Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Kurangi jumlah pemindaian data
Untuk memulai, pertimbangkan untuk memuat hanya data yang Anda butuhkan. Anda dapat meningkatkan kinerja hanya dengan mengurangi jumlah data yang dimuat ke cluster Spark Anda untuk setiap sumber data. Untuk menilai apakah pendekatan ini tepat, gunakan metrik berikut.
CloudWatch metrik
Anda dapat melihat perkiraan ukuran baca dari Amazon S3 di ETL Data Movement (Bytes). Metrik ini menunjukkan jumlah byte yang dibaca dari Amazon S3 oleh semua pelaksana sejak laporan sebelumnya. Anda dapat menggunakannya untuk memantau pergerakan data ETL dari Amazon S3, dan Anda dapat membandingkan pembacaan dengan tingkat konsumsi dari sumber data eksternal.
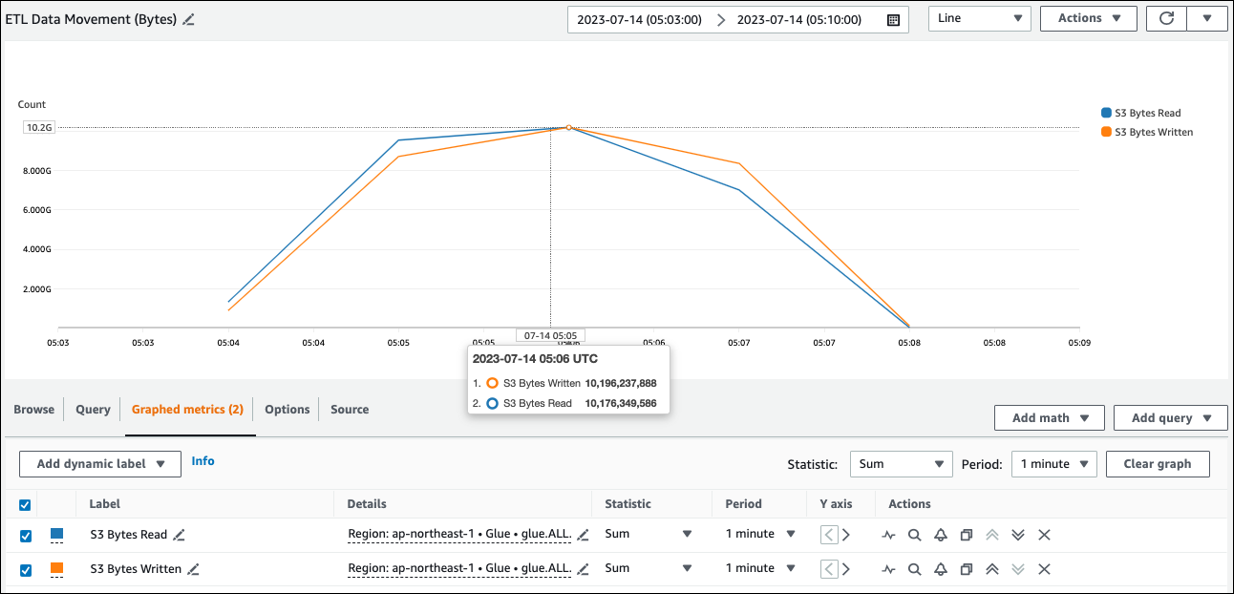
Jika Anda mengamati titik data S3 Bytes Read yang lebih besar dari yang Anda harapkan, pertimbangkan solusi berikut.
