Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Sentimento mirato
Il sentimento mirato fornisce una comprensione dettagliata dei sentimenti associati a entità specifiche (come marchi o prodotti) nei documenti di input.
La differenza tra il sentimento mirato e il sentimento è il livello di granularità dei dati di output. L'analisi del sentiment determina il sentiment dominante per ogni documento di input, ma non fornisce dati per ulteriori analisi. L'analisi mirata del sentiment determina il sentimento a livello di entità per entità specifiche in ogni documento di input. È possibile analizzare i dati di output per determinare i prodotti e i servizi specifici che ottengono feedback positivi o negativi.
Ad esempio, in una serie di recensioni di ristoranti, un cliente fornisce la seguente recensione: «I tacos erano deliziosi e il personale era cordiale». L'analisi di questa recensione produce i seguenti risultati:
L'analisi del sentiment determina se il sentimento complessivo di ogni recensione di un ristorante è positivo, negativo, neutro o misto. In questo esempio, il sentimento generale è positivo.
L'analisi mirata del sentiment determina il sentiment per le entità e gli attributi del ristorante menzionati dai clienti nelle recensioni. In questo esempio, il cliente ha espresso commenti positivi su «tacos» e «staff».
Targeted Sentiment fornisce i seguenti risultati per ogni lavoro di analisi:
Identità delle entità menzionate nei documenti.
-
Classificazione del tipo di entità per ogni entità menzionata.
Il sentimento e un punteggio di sentimento per ciascuna menzione dell'entità.
Gruppi di menzioni (gruppi di co-riferimento) che corrispondono a una singola entità.
Puoi utilizzare la console o l'API per eseguire analisi mirate del sentiment. La console e l'API supportano l'analisi in tempo reale e l'analisi asincrona per un sentiment mirato.
Amazon Comprehend supporta il sentiment mirato per i documenti in lingua inglese.
Per ulteriori informazioni sul sentimento mirato, incluso un tutorial, consulta Extract granular sentiment in text with Amazon Comprehend Targeted Sentiment nel blog
Argomenti
Tipi di entità
Il sentimento mirato identifica i seguenti tipi di entità. Assegna il tipo di entità OTHER se l'entità non appartiene a nessun'altra categoria. Ogni entità menzionata nel file di output include il tipo di entità, ad esempio"Type": "PERSON".
| Tipo di entità | Definizione |
|---|---|
| PERSONA | Gli esempi includono individui, gruppi di persone, soprannomi, personaggi immaginari e nomi di animali. |
| LOCATION | Luoghi geografici come paesi, città, stati, indirizzi, formazioni geologiche, specchi d'acqua, monumenti naturali e luoghi astronomici. |
| ORGANIZZAZIONE | Gli esempi includono governi, aziende, squadre sportive e religioni. |
| SERVIZIO, STRUTTURA | Edifici, aeroporti, autostrade, ponti e altre strutture artificiali permanenti e miglioramenti immobiliari. |
| MARCA | Organizzazione, gruppo o produttore di uno specifico articolo o linea di prodotti commerciale. |
| OGGETTO_COMMERCIALE | Qualsiasi articolo acquistabile o acquisibile non generico, compresi i veicoli e i prodotti di grandi dimensioni per i quali è stato prodotto un solo articolo. |
| FILM | Un film o un programma televisivo. Entity potrebbe essere il nome completo, un soprannome o un sottotitolo. |
| MUSICA | Una canzone, completa o parziale. Inoltre, raccolte di singole creazioni musicali, come un album o un'antologia. |
| LIBRO | Un libro, pubblicato professionalmente o autopubblicato. |
| SOFTWARE | Un prodotto software rilasciato ufficialmente. |
| GIOCO | Un gioco, ad esempio videogiochi, giochi da tavolo, giochi comuni o sport. |
| TITOLO_PERSONALE | Titoli ufficiali e onorificenze come Presidente, PhD o Dr. |
| EVENT | Gli esempi includono festival, concerti, elezioni, guerre, conferenze ed eventi promozionali. |
| DATE | Qualsiasi riferimento a una data o a un'ora, specifica o generale, assoluta o relativa. |
| QUANTITÀ | Tutte le misurazioni con le relative unità (valuta, percentuale, numero, byte, ecc.). |
| ATTRIBUTE | Un attributo, una caratteristica o un tratto di un'entità, ad esempio la «qualità» di un prodotto, il «prezzo» di un telefono o la «velocità» di una CPU. |
| OTHER | Entità che non appartengono a nessuna delle altre categorie. |
Gruppo di co-riferimento
Targeted Sentiment identifica i gruppi di co-riferimento in ogni documento di input. Un gruppo di co-riferimento è un gruppo di menzioni in un documento che corrispondono a un'entità del mondo reale.
