Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Crawling di un archivio di dati Amazon S3 utilizzando un endpoint VPC
Per motivi di sicurezza, audit o controllo, puoi consentire l'accesso all'archivio dati Amazon S3 o alle tabelle Catalogo dati supportate da Amazon S3 solo tramite un ambiente Amazon Virtual Private Cloud (Amazon VPC). In questo argomento viene descritto come creare e testare una connessione all'archivio dati Amazon S3 o alle tabelle Catalogo dati supportate da Amazon S3 in un endpoint VPC utilizzando il tipo di connessione Network.
Esegui le attività seguenti per eseguire un crawler nell'archivio dati:
Prerequisiti
Verifica di aver soddisfatto questi prerequisiti per configurare il datastore Amazon S3 affinché vi si possa accedere solo tramite un ambiente Amazon Virtual Private Cloud (Amazon VPC).
-
Un VPC configurato. Ad esempio: vpc-01685961063b0d84b. Per ulteriori informazioni, consulta le Nozioni di base su Amazon VPC nella Guida per l'utente di Amazon VPC.
-
Un endpoint Amazon S3 collegato al VPC. Ad esempio: vpc-01685961063b0d84b. Per ulteriori informazioni, consulta Endpoint per Amazon S3 nella Guida per l'utente di Amazon VPC.
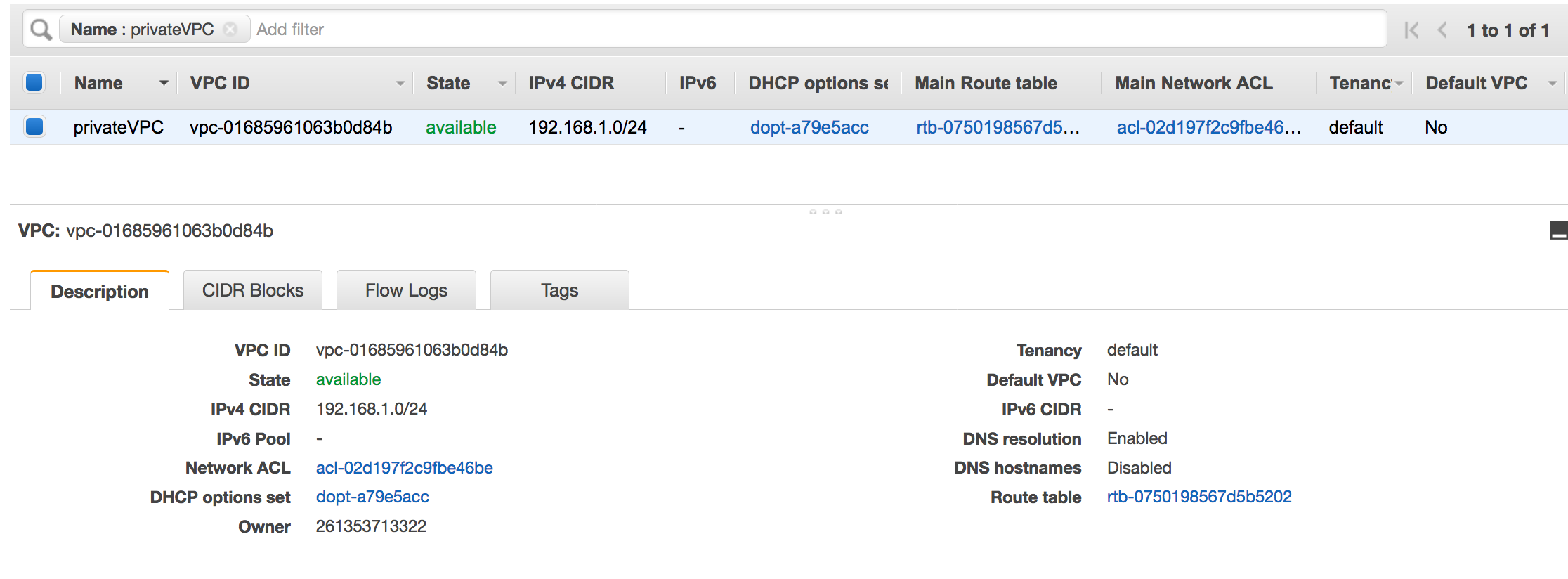
-
Una voce route che punta all'endpoint VPC. Ad esempio vpce-0ec5da4d265227786 nella tabella di routing utilizzata dall'endpoint VPC (vpce-0ec5da4d265227786).
