Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Addestra e valuta DeepRacer i modelli AWS utilizzando la DeepRacer console AWS
Per addestrare un modello di reinforcement learning, puoi usare la DeepRacer console AWS. Nella console è possibile creare un processo di formazione, scegliere un framework supportato e un algoritmo disponibile, aggiungere una funzione di ricompensa e configurare le impostazioni di formazione. È anche possibile osservare i progressi della formazione in un simulatore. Puoi trovare le step-by-step istruzioni inAddestra il tuo primo DeepRacer modello AWS .
Questa sezione spiega come addestrare e valutare un DeepRacer modello AWS. Mostra anche come creare e migliorare una funzione di ricompensa, come lo spazio d'azione influisce sulle prestazioni del modello e come gli iperparametri influiscono sulle prestazioni dell'addestramento. È anche possibile imparare a clonare un modello di addestramento per estendere una sessione di formazione, come utilizzare il simulatore per valutare le prestazioni dell'addestramento e come utilizzare alcuni aspetti della simulazione nelle sfide del mondo reale.
Argomenti
Crea la tua funzione di ricompensa
Una funzione di ricompensa descrive il feedback immediato (come ricompensa o punteggio di penalità) quando il DeepRacer veicolo AWS passa da una posizione in pista a una nuova posizione. Lo scopo della funzione è incoraggiare il veicolo a spostarsi nel circuito per raggiungere una destinazione rapidamente senza incidenti o infrazioni. Uno spostamento ideale ottiene un punteggio maggiore per l'azione o lo stato target. Uno spostamento scorretto o più lungo del necessario ottiene un punteggio inferiore. Durante l'addestramento di un DeepRacer modello AWS, la funzione di ricompensa è l'unica parte specifica dell'applicazione.
In generale, si progetta la funzione di ricompensa in modo che agisca da programma di incentivi. Diverse strategie di incentivazione potrebbero causare diversi comportamenti del veicolo. Per far correre più rapidamente il veicolo, la funzione deve ricompensarlo quando segue il circuito. La funzione deve dispensare penalità quando il veicolo finisce fuori strada o impiega troppo tempo a completare un giro. Per evitare percorsi di guida a zig-zag, potrebbe ricompensare il veicolo se sterza di meno nelle parti più dritte nel circuito. La funzione di ricompensa potrebbe assegnare punteggi positivi quando il veicolo ottiene determinati traguardi, nel modo misurato da waypoints. In questo modo si possono ridurre i tempi di attesa o di guida nella direzione sbagliata. Inoltre, è consigliabile modificare la funzione di ricompensa in modo da tenere conto delle condizioni del circuito. Tuttavia, più la funzione di ricompensa tiene conto delle informazioni ambientali, più il modello addestrato sarà dotato di overfitting e meno generico. Per rendere il modello più generalmente applicabile, è possibile esplorare lo spazio d'azione.
Senza un'attenta considerazione, un programma di incentivazione può causare conseguenze indesiderate di effetto opposto
Un buon metodo per creare una funzione di ricompensa è iniziare con una funzione semplice, valida per gli scenari di base, È possibile migliorare la funzione in modo che possa gestire più operazioni. Diamo ora un'occhiata ad alcune semplici funzioni di ricompensa.
Semplici esempi di funzioni di ricompensa
È possibile iniziare a creare la funzione di ricompensa considerando innanzitutto la situazione di base. Tale situazione è la guida su un rettilineo dall'inizio alla fine senza uscire dal circuito. In questo scenario, la logica della funzione di ricompensa dipende solo da on_track e progress. Per provare, si potrebbe iniziare con la seguente logica:
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else if params["progress"] == 1 : reward = 10 return reward
Questa logica penalizza l'agente in caso di uscita dal circuito. Ricompensa l'agente se arriva al traguardo. È una logica ragionevole per raggiungere l'obiettivo prestabilito. Tuttavia, l'agente si muove liberamente tra il punto di partenza e il traguardo e può anche percorrere il circuito in senso inverso. Il tempo di completamento dell'addestramento potrebbe essere molto lungo e il modello addestrato potrebbe comportare una guida meno efficiente se implementato in un veicolo reale.