Spark UI
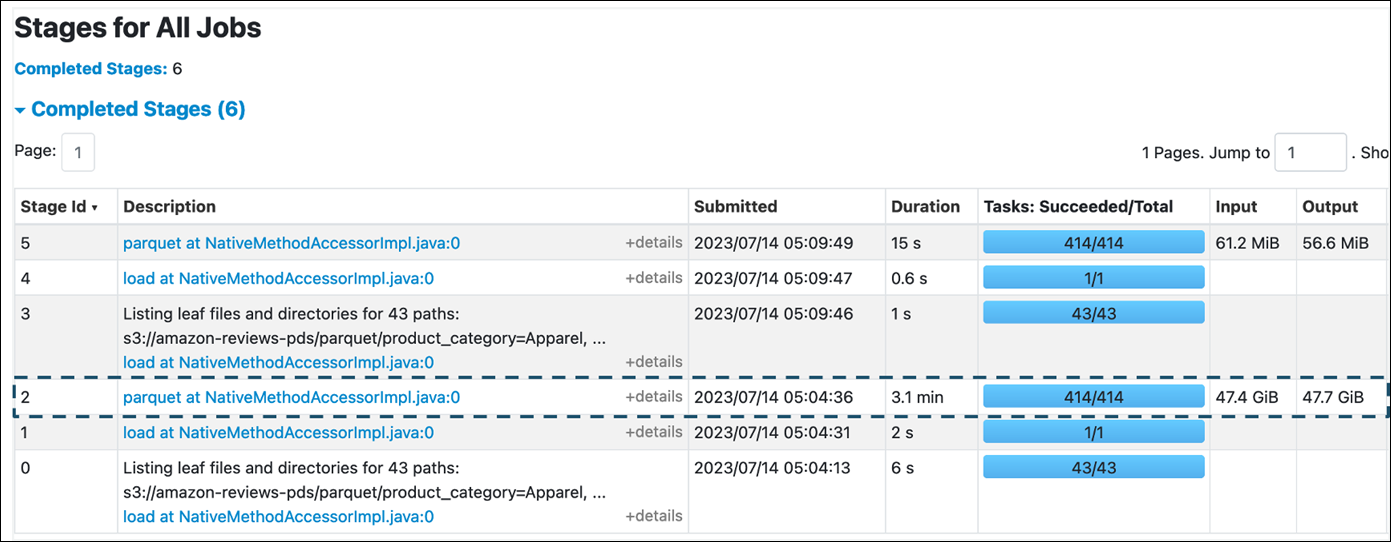
Pada tab Stage di AWS Glue for Spark UI, Anda dapat melihat ukuran Input dan Output. Pada contoh berikut, tahap 2 membaca input 47,4 GiB dan output 47,7 GiB, sedangkan tahap 5 membaca input 61,2 MiB dan output 56,6 MiB.
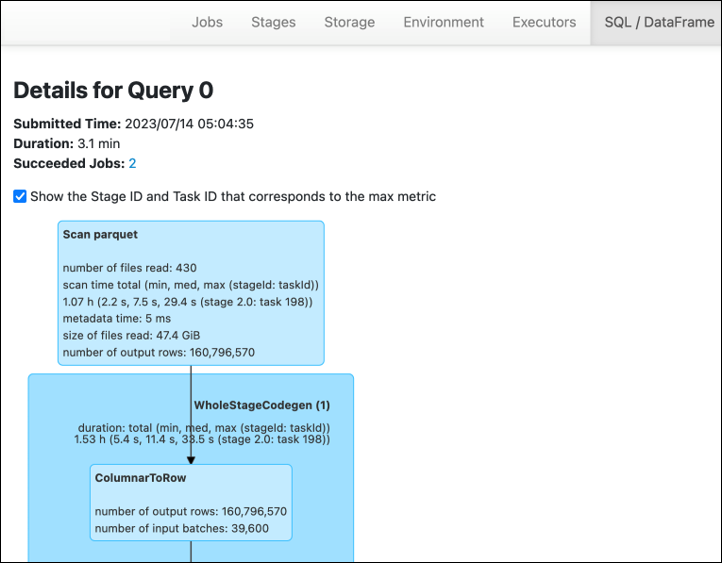
Saat Anda menggunakan Spark SQL atau DataFrame pendekatan dalam AWS Glue pekerjaan Anda, tab SQL/D ATAFrame menunjukkan lebih banyak statistik tentang tahapan ini. Dalam hal ini, tahap 2 menunjukkan jumlah file yang dibaca: 430, ukuran file yang dibaca: 47.4 GiB, dan jumlah baris output: 160.796.570.
Jika Anda mengamati bahwa ada perbedaan besar dalam ukuran antara data yang Anda baca dan data yang Anda gunakan, cobalah solusi berikut.
Amazon S3
Untuk mengurangi jumlah data yang dimuat ke pekerjaan Anda saat membaca dari Amazon S3, pertimbangkan ukuran file, kompresi, format file, dan tata letak file (partisi) untuk kumpulan data Anda. AWS Glue untuk pekerjaan Spark sering digunakan untuk ETL data mentah, tetapi untuk pemrosesan terdistribusi yang efisien, Anda perlu memeriksa fitur format sumber data Anda.
