Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Metrik dan validasi
Panduan ini menunjukkan metrik dan teknik validasi yang dapat Anda gunakan untuk mengukur kinerja model pembelajaran mesin. Amazon SageMaker Autopilot menghasilkan metrik yang mengukur kualitas prediktif kandidat model pembelajaran mesin. Metrik yang dihitung untuk kandidat ditentukan menggunakan array MetricDatumtipe.
Metrik Autopilot
Daftar berikut berisi nama-nama metrik yang saat ini tersedia untuk mengukur kinerja model dalam Autopilot.
catatan
Autopilot mendukung bobot sampel. Untuk mempelajari lebih lanjut tentang bobot sampel dan metrik objektif yang tersedia, lihat. Metrik tertimbang autopilot
Berikut ini adalah metrik yang tersedia.
Accuracy-
Rasio jumlah item yang diklasifikasikan dengan benar dengan jumlah total item yang diklasifikasikan (benar dan salah). Ini digunakan untuk klasifikasi biner dan multiclass. Akurasi mengukur seberapa dekat nilai kelas yang diprediksi dengan nilai aktual. Nilai untuk metrik akurasi bervariasi antara nol (0) dan satu (1). Nilai 1 menunjukkan akurasi sempurna, dan 0 menunjukkan ketidakakuratan sempurna.
AUC-
Metrik area under the curve (AUC) digunakan untuk membandingkan dan mengevaluasi klasifikasi biner dengan algoritma yang mengembalikan probabilitas, seperti regresi logistik. Untuk memetakan probabilitas ke dalam klasifikasi, ini dibandingkan dengan nilai ambang batas.
Kurva yang relevan adalah kurva karakteristik operasi penerima. Kurva memplot tingkat positif sebenarnya (TPR) prediksi (atau recall) terhadap tingkat positif palsu (FPR) sebagai fungsi dari nilai ambang batas, di atasnya prediksi dianggap positif. Meningkatkan ambang menghasilkan lebih sedikit positif palsu, tetapi lebih banyak negatif palsu.
AUC adalah area di bawah kurva karakteristik operasi penerima ini. Oleh karena itu, AUC memberikan ukuran agregat dari kinerja model di semua ambang batas klasifikasi yang mungkin. Skor AUC bervariasi antara 0 dan 1. Skor 1 menunjukkan akurasi sempurna, dan skor satu setengah (0,5) menunjukkan bahwa prediksi tidak lebih baik daripada pengklasifikasi acak.
BalancedAccuracy-
BalancedAccuracyadalah metrik yang mengukur rasio prediksi akurat untuk semua prediksi. Rasio ini dihitung setelah menormalkan positif sejati (TP) dan negatif sejati (TN) dengan jumlah total nilai positif (P) dan negatif (N). Ini digunakan dalam klasifikasi biner dan multiclass dan didefinisikan sebagai berikut: 0,5* ((TP/P)+(TN/N)), dengan nilai mulai dari 0 hingga 1.BalancedAccuracymemberikan ukuran akurasi yang lebih baik ketika jumlah positif atau negatif sangat berbeda satu sama lain dalam kumpulan data yang tidak seimbang, seperti ketika hanya 1% email adalah spam. F1-
F1Skor adalah rata-rata harmonik dari presisi dan ingatan, didefinisikan sebagai berikut: F1 = 2 * (presisi * recall)/(presisi + recall). Ini digunakan untuk klasifikasi biner ke dalam kelas yang secara tradisional disebut sebagai positif dan negatif. Prediksi dikatakan benar ketika mereka cocok dengan kelas mereka yang sebenarnya (benar), dan salah ketika tidak.Presisi adalah rasio prediksi positif sejati untuk semua prediksi positif, dan itu termasuk positif palsu dalam kumpulan data. Presisi mengukur kualitas prediksi ketika memprediksi kelas positif.
Ingat (atau sensitivitas) adalah rasio prediksi positif sejati untuk semua contoh positif aktual. Ingat mengukur seberapa lengkap model memprediksi anggota kelas yang sebenarnya dalam kumpulan data.
Skor F1 bervariasi antara 0 dan 1. Skor 1 menunjukkan kinerja terbaik, dan 0 menunjukkan yang terburuk.
