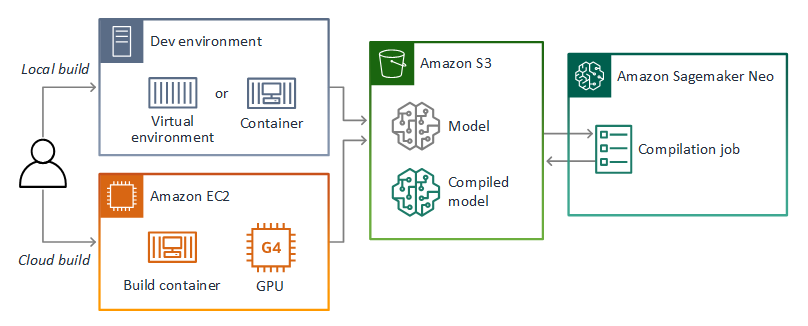
AWS Panorama menggunakan SageMaker AI Neo untuk mengkompilasi model untuk digunakan pada AWS Panorama Appliance. Untuk setiap kerangka kerja, gunakan format yang didukung oleh SageMaker AI Neo, dan paket model dalam .tar.gz arsip.
Untuk informasi selengkapnya, lihat Mengompilasi dan menerapkan model dengan Neo di Panduan Pengembang Amazon SageMaker AI.
Mengemas model
Paket model terdiri dari deskriptor, konfigurasi paket, dan arsip model. Seperti dalam paket gambar aplikasi, konfigurasi paket memberi tahu layanan AWS Panorama tempat model dan deskriptor disimpan di Amazon S3.
contoh Paket/123456789012-Squeezenet_Pytorch-1.0/Descriptor.json
{ "mlModelDescriptor": { "envelopeVersion": "2021-01-01", "framework": "PYTORCH", "frameworkVersion": "1.8", "precisionMode": "FP16", "inputs": [ { "name": "data", "shape": [ 1, 3, 224, 224 ] } ] } }
catatan
Tentukan versi mayor dan minor versi kerangka kerja saja. Untuk daftar versi yang didukung PyTorch, Apache MXNet, dan TensorFlow versi, lihat Kerangka kerja yang didukung.
Untuk mengimpor model, gunakan perintah AWS Panorama Application CLI. import-raw-model Jika Anda membuat perubahan pada model atau deskriptornya, Anda harus menjalankan kembali perintah ini untuk memperbarui aset aplikasi. Untuk informasi selengkapnya, lihat Mengubah model visi komputer.
Untuk skema JSON file deskriptor, lihat AssetDescriptor.schema.json.
Model pelatihan
Saat Anda melatih model, gunakan gambar dari lingkungan target, atau dari lingkungan pengujian yang sangat mirip dengan lingkungan target. Pertimbangkan faktor-faktor berikut yang dapat mempengaruhi kinerja model:
-
Pencahayaan — Jumlah cahaya yang dipantulkan oleh subjek menentukan seberapa banyak detail yang harus dianalisis model. Model yang dilatih dengan gambar subjek yang cukup terang mungkin tidak berfungsi dengan baik di lingkungan dengan cahaya rendah atau cahaya latar.
-
Resolusi — Ukuran input model biasanya ditetapkan pada resolusi antara 224 dan 512 piksel lebar dalam rasio aspek persegi. Sebelum Anda meneruskan bingkai video ke model, Anda dapat menurunkan atau memotongnya agar sesuai dengan ukuran yang diperlukan.
-
Distorsi gambar — Panjang fokus kamera dan bentuk lensa dapat menyebabkan gambar menunjukkan distorsi jauh dari pusat bingkai. Posisi kamera juga menentukan fitur subjek mana yang terlihat. Misalnya, kamera overhead dengan lensa sudut lebar akan menunjukkan bagian atas subjek saat berada di tengah bingkai, dan tampilan miring dari sisi subjek saat bergerak lebih jauh dari tengah.
Untuk mengatasi masalah ini, Anda dapat memproses gambar sebelum mengirimnya ke model, dan melatih model pada variasi gambar yang lebih luas yang mencerminkan varians di lingkungan dunia nyata. Jika model perlu beroperasi dalam situasi pencahayaan dan dengan berbagai kamera, Anda memerlukan lebih banyak data untuk pelatihan. Selain mengumpulkan lebih banyak gambar, Anda bisa mendapatkan lebih banyak data pelatihan dengan membuat variasi gambar yang ada yang miring atau memiliki pencahayaan berbeda.