-
Ukuran file - Kami merekomendasikan untuk menjaga ukuran file input dan output dalam kisaran moderat (misalnya, 128 MB). File yang terlalu kecil dan file yang terlalu besar dapat menyebabkan masalah.
Sejumlah besar file kecil menyebabkan masalah berikut:
-
Beban I/O jaringan yang berat di Amazon S3 karena overhead yang diperlukan untuk membuat permintaan (
ListsepertiGet,,Headatau) untuk banyak objek (dibandingkan dengan beberapa objek yang menyimpan jumlah data yang sama). -
I/O berat dan beban pemrosesan pada driver Spark, yang akan menghasilkan banyak partisi dan tugas dan menyebabkan paralelisme yang berlebihan.
Di sisi lain, jika jenis file Anda tidak dapat dibagi (seperti gzip) dan file terlalu besar, aplikasi Spark harus menunggu hingga satu tugas selesai membaca seluruh file.
Untuk mengurangi paralelisme berlebihan yang terjadi ketika tugas Apache Spark dibuat untuk setiap file kecil, gunakan pengelompokan file untuk. DynamicFrames Pendekatan ini mengurangi kemungkinan pengecualian OOM dari driver Spark. Untuk mengkonfigurasi pengelompokan file, atur
groupSizeparametergroupFilesdan. Contoh kode berikut menggunakan AWS Glue DynamicFrame API dalam skrip ETL dengan parameter ini.dyf = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input-s3-path/"], 'recurse':True, 'groupFiles': 'inPartition', 'groupSize': '1048576'}, format="json") -
-
Kompresi — Jika objek S3 Anda berada dalam ratusan megabyte, pertimbangkan untuk mengompresnya. Ada berbagai format kompresi, yang secara luas dapat diklasifikasikan menjadi dua jenis:
-
Format kompresi yang tidak dapat dipisahkan seperti gzip mengharuskan seluruh file didekompresi oleh satu pekerja.
-
Format kompresi yang dapat dipisahkan, seperti bzip2 atau LZO (diindeks), memungkinkan dekompresi sebagian file, yang dapat diparalelkan.
Untuk Spark (dan mesin pemrosesan terdistribusi umum lainnya), Anda akan membagi file data sumber Anda menjadi potongan-potongan yang dapat diproses mesin Anda secara paralel. Unit-unit ini sering disebut sebagai split. Setelah data Anda dalam format yang dapat dipisahkan, AWS Glue pembaca yang dioptimalkan dapat mengambil split dari objek S3 dengan memberikan