F1macro-
F1macroSkor tersebut menerapkan penilaian F1 untuk masalah klasifikasi multiclass. Hal ini dilakukan dengan menghitung presisi dan recall, dan kemudian mengambil mean harmonik mereka untuk menghitung skor F1 untuk setiap kelas. Terakhir,F1macrorata-rata skor individu untuk mendapatkan skor.F1macroF1macroSkor bervariasi antara 0 dan 1. Skor 1 menunjukkan kinerja terbaik, dan 0 menunjukkan yang terburuk. InferenceLatency-
Latensi inferensi adalah perkiraan jumlah waktu antara membuat permintaan untuk prediksi model untuk menerimanya dari titik akhir waktu nyata tempat model digunakan. Metrik ini diukur dalam hitungan detik dan hanya tersedia dalam mode ansambel.
LogLoss-
Loss log, juga dikenal sebagai cross-entropy loss, adalah metrik yang digunakan untuk mengevaluasi kualitas output probabilitas, bukan output itu sendiri. Ini digunakan dalam klasifikasi biner dan multiclass dan dalam jaring saraf. Ini juga merupakan fungsi biaya untuk regresi logistik. Kehilangan log adalah metrik penting untuk menunjukkan kapan model membuat prediksi yang salah dengan probabilitas tinggi. Nilai berkisar dari 0 hingga tak terbatas. Nilai 0 mewakili model yang memprediksi data dengan sempurna.
MAE-
Kesalahan absolut rata-rata (MAE) adalah ukuran seberapa berbeda nilai prediksi dan aktual, ketika dirata-ratakan pada semua nilai. MAE biasanya digunakan dalam analisis regresi untuk memahami kesalahan prediksi model. Jika ada regresi linier, MAE mewakili jarak rata-rata dari garis yang diprediksi ke nilai aktual. MAE didefinisikan sebagai jumlah kesalahan absolut dibagi dengan jumlah pengamatan. Nilai berkisar dari 0 hingga tak terhingga, dengan angka yang lebih kecil menunjukkan kecocokan model yang lebih baik dengan data.
MSE-
Mean squared error (MSE) adalah rata-rata perbedaan kuadrat antara nilai prediksi dan aktual. Ini digunakan untuk regresi. Nilai MSE selalu positif. Semakin baik model dalam memprediksi nilai aktual, semakin kecil nilai MSE.
Precision-
Presisi mengukur seberapa baik suatu algoritma memprediksi positif sejati (TP) dari semua hal positif yang diidentifikasi. Ini didefinisikan sebagai berikut: Presisi = TP/ (TP+FP), dengan nilai mulai dari nol (0) hingga satu (1), dan digunakan dalam klasifikasi biner. Presisi adalah metrik penting ketika biaya positif palsu tinggi. Misalnya, biaya positif palsu sangat tinggi jika sistem keselamatan pesawat secara keliru dianggap aman untuk terbang. Positif palsu (FP) mencerminkan prediksi positif yang sebenarnya negatif dalam data.
PrecisionMacro-
Makro presisi menghitung presisi untuk masalah klasifikasi multiclass. Ini dilakukan dengan menghitung presisi untuk setiap kelas dan skor rata-rata untuk mendapatkan presisi untuk beberapa kelas.
PrecisionMacroSkor berkisar dari nol (0) hingga satu (1). Skor yang lebih tinggi mencerminkan kemampuan model untuk memprediksi positif sejati (TP) dari semua positif yang diidentifikasi, dirata-ratakan di beberapa kelas. R2-
R 2, juga dikenal sebagai koefisien determinasi, digunakan dalam regresi untuk mengukur seberapa banyak model dapat menjelaskan varians variabel dependen. Nilai berkisar dari satu (1) ke negatif (-1). Angka yang lebih tinggi menunjukkan fraksi yang lebih tinggi dari variabilitas yang dijelaskan.
R2nilai mendekati nol (0) menunjukkan bahwa sangat sedikit variabel dependen yang dapat dijelaskan oleh model. Nilai negatif menunjukkan kecocokan yang buruk dan bahwa model tersebut dikalahkan oleh fungsi konstan. Untuk regresi linier, ini adalah garis horizontal. Recall-
Ingat mengukur seberapa baik algoritme memprediksi dengan benar semua positif sejati (TP) dalam kumpulan data. Positif sejati adalah prediksi positif yang juga merupakan nilai positif aktual dalam data. Recall didefinisikan sebagai berikut: Recall = TP/ (TP+FN), dengan nilai mulai dari 0 hingga 1. Skor yang lebih tinggi mencerminkan kemampuan model yang lebih baik untuk memprediksi positif sejati (TP) dalam data. Ini digunakan dalam klasifikasi biner.