In pratica, un agente apprende in modo più efficace se riesce a farlo bit-by-bit durante il corso della formazione. Ciò significa che una funzione di ricompensa dovrebbe riconoscere ricompense più piccole progressivamente lungo il circuito. Perché l'agente guidi sul tracciato rettilineo, possiamo migliorare la funzione ricompensa come segue:
def reward_function(params): if not params["all_wheels_on_track"]: reward = -1 else: reward = params["progress"] return reward
Con questa funzione l'agente ottiene più ricompense man mano che si avvicina al traguardo. In questo modo i tentativi improduttivi di guida in senso inverso dovrebbero ridursi o azzerarsi. In generale, desideriamo che la funzione ricompensa distribuisca la ricompensa in modo più uniforme lungo lo spazio dell'azione. La creazione di un'efficace funzione di ricompensa può essere un'impresa impegnativa. È consigliabile iniziare con una funzione semplice e progressivamente incrementarla o migliorarla. Sperimentando sistematicamente, la funzione può diventare più affidabile ed efficiente.
Migliora la tua funzione di ricompensa
Dopo aver addestrato con successo il tuo DeepRacer modello AWS per il semplice percorso rettilineo, il DeepRacer veicolo AWS (virtuale o fisico) può guidare da solo senza uscire di pista. Se hai lasciato che il veicolo si muovesse su un tracciato circolare, non riuscirà a rimanere all'interno del circuito. La funzione di ricompensa ha ignorato operazioni come l'esecuzione di curve per riuscire a seguire il tracciato.
Per consentire al veicolo di compiere tali operazioni, occorre incrementare la funzione di ricompensa. La funzione deve assegnare un premio se l'agente effettua una curva lecita e produrre una penalità se l'agente effettua una curva illecita. Sei quindi pronto per iniziare un altro round di addestramento. Per trarre vantaggio dall'addestramento precedente, puoi iniziare quello nuovo clonando il precedente modello addestrato, trasferendo le conoscenze apprese in precedenza. Puoi seguire questo schema per aggiungere gradualmente altre funzionalità alla funzione di ricompensa per addestrare il tuo DeepRacer veicolo AWS a guidare in ambienti sempre più complessi.
Per funzioni di ricompensa più avanzate, vedere gli esempi seguenti:
Esplora lo spazio d'azione per addestrare un modello robusto
Come regola generale, il modello va addestrato per essere il più affidabile possibile, in modo che possa essere applicato a quanti più ambienti possibile. Un modello affidabile è quello che può essere applicato in un'ampia gamma di forme e condizioni del circuito. In linea generale, un modello affidabile non è "intelligente", perché la sua funzione di ricompensa non è in grado di contenere conoscenze esplicite dell'ambiente. In caso contrario, è probabile che il modello possa essere applicato solo a un ambiente simile a quello dell'addestramento.
L'incorporamento esplicito di informazioni specifiche dell'ambiente nella funzione di ricompensa corrisponde alla progettazione delle caratteristiche. La progettazione delle caratteristiche aiuta a ridurre il tempo di addestramento e può essere utile nelle soluzioni su misura per un particolare ambiente. Per addestrare un modello universalmente applicabile, però, occorre evitare un eccessivo affidamento alla progettazione delle caratteristiche.
Ad esempio, se si addestra un modello in un tracciato circolare, non ci si può attendere che il modello sia applicabile ai tracciati non circolari se queste proprietà geometriche sono incorporate esplicitamente nella funzione di ricompensa.
Come si fa ad addestrare un modello che sia il più affidabile possibile mantenendo la funzione di ricompensa la più semplice possibile? Un modo è quello di esplorare lo spazio operativo, ampliando le operazioni eseguibili dall'agente. Un altro è quello di sperimentare gli iperparametri dell'algoritmo di addestramento sottostante. Spesso si utilizzano entrambi i metodi. Qui, ci concentriamo su come esplorare lo spazio d'azione per addestrare un modello robusto per il tuo DeepRacer veicolo AWS.
