Terjemahan disediakan oleh mesin penerjemah. Jika konten terjemahan yang diberikan bertentangan dengan versi bahasa Inggris aslinya, utamakan versi bahasa Inggris.
Kegagalan abu-abu
Kegagalan abu-abu didefinisikan oleh karakteristikobservabilitas diferensial
Observabilitas diferensial
Beban kerja yang Anda operasikan biasanya memiliki dependensi. Misalnya, ini bisa menjadiAWSlayanan cloud yang Anda gunakan untuk membangun beban kerja Anda atau penyedia identitas pihak ketiga (IDP) yang Anda gunakan untuk federasi. Dependensi tersebut hampir selalu menerapkan pengamatan mereka sendiri, merekam metrik tentang kesalahan, ketersediaan, dan latensi antara lain yang dihasilkan oleh penggunaan pelanggan mereka. Ketika ambang batas dilintasi untuk salah satu metrik ini, ketergantungan biasanya mengambil beberapa tindakan untuk memperbaikinya.
Dependensi ini biasanya memiliki banyak konsumen layanan mereka. Konsumen juga menerapkan observabilitas mereka sendiri dan merekam metrik dan log tentang interaksi mereka dengan dependensinya, merekam hal-hal seperti berapa banyak latensi yang ada dalam pembacaan disk, berapa banyak permintaan API yang gagal, atau berapa lama kueri database.
Interaksi dan pengukuran ini digambarkan dalam model abstrak pada gambar berikut.

Model abstrak untuk memahami kegagalan abu-abu
Pertama, kita memilikisistem, yang merupakan ketergantungan untuk konsumen App 1, App 2, dan App 3 dalam skenario ini. Sistem ini memiliki detektor kegagalan yang memeriksa metrik yang dibuat dari proses bisnis inti. Ini juga memiliki mekanisme respons kegagalan untuk mengurangi atau memperbaiki masalah yang diamati oleh detektor kegagalan. Sistem melihat latensi rata-rata keseluruhan 53 ms dan telah menetapkan ambang batas untuk memanggil mekanisme respons kegagalan ketika latensi rata-rata melebihi 60 ms. App 1, App 2, dan App 3 juga membuat pengamatan mereka sendiri tentang interaksi mereka dengan sistem, merekam latensi rata-rata 50 ms, 53 ms, dan 56 ms masing-masing.
Observabilitas diferensial adalah situasi di mana salah satu konsumen sistem mendeteksi bahwa sistem tidak sehat, tetapi pemantauan sistem sendiri tidak mendeteksi masalah atau dampaknya tidak melewati ambang alarm. Mari kita bayangkan bahwa App 1 mulai mengalami latensi rata-rata 70 ms, bukan 50ms. Aplikasi 2 dan Aplikasi 3 tidak melihat perubahan latensi rata-rata mereka. Ini meningkatkan latensi rata-rata sistem yang mendasarinya menjadi 59,66 ms, tetapi ini tidak melewati ambang latensi untuk mengaktifkan mekanisme respons kegagalan. Namun, App 1 melihat peningkatan latensi 40%. Hal ini dapat memengaruhi ketersediaannya dengan melampaui batas waktu klien yang dikonfigurasi untuk Aplikasi 1, atau dapat menyebabkan dampak cascading dalam rantai interaksi yang lebih lama. Dari perspektif App 1, sistem yang mendasarinya tergantung pada tidak sehat, tetapi dari perspektif sistem itu sendiri juga App 2 dan App 3, sistemnya sehat. Gambar berikut merangkum perspektif yang berbeda ini.