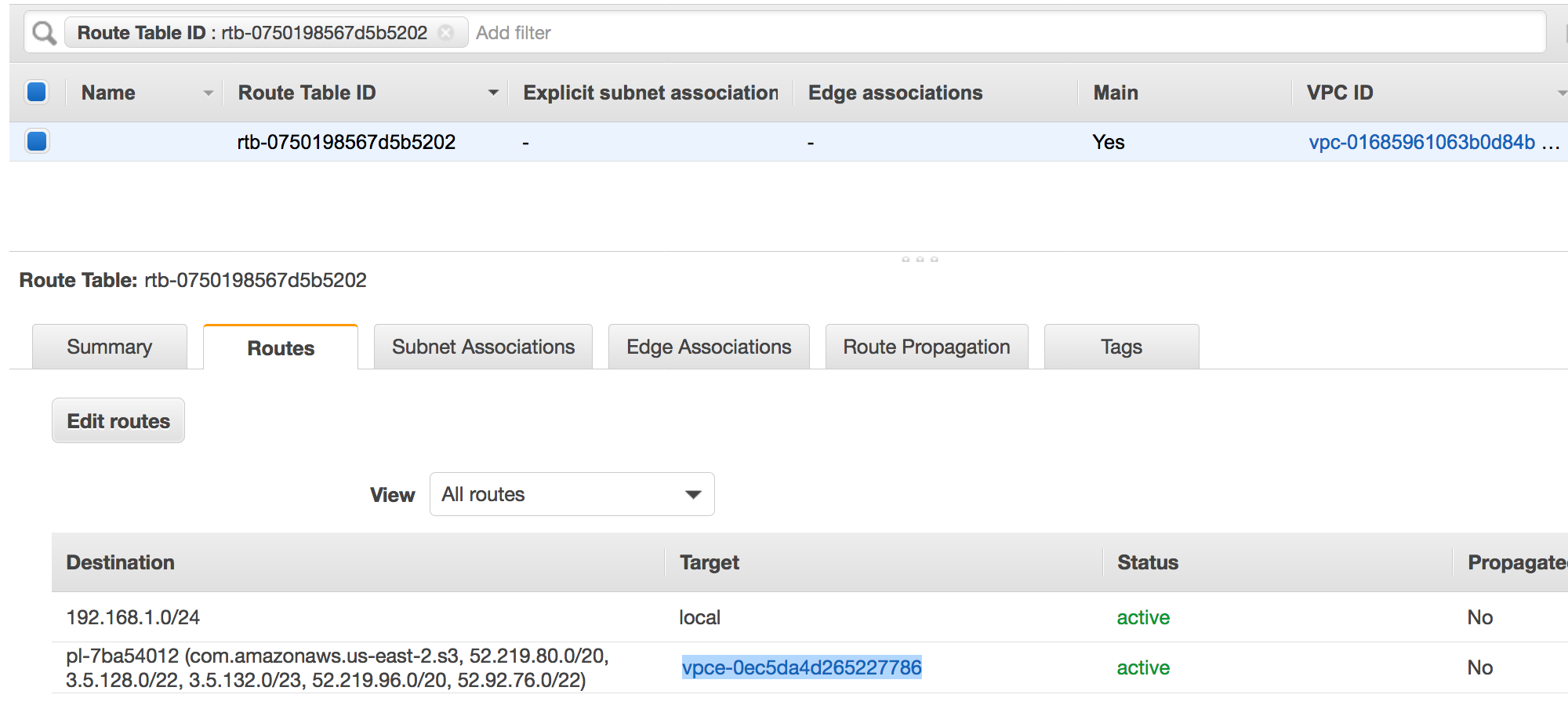
-
Una lista di controllo degli accessi di rete collegata al VPC consente il traffico.
-
Un gruppo di sicurezza collegato al VPC consente il traffico.
Creazione della connessione ad Amazon S3
In genere, le risorse vengono create in Amazon Virtual Private Cloud (Amazon VPC) per impedirne l'accesso tramite rete internet pubblica. Per impostazione predefinita, non è AWS Glue possibile accedere alle risorse all'interno di un VPC. Per consentire l'accesso AWS Glue alle risorse all'interno del VPC, è necessario fornire ulteriori informazioni di configurazione specifiche del VPC che