Build a multi-tenant serverless architecture in Amazon OpenSearch Service
Tabby Ward and Nisha Gambhir, Amazon Web Services
Summary
Amazon OpenSearch Service is a managed service that makes it easy to deploy, operate, and scale Elasticsearch, which is a popular open-source search and analytics engine. OpenSearch Service provides free-text search as well as near real-time ingestion and dashboarding for streaming data such as logs and metrics.
Software as a service (SaaS) providers frequently use OpenSearch Service to address a broad range of use cases, such as gaining customer insights in a scalable and secure way while reducing complexity and downtime.
Using OpenSearch Service in a multi-tenant environment introduces a series of considerations that affect partitioning, isolation, deployment, and management of your SaaS solution. SaaS providers have to consider how to effectively scale their Elasticsearch clusters with continually shifting workloads. They also need to consider how tiering and noisy neighbor conditions could impact their partitioning model.
This pattern reviews the models that are used to represent and isolate tenant data with Elasticsearch constructs. In addition, the pattern focuses on a simple serverless reference architecture as an example to demonstrate indexing and searching using OpenSearch Service in a multi-tenant environment. It implements the pool data partitioning model, which shares the same index among all tenants while maintaining a tenant's data isolation. This pattern uses the following AWS services: Amazon API Gateway, AWS Lambda, Amazon Simple Storage Service (Amazon S3), and OpenSearch Service.
For more information about the pool model and other data partitioning models, see the Additional information section.
Prerequisites and limitations
Prerequisites
An active AWS account
AWS Command Line Interface (AWS CLI) version 2.x, installed and configured on macOS, Linux, or Windows
pip3
– The Python source code is provided as a .zip file to be deployed in a Lambda function. If you want to use the code locally or customize it, follow these steps to develop and recompile the source code: Generate the
requirements.txtfile by running the the following command in the same directory as the Python scripts:pip3 freeze > requirements.txtInstall the dependencies:
pip3 install -r requirements.txt
Limitations
This code runs in Python, and doesn’t currently support other programming languages.