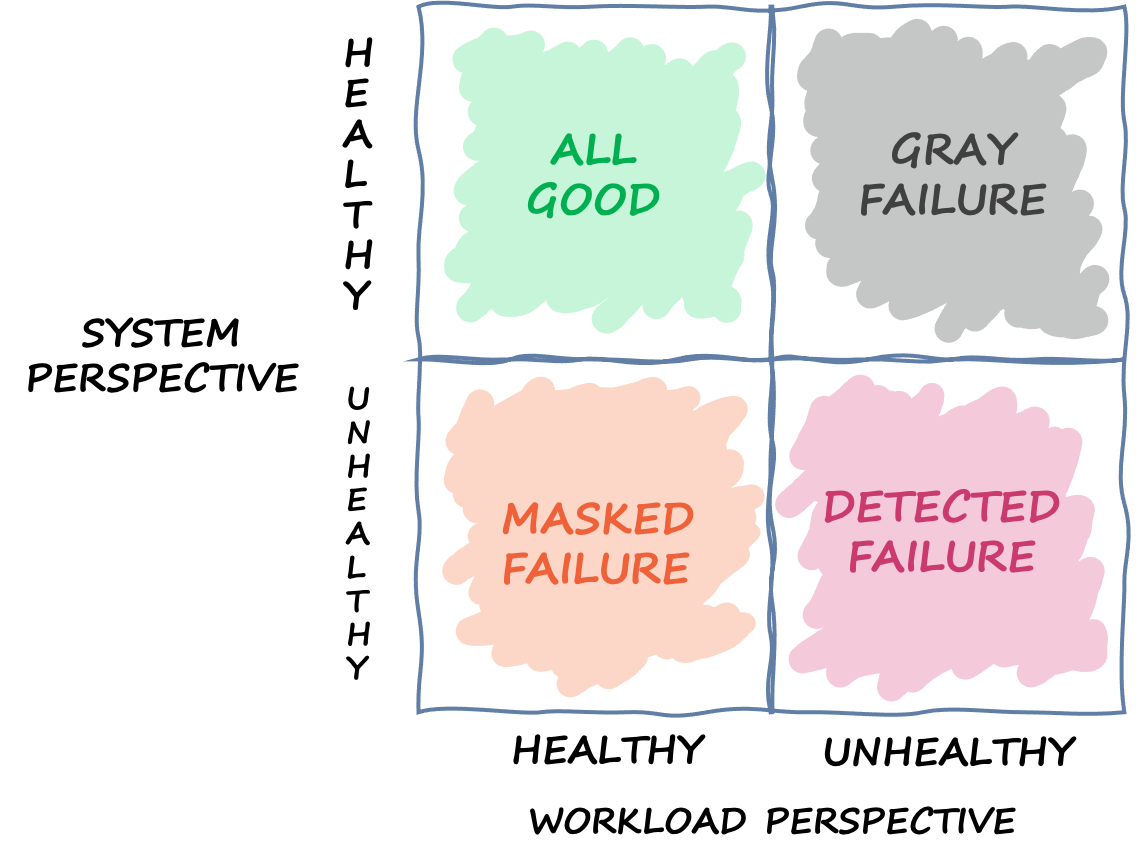
Kuadran yang mendefinisikan berbagai negara suatu sistem dapat didasarkan pada perspektif yang berbeda
Kegagalan juga dapat melintasi kuadran ini. Suatu peristiwa bisa dimulai sebagai kegagalan abu-abu, kemudian menjadi kegagalan yang terdeteksi, kemudian pindah ke kegagalan bertopeng, dan kemudian mungkin kembali ke kegagalan abu-abu. Tidak ada siklus yang ditentukan, dan hampir selalu ada kemungkinan kegagalan kambuh sampai akar penyebabnya ditangani.
Kesimpulan yang kami ambil dari ini adalah bahwa beban kerja tidak selalu dapat mengandalkan sistem yang mendasarinya untuk mendeteksi dan mengurangi kegagalan. Tidak peduli seberapa canggih dan tangguh sistem yang mendasarinya, akan selalu ada kemungkinan bahwa kegagalan bisa tidak terdeteksi atau tetap berada di bawah ambang reaksi. Konsumen dari sistem itu, seperti App 1, perlu diperlengkapi untuk mendeteksi dan mengurangi dampak yang disebabkan oleh kegagalan abu-abu. Ini membutuhkan pengamatan bangunan dan mekanisme pemulihan untuk situasi ini.
Contoh kegagalan abu-abu
Kegagalan abu-abu dapat berdampak pada sistem Multi-AZ diAWS. Misalnya, ambil armadaAmazon EC2

Kegagalan abu-abu yang memengaruhi koneksi database dari instans di Availability Zone 1
Dalam contoh ini, Amazon EC2 melihat instans di Availability Zone 1 sehat karena terus lolospemeriksaan status sistem dan instance. Amazon EC2 Auto Scaling juga tidak mendeteksi dampak langsung ke Availability Zone apa pun, dan terus berlanjutmeluncurkan kapasitas di Availability Zone yang dikonfigurasi. Network Load Balancer (NLB) juga melihat instance di belakangnya sehat seperti pemeriksaan kesehatan Route 53 yang dilakukan terhadap titik akhir NLB. Demikian pula, Amazon Relational Database Service (Amazon RDS) melihat klaster database sebagai sehat dan tidakmemicu failover otomatis. Kami memiliki banyak layanan berbeda yang semuanya melihat layanan dan sumber daya mereka sehat, tetapi beban kerja mendeteksi kegagalan yang memengaruhi ketersediaannya. Ini adalah kegagalan abu-abu.
Menanggapi kegagalan abu-abu
Ketika Anda mengalami kegagalan abu-abu diAWSlingkungan, Anda umumnya memiliki tiga pilihan yang tersedia:
-
Jangan lakukan apa pun dan tunggu sampai kerusakan berakhir.
-
Jika gangguan diisolasi ke Availability Zone tunggal, evakuasi Availability Zone tersebut.
-
Failover ke yang lainWilayah AWSdan menggunakan manfaatAWSIsolasi regional untuk mengurangi dampak.