Ingat penting ketika menguji kanker karena digunakan untuk menemukan semua hal positif yang sebenarnya. Positif palsu (FP) mencerminkan prediksi positif yang sebenarnya negatif dalam data. Seringkali tidak cukup untuk mengukur hanya ingatan, karena memprediksi setiap output sebagai positif sejati menghasilkan skor ingatan yang sempurna.
RecallMacro-
RecallMacroMenghitung penarikan kembali untuk masalah klasifikasi multiclass dengan menghitung recall untuk setiap kelas dan skor rata-rata untuk mendapatkan recall untuk beberapa kelas.RecallMacroskor berkisar dari 0 hingga 1. Skor yang lebih tinggi mencerminkan kemampuan model untuk memprediksi positif sejati (TP) dalam kumpulan data, sedangkan positif sejati mencerminkan prediksi positif yang juga merupakan nilai positif aktual dalam data. Seringkali tidak cukup untuk mengukur hanya ingatan, karena memprediksi setiap output sebagai positif sejati akan menghasilkan skor ingatan yang sempurna. RMSE-
Kesalahan kuadrat rata-rata akar (RMSE) mengukur akar kuadrat dari perbedaan kuadrat antara nilai prediksi dan aktual, dan dirata-ratakan pada semua nilai. Ini digunakan dalam analisis regresi untuk memahami kesalahan prediksi model. Ini adalah metrik penting untuk menunjukkan adanya kesalahan model besar dan outlier. Nilai berkisar dari nol (0) hingga tak terhingga, dengan angka yang lebih kecil menunjukkan kecocokan model yang lebih baik dengan data. RMSE tergantung pada skala, dan tidak boleh digunakan untuk membandingkan kumpulan data dengan ukuran yang berbeda.
Metrik yang dihitung secara otomatis untuk kandidat model ditentukan oleh jenis masalah yang ditangani.
Lihat dokumentasi referensi Amazon SageMaker API untuk daftar metrik yang tersedia yang didukung oleh Autopilot.
Metrik tertimbang autopilot
catatan
Autopilot mendukung bobot sampel dalam mode ansambel hanya untuk semua metrik yang tersedia dengan pengecualian dan. Balanced Accuracy InferenceLatency BalanceAccuracydilengkapi dengan skema pembobotannya sendiri untuk kumpulan data yang tidak seimbang yang tidak memerlukan bobot sampel. InferenceLatencytidak mendukung bobot sampel. Baik objektif Balanced Accuracy maupun InferenceLatency metrik mengabaikan bobot sampel yang ada saat melatih dan mengevaluasi model.
Pengguna dapat menambahkan kolom bobot sampel ke data mereka untuk memastikan bahwa setiap pengamatan yang digunakan untuk melatih model pembelajaran mesin diberi bobot yang sesuai dengan persepsi pentingnya model. Ini sangat berguna dalam skenario di mana pengamatan dalam kumpulan data memiliki berbagai tingkat kepentingan, atau di mana kumpulan data berisi jumlah sampel yang tidak proporsional dari satu kelas dibandingkan dengan yang lain. Menetapkan bobot untuk setiap pengamatan berdasarkan pentingnya atau kepentingan yang lebih besar bagi kelas minoritas dapat membantu kinerja keseluruhan model, atau memastikan bahwa model tidak bias terhadap kelas mayoritas.
Untuk informasi tentang cara meneruskan bobot sampel saat membuat eksperimen di UI Studio Classic, lihat Langkah 7 di Membuat eksperimen Autopilot menggunakan Studio Classic.
Validasi silang di Autopilot
Validasi silang digunakan untuk mengurangi overfitting dan bias dalam pemilihan model. Hal ini juga digunakan untuk menilai seberapa baik model dapat memprediksi nilai-nilai dari dataset validasi yang tak terlihat, jika dataset validasi diambil dari populasi yang sama. Metode ini sangat penting saat melatih kumpulan data yang memiliki jumlah instance pelatihan terbatas.
Autopilot menggunakan validasi silang untuk membangun model dalam optimasi hyperparameter (HPO) dan mode pelatihan ensemble. Langkah pertama dalam proses validasi silang Autopilot adalah membagi data menjadi k-folds.
Pemisahan K-lipat
K-fold splitting adalah metode yang memisahkan dataset pelatihan input menjadi beberapa kumpulan data pelatihan dan validasi. Dataset dibagi menjadi sub-sampel k berukuran sama yang disebut lipatan. Model kemudian dilatih pada k-1 lipatan dan diuji terhadap lipatan k th yang tersisa, yang merupakan kumpulan data validasi. Proses ini diulang k kali menggunakan kumpulan data yang berbeda untuk validasi.