Esempio
Nel seguente esempio di recensione di un cliente, «spa» è l'entità con il tipo di entità. FACILITY L'entità ha due menzioni aggiuntive come pronome («it»).

Organizzazione dei file di output
Il lavoro mirato di analisi del sentiment crea un file di output di testo JSON. Il file contiene un oggetto JSON per ciascuno dei documenti di input. Ogni oggetto JSON contiene i seguenti campi:
-
Entità: una serie di entità trovate nel documento.
-
File: il nome del file del documento di input.
-
Riga: se il file di input è un documento per riga, Entities contiene il numero di riga del documento nel file.
Nota
Se Targeted Sentiment non identifica alcuna entità nel testo di input, restituisce un array vuoto come risultato Entities.
L'esempio seguente mostra Entities per un file di input con tre righe di input. Il formato di input è ONE_DOC_PER_LINE, quindi ogni riga di input è un documento.
{ "Entities":[
{entityA},
{entityB},
{entityC}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 0
}
{ "Entities": [
{entityD},
{entityE}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 1
}
{ "Entities": [
{entityF},
{entityG}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 2
}Un'entità nell'array Entities include un raggruppamento logico (chiamato gruppo di co-riferimento) delle menzioni di entità rilevate nel documento. Ogni entità ha la seguente struttura generale:
{"DescriptiveMentionIndex": [0],
"Mentions": [
{mentionD},
{mentionE}
]
} Un'entità contiene i seguenti campi:
-
Menzioni: una serie di menzioni dell'entità nel documento. L'array rappresenta un gruppo di co-riferimento. Consulta Gruppo di co-riferimento per un esempio. L'ordine delle menzioni nell'array Mentions è l'ordine della loro posizione (offset) nel documento. Ogni menzione include il punteggio del sentiment e il punteggio di gruppo per quella menzione. Il punteggio di gruppo indica il livello di fiducia che queste menzioni appartengano alla stessa entità.
-
DescriptiveMentionIndex— Uno o più indici nell'array Mentions che forniscono il nome migliore per il gruppo di entità. Ad esempio, un'entità potrebbe avere tre menzioni con valori di testo «ABC Hotel», «ABC Hotel» e «it». Il nome migliore è «ABC Hotel», che ha un DescriptiveMentionIndex valore di [0,1].
Ogni menzione include i seguenti campi
-
BeginOffset— L'offset nel testo del documento in cui inizia la menzione.
-
EndOffset— L'offset rispetto al testo del documento in cui termina la menzione.
GroupScore— La fiducia che tutte le entità menzionate nel gruppo si riferiscano alla stessa entità.
Testo: il testo del documento che identifica l'entità.
Tipo: il tipo di entità. Amazon Comprehend supporta diversi tipi di entità.
Punteggio: modello di fiducia che l'entità sia pertinente. L'intervallo di valori va da zero a uno, dove uno rappresenta la massima confidenza.
MentionSentiment— Contiene il sentiment e il punteggio di sentiment per la menzione.
Sentimento: il sentimento della menzione. I valori includono: POSITIVO, NEUTRO, NEGATIVO e MISTO.
SentimentScore— Fornisce un modello di fiducia per ciascuno dei sentimenti possibili. L'intervallo di valori è compreso tra zero e uno corrisponde alla massima confidenza.