BanyakAWSpelanggan baik-baik saja dengan opsi satu untuk sebagian besar beban kerja mereka. Mereka menerima memiliki kemungkinan diperpanjangTujuan Waktu Pemulihan (RTO)dengan tradeoff bahwa mereka tidak harus membangun observabilitas tambahan atau solusi ketahanan. Pelanggan lain memilih untuk menerapkan opsi ketiga,Pemulihan Bencana Multi Wilayah
Pertama, membangun dan mengoperasikan arsitektur multi-wilayah dapat menjadi usaha yang menantang, kompleks, dan berpotensi mahal. Arsitektur Multi-Region memerlukan pertimbangan yang cermatStrategi DRAnda pilih. Mungkin tidak layak secara fiskal untuk menerapkan solusi DR aktif multi-wilayah hanya untuk menangani gangguan zonal, sementara strategi pencadangan dan pemulihan mungkin tidak memenuhi persyaratan ketahanan Anda. Selain itu, failovers multi-wilayah harus terus dipraktekkan dalam produksi sehingga Anda yakin mereka akan bekerja bila diperlukan. Ini semua membutuhkan banyak waktu dan sumber daya khusus untuk membangun, mengoperasikan, dan menguji.
Kedua, replikasi data diWilayah AWSmemakaiAWSlayanan hari ini semua dilakukan asynchronous. Replikasi asinkron dapat mengakibatkan kehilangan data. Ini berarti bahwa selama failover Regional, ada peluang untuk sejumlah kehilangan data dan inkonsistensi. Toleransi Anda terhadap jumlah kehilangan data didefinisikan sebagai AndaTujuan Titik Pemulihan (RPO). Pelanggan, untuk siapa konsistensi data yang kuat adalah persyaratan, harus membangun sistem rekonsiliasi untuk memperbaiki masalah konsistensi ini ketika Wilayah utama tersedia lagi. Atau, mereka harus membangun replikasi sinkron atau sistem penulisan ganda mereka sendiri, yang dapat berdampak signifikan pada latensi respons, biaya, dan kompleksitas. Mereka juga membuat Region sekunder ketergantungan keras untuk setiap transaksi, yang berpotensi mengurangi ketersediaan sistem secara keseluruhan.
Akhirnya, untuk banyak beban kerja yang menggunakan pendekatan aktif/siaga, ada jumlah waktu yang tidak nol yang diperlukan untuk melakukan failover ke Wilayah lain. Portofolio beban kerja Anda mungkin perlu diturunkan di Wilayah utama dalam urutan tertentu, perlu menguras koneksi, atau menghentikan proses tertentu. Kemudian, layanan mungkin perlu dibawa kembali dalam urutan tertentu. Sumber daya baru mungkin juga perlu disediakan atau memerlukan waktu untuk lulus pemeriksaan kesehatan yang diperlukan sebelum dibawa ke layanan. Proses failover ini dapat dialami sebagai periode tidak tersedianya lengkap. Inilah yang menjadi perhatian RTO.
Di dalam Wilayah, banyakAWSlayanan menawarkan persistensi data yang sangat konsisten. Penggunaan penerapan Multi-AZ Amazon RDSreplikasi sinkron. Layanan Penyimpanan Sederhana Amazon
Mengevakuasi Availability Zone dapat memiliki RTO yang lebih rendah daripada strategi Multi-region, karena infrastruktur dan sumber daya Anda sudah disediakan di Availability Zone. Alih-alih perlu hati-hati memesan layanan yang diturunkan dan dicadangkan, atau menguras koneksi, arsitektur Multi-AZ dapat terus beroperasi secara statis ketika Availability Zone terganggu. Alih-alih periode ketidaktersediaan lengkap yang dapat terjadi selama failover Regional, selama evakuasi Availability Zone, banyak sistem mungkin hanya melihat sedikit degradasi, karena pekerjaan digeser ke Availability Zone yang tersisa. Jika sistem telah dirancang untuk menjadistabil secara statis
Ada kemungkinan bahwa gangguan pada Availability Zone tunggal berdampak pada satu atau lebihAWS Layanan regionalselain beban kerja Anda. Jika Anda mengamati dampak Regional, Anda harus memperlakukan acara tersebut sebagai gangguan layanan Regional meskipun sumber dampaknya berasal dari Availability Zone tunggal. Mengevakuasi Availability Zone tidak akan mengurangi jenis masalah ini. Gunakan rencana respons yang Anda miliki untuk menanggapi gangguan layanan Regional saat ini terjadi.
Sisa dokumen ini berfokus pada opsi kedua, mengevakuasi Availability Zone, sebagai cara untuk mencapai RTO dan RPO yang lebih rendah untuk kegagalan abu-abu single-AZ. Pola-pola ini dapat membantu mencapai nilai dan efisiensi arsitektur Multi-AZ yang lebih baik dan, untuk sebagian besar kelas beban kerja, dapat mengurangi kebutuhan untuk membuat arsitektur Multi-wilayah untuk menangani jenis acara ini.