includono la sottorete VPC e il gruppo di sicurezza. IDs IDs Per creare una connessione Network, è necessario specificare le informazioni seguenti:
-
Un ID VPC
-
Una sottorete all'interno del VPC
-
Un gruppo di sicurezza
Per impostare una connessione Network:
-
Scegli Add connection (Aggiungi connessione) nel pannello di navigazione della console AWS Glue .
-
Inserisci il nome della connessione e scegli Network (Rete) come tipo di connessione. Scegli Next (Successivo).
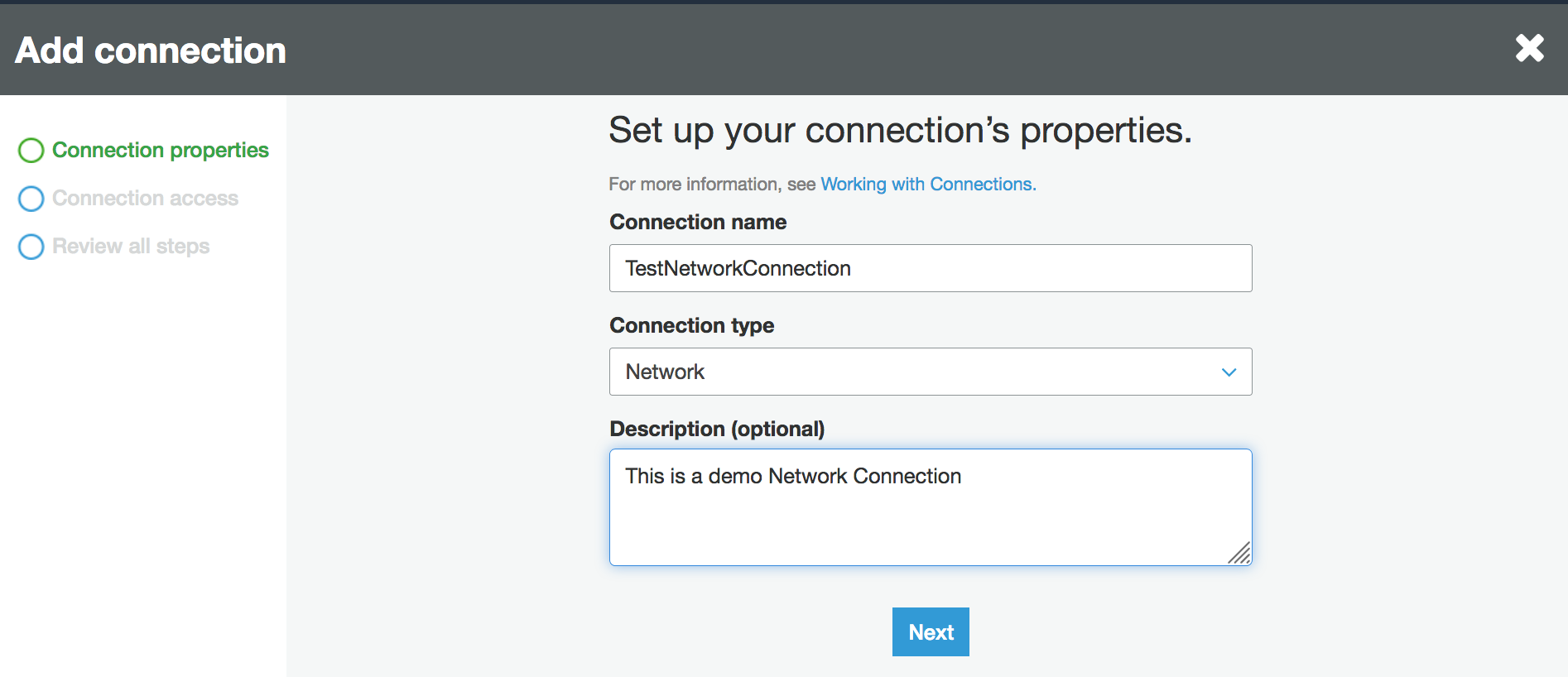
-
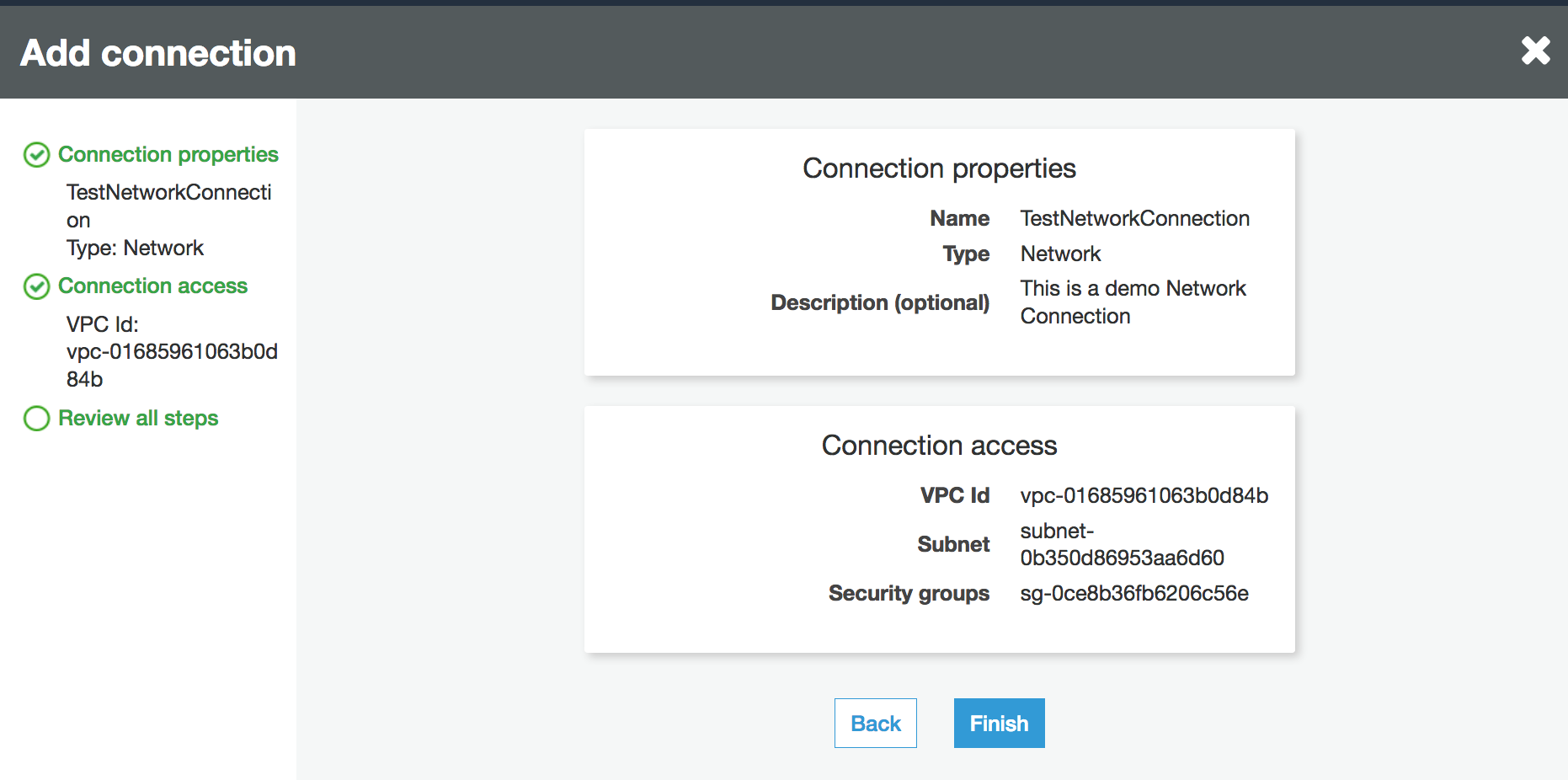
Configura le informazioni su VPC, sottorete e gruppi di sicurezza.
