Access, query, and join Amazon DynamoDB tables using Athena
Moinul Al-Mamun, Amazon Web Services
Summary
This pattern shows you how to set up a connection between Amazon Athena and Amazon DynamoDB by using the Amazon Athena DynamoDB connector. The connector uses an AWS Lambda function to query the data in DynamoDB. You don’t need to write any code to set up the connection. After the connection is established, you can quickly access and analyze DynamoDB tables by using Athena Federated Query to run SQL commands from Athena. You can also join one or more DynamoDB tables to each other or to other data sources, such as Amazon Redshift or Amazon Aurora.
Prerequisites and limitations
Prerequisites
An active AWS account with permissions to manage DynamoDB tables, Athena Data sources, Lambda, and AWS Identity and Access Management (IAM) roles
An Amazon Simple Storage Service (Amazon S3) bucket where Athena can store query results
An S3 bucket where the Athena DynamoDB Connector can save the data in the short term
An AWS Region that supports Athena engine version 2
IAM permissions to access Athena and the required S3 buckets
Amazon Athena DynamoDB Connector
, installed
Limitations
There is a cost for querying DynamoDB tables. Table sizes exceeding a few gigabytes (GBs) can incur a high cost. We recommend that you consider cost before performing any full table SCAN operation. For more information, see Amazon DynamoDB pricingSELECT * FROM table1 LIMIT 10). Also, before you perform a JOIN or GROUP BY query in a production environment, consider the size of your tables. If your tables are too large, consider alternative options such as migrating the table to Amazon S3
Architecture
The following diagram shows how a user can run a SQL query on a DynamoDB table from Athena.
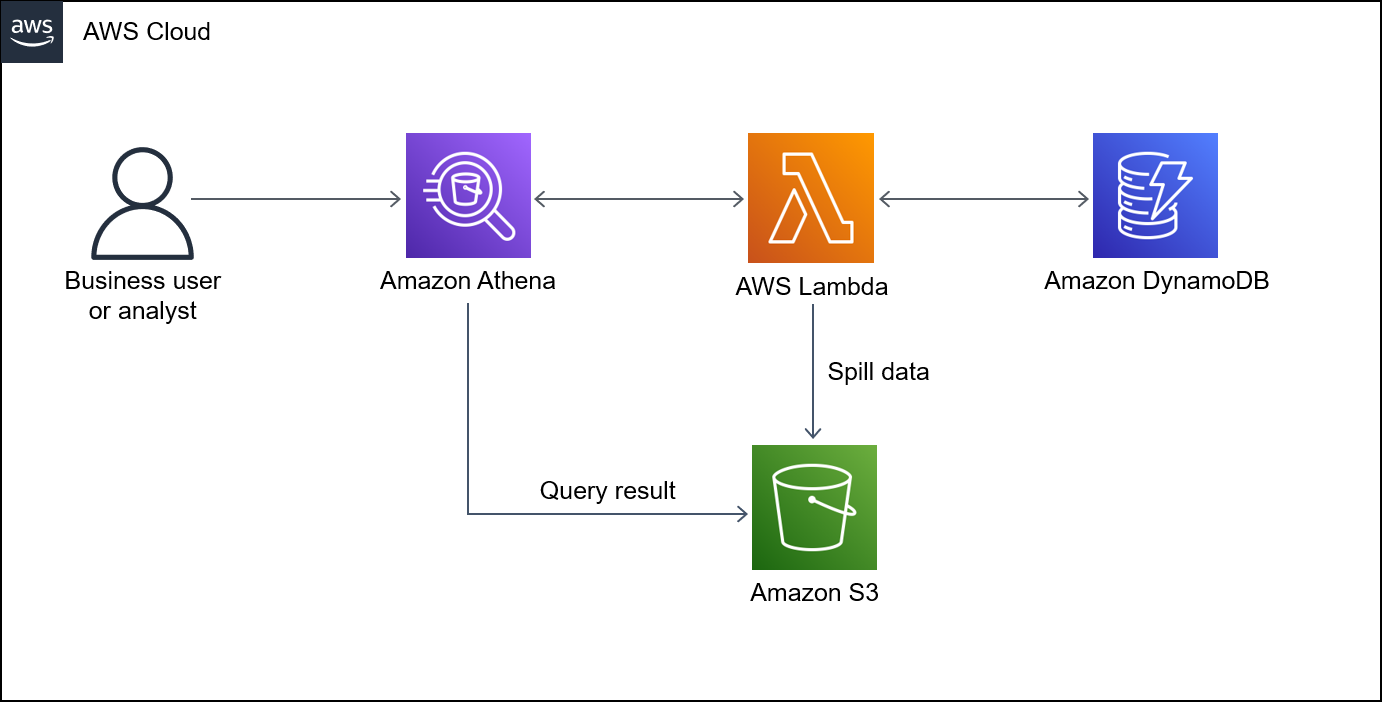
The diagram shows the following workflow:
To query a DynamoDB table, a user runs a SQL query from Athena.