Nell'addestramento di un DeepRacer modello AWS, un'azione (a) è una combinazione di velocità (tmetri al secondo) e angolo di sterzata (sin gradi). Lo spazio operativo dell'agente definisce gli intervalli di velocità e angolo di sterzata accettabili da parte dell'agente. Per uno spazio operativo discreto di numero m di velocità, (v1, .., vn) e numero n di angoli di sterzata, (s1, ..,
sm), esistono m*n possibili operazioni nello spazio operativo:
a1: (v1, s1) ... an: (v1, sn) ... a(i-1)*n+j: (vi, sj) ... a(m-1)*n+1: (vm, s1) ... am*n: (vm, sn)
I valori effettivi di (vi,
sj) dipendono dagli intervalli di vmax e |smax| e non sono distribuiti uniformemente.
Ogni volta che inizi ad addestrare o iterare il tuo DeepRacer modello AWS, devi prima specificare |smax| e/o accettare di utilizzarne i valori predefiniti. n m vmax In base alla tua scelta, il DeepRacer servizio AWS genera le azioni disponibili che il tuo agente può scegliere durante la formazione. Le operazioni generate non sono distribuite in modo uniforme nello spazio operativo.
In generale, un maggior numero di operazioni e di intervalli offrono all'agente più margini di scelta per reagire a condizioni del circuito più diverse, come un percorso con curve con angoli o direzioni irregolari. Maggiore è il numero di opzioni disponibili per l'agente, più pronto sarà a gestire le variazioni del circuito. Di conseguenza, si può prevedere che il modello addestrato sia applicabile più generalmente, anche se si utilizza una funzione di ricompensa semplice.
Ad esempio, l'agente può imparare rapidamente a gestire i rettilinei utilizzando uno spazio operativo grossolano con un numero ridotto di velocità e di angoli di sterzata. In un circuito ricco di curve, lo spazio operativo grossolano può spingere l'agente ad andare troppo forte e a uscire di strada in curva. Ciò si verifica perché l'agente non ha abbastanza opzioni per regolare la velocità o la sterzata. Aumentando il numero delle velocità o degli angoli di sterzata (o entrambi), l'agente diventa più capace di gestire le curve rimanendo all'interno del tracciato. Analogamente, se l'agente si sposta a zig-zag, è possibile provare ad aumentare il numero degli intervalli di sterzata per ridurre le curve brusche a ogni passaggio.
Quando lo spazio operativo è troppo grande, le prestazioni dell'addestramento possono essere compromesse, perché la sua esplorazione richiede un tempo maggiore. Occorre fare in modo di bilanciare i vantaggi dell'applicabilità generale del modello con i requisiti prestazionali dell'addestramento. Questa ottimizzazione prevede una sperimentazione sistematica.
Ottimizza sistematicamente gli iperparametri
Un modo per migliorare le prestazioni del modello è quello di implementare un processo di addestramento migliore o più efficace. Ad esempio, per ottenere un modello affidabile, l'addestramento deve fornire all'agente un campionamento più o meno uniformemente distribuito nello spazio operativo dell'agente. Ciò richiede una combinazione adeguata tra l'esplorazione e lo sfruttamento. Le variabili coinvolte includono la quantità di dati dell'addestramento utilizzati (number of episodes between each
training e batch size), la velocità di apprendimento dell'agente (learning rate) e la porzione di esplorazione (entropy). Per favorire la praticità dell'addestramento, è preferibile velocizzare il processo di apprendimento. Le variabili qui coinvolte includono learning rate, batch size, number of
epochs e discount factor.
Le variabili che interessano il processo di addestramento sono chiamati iperparametri dell'addestramento. Questi attributi dell'algoritmo non sono di proprietà del modello sottostante. Purtroppo gli iperparametri sono di per sé empirici. I loro valori ottimali non sono noti per tutti gli scopi pratici la loro scoperta richiede una sperimentazione sistematica.
Prima di parlare degli iperparametri che possono essere regolati per ottimizzare le prestazioni di addestramento del DeepRacer modello AWS, definiamo la seguente terminologia.
- Punto dati
-
Un punto dati, anche detto esperienza, è una tupla di (s,a,r,s'), dove s rappresenta un'osservazione (o stato) acquisita dalla fotocamera, a un'operazione (action) compiuta dal veicolo, r la ricompensa prevista dall'operazione e s' per la nuova operazione successiva al compimento dell'operazione.