-
VPC: scegli il nome del VPC che contiene l'archivio dati.
-
Sottorete: scegli una sottorete nel VPC.
-
Gruppi di sicurezza: scegli uno o più gruppi di protezione che consentono l'accesso all'archivio dati nel VPC.
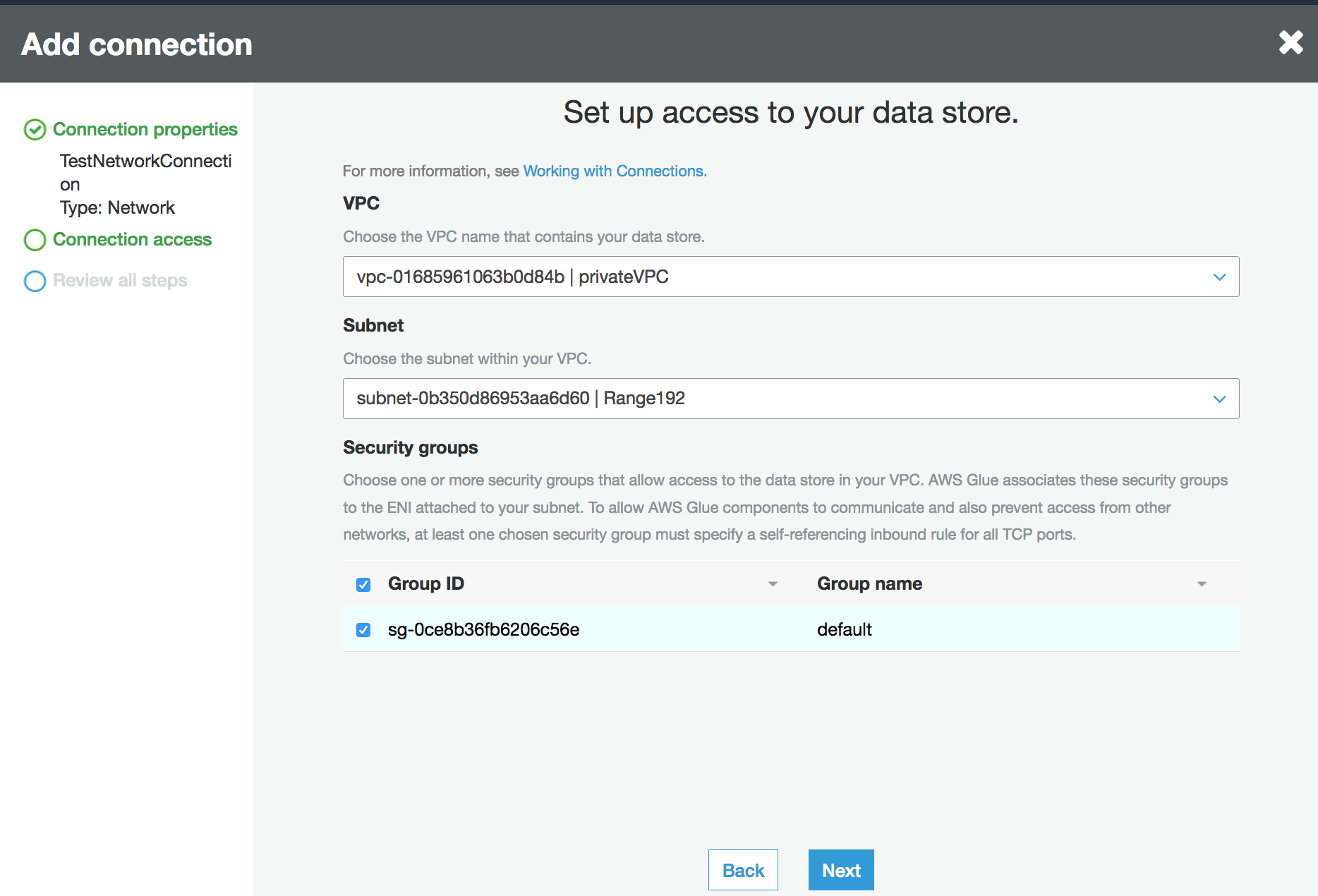
-
-
Seleziona Next (Successivo).
-
Verifica le informazioni di connessione e scegli Finish (Termina).
Test della connessione ad Amazon S3
Una volta creata la connessione di Network, puoi testare la connettività al tuo archivio dati Amazon S3 in un endpoint VPC.
Durante il test di una connessione possono verificarsi i seguenti errori:
-
ERRORE DI CONNESSIONE A INTERNET: indica un problema di connessione a Internet
-
ERRORE DI BUCKET NON VALIDO: indica un problema con il bucket Amazon S3
-
ERRORE DI CONNESSIONE S3: indica un errore di connessione ad Amazon S3
-
ERRORE DI TIPO DI CONNESSIONE: indica che il tipo di connessione non ha il valore previsto,
NETWORK -
TIPO DI TEST DI CONNESSIONE NON VALIDO: indica un problema con il tipo di test della connessione di rete
-
DESTINAZIONE NON VALIDA: indica che il bucket Amazon S3 non è stato specificato correttamente
Per testare una connessione Network:
-
Seleziona la connessione Network (Rete) nella console AWS Glue .
-
Scegli Test Connection (Connessione di prova).
-
Scegli il ruolo IAM creato nel passaggio precedente e specifica un bucket Amazon S3.