Rangeopsi keGetObjectAPI untuk mengambil hanya blok tertentu. Pertimbangkan diagram berikut untuk melihat bagaimana ini akan bekerja dalam praktik.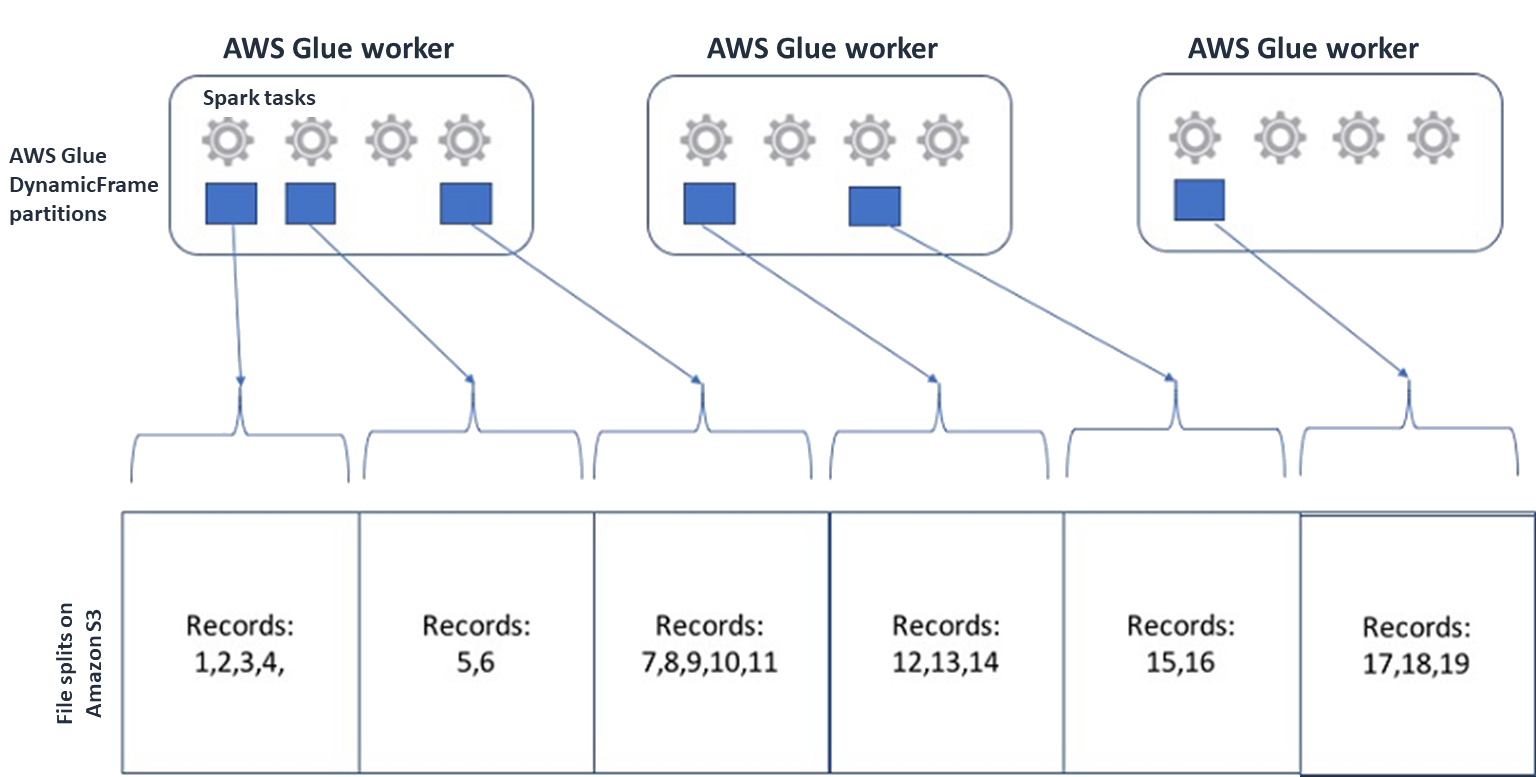
Data terkompresi dapat mempercepat aplikasi Anda secara signifikan, selama file berukuran optimal atau file dapat dibagi. Ukuran data yang lebih kecil mengurangi data yang dipindai dari Amazon S3 dan lalu lintas jaringan dari Amazon S3 ke cluster Spark Anda. Di sisi lain, lebih banyak CPU diperlukan untuk mengompres dan mendekompresi data. Jumlah skala komputasi yang diperlukan dengan rasio kompresi algoritma kompresi Anda. Pertimbangkan trade-off ini saat memilih format kompresi yang dapat dibagi.
catatan
Meskipun file gzip umumnya tidak dapat dibagi, Anda dapat mengompres blok parket individual dengan gzip, dan blok tersebut dapat diparalelkan.
-
-
Format file - Gunakan format kolumnar. Apache Parquet
dan Apache ORC adalah format data kolumnar yang populer. Parket dan ORC menyimpan data secara efisien dengan menggunakan kompresi berbasis kolom, pengkodean, dan kompresi setiap kolom berdasarkan tipe datanya. Untuk informasi lebih lanjut tentang pengkodean Parket, lihat Definisi pengkodean parket . File parket juga dapat dibagi. Format kolumnar mengelompokkan nilai berdasarkan kolom dan menyimpannya bersama dalam blok. Saat menggunakan format kolumnar, Anda dapat melewati blok data yang sesuai dengan kolom yang tidak Anda rencanakan untuk digunakan. Aplikasi Spark hanya dapat mengambil kolom yang Anda butuhkan. Umumnya, rasio kompresi yang lebih baik atau melewatkan blok data berarti membaca lebih sedikit byte dari Amazon S3, yang mengarah ke kinerja yang lebih baik. Kedua format juga mendukung pendekatan pushdown berikut untuk mengurangi I/O:
-
Proyeksi pushdown - Proyeksi pushdown adalah teknik untuk mengambil hanya kolom yang ditentukan dalam aplikasi Anda. Anda menentukan kolom dalam aplikasi Spark Anda, seperti yang ditunjukkan dalam contoh berikut:
-
DataFrame contoh:
df.select("star_rating") -
Contoh Spark SQL:
spark.sql("select start_rating from <table>")
-
-
Predikat pushdown — Predikat pushdown adalah teknik untuk memproses dan klausa secara efisien.