- Episodio
-
Un episodio è un periodo di tempo compreso tra il momento in cui il veicolo si muove da un determinato punto di partenza e quello in cui completa il circuito o esce di strada. Rappresenta una sequenza di esperienze. Episodi diversi possono avere lunghezze differenti.
- Buffer dell'esperienza
-
Un buffer dell'esperienza consiste in un numero di punti dati ordinati raccolti in un numero fisso di episodi di lunghezza variabile nel corso dell'addestramento. Per AWS DeepRacer, corrisponde alle immagini acquisite dalla telecamera montata sul DeepRacer veicolo AWS e alle azioni intraprese dal veicolo e funge da fonte da cui attingere l'input per l'aggiornamento delle reti neurali sottostanti (politiche e valori).
- Archiviazione
-
Un batch è un elenco ordinato di esperienze che rappresenta una porzione della simulazione in un periodo di tempo, utilizzato per aggiornare le ponderazioni della rete di policy. È un sottoinsieme del buffer dell'esperienza.
- Dati dell'addestramento
-
I dati di addestramento sono un set di batch campionati casualmente dal buffer dell'esperienza e sono utilizzati per addestrare le ponderazioni della rete di policy.
| Iperparametri | Descrizione |
|---|---|
|
Gradient descent batch size (Dimensioni del batch per la discesa del gradiente) |
Il numero di esperienze recenti del veicolo campionato casualmente da un buffer dell'esperienza, utilizzato per aggiornare le ponderazioni della rete neurale di deep-learning sottostante. Il campionamento casuale aiuta a ridurre le correlazioni insite nei dati di input. Batch di dimensioni maggiori favoriscono aggiornamenti più stabili e semplici alle ponderazioni della rete neurale, ma c'è anche la possibilità che l'addestramento sia più lungo o lento.
|
|
Number of epochs (Numero di epoch) |
Il numero di passaggi attraverso i dati di addestramento per aggiornare le ponderazioni della rete neurale nell'ascesa del gradiente. I dati di addestramento corrispondono ai campionamenti casuali dal buffer dell'esperienza. Un numero maggiore di epoch favorisce aggiornamenti più stabili, ma si deve prevedere un addestramento più lento. Se le dimensioni del batch sono ridotte, si può utilizzare un numero di epoch inferiore.
|
|
Learning rate (Velocità di apprendimento) |
Durante ciascun aggiornamento, una porzione della nuova ponderazione può provenire dal contributo della discesa (o dell'ascesa) del gradiente e il resto dal valore della ponderazione esistente. La velocità di apprendimento controlla la quantità del contributo di una discesa (o di un'ascesa) del gradiente alle ponderazioni di una rete. Una velocità di apprendimento maggiore include più contributi della discesa del gradiente e accelera l'addestramento, ma occorre essere consapevoli che la ricompensa prevista potrebbe non convergere se la velocità di apprendimento è troppo grande.
|
Entropy |
Un grado di incertezza utilizzato per determinare quando aggiungere casualità alla distribuzione della policy. L'ulteriore incertezza aiuta il DeepRacer veicolo AWS a esplorare lo spazio d'azione in modo più ampio. Un'entropia più grande incoraggia il veicolo a esplorare lo spazio operativo con maggiore attenzione.
|
| Discount factor (Fattore sconto) |
Fattore che specifica quanto delle ricompense future contribuisca alle ricompense previste. Maggiore è il valore Fattore sconto, più distanti saranno i contributi che il veicolo prende in considerazione per eseguire un'operazione e più lento sarà l'addestramento. Con il fattore sconto di 0,9, il veicolo include ricompense da un ordine di 10 passaggi futuri per effettuare uno spostamento. Con il fattore sconto di 0,999, il veicolo considera ricompense da un ordine di 1.000 passaggi futuri per effettuare uno spostamento. I valori consigliati del fattore sconto consigliati sono 0,74, 0,999 e 0,9999.