The sample application doesn’t include AWS cross-Region or disaster recovery (DR) support.
This pattern is intended for demonstration purposes only. It is not intended to be used in a production environment.
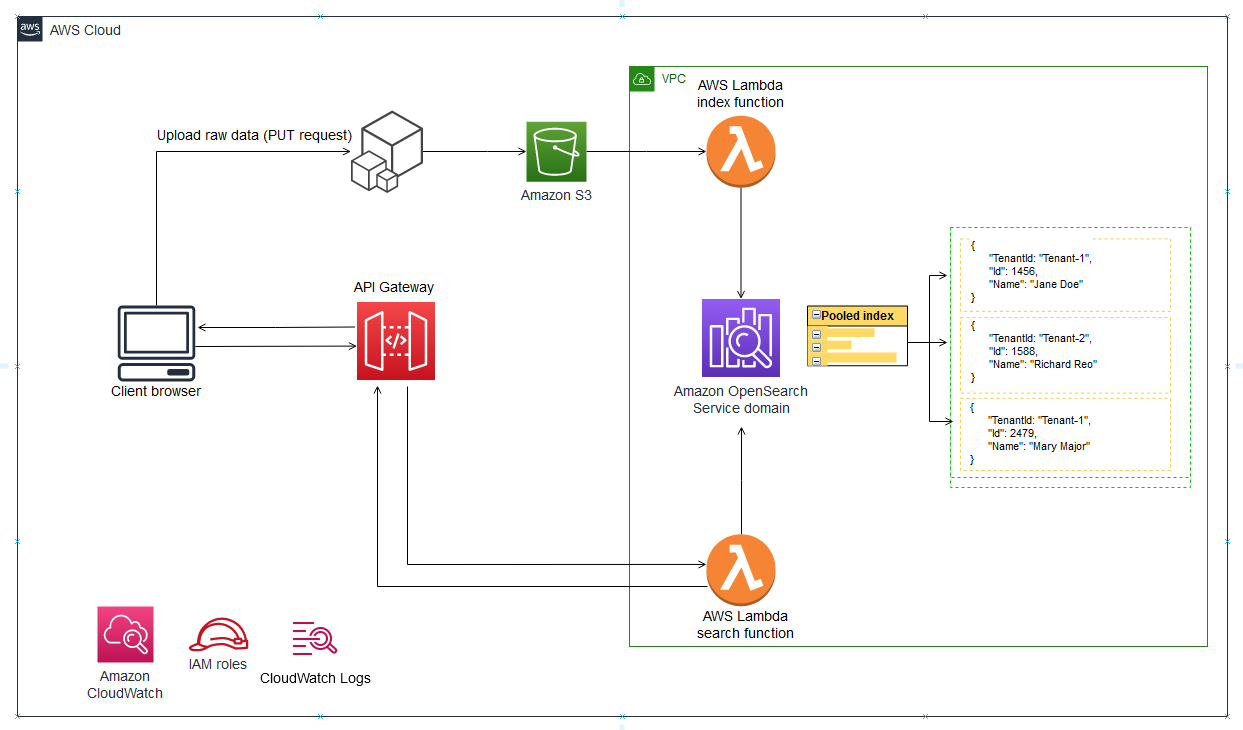
Architecture
The following diagram illustrates the high-level architecture of this pattern. The architecture includes the following:
Lambda to index and query the content
OpenSearch Service to perform search
API Gateway to provide an API interaction with the user
Amazon S3 to store raw (non-indexed) data
Amazon CloudWatch to monitor logs
AWS Identity and Access Management (IAM) to create tenant roles and policies
Automation and scale
For simplicity, the pattern uses AWS CLI to provision the infrastructure and to deploy the sample code. You can create an AWS CloudFormation template or AWS Cloud Development Kit (AWS CDK) scripts to automate the pattern.
Tools
AWS services
AWS CLI
is a unified tool for managing AWS services and resources by using commands in your command-line shell. Lambda
is a compute service that lets you run code without provisioning or managing servers. Lambda runs your code only when needed and scales automatically, from a few requests per day to thousands per second. API Gateway
is an AWS service for creating, publishing, maintaining, monitoring, and securing REST, HTTP, and WebSocket APIs at any scale. Amazon S3
is an object storage service that lets you store and retrieve any amount of information at any time, from anywhere on the web. OpenSearch Service
is a fully managed service that makes it easy for you to deploy, secure, and run Elasticsearch cost-effectively at scale.
Code
The attachment provides sample files for this pattern. These include:
index_lambda_package.zip– The Lambda function for indexing data in OpenSearch Service by using the pool model.search_lambda_package.zip– The Lambda function for searching for data in OpenSearch Service.Tenant-1-data– Sample raw (non-indexed) data for Tenant-1.Tenant-2-data– Sample raw (non-indexed) data for Tenant-2.
Important
The stories in this pattern include AWS CLI command examples that are formatted for Unix, Linux, and macOS. For Windows, replace the backslash (\) Unix continuation character at the end of each line with a caret (^).
Note
In AWS CLI commands, replace all values within the angle brackets (<>) with correct values.