WHEREGROUP BYKedua format memiliki blok data yang mewakili nilai kolom. Setiap blok menyimpan statistik untuk blok, seperti nilai maksimum dan minimum. Spark dapat menggunakan statistik ini untuk menentukan apakah blok harus dibaca atau dilewati tergantung pada nilai filter yang digunakan dalam aplikasi. Untuk menggunakan fitur ini, tambahkan lebih banyak filter dalam kondisi, seperti yang ditunjukkan dalam contoh berikut sebagai berikut:-
DataFrame contoh:
df.select("star_rating").filter("star_rating < 2") -
Contoh Spark SQL:
spark.sql("select * from <table> where star_rating < 2")
-
-
-
Tata letak file - Dengan menyimpan data S3 Anda ke objek di jalur yang berbeda berdasarkan bagaimana data akan digunakan, Anda dapat secara efisien mengambil data yang relevan. Untuk informasi selengkapnya, lihat Mengatur objek menggunakan awalan dalam dokumentasi Amazon S3. AWS Glue mendukung penyimpanan kunci dan nilai ke awalan Amazon S3 dalam format
key=value, mempartisi data Anda dengan jalur Amazon S3. Dengan mempartisi data Anda, Anda dapat membatasi jumlah data yang dipindai oleh setiap aplikasi analitik hilir, meningkatkan kinerja dan mengurangi biaya. Untuk informasi selengkapnya, lihat Mengelola partisi untuk keluaran ETL di. AWS GluePartisi membagi tabel Anda menjadi beberapa bagian dan menyimpan data terkait dalam file yang dikelompokkan berdasarkan nilai kolom seperti tahun, bulan, dan hari, seperti yang ditunjukkan pada contoh berikut.
# Partitioning by /YYYY/MM/DD s3://<YourBucket>/year=2023/month=03/day=31/0000.gz s3://<YourBucket>/year=2023/month=03/day=01/0000.gz s3://<YourBucket>/year=2023/month=03/day=02/0000.gz s3://<YourBucket>/year=2023/month=03/day=03/0000.gz ...Anda dapat menentukan partisi untuk kumpulan data Anda dengan memodelkannya dengan tabel di. AWS Glue Data Catalog Anda kemudian dapat membatasi jumlah pemindaian data dengan menggunakan pemangkasan partisi sebagai berikut:
-
Untuk AWS Glue DynamicFrame, atur
push_down_predicate(ataucatalogPartitionPredicate).dyf = Glue_context.create_dynamic_frame.from_catalog( database=src_database_name, table_name=src_table_name, push_down_predicate = "year='2023' and month ='03'", ) -
Untuk Spark DataFrame, atur jalur tetap untuk memangkas partisi.
df = spark.read.format("json").load("s3://<YourBucket>/year=2023/month=03/*/*.gz") -
Untuk Spark SQL, Anda dapat mengatur klausa where untuk memangkas partisi dari Katalog Data.
df = spark.sql("SELECT * FROM <Table> WHERE year= '2023' and month = '03'") -
Untuk mempartisi berdasarkan tanggal saat menulis data Anda AWS Glue, Anda mengatur PartitionKeys DynamicFrame di atau partitionBy (
) dengan informasi tanggal DataFrame di kolom Anda sebagai berikut. -
DynamicFrame
glue_context.write_dynamic_frame_from_options( frame= dyf, connection_type='s3',format='parquet' connection_options= { 'partitionKeys': ["year", "month", "day"], 'path': 's3://<YourBucket>/<Prefix>/' } ) -
DataFrame
df.write.mode('append')\ .partitionBy('year','month','day')\ .parquet('s3://<YourBucket>/<Prefix>/')
Hal ini dapat meningkatkan kinerja konsumen dari data output Anda.