|
| Loss type (Tipo di perdita) |
Tipo di funzione obiettivo utilizzata per aggiornare i pesi della rete. Un buon algoritmo di addestramento dovrebbe apportare modifiche incrementali alla strategia dell'agente in modo che passi gradualmente dal prendere azioni casuali a prendere azioni strategiche per migliorare la ricompensa. Tuttavia, se il cambiamento è troppo grande, l'addestramento diventa instabile e l'agente finisce con il non apprendere. I tipi di funzione di Perdita di Huber
|
| Number of experience episodes between each policy-updating iteration (Numero di episodi di esperienza tra ciascuna iterazione di aggiornamento della policy) | Le dimensione del buffer dell'esperienza utilizzata per ricavare dati di addestramento per le ponderazioni della rete di policy di formazione. Un episodio di esperienza è un periodo di tempo nel quale l'agente parte da un certo punto di partenza e finisce completando il circuito o uscendo di strada. È costituito da una sequenza di esperienze. Episodi diversi possono avere lunghezze differenti. Per problemi semplici relativi all'apprendimento per rinforzo, un buffer dell'esperienza di piccole dimensioni può essere sufficiente e l'apprendimento è rapido. Per problemi più complessi che hanno più locali massimi, è necessario un buffer dell'esperienza più grande per fornire più punti dati non correlati. In questo caso, la formazione è più lenta ma più stabile. I valori consigliati sono 10, 20 e 40.
|
Esamina lo stato DeepRacer di avanzamento delle mansioni di formazione
Dopo aver avviato il processo di training, puoi esaminare i parametri di training delle ricompense e del completamento del circuito per singolo episodio, in modo da verificare le prestazioni del processo di training del modello. Sulla DeepRacer console AWS, le metriche vengono visualizzate nel grafico Reward, come illustrato nella figura seguente.
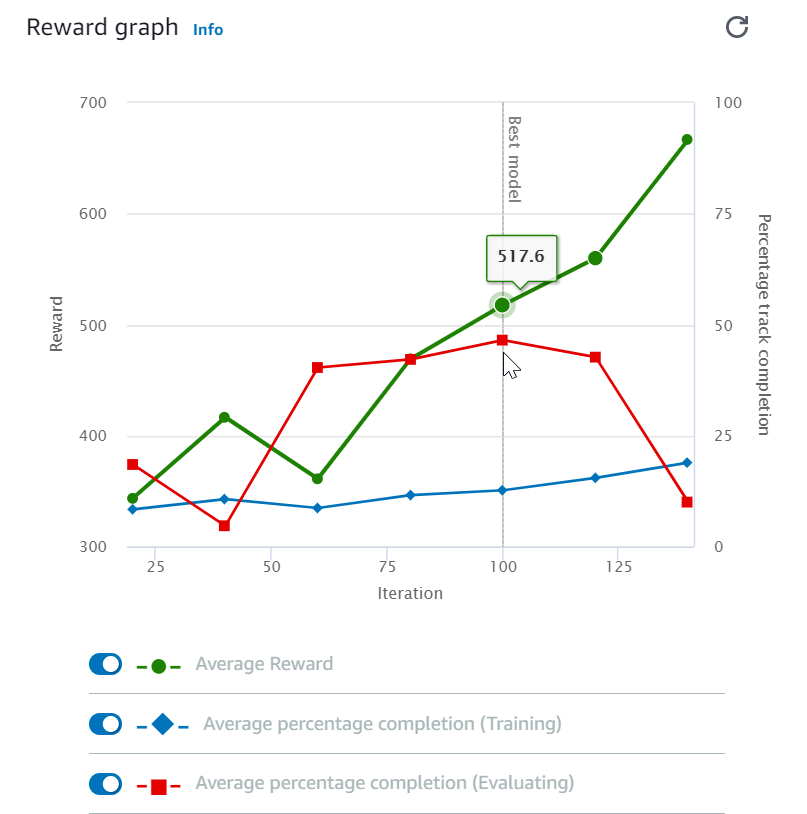
Puoi scegliere di visualizzare la ricompensa ottenuta per episodio, la media delle ricompense per iterazione, l'avanzamento per episodio, l'avanzamento medio per iterazione o qualsiasi combinazione di essi. Per farlo, attiva/disattiva gli interruttori Reward ((Episode, Average) (Ricompensa, Episodio Media) o Progress (Episode, Average) (Avanzamento, Episodio, Media) nella parte inferiore del Reward graph (Grafico ricompensa). La ricompensa e l'avanzamento per episodio vengono visualizzati come diagrammi a dispersione in diversi colori. La ricompensa e il completamento del circuiti medi vengono visualizzati come diagrammi lineari a partire dalla prima iterazione.