Epics
| Task | Description | Skills required |
|---|---|---|
Create an S3 bucket. | Create an S3 bucket in your AWS Region. This bucket will hold the non-indexed tenant data for the sample application. Make sure that the S3 bucket's name is globally unique, because the namespace is shared by all AWS accounts. To create an S3 bucket, you can use the AWS CLI create-bucket
where | Cloud architect, Cloud administrator |
| Task | Description | Skills required |
|---|---|---|
Create an OpenSearch Service domain. | Run the AWS CLI create-elasticsearch-domain
The instance count is set to 1 because the domain is for testing purposes. You need to enable fine-grained access control by using the This command creates a master user name ( Because the domain is part of a virtual private cloud (VPC), you have to make sure that you can reach the Elasticsearch instance by specifying the access policy to use. For more information, see Launching your Amazon OpenSearch Service domains within a VPC in the AWS documentation. | Cloud architect, Cloud administrator |
Set up a bastion host. | Set up a Amazon Elastic Compute Cloud (Amazon EC2) Windows instance as a bastion host to access the Kibana console. The Elasticsearch security group must allow traffic from the Amazon EC2 security group. For instructions, see the blog post Controlling Network Access to EC2 Instances Using a Bastion Server When the bastion host has been set up, and you have the security group that is associated with the instance available, use the AWS CLI authorize-security-group-ingress
| Cloud architect, Cloud administrator |
| Task | Description | Skills required |
|---|---|---|
Create the Lambda execution role. | Run the AWS CLI create-role
where
| Cloud architect, Cloud administrator |
Attach managed policies to the Lambda role. | Run the AWS CLI attach-role-policy
| Cloud architect, Cloud administrator |
Create a policy to give the Lambda index function permission to read the S3 objects. | Run the AWS CLI create-policy
The file
| Cloud architect, Cloud administrator |
Attach the Amazon S3 permission policy to the Lambda execution role. | Run the AWS CLI attach-role-policy
where | Cloud architect, Cloud administrator |
Create the Lambda index function. | Run the AWS CLI create-function
| Cloud architect, Cloud administrator |
Allow Amazon S3 to call the Lambda index function. | Run the AWS CLI add-permission
| Cloud architect, Cloud administrator |
Add a Lambda trigger for the Amazon S3 event. | Run the AWS CLI put-bucket-notification-configuration
The file | Cloud architect, Cloud administrator |
| Task | Description | Skills required |
|---|---|---|
Create the Lambda execution role. | Run the AWS CLI create-role
where
| Cloud architect, Cloud administrator |
Attach managed policies to the Lambda role. | Run the AWS CLI attach-role-policy
| Cloud architect, Cloud administrator |
Create the Lambda search function. | Run the AWS CLI create-function
| Cloud architect, Cloud administrator |
| Task | Description | Skills required |
|---|---|---|
Create tenant IAM roles. | Run the AWS CLI create-role
The file
| Cloud architect, Cloud administrator |
Create a tenant IAM policy. | Run the AWS CLI create-policy
The file
| Cloud architect, Cloud administrator |
Attach the tenant IAM policy to the tenant roles. | Run the AWS CLI attach-role-policy
The policy ARN is from the output of the previous step. | Cloud architect, Cloud administrator |
Create an IAM policy to give Lambda permissions to assume role. | Run the AWS CLI create-policy
The file
For | Cloud architect, Cloud administrator |
Create an IAM policy to give the Lambda index role permission to access Amazon S3. | Run the AWS CLI create-policy
The file
| Cloud architect, Cloud administrator |
Attach the policy to the Lambda execution role. | Run the AWS CLI attach-role-policy
The policy ARN is from the output of the previous step. | Cloud architect, Cloud administrator |
| Task | Description | Skills required |
|---|---|---|
Create a REST API in API Gateway. | Run the AWS CLI create-rest-api
For the endpoint configuration type, you can specify Note the value of the | Cloud architect, Cloud administrator |
Create a resource for the search API. | The search API resource starts the Lambda search function with the resource name
| Cloud architect, Cloud administrator |
Create a GET method for the search API. | Run the AWS CLI put-method
For | Cloud architect, Cloud administrator |
Create a method response for the search API. | Run the AWS CLI put-method-response
For | Cloud architect, Cloud administrator |
Set up a proxy Lambda integration for the search API. | Run the AWS CLI put-integration
For | Cloud architect, Cloud administrator |
Grant API Gateway permission to call the Lambda search function. | Run the AWS CLI add-permission
Change the | Cloud architect, Cloud administrator |
Deploy the search API. | Run the AWS CLI create-deployment
If you update the API, you can use the same AWS CLI command to redeploy it to the same stage. | Cloud architect, Cloud administrator |
| Task | Description | Skills required |
|---|---|---|
Log in to the Kibana console. |
| Cloud architect, Cloud administrator |
Create and configure Kibana roles. | To provide data isolation and to make sure that one tenant cannot retrieve the data of another tenant, you need to use document security, which allows tenants to access only documents that contain their tenant ID.