Athena initiates a Lambda function.
The Lambda function queries the requested data in the DynamoDB table.
DynamoDB returns the requested data to the Lambda function. Then, the function transfers the query results to the user through Athena.
The Lambda function stores data in the S3 bucket.
Technology stack
Amazon Athena
Amazon DynamoDB
Amazon S3
AWS Lambda
Tools
Amazon Athena is an interactive query service that helps you analyze data directly in Amazon S3 by using standard SQL.
Amazon Athena DynamoDB Connector
is an AWS tool that enables Athena to connect with DynamoDB and access your tables by using SQL queries. Amazon DynamoDB is a fully managed NoSQL database service that provides fast, predictable, and scalable performance.
AWS Lambda is a compute service that helps you run code without needing to provision or manage servers. It runs your code only when needed and scales automatically, so you pay only for the compute time that you use.
Epics
| Task | Description | Skills required |
|---|---|---|
Create the first sample table. |
| Developer |
Insert sample data into the first table. |
| Developer |
Create the second sample table. |
| Developer |
Insert sample data into the second table. |
| Developer |
| Task | Description | Skills required |
|---|---|---|
Set up the data source connector. | Create a data source for DynamoDB, and then create a Lambda function to connect to that data source.
| Developer |
Verify that the Lambda function can access the S3 spill bucket. |
If you experience errors, see the Additional information section in this pattern for guidance. | Developer |
| Task | Description | Skills required |
|---|---|---|
Query the DynamoDB tables. |
| Developer |
Join the two DynamoDB tables. | DynamoDB is a NoSQL data store and doesn’t support the SQL join operation. Consequently, you must perform a join operation on two DynamoDB tables:
| Developer |
Related resources
Amazon Athena DynamoDB Connector
(AWS Labs) Query any data source with Amazon Athena’s new federated query
(AWS Big Data Blog) Athena engine version reference (Athena User Guide)
Simplify Amazon DynamoDB data extraction and analysis by using AWS Glue and Amazon Athena
(AWS Database Blog)
Additional information
If you run a query in Athena with spill_bucket in the {bucket_name}/folder_name/ format, then you can receive the following error message:
"GENERIC_USER_ERROR: Encountered an exception[java.lang.RuntimeException] from your LambdaFunction[arn:aws:lambda:us-east-1:xxxxxx:function:testdynamodb] executed in context[retrieving meta-data] with message[You do NOT own the spill bucket with the name: s3://amzn-s3-demo-bucket/athena_dynamodb_spill_data/] This query ran against the "default" database, unless qualified by the query. Please post the error message on our forum or contact customer support with Query Id: [query-id]"
To resolve this error, update the Lambda function’s environment variable spill_bucket to {bucket_name_only}, and then update the following Lambda IAM policy for bucket write access:
{ "Action": [ "s3:GetObject", "s3:ListBucket", "s3:GetBucketLocation", "s3:GetObjectVersion", "s3:PutObject", "s3:PutObjectAcl", "s3:GetLifecycleConfiguration", "s3:PutLifecycleConfiguration", "s3:DeleteObject" ], "Resource": [ "arn:aws:s3:::spill_bucket", "arn:aws:s3:::spill_bucket/*" ], "Effect": "Allow" }
Alternatively, you can remove the Athena data source connector that you created earlier, and recreate it by using only {bucket_name} for spill_bucket.
