Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Praktik terbaik untuk peramalan permintaan produk baru
Bagian ini membahas praktik terbaik berikut untuk peramalan permintaan produk baru:
Memenuhi persyaratan kesiapan data untuk peramalan permintaan berbasis data NPI
Untuk mengadopsi pendekatan berbasis data untuk peramalan NPI permintaan, organisasi Anda harus mendapatkan dukungan dari semua pemangku kepentingan yang relevan, seperti manajer di departemen ilmu data atau analitik, rantai pasokan, pemasaran, dan TI. Organisasi Anda kemudian harus mengidentifikasi hal-hal berikut:
-
Sumber data internal yang ada dan data eksternal yang relevan
-
Pemilik sumber data ini
-
Prosedur dan izin yang diperlukan untuk menggunakan sumber data ini untuk inisiatif
Anda dapat mengevaluasi kesiapan data Anda terhadap jenis kumpulan data wajib dan opsional berikut. Menggunakan kumpulan data sebanyak mungkin, termasuk jenis opsional, membantu model pembelajaran mesin menghasilkan perkiraan NPI permintaan yang lebih akurat.
Berikut ini adalah contoh sumber data internal yang diperlukan:
-
Riwayat penjualan lengkap (dari peluncuran produk hingga penghentian) untuk semua produk atau subset produk yang memiliki atribut serupa dengan produk baru yang diluncurkan. Riwayat penjualan dapat berasal dari beberapa saluran penjualan atau digabungkan di semua saluran.
-
Pemetaan atribut produk untuk mengidentifikasi subset produk yang memiliki atribut serupa dengan produk baru yang diluncurkan.
Berikut ini adalah contoh sumber data internal opsional:
-
Data pemasaran yang melacak promosi dan diskon untuk produk serupa. Data ini harus sama dengan atau lebih besar dari panjang riwayat penjualan.
-
Ulasan produk, peringkat, dan data lalu lintas web. Data ini harus sama dengan atau lebih besar dari panjang riwayat penjualan.
-
Data demografis konsumen
Berikut ini adalah contoh sumber data eksternal opsional yang dapat melengkapi data internal Anda:
-
Data indeks konsumen
-
Data penjualan pesaing
-
Data survei
Membangun mekanisme konsumsi data yang hemat biaya
Setelah persyaratan kesiapan data Anda terpenuhi, organisasi Anda dapat memilih mekanisme konsumsi data dan penyimpanan data yang paling sesuai. Jika sumber utama data penjualan organisasi Anda dikumpulkan setiap hari dari saluran yang berbeda, pertimbangkan konsumsi data batch. Streaming konsumsi data adalah pilihan lain jika Anda menginginkan perkiraan layanan mandiri yang mendapat manfaat dari memiliki data terbaru.
Pipa konsumsi data mentah harus menggunakan pipa ekstrak, transformasi, dan beban (ETL) untuk transformasi ringan. Pipeline harus melakukan pemeriksaan kualitas data dan menyimpan data yang diproses dalam database untuk konsumsi hilir.
Anda dapat menggunakan Layanan AWS, seperti AWS Glue, Amazon Data Firehose AWS Glue Data Catalog, dan Amazon Simple Storage Service (Amazon S3), untuk konsumsi dan penyimpanan data yang hemat biaya. AWS Glue adalah ETL layanan tanpa server yang dikelola sepenuhnya yang membantu Anda mengkategorikan, membersihkan, mengubah, dan mentransfer data dengan andal antara berbagai penyimpanan data. Komponen inti AWS Glue terdiri dari repositori metadata pusat, yang dikenal sebagai AWS Glue Data Catalog, dan sistem ETL pekerjaan yang secara otomatis menghasilkan kode Python dan Scala dan mengelola pekerjaan. ETL Amazon Data Firehose membantu Anda mengumpulkan, memproses, dan menganalisis data streaming waktu nyata dalam skala apa pun. Firehose dapat mengirimkan data streaming real-time langsung ke data lake (seperti Amazon S3), penyimpanan data, dan layanan analitis untuk diproses lebih lanjut. Amazon S3 adalah layanan penyimpanan objek yang menawarkan skalabilitas, ketersediaan data, keamanan, dan kinerja.