Gambar berikut menggambarkan pemisahan k-fold dengan k = 4 lipatan. Setiap lipatan direpresentasikan sebagai baris. Kotak berwarna gelap mewakili bagian dari data yang digunakan dalam pelatihan. Kotak berwarna terang yang tersisa menunjukkan kumpulan data validasi.

Autopilot menggunakan validasi silang k-fold untuk mode optimasi hiperparameter (HPO) dan mode ansambel.
Anda dapat menerapkan model Autopilot yang dibuat menggunakan validasi silang seperti yang Anda lakukan dengan model Autopilot atau AI lainnya. SageMaker
Modus HPO
Validasi silang K-fold menggunakan metode pemisahan k-fold untuk validasi silang. Dalam mode HPO, Autopilot secara otomatis mengimplementasikan validasi silang k-fold untuk kumpulan data kecil dengan 50.000 instans pelatihan atau lebih sedikit. Melakukan validasi silang sangat penting ketika melatih kumpulan data kecil karena melindungi terhadap overfitting dan bias seleksi.
Mode HPO menggunakan nilai k 5 pada masing-masing algoritma kandidat yang digunakan untuk memodelkan dataset. Beberapa model dilatih pada split yang berbeda, dan model disimpan secara terpisah. Ketika pelatihan selesai, metrik validasi untuk masing-masing model dirata-ratakan untuk menghasilkan metrik estimasi tunggal. Terakhir, Autopilot menggabungkan model dari uji coba dengan metrik validasi terbaik ke dalam model ansambel. Autopilot menggunakan model ansambel ini untuk membuat prediksi.
Metrik validasi untuk model yang dilatih oleh Autopilot disajikan sebagai metrik objektif di papan peringkat model. Autopilot menggunakan metrik validasi default untuk setiap jenis masalah yang ditangani, kecuali jika Anda menentukan sebaliknya. Untuk daftar semua metrik yang digunakan Autopilot, lihat. Metrik Autopilot
Misalnya, dataset Perumahan Boston
Validasi silang dapat meningkatkan waktu pelatihan rata-rata 20%. Waktu pelatihan juga dapat meningkat secara signifikan untuk kumpulan data yang kompleks.
catatan
Dalam mode HPO, Anda dapat melihat metrik pelatihan dan validasi dari setiap lipatan di Log Anda. /aws/sagemaker/TrainingJobs CloudWatch Untuk informasi selengkapnya tentang CloudWatch Log, lihatCloudWatch Log untuk Amazon SageMaker AI.
Mode ansambel
catatan
Autopilot mendukung bobot sampel dalam mode ansambel. Untuk daftar metrik yang tersedia yang mendukung bobot sampel, lihat. Metrik Autopilot
Dalam mode ansambel, validasi silang dilakukan terlepas dari ukuran kumpulan data. Pelanggan dapat menyediakan kumpulan data validasi dan rasio pemisahan data khusus mereka sendiri, atau membiarkan Autopilot membagi kumpulan data secara otomatis menjadi rasio pemisahan 80-20%. Data pelatihan kemudian dibagi menjadi k -lipatan untuk validasi silang, di mana nilai k ditentukan oleh mesin. AutoGluon Sebuah ansambel terdiri dari beberapa model pembelajaran mesin, di mana setiap model dikenal sebagai model dasar. Model dasar tunggal dilatih pada (k-1) lipatan dan membuat out-of-fold prediksi pada lipatan yang tersisa. Proses ini diulang untuk semua k lipatan, dan prediksi out-of-fold (OOF) digabungkan untuk membentuk satu set prediksi. Semua model dasar dalam ansambel mengikuti proses yang sama untuk menghasilkan prediksi OOF.
Gambar berikut menggambarkan validasi k-fold dengan k = 4 lipatan. Setiap lipatan direpresentasikan sebagai baris. Kotak berwarna gelap mewakili bagian dari data yang digunakan dalam pelatihan. Kotak berwarna terang yang tersisa menunjukkan kumpulan data validasi.
Di bagian atas gambar, di setiap lipatan, model dasar pertama membuat prediksi pada kumpulan data validasi setelah pelatihan pada kumpulan data pelatihan. Pada setiap lipatan berikutnya, kumpulan data mengubah peran. Dataset yang sebelumnya digunakan untuk pelatihan sekarang digunakan untuk validasi, dan ini juga berlaku secara terbalik. Pada akhir k lipatan, semua prediksi digabungkan untuk membentuk satu set prediksi yang disebut prediksi (OOF). out-of-fold Proses ini diulang untuk setiap model n dasar.