| Cloud architect, Cloud administrator |
Map users to roles. |
We recommend that you automate the creation of the tenant and Kibana roles at the time of tenant onboarding. | Cloud architect, Cloud administrator |
Create the tenant-data index. | In the navigation pane, under Management, choose Dev Tools, and then run the following command. This command creates the
| Cloud architect, Cloud administrator |
| Task | Description | Skills required |
|---|---|---|
Create a VPC endpoint for Amazon S3. | Run the AWS CLI create-vpc-endpoint
For | Cloud architect, Cloud administrator |
Create a VPC endpoint for AWS STS. | Run the AWS CLI create-vpc-endpoint
For | Cloud architect, Cloud administrator |
| Task | Description | Skills required |
|---|---|---|
Update the Python files for the index and search functions. |
You can get the Elasticsearch endpoint from the Overview tab of the OpenSearch Service console. It has the format | Cloud architect, App developer |
Update the Lambda code. | Use the AWS CLI update-function-code
| Cloud architect, App developer |
Upload raw data to the S3 bucket. | Use the AWS CLI cp
The S3 bucket is set up to run the Lambda index function whenever data is uploaded so that the document is indexed in Elasticsearch. | Cloud architect, Cloud administrator |
Search data from the Kibana console. | On the Kibana console, run the following query:
This query displays all the documents indexed in Elasticsearch. In this case, you should see two separate documents for Tenant-1 and Tenant-2. | Cloud architect, Cloud administrator |
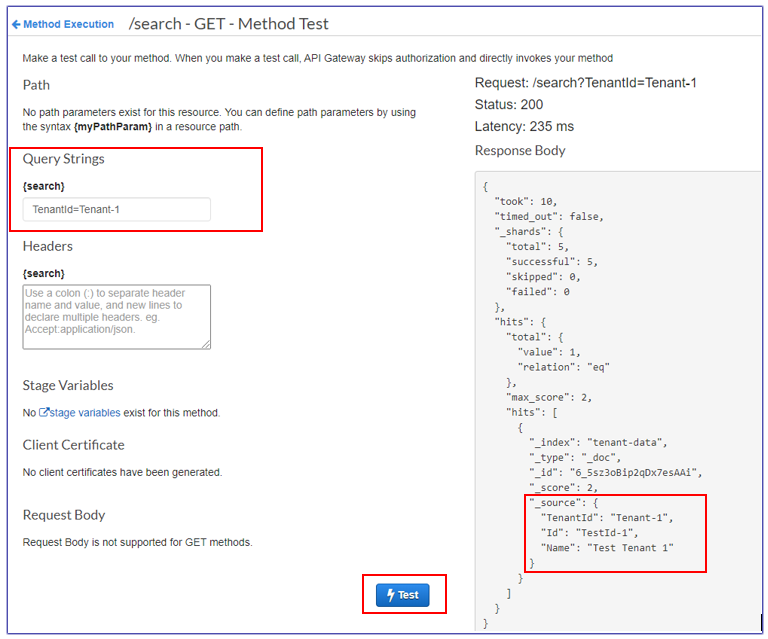
Test the search API from API Gateway. |
For screen illustrations, see the Additional information section. | Cloud architect, App developer |
Clean up resources. | Clean up all the resources you created to prevent additional charges to your account. | AWS DevOps, Cloud architect, Cloud administrator |
Related resources
Additional information
Data partitioning models
There are three common data partitioning models used in multi-tenant systems: silo, pool, and hybrid. The model you choose depends on the compliance, noisy neighbor, operations, and isolation needs of your environment.
Silo model
In the silo model, each tenant’s data is stored in a distinct storage area where there is no commingling of tenant data. You can use two approaches to implement the silo model with OpenSearch Service: domain per tenant and index per tenant.
Domain per tenant – You can use a separate OpenSearch Service domain (synonymous with an Elasticsearch cluster) per tenant. Placing each tenant in its own domain provides all the benefits associated with having data in a standalone construct. However, this approach introduces management and agility challenges. Its distributed nature makes it harder to aggregate and assess the operational health and activity of tenants. This is a costly option that requires each OpenSearch Service domain to have three master nodes and two data nodes for production workloads at the minimum.