Tentukan pendekatan ML yang layak untuk memperkirakan permintaan NPI
Bergantung pada kasus penggunaan spesifik, organisasi Anda dapat mempertimbangkan opsi peramalan yang berbeda.
Pendekatan peramalan statistik, seperti model difusi Bass
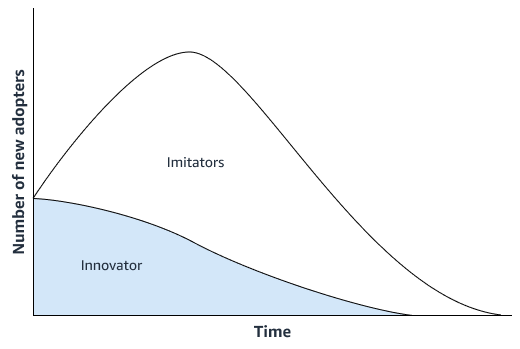
Jika produk baru tidak menampilkan inovasi yang signifikan, organisasi Anda dapat menggunakan model peramalan deret waktu yang beroperasi pada riwayat penjualan produk yang paling mirip dengan produk baru. Anda dapat menggunakan algoritme peramalan berbasis MD, seperti algoritme peramalan Amazon AI SageMaker DeepAR, yang dapat menggunakan data penjualan deret waktu dari beberapa produk serupa. Ini sangat cocok untuk skenario peramalan awal dingin, yaitu saat Anda ingin menghasilkan perkiraan untuk deret waktu tetapi memiliki sedikit atau tidak ada data historis yang ada. Gambar berikut menunjukkan bagaimana Anda dapat menggunakan data deret waktu dari produk terkait untuk menghasilkan perkiraan untuk produk baru yang serupa.
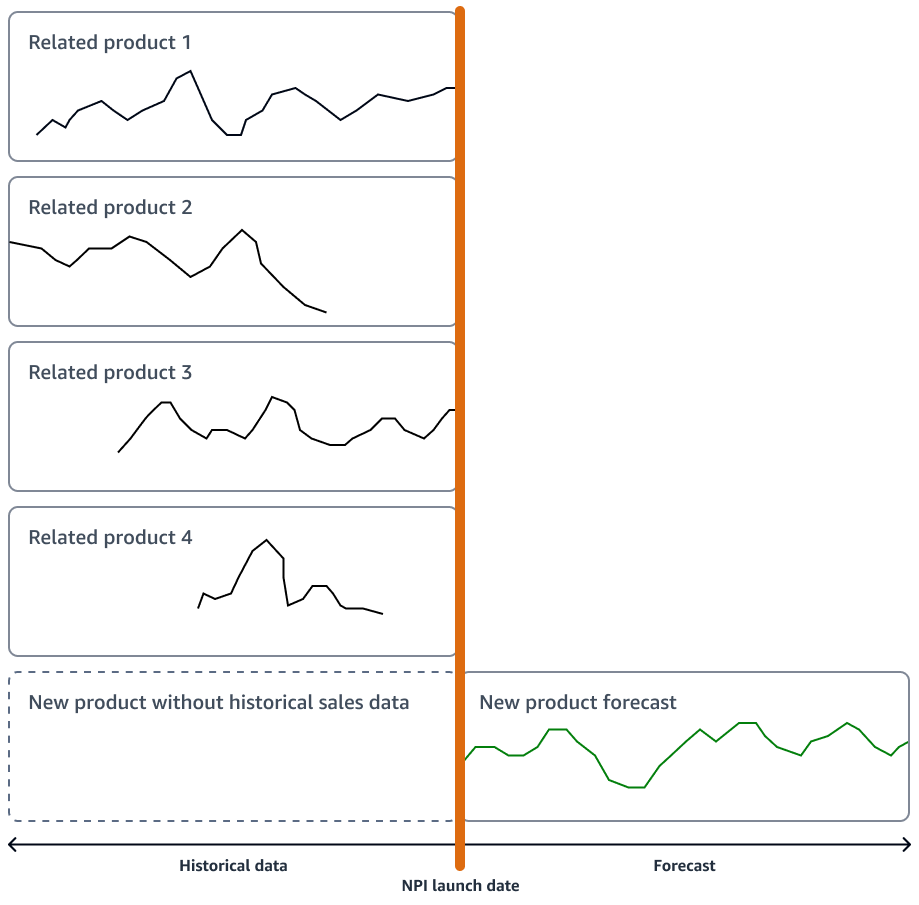
Anda harus mempertimbangkan untuk membuat perkiraan yang selaras dengan timeline peluncuran produk baru Anda. Hasilkan perkiraan jauh sebelumnya untuk memungkinkan buffer yang cukup untuk koreksi logistik apa pun.
