Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Membuat saluran pipa ML-siap produksi di AWS
Josiah Davis, Verdi March, Yin Song, Baichuan Sun, Chen Wu, dan Wei Yih Yap, Amazon Web Services ()AWS
Januari 2021 (riwayat dokumen)
Proyek pembelajaran mesin (ML) membutuhkan upaya multi-tahap yang signifikan yang mencakup pemodelan, implementasi, dan produksi untuk memberikan nilai bisnis dan untuk memecahkan masalah dunia nyata. Banyak alternatif dan opsi penyesuaian tersedia di setiap langkah, dan ini membuatnya semakin menantang untuk menyiapkan model ML untuk produksi dalam batasan sumber daya dan anggaran Anda. Selama beberapa tahun terakhir di Amazon Web Services (AWS), tim Ilmu Data kami telah bekerja dengan berbagai sektor industri dalam inisiatif ML. Kami mengidentifikasi titik-titik nyeri yang dimiliki oleh banyak AWS pelanggan, yang berasal dari masalah organisasi dan tantangan teknis, dan kami telah mengembangkan pendekatan optimal untuk memberikan solusi ML siap produksi.
Panduan ini ditujukan untuk ilmuwan data dan insinyur ML yang terlibat dalam implementasi pipa ML. Ini menjelaskan pendekatan kami untuk memberikan jaringan pipa ML siap produksi. Panduan ini membahas bagaimana Anda dapat bertransisi dari menjalankan model ML secara interaktif (selama pengembangan) ke menerapkannya sebagai bagian dari pipeline (selama produksi) untuk kasus penggunaan ML Anda. Untuk tujuan ini, kami juga telah mengembangkan satu set contoh template (lihat proyek proyek MLMax
Gambaran Umum
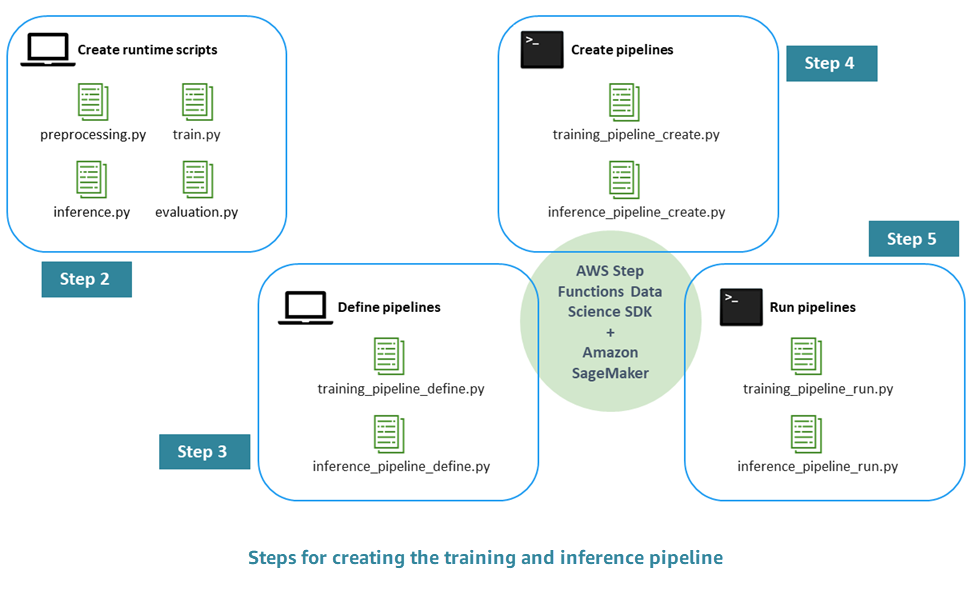
Proses pembuatan pipa ML siap produksi terdiri dari langkah-langkah berikut:
-
Langkah 1. Lakukan EDA dan kembangkan model awal — Ilmuwan data membuat data mentah tersedia di Amazon Simple Storage Service (Amazon S3), melakukan analisis data eksplorasi (EDA), mengembangkan model ML awal, dan mengevaluasi kinerja inferensinya. Anda dapat melakukan kegiatan ini secara interaktif melalui notebook Jupyter.
-
Langkah 2. Buat skrip runtime — Anda mengintegrasikan model dengan skrip Python runtime sehingga dapat dikelola dan disediakan oleh kerangka kerja HTML (dalam kasus kami, Amazon AI). SageMaker Ini adalah langkah pertama dalam menjauh dari pengembangan interaktif model mandiri menuju produksi. Secara khusus, Anda mendefinisikan logika untuk preprocessing, evaluasi, pelatihan, dan inferensi secara terpisah.
-
Langkah 3. Tentukan pipeline — Anda menentukan placeholder input dan output untuk setiap langkah pipeline. Nilai konkret untuk ini akan diberikan nanti, selama runtime (langkah 5). Anda fokus pada pipeline untuk pelatihan, inferensi, validasi silang, dan pengujian kembali.
-
Langkah 4. Buat pipeline — Anda membuat infrastruktur yang mendasarinya, termasuk instans mesin AWS Step Functions status secara otomatis (hampir satu klik), dengan menggunakan AWS CloudFormation.
-
Langkah 5. Jalankan pipeline — Anda menjalankan pipeline yang ditentukan pada langkah 4. Anda juga menyiapkan metadata dan data atau lokasi data untuk mengisi nilai konkret untuk placeholder input/output yang Anda tentukan pada langkah 3. Ini termasuk skrip runtime yang ditentukan pada langkah 2 serta model hyperparameters.
-
Langkah 6. Perluas pipeline — Anda menerapkan proses integrasi berkelanjutan dan penerapan berkelanjutan (CI/CD), pelatihan ulang otomatis, inferensi terjadwal, dan ekstensi pipa yang serupa.
Diagram berikut menggambarkan langkah-langkah utama dalam proses ini.