-
Per verificare la connessione, scegli Test connection (Testa connessione). Potrebbero essere necessari alcuni istanti prima che il risultato venga visualizzato.
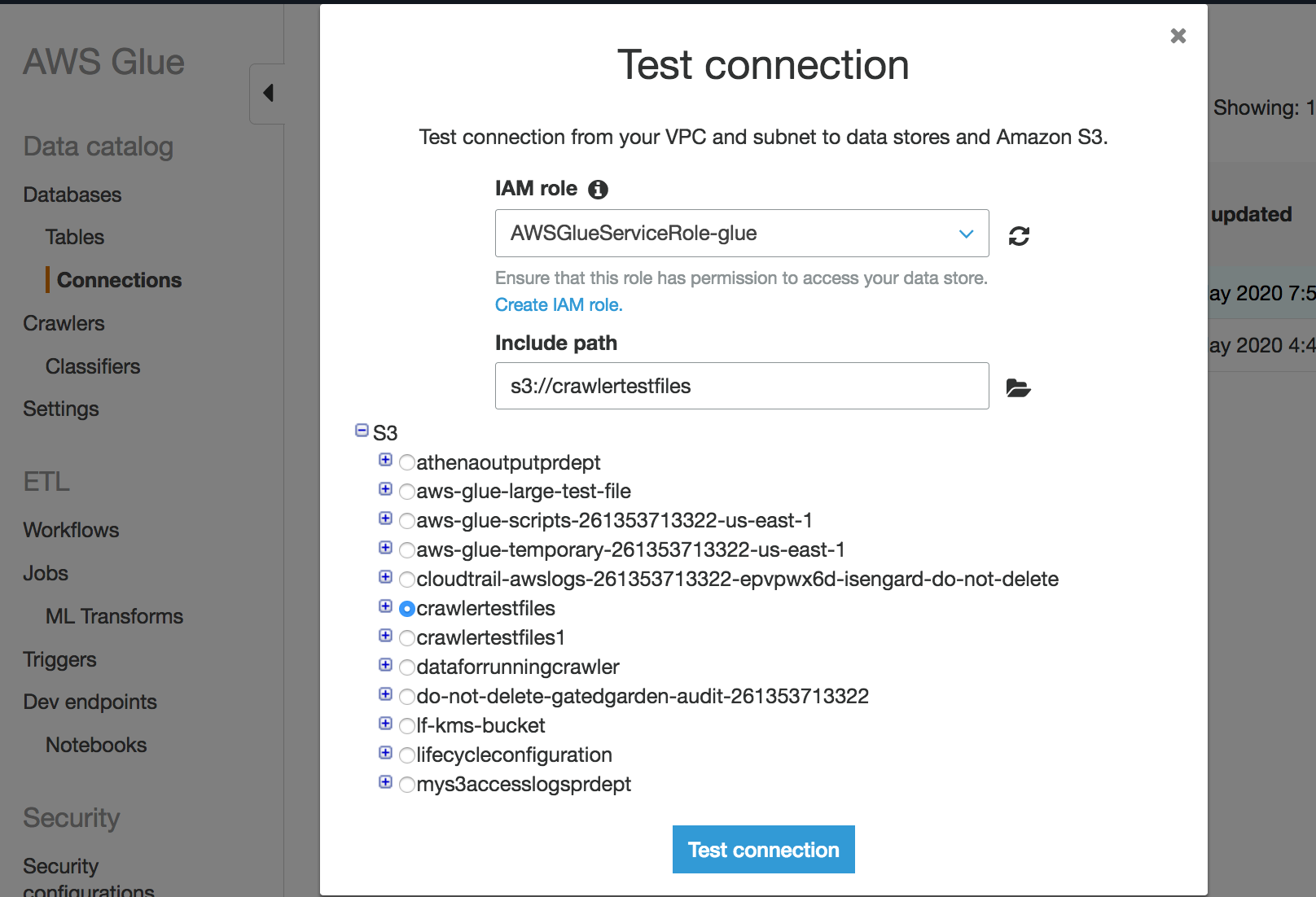
Se viene visualizzato un errore, controlla quanto segue:
-
I privilegi corretti vengono forniti al ruolo selezionato.
-
Viene fornito il bucket Amazon S3 corretto.
-
I gruppi di sicurezza e la lista di controllo degli accessi di rete consentono il traffico in entrata e in uscita necessario.
-
Il VPC specificato è connesso a un endpoint VPC Amazon S3.
Dopo aver testato correttamente la connessione, è possibile creare un crawler.
Creazione di un crawler per un archivio di dati Amazon S3
Ora è possibile creare un crawler che specifichi la connessione di Network creata. Per ulteriori dettagli sulla creazione di un crawler, consulta Configurazione di un crawler.
-
Inizia selezionando Crawler nel riquadro di navigazione della console. AWS Glue
-
Scegli Add crawler (Aggiungi crawler).
-
Specifica il nome del crawler, quindi scegli Next (Avanti).