L'intervallo delle ricompense viene visualizzato nella parte sinistra del grafico, mentro quello dell'avanzamento (0-100) è sulla parte destra. Per leggere il valore esatto di un parametro di training, sposta il mouse vicino al punto dati sul grafico.
I grafici vengono aggiornati automaticamente ogni 10 secondi mentre il training è in corso. Puoi selezionare il pulsante di aggiornamento per aggiornare manualmente la visualizzazione del parametro.
Un processo di training è valido se la media della ricompensa e quella del completamento del circuito tendono a convergere. In particolare, il modello è probabilmente convergente se l'avanzamento per episodio raggiunge continuamente il 100% e la ricompensa viene aumentata. In caso contrario, occorre clonare il modello e riaddestrarlo.
Clona un modello addestrato per iniziare un nuovo pass di formazione
Se si clona un modello addestrato in precedenza come punto di partenza di un nuovo ciclo di formazione, è possibile migliorare l'efficienza dell'addestramento. Per eseguire questa operazione, occorre modificare gli iperparametri in modo che sfruttino le conoscenze già apprese.
In questa sezione, imparerai come clonare un modello addestrato utilizzando la DeepRacer console AWS.
Per iterare l'addestramento del modello di reinforcement learning utilizzando la console AWS DeepRacer
-
Accedi alla DeepRacer console AWS, se non hai già effettuato l'accesso.
-
Nella pagina Models (Modelli) scegliere un modello addestrato, quindi Clone (Clona) dal menu a discesa Action (Azione).
-
Per Model details (Dettagli modello) procedere come indicato di seguito:
-
Digitare
RL_model_1in Model name (Nome modello), se non si desidera generare un nome per il modello clonato. -
Facoltativamente, fornisci una descrizione del to-be-cloned modello in Descrizione del modello - opzionale.
-
-
Per la simulazione dell'ambiente, scegliete un'altra opzione di traccia.
-
In Reward function (Funzione di ricompensa), scegliere uno degli esempi disponibili. Modificare la funzione di ricompensa. Ad esempio, prendiamo in considerazione la sterzata.
-
Espandere Impostazioni algoritmo e provare diverse opzioni. Ad esempio, modificare il valore Dimensioni batch di discesa del gradiente da 32 a 64 o aumentare Learning rate (Velocità di apprendimento) per accelerare l'apprendimento.
-
Provare a scegliere le diverse opzioni di Stop conditions (Interrompi condizioni).
-
Selezionare Start training (Inizia addestramento) per iniziare un nuovo round di addestramento.
Come avviene in generale per l'addestramento di un modello affidabile di machine learning, è importante condurre una sperimentazione sistematica per trovare la soluzione migliore.
Valuta i DeepRacer modelli AWS nelle simulazioni
Valutare un modello vuol dire testare le prestazioni di un modello addestrato. In AWS DeepRacer, la metrica prestazionale standard è il tempo medio impiegato per completare tre giri consecutivi. Utilizzando questa metrica, per due modelli qualsiasi, un modello è migliore dell'altro se riesce a far sì che l'agente proceda più velocemente sulla stessa strada.
In generale, la valutazione di un modello prevede le seguenti attività:
-
Configurazione e avvio di un processo di valutazione.
-
Osservazione dello stato di avanzamento della valutazione mentre il processo è in esecuzione. Questa operazione può essere eseguita nel DeepRacer simulatore AWS.
-
Analisi del riepilogo della valutazione al termine del processo di valutazione. È possibile terminare un processo di valutazione in corso in qualsiasi momento.
Nota
Il tempo di valutazione dipende dai criteri selezionati. Se il modello non soddisfa i criteri di valutazione, la valutazione continuerà fino al raggiungimento del limite di 20 minuti.
-
Facoltativamente, invia il risultato della valutazione a una DeepRacer classifica AWS idonea. L'ordine di classifica permette di mettere a confronto le prestazioni del modello con quelle degli altri partecipanti.