I valori Sentiment hanno il seguente significato:
-
Positivo: l'entità menzionata esprime un sentimento positivo.
-
Negativo: la menzione dell'entità esprime un sentimento negativo.
-
Mista: la menzione dell'entità esprime sentimenti sia positivi che negativi.
-
Neutro: la menzione dell'entità non esprime sentimenti positivi o negativi.
Nell'esempio seguente, un'entità ha una sola menzione nel documento di input, quindi DescriptiveMentionIndex è zero (la prima menzione nell'array Mentions). L'entità identificata è una PERSONA con il nome «I» Il punteggio del sentiment è neutro.
{"Entities":[ { "DescriptiveMentionIndex": [0], "Mentions": [ { "BeginOffset": 0, "EndOffset": 1, "Score": 0.999997, "GroupScore": 1, "Text": "I", "Type": "PERSON", "MentionSentiment": { "Sentiment": "NEUTRAL", "SentimentScore": { "Mixed": 0, "Negative": 0, "Neutral": 1, "Positive": 0 } } } ] } ], "File": "Input.txt", "Line": 0 }
Analisi in tempo reale tramite console
Puoi utilizzare la console Amazon Comprehend per l'esecuzione Sentimento mirato in tempo reale. Usa il testo di esempio o incolla il tuo testo nella casella di testo di input, quindi scegli Analizza.
Nel pannello Insights, la console mostra tre visualizzazioni dell'analisi mirata del sentiment:
-
Testo analizzato: visualizza il testo analizzato e sottolinea ogni entità. Il colore della sottolineatura indica il valore di sentiment (positivo, neutro, negativo o misto) assegnato dall'analisi all'entità. La console visualizza le mappature dei colori nell'angolo superiore destro della casella di testo analizzata. Se si posiziona il cursore su un'entità, la console visualizza un pannello popup contenente i valori di analisi (tipo di entità, punteggio di sentiment) relativi all'entità.
-
Risultati: visualizza una tabella contenente una riga per ogni menzione di entità identificata nel testo. Per ogni entità, la tabella mostra l'entità e il punteggio dell'entità. La riga include anche il sentimento principale e il punteggio per ogni valore del sentimento. Se sono presenti più menzioni della stessa entità, nota come aGruppo di co-riferimento, la tabella visualizza queste menzioni come un insieme di righe comprimibile associato all'entità principale.
Se passi il mouse su una riga di entità nella tabella Risultati, la console evidenzia l'entità menzionata nel pannello di testo Analizzato.
-
Integrazione delle applicazioni: visualizza i valori dei parametri della richiesta API e la struttura dell'oggetto JSON restituito nella risposta API. Per una descrizione dei campi dell'oggetto JSON, consulta. Organizzazione dei file di output
Esempio di analisi in tempo reale da console
Questo esempio utilizza il testo seguente come input, che è il testo di input predefinito fornito dalla console.
Hello Zhang Wei, I am John. Your AnyCompany Financial Services, LLC credit card account 1111-0000-1111-0008 has a minimum payment of $24.53 that is due by July 31st. Based on your autopay settings, we will withdraw your payment on the due date from your bank account number XXXXXX1111 with the routing number XXXXX0000. Customer feedback for Sunshine Spa, 123 Main St, Anywhere. Send comments to Alice at sunspa@mail.com. I enjoyed visiting the spa. It was very comfortable but it was also very expensive. The amenities were ok but the service made the spa a great experience.
Il pannello Testo analizzato mostra il seguente output per questo esempio. Passa il mouse sul testo Zhang Wei per visualizzare il pannello popup relativo a questa entità.

La tabella Risultati fornisce dettagli aggiuntivi su ciascuna entità, tra cui il punteggio dell'entità, il sentimento principale e il punteggio per ogni sentimento.