-
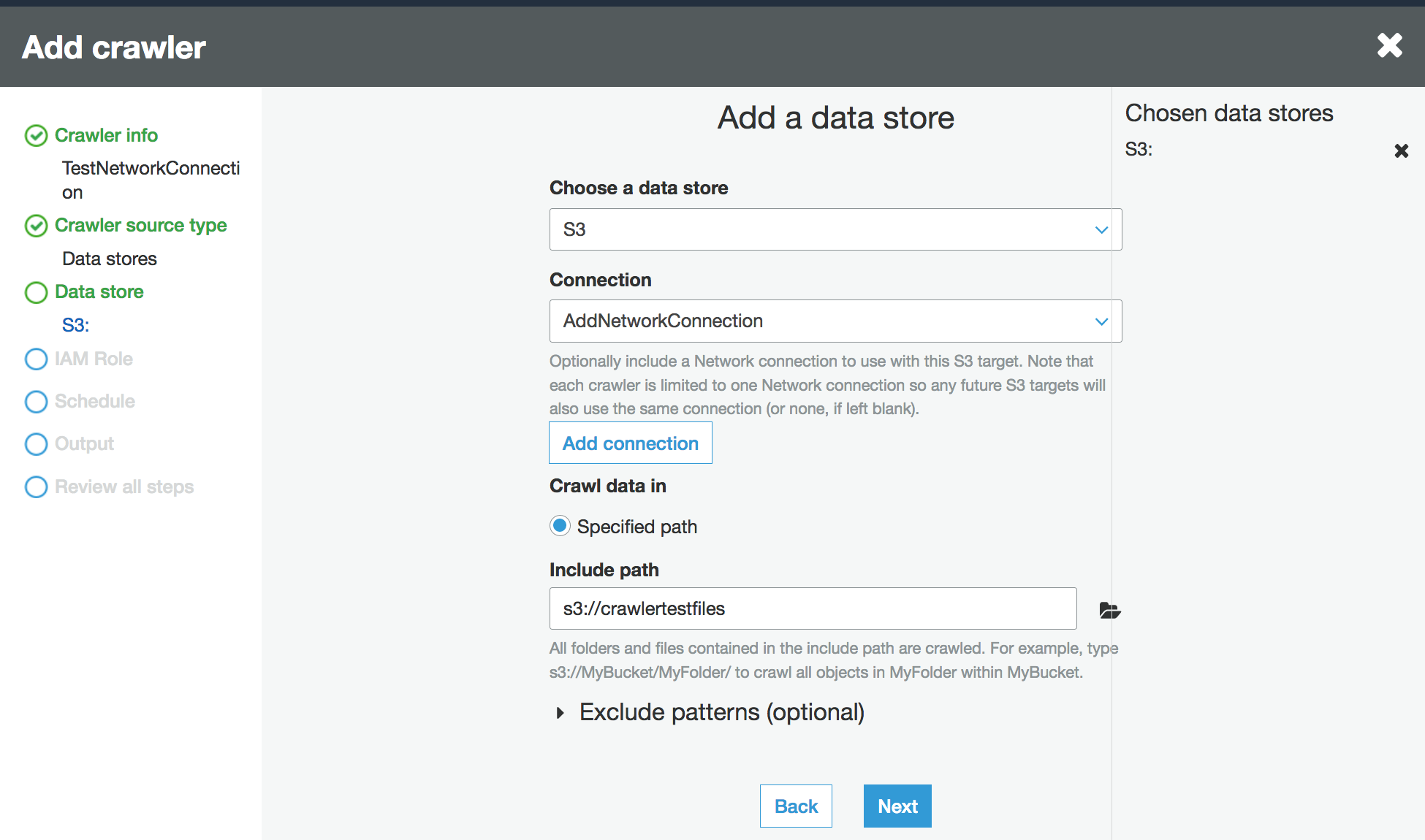
Quando viene richiesto di specificare l'origine dati, seleziona S3 e specifica il prefisso del bucket Amazon S3 e la connessione creata in precedenza.
-
Se necessario, aggiungi un altro archivio dati sulla stessa connessione di rete.
-
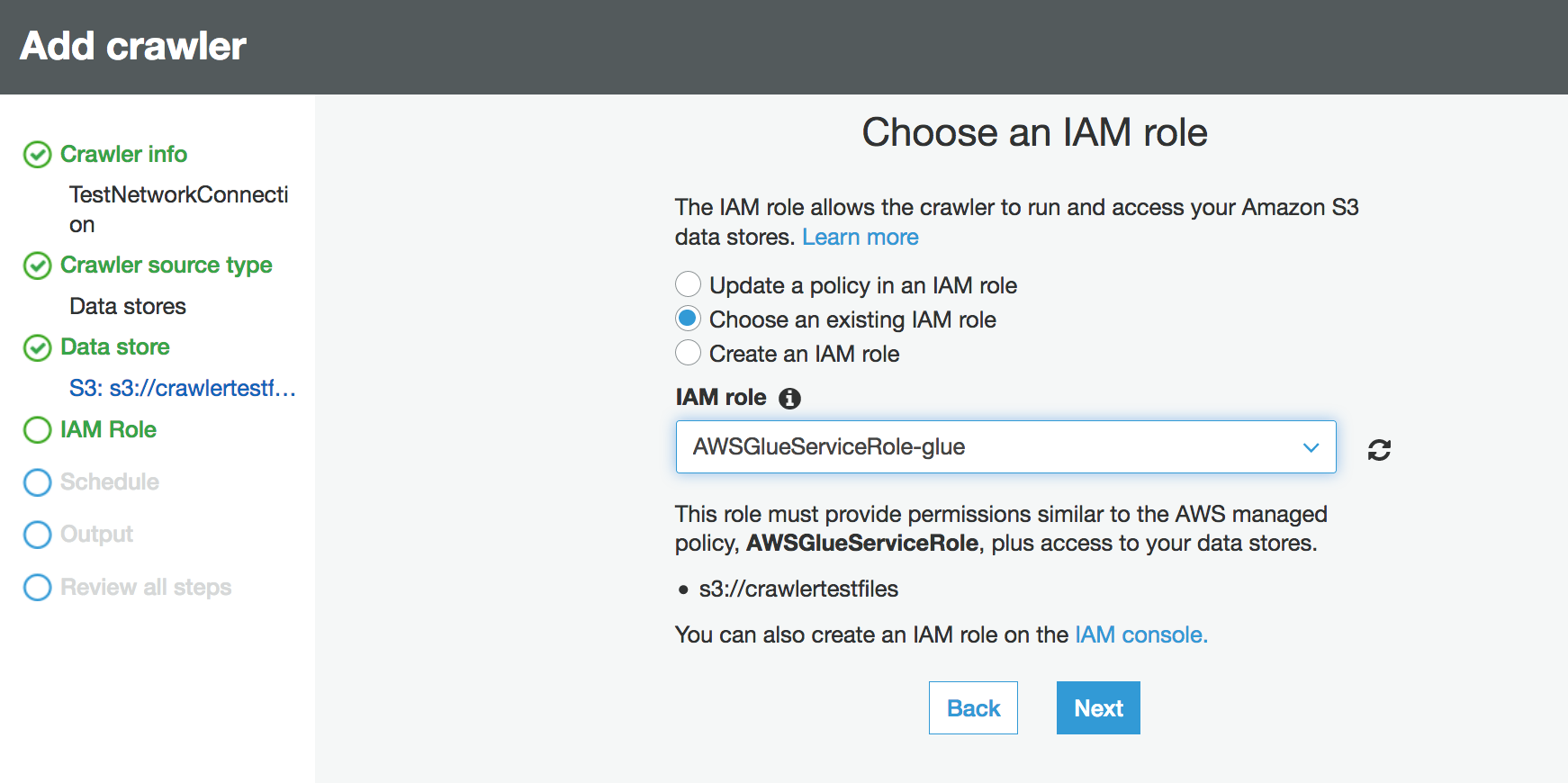