Prova un DeepRacer modello AWS con un DeepRacer veicolo AWS che guida su una pista fisica, vediUsa il tuo DeepRacer veicolo AWS .
Ottimizza la formazione DeepRacer dei modelli AWS per ambienti reali
Molti fattori influiscono sulle prestazioni effettive di un modello addestrato, tra cui la scelta dello spazio operativo, della funzione di ricompensa, degli iperparametri utilizzati nell'addestramento e della calibrazione del veicolo, nonché delle condizioni del circuito reale. Inoltre, la simulazione è solo una approssimazione (spesso grezza) del mondo reale. È difficile addestrare un modello nella simulazione, applicarlo al mondo reale e ottenere prestazioni soddisfacenti.
L'addestramento di un modello per ottenere prestazioni affidabili nel mondo reale spesso richiede numerose iterazioni dell'esplorazione della funzione di ricompensa, degli spazi operativi, degli iperparametri, della valutazione nella simulazione, nonché dei test in un ambiente reale. L'ultimo passaggio prevede il cosiddetto trasferimento simulation-to-real mondiale (sim2real) e può sembrare ingombrante.
Come aiuto per affrontare le difficoltà del sim2real, prendere in considerazione quanto segue:
-
Verificare che il veicolo sia ben calibrato.
Questo è importante perché l'ambiente simulato è spesso una rappresentazione parziale di quello reale. Inoltre, l'agente compie un'operazione in base alla condizione attuale del circuito, acquisita come immagine dalla fotocamera, in ogni passaggio. Non riesce a vedere abbastanza lontano per pianificare il suo percorso ad alta velocità. Per risolvere questa problematica, la simulazione impone limiti alla velocità e alla sterzata. Per garantire il funzionamento del modello nel mondo reale, il veicolo deve essere calibrato adeguatamente in modo da corrispondere a questa e ad altre impostazioni della simulazione. Per ulteriori informazioni sulla calibrazione del veicolo, consulta Calibra il tuo veicolo AWS DeepRacer .
-
Test preliminare del veicolo con il modello predefinito.
Il DeepRacer veicolo AWS viene fornito con un modello pre-addestrato caricato nel suo motore di inferenza. Prima di testare un modello nel mondo reale, occorre verificare che le prestazioni del veicolo siano buone con il modello predefinito. In caso contrario, verificare la configurazione del circuito fisico. È probabile che il test di un modello eseguito su un circuito fisico creato in modo non corretto comporti prestazioni di basso livello. In questi casi, occorre riconfigurare o riparare il circuito prima di avviare o riprendere il test.
Nota
Quando si utilizza un DeepRacer veicolo AWS, le azioni vengono dedotte in base alla rete di policy addestrata senza richiamare la funzione di ricompensa.
-
Verificare che il modello funzioni nella simulazione.
Se il modello non funziona bene nel mondo reale, è possibile che il modello o il circuito siano difettosi. Per risolvere le cause principali, occorre innanzitutto valutare il modello nelle simulazioni per controllare se l'agente simulato è in grado di terminare almeno un loop senza uscire di strada. È possibile farlo ispezionando la convergenza delle ricompense e osservando la traiettoria dell'agente nel simulatore. Se la ricompensa raggiunge il massimo quando l'agente simulato completa un loop senza errori, è probabile che il modello sia valido.
-
Non addestrare eccessivamente il modello.
Proseguire l'addestramento dopo che il modello ha completato coerentemente il circuito nella simulazione causa l'overfitting del modello. Un modello troppo addestrato non avrà buone prestazioni mondo reale, perché non è in grado di gestire neanche le più piccole variazioni tra il circuito simulato e l'ambiente reale.
-
Utilizzare più modelli da diverse iterazioni.
Una tipica sessione di addestramento produce un intervallo di modelli compreso tra l'essere troppo o troppo poco adatti. Poiché non vi sono criteri a priori per stabilire se un modello è adatto, è opportuno scegliere pochi candidati dal momento in cui l'agente completa un solo loop nel simulatore fino a quando non esegue loop in modo costante.
-
Conviene partire lentamente e aumentare gradualmente la velocità nel test.