Skala dan lacak efek prakiraan
Setelah menyelesaikan bukti konsep untuk peramalan NPI permintaan, solusi pada akhirnya harus skala untuk memasukkan produk tambahan dan beberapa wilayah. Gunakan kerangka kerja kecerdasan buatan dan pembelajaran mesin (AI/ML) untuk menyiapkan data dan mengembangkan, menyebarkan, dan memantau model.
Diagram berikut menunjukkan strategi peluncuran dan skala saat solusi NPI peramalan organisasi matang.
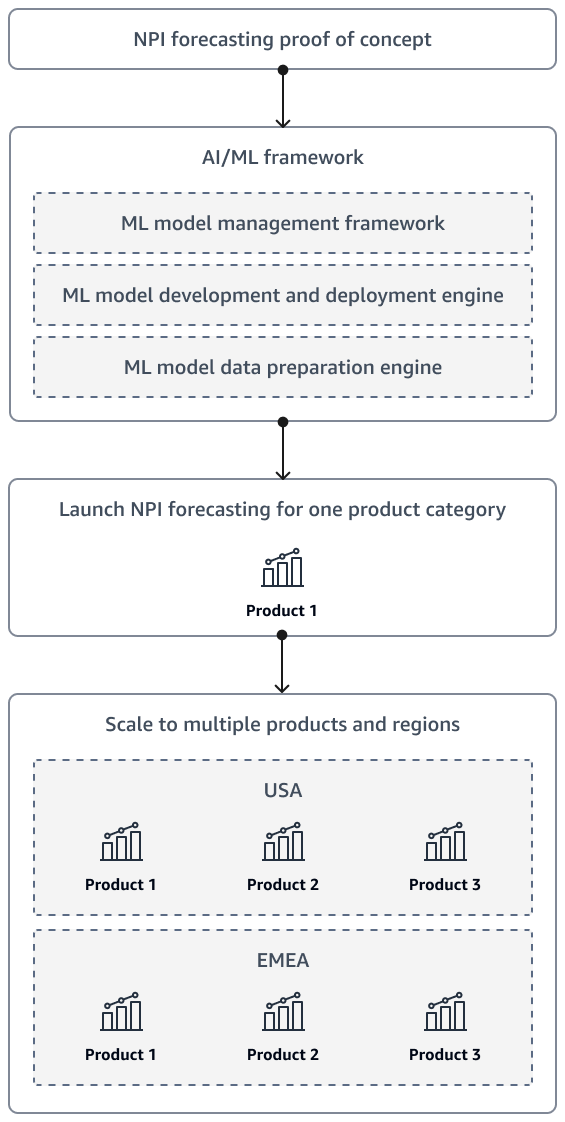
Anda juga disarankan untuk merancang solusinya sehingga para eksekutif dan pemangku kepentingan dapat melayani sendiri prakiraan. Misalnya, Anda dapat membuat QuickSightdasbor Amazon sehingga pemangku kepentingan dapat mengakses perkiraan terbaru sesuai permintaan.
Pantau dengan cermat akurasi peramalan, dan selidiki penyimpangan secara menyeluruh untuk memastikan pengembalian investasi yang wajar ()ROI. Jika Anda mengatur pemantauan model dengan Amazon SageMaker AI Model Monitor, Anda dapat melacak kinerja model Anda saat mereka membuat prediksi real-time pada data langsung. Anda dapat menggunakan Dasbor SageMaker Model Amazon untuk menemukan model yang melanggar ambang batas yang Anda tetapkan untuk kualitas data, kualitas model, bias, dan kemampuan penjelasan. Untuk informasi selengkapnya, lihat Menggunakan tata kelola untuk mengelola izin dan melacak kinerja model dalam dokumentasi Amazon SageMaker AI.