Scegli il ruolo IAM. Il ruolo IAM deve consentire l'accesso al servizio AWS Glue e al bucket Amazon S3. Per ulteriori informazioni, consulta Configurazione di un crawler.
-
Definisci la pianificazione per il crawler.
-
Scegli un database esistente nel catalogo dati oppure crea una nuova voce del database.
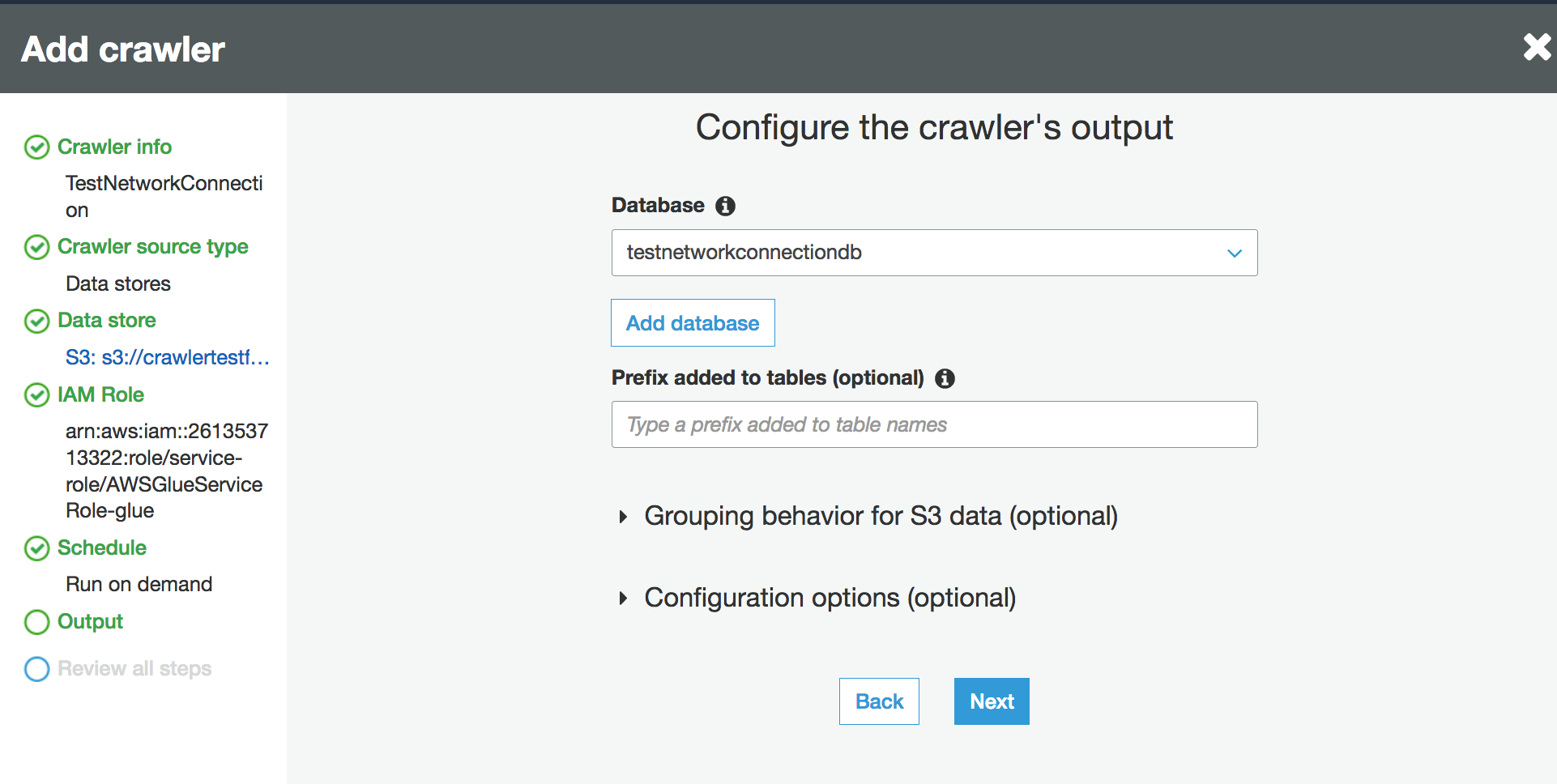
-
Completa la configurazione rimanente.