Index per tenant – You can place tenant data in separate indexes within an OpenSearch Service cluster. With this approach, you use a tenant identifier when you create and name the index, by prepending the tenant identifier to the index name. The index per tenant approach helps you achieve your silo goals without introducing a completely separate cluster for each tenant. However, you might encounter memory pressure if the number of indexes grows, because this approach requires more shards, and the master node has to handle more allocation and rebalancing.

Isolation in the silo model – In the silo model, you use IAM policies to isolate the domains or indexes that hold each tenant’s data. These policies prevent one tenant from accessing another tenant’s data. To implement your silo isolation model, you can create a resource-based policy that controls access to your tenant resource. This is often a domain access policy that specifies which actions a principal can perform on the domain’s sub-resources, including Elasticsearch indexes and APIs. With IAM identity-based polices, you can specify allowed or denied actions on the domain, indexes, or APIs within OpenSearch Service. The Action element of an IAM policy describes the specific action or actions that are allowed or denied by the policy, and the Principal element specifies the affected accounts, users, or roles.
The following sample policy grants Tenant-1 full access (as specified by es:*) to the sub-resources on the tenant-1 domain only. The trailing /* in the Resource element indicates that this policy applies to the domain’s sub-resources, not to the domain itself. When this policy is in effect, tenants are not allowed to create a new domain or modify settings on an existing domain.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<aws-account-id>:user/Tenant-1" }, "Action": "es:*", "Resource": "arn:aws:es:<Region>:<account-id>:domain/tenant-1/*" } ] }
To implement the tenant per index silo model, you would need to modify this sample policy to further restrict Tenant-1 to the specified index or indexes, by specifying the index name. The following sample policy restricts Tenant-1 to the tenant-index-1 index.
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789012:user/Tenant-1" }, "Action": "es:*", "Resource": "arn:aws:es:<Region>:<account-id>:domain/test-domain/tenant-index-1/*" } ] }
Pool model
In the pool model, all tenant data is stored in an index within the same domain. The tenant identifier is included in the data (document) and used as the partition key, so you can determine which data belongs to which tenant. This model reduces the management overhead. Operating and managing the pooled index is easier and more efficient than managing multiple indexes. However, because tenant data is commingled within the same index, you lose the natural tenant isolation that the silo model provides. This approach might also degrade performance because of the noisy neighbor effect.

Tenant isolation in the pool model – In general, tenant isolation is challenging to implement in the pool model. The IAM mechanism used with the silo model doesn’t allow you to describe isolation based on the tenant ID stored in your document.
An alternative approach is to use the fine-grained access control (FGAC) support provided by the Open Distro for Elasticsearch. FGAC allows you to control permissions at an index, document, or field level. With each request, FGAC evaluates the user credentials and either authenticates the user or denies access. If FGAC authenticates the user, it fetches all roles mapped to that user and uses the complete set of permissions to determine how to handle the request.
To achieve the required isolation in the pooled model, you can use document-level security
{ "bool": { "must": { "match": { "tenantId": "Tenant-1" } } } }
Hybrid model
The hybrid model uses a combination of the silo and pool models in the same environment to offer unique experiences to each tenant tier (such as free, standard, and premium tiers). Each tier follows the same security profile that was used in the pool model.

Tenant isolation in the hybrid model – In the hybrid model, you follow the same security profile as in the pool model, where using the FGAC security model at the document level provided tenant isolation. Although this strategy simplifies cluster management and offers agility, it complicates other aspects of the architecture. For example, your code requires additional complexity to determine which model is associated with each tenant. You also have to ensure that single-tenant queries don’t saturate the entire domain and degrade the experience for other tenants.
Testing in API Gateway
Test window for Tenant-1 query
Test window for Tenant-2 query

Attachments
To access additional content that is associated with this document, unzip the following file: attachment.zip