Jika Anda tidak memiliki akses untuk mengubah pipeline yang membuat kumpulan data input Anda, partisi bukanlah pilihan. Sebagai gantinya, Anda dapat mengecualikan jalur S3 yang tidak dibutuhkan dengan menggunakan pola glob. Tetapkan pengecualian saat membaca. DynamicFrame Misalnya, kode berikut tidak termasuk hari dalam bulan 01 hingga 09, pada tahun 2023.
dyf = glueContext.create_dynamic_frame.from_catalog( database=db, table_name=table, additional_options = { "exclusions":"[\"**year=2023/month=0[1-9]/**\"]" }, transformation_ctx='dyf' )Anda juga dapat mengatur pengecualian dalam properti tabel di Katalog Data:
-
Kunci:
exclusions -
Nilai:
["**year=2023/month=0[1-9]/**"]
-
-
-
Terlalu banyak partisi Amazon S3 - Hindari mempartisi data Amazon S3 Anda pada kolom yang berisi berbagai nilai, seperti kolom ID dengan ribuan nilai. Ini secara substansional dapat meningkatkan jumlah partisi dalam bucket Anda, karena jumlah partisi yang mungkin adalah produk dari semua bidang yang telah Anda partisi. Terlalu banyak partisi dapat menyebabkan hal berikut:
-
Peningkatan latensi untuk mengambil metadata partisi dari Katalog Data
-
Peningkatan jumlah file kecil, yang membutuhkan lebih banyak permintaan API Amazon S3 (
List,Get, dan)Head
Misalnya, ketika Anda menetapkan tipe tanggal di
partitionByataupartitionKeys, partisi tingkat tanggal seperti baik untuk banyakyyyy/mm/ddkasus penggunaan. Namun,yyyy/mm/dd/<ID>mungkin menghasilkan begitu banyak partisi sehingga akan berdampak negatif pada kinerja secara keseluruhan.Di sisi lain, beberapa kasus penggunaan, seperti aplikasi pemrosesan waktu nyata, memerlukan banyak partisi seperti
yyyy/mm/dd/hh. Jika kasus penggunaan Anda memerlukan partisi besar, pertimbangkan untuk menggunakan indeks AWS Glue partisi untuk mengurangi latensi untuk mengambil metadata partisi dari Katalog Data. -
Database dan JDBC
Untuk mengurangi pemindaian data saat mengambil informasi dari database, Anda dapat menentukan where predikat (atau klausa) dalam kueri SQL. Database yang tidak menyediakan antarmuka SQL akan menyediakan mekanisme mereka sendiri untuk query atau penyaringan.
Saat menggunakan koneksi Java Database Connectivity (JDBC), berikan kueri pilih dengan where klausa untuk parameter berikut:
-
Untuk DynamicFrame, gunakan opsi SampleQuery. Saat menggunakan
create_dynamic_frame.from_catalog, konfigurasikanadditional_optionsargumen sebagai berikut.query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_catalog( database = db, table_name = table, additional_options={ "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True }, transformation_ctx = "datasource0" )Kapan
using create_dynamic_frame.from_options, konfigurasikanconnection_optionsargumen sebagai berikut.query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_options( connection_type = connection, connection_options={ "url": url, "user": user, "password": password, "dbtable": table, "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True } ) -
Untuk DataFrame, gunakan opsi kueri
. query = "SELECT * FROM <TableName> where id = 'XX'" jdbcDF = spark.read \ .format('jdbc') \ .option('url', url) \ .option('user', user) \ .option('password', pwd) \ .option('query', query) \ .load() -
dyf = glueContext.create_dynamic_frame.from_catalog( database = "redshift-dc-database-name", table_name = "redshift-table-name", redshift_tmp_dir = args["temp-s3-dir"], additional_options = {"aws_iam_role": "arn:aws:iam::role-account-id:role/rs-role-name"} ) -
Untuk database lain, lihat dokumentasi untuk database tersebut.
AWS Glue pilihan
-
Untuk menghindari pemindaian penuh untuk semua pekerjaan yang berjalan terus menerus, dan hanya memproses data yang tidak ada selama pekerjaan terakhir dijalankan, aktifkan bookmark pekerjaan.
-
Untuk membatasi jumlah data input yang akan diproses, aktifkan eksekusi terbatas dengan bookmark pekerjaan. Ini membantu mengurangi jumlah data yang dipindai untuk setiap pekerjaan yang dijalankan.