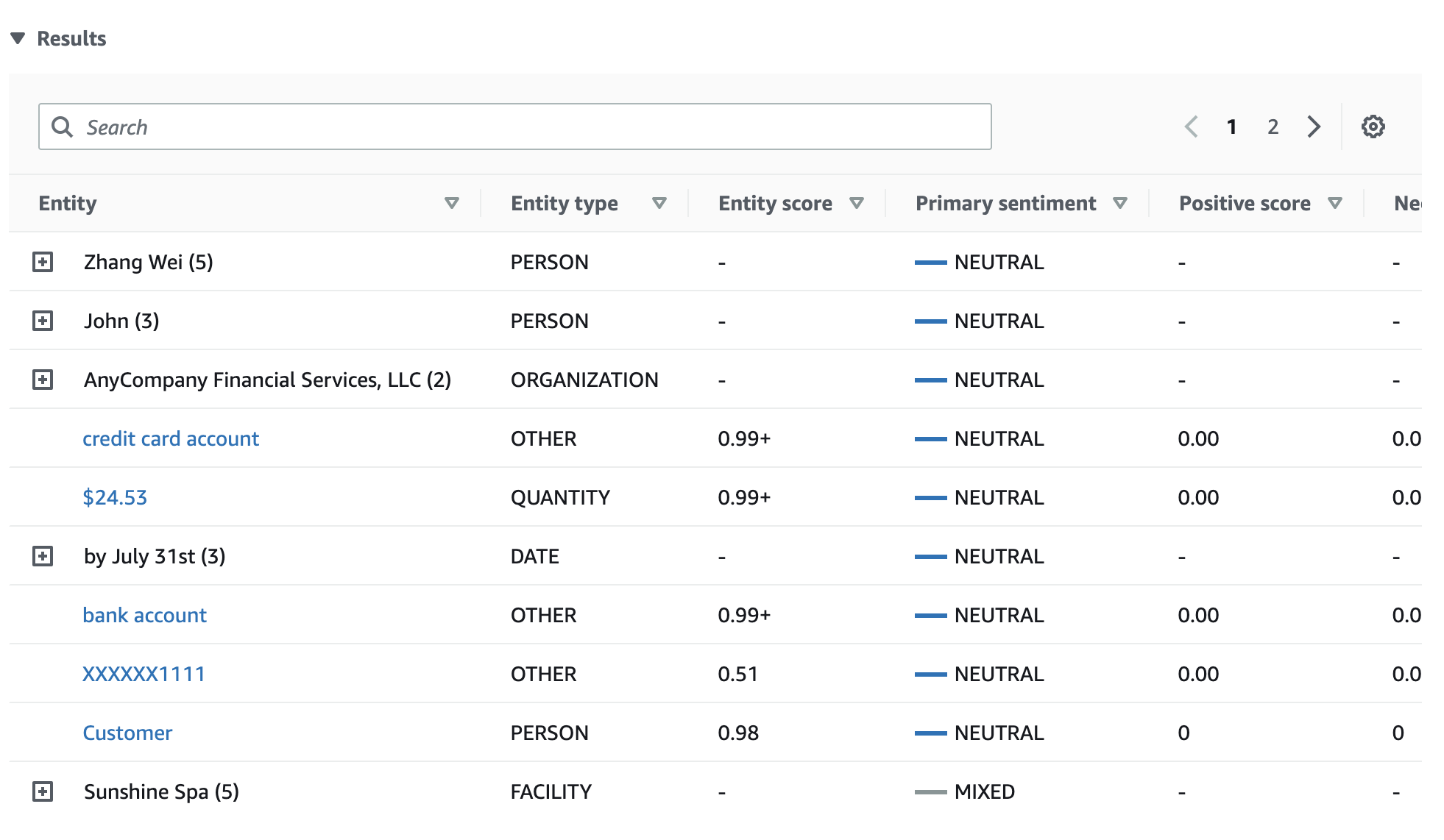
Nel nostro esempio, l'analisi mirata del sentiment riconosce che ogni tua menzione nel testo di input è un riferimento all'entità personale Zhang Wei. La console visualizza queste menzioni come un insieme di righe comprimibili associate all'entità principale.