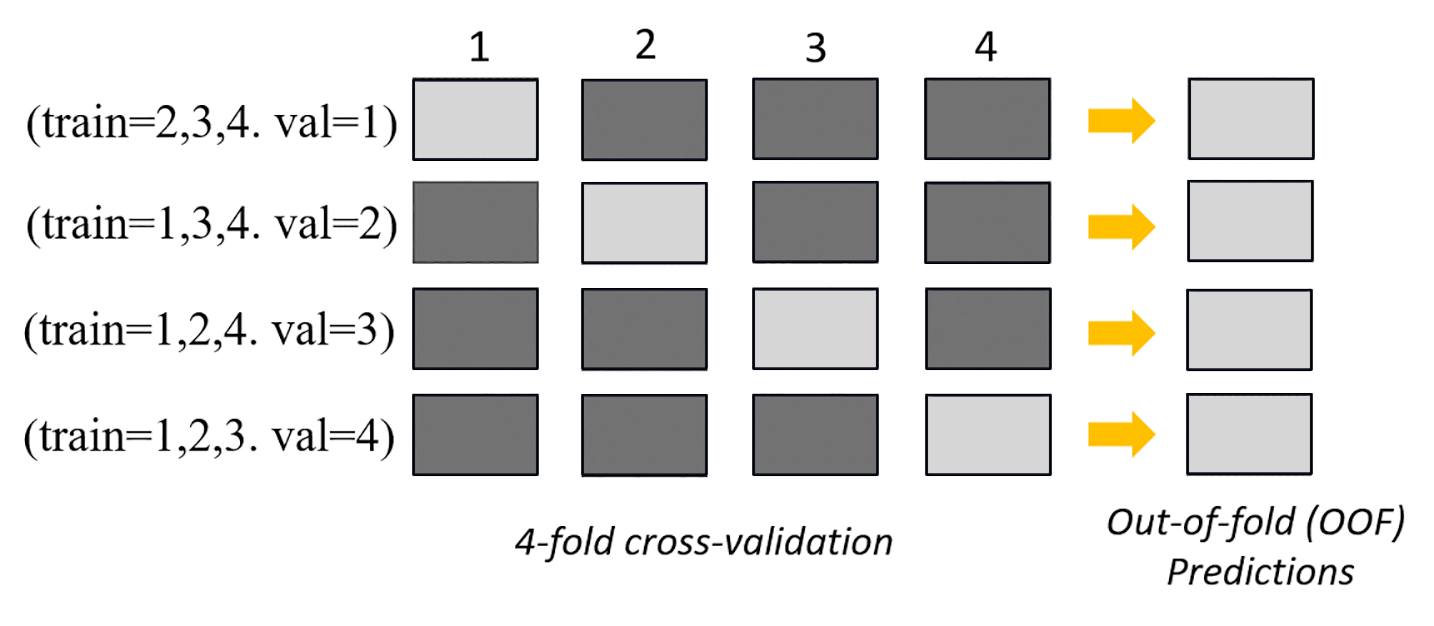
Prediksi OOF untuk setiap model dasar kemudian digunakan sebagai fitur untuk melatih model susun. Model susun mempelajari bobot penting untuk setiap model dasar. Bobot ini digunakan untuk menggabungkan prediksi OOF untuk membentuk prediksi akhir. Kinerja pada dataset validasi menentukan basis atau model susun mana yang terbaik, dan model ini dikembalikan sebagai model akhir.
Dalam mode ansambel, Anda dapat memberikan kumpulan data validasi Anda sendiri atau membiarkan Autopilot membagi kumpulan data input secara otomatis menjadi kumpulan data 80% dan kumpulan data validasi 20%. Data pelatihan kemudian dibagi menjadi k -lipatan untuk validasi silang dan menghasilkan prediksi OOF dan model dasar untuk setiap lipatan.
Prediksi OOF ini digunakan sebagai fitur untuk melatih model susun, yang secara bersamaan mempelajari bobot untuk setiap model dasar. Bobot ini digunakan untuk menggabungkan prediksi OOF untuk membentuk prediksi akhir. Kumpulan data validasi untuk setiap lipatan digunakan untuk penyetelan hiperparameter dari semua model dasar dan model susun. Kinerja pada kumpulan data validasi menentukan model basis atau susun mana yang merupakan model terbaik, dan model ini dikembalikan sebagai model akhir.