Quando si testa il modello implementato nel veicolo, occorre partire da un valore basso di velocità massima. Ad esempio, è possibile impostare il limite di velocità del test in modo che sia inferiore al 10% del limite di velocità dell'addestramento. Quindi, occorre aumentare gradualmente il limite di velocità del test fino a quando il veicolo non inizia a muoversi. Il limite di velocità del test si imposta quando si calibra il veicolo utilizzando la console di controllo del dispositivo. Se il veicolo va troppo veloce, ad esempio se la velocità supera quella registrata durante l'addestramento al simulatore, è improbabile che il modello si comporti bene sulla pista reale.
-
Test di un modello con il veicolo in diverse posizioni di partenza.
Il modello impara a prendere un determinato percorso nella simulazione e può essere sensibile alla posizione all'interno del circuito. È consigliabile avviare i test del veicolo con diverse posizioni all'interno dei confini del circuito (da sinistra, al centro e a destra) per verificare che il modello abbia buone prestazioni da determinate posizioni. La maggior parte dei modelli tende a mantenere il veicolo a ridosso di uno dei due lati di una delle righe bianche. Come aiuto nell'analisi del percorso del veicolo, tracciare le posizioni del veicolo (x, y) passo per passo dalla simulazione per identificare i percorsi che è probabile il veicolo prenda nell'ambiente reale.
-
Avviare il test con un percorso rettilineo.
Un rettilineo è molto più facile da percorrere rispetto a un tracciato con curve. Avviare il test con un rettilineo è utile per eliminare rapidamente i modelli di scarsa qualità. Se un veicolo non è in grado di seguire un rettilineo la maggior parte delle volte, il modello non si comporterà bene neanche nei tracciati curvilinei.
-
Occorre fare attenzione al comportamento in cui il veicolo effettua solo un tipo di operazione.
Se il veicolo riesce a eseguire solo un tipo di azione, ad esempio sterzando il veicolo solo a sinistra, è probabile che il modello sia sovraequipaggiato o mal equipaggiato. Con determinati parametri del modello, troppe iterazioni nell'addestramento possono rendere il modello eccessivamente adatto. Troppo poche interazioni lo possono rendere poco adatto.
-
Occorre fare attenzione all'abilità del veicolo di correggere il proprio percorso lungo i confini di un circuito.
Un buon modello permette al veicolo di correggersi quando si avvicina ai bordi del tracciato. La maggior parte dei modelli ben addestrati dispone di questa funzionalità. Se il veicolo è in grado di correggersi automaticamente su entrambi i bordi, il modello è considerato più affidabile e di qualità superiore.
-
Occorre fare attenzione ai comportamenti incoerenti mostrati dal veicolo.
Un modello di policy rappresenta una distribuzione probabilistica per l'esecuzione di un'operazione in un determinato stato. Con il modello addestrato caricato nel motore di inferenza, un veicolo sceglie l'operazione più probabile, un passo per volta, in base alle indicazioni del modello. Se le probabilità dell'operazione sono distribuite in modo uniforme, il veicolo può compiere qualunque operazione con probabilità uguali o simili. Ne conseguirà un comportamento di guida imprevedibile. Ad esempio, quando a volte il veicolo segue un percorso rettilineo (ad esempio, la metà delle volte) e altre volte compie curve inutili, il modello è sovraequipaggiato o troppo equipaggiato.
-
Fai attenzione a un solo tipo di svolta (sinistra o destra) effettuata dal veicolo.
Se il veicolo prende molto bene le curve a sinistra ma non riesce a sterzare a destra o, analogamente, se prende bene solo le curve a destra, sarà necessario calibrare o ricalibrare la sterzata del veicolo. In alternativa, è possibile provare a utilizzare un modello addestrato con impostazioni vicine a quelle fisiche in fase di test.
-
Fai attenzione al veicolo che fa curve improvvise e va fuori pista.
Se il veicolo segue il percorso correttamente la maggior parte del tempo, ma improvvisamente esce di strada, è probabile che il motivo sia dovuto alle distrazioni nell'ambiente. Le distrazioni più comuni includono riflessi di luce involontari o imprevisti. In questi casi, occorre utilizzare barriere lungo il circuito o altri strumenti per ridurre le luci abbaglianti.