Il pannello di integrazione dell'applicazione mostra l'oggetto JSON generato dall' DetectTargetedSentiment API. Per un esempio completo, consultate la sezione seguente.
Esempio di produzione mirata del sentiment
L'esempio seguente mostra il file di output di un lavoro mirato di analisi del sentiment. Il file di input è composto da tre semplici documenti:
The burger was very flavorful and the burger bun was excellent. However, customer service was slow. My burger was good, and it was warm. The burger had plenty of toppings. The burger was cooked perfectly but it was cold. The service was OK.
L'analisi mirata del sentiment di questo file di input produce il seguente output.
{"Entities":[
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 4,
"EndOffset": 10,
"Score": 0.999991,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 0,
"Positive": 1
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 38,
"EndOffset": 44,
"Score": 1,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0.000005,
"Negative": 0.000005,
"Neutral": 0.999591,
"Positive": 0.000398
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 45,
"EndOffset": 48,
"Score": 0.961575,
"GroupScore": 1,
"Text": "bun",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000327,
"Negative": 0.000286,
"Neutral": 0.050269,
"Positive": 0.949118
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 73,
"EndOffset": 89,
"Score": 0.999988,
"GroupScore": 1,
"Text": "customer service",
"Type": "ATTRIBUTE",
"MentionSentiment": {
"Sentiment": "NEGATIVE",
"SentimentScore": {
"Mixed": 0.000001,
"Negative": 0.999976,
"Neutral": 0.000017,
"Positive": 0.000006
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 0
}
{
"Entities": [
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 0,
"EndOffset": 2,
"Score": 0.99995,
"GroupScore": 1,
"Text": "My",
"Type": "PERSON",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 1,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0,
2
],
"Mentions": [
{
"BeginOffset": 3,
"EndOffset": 9,
"Score": 0.999999,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000002,
"Negative": 0.000001,
"Neutral": 0.000003,
"Positive": 0.999994
}
}
},
{
"BeginOffset": 24,
"EndOffset": 26,
"Score": 0.999756,
"GroupScore": 0.999314,
"Text": "it",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0.000003,
"Neutral": 0.000006,
"Positive": 0.999991
}
}
},
{
"BeginOffset": 41,
"EndOffset": 47,
"Score": 1,
"GroupScore": 0.531342,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.000215,
"Negative": 0.000094,
"Neutral": 0.00008,
"Positive": 0.999611
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 52,
"EndOffset": 58,
"Score": 0.965462,
"GroupScore": 1,
"Text": "plenty",
"Type": "QUANTITY",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 1,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 62,
"EndOffset": 70,
"Score": 0.998353,
"GroupScore": 1,
"Text": "toppings",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0,
"Negative": 0,
"Neutral": 0.999964,
"Positive": 0.000036
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 1
}
{
"Entities": [
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 4,
"EndOffset": 10,
"Score": 1,
"GroupScore": 1,
"Text": "burger",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "POSITIVE",
"SentimentScore": {
"Mixed": 0.001515,
"Negative": 0.000822,
"Neutral": 0.000243,
"Positive": 0.99742
}
}
},
{
"BeginOffset": 36,
"EndOffset": 38,
"Score": 0.999843,
"GroupScore": 0.999661,
"Text": "it",
"Type": "OTHER",
"MentionSentiment": {
"Sentiment": "NEGATIVE",
"SentimentScore": {
"Mixed": 0,
"Negative": 0.999996,
"Neutral": 0.000004,
"Positive": 0
}
}
}
]
},
{
"DescriptiveMentionIndex": [
0
],
"Mentions": [
{
"BeginOffset": 53,
"EndOffset": 60,
"Score": 1,
"GroupScore": 1,
"Text": "service",
"Type": "ATTRIBUTE",
"MentionSentiment": {
"Sentiment": "NEUTRAL",
"SentimentScore": {
"Mixed": 0.000033,
"Negative": 0.000089,
"Neutral": 0.993325,
"Positive": 0.006553
}
}
}
]
}
],
"File": "TargetSentimentInputDocs.txt",
"Line": 2
}
}