Creazione di un crawler per le tabelle del Catalogo dati supportate da Amazon S3
Ora è possibile creare un crawler che specifichi la connessione di Network creata e il tipo di fonte del Catalogo. Per ulteriori dettagli sulla creazione di un crawler, consulta Configurazione di un crawler.
-
Inizia scegliendo Crawler nel riquadro di navigazione della console. AWS Glue
-
Scegli Add crawler (Aggiungi crawler).
-
Specifica il nome del crawler, quindi scegli Next (Avanti).
-
Quando viene richiesto il tipo di origine crawler, scegliere Existing catalog tables (Tabelle di catalogo esistenti) e specificare le tabelle di catalogo esistenti da eseguire per il crawling dall'elenco delle tabelle disponibili.
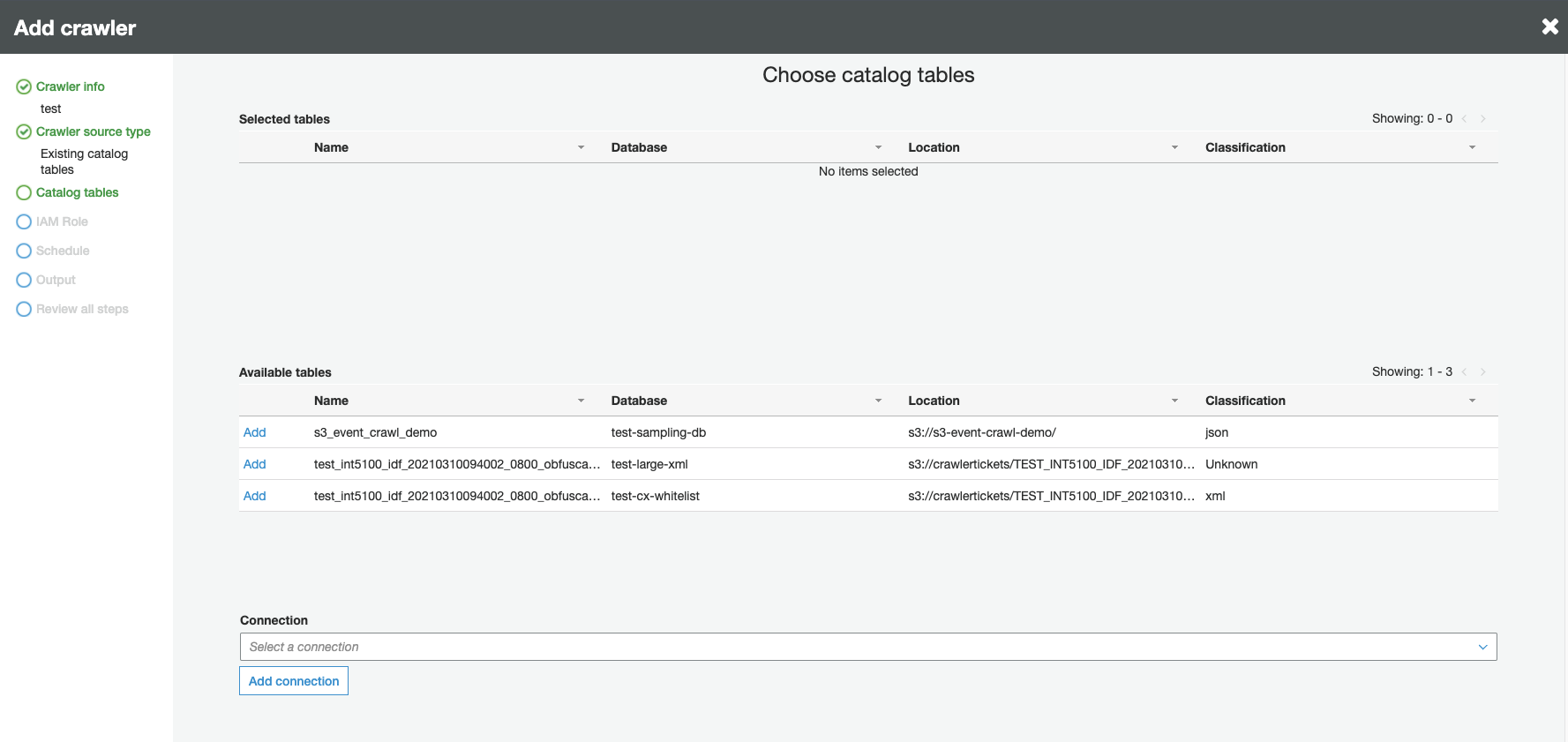
-
Scegli il ruolo IAM. Il ruolo IAM deve consentire l'accesso al servizio AWS Glue e al bucket Amazon S3. Per ulteriori informazioni, consulta Configurazione di un crawler.
-
Definisci la pianificazione per il crawler.
-
Scegli un database esistente nel catalogo dati oppure crea una nuova voce del database.
-
Completa la configurazione rimanente e rivedi i passaggi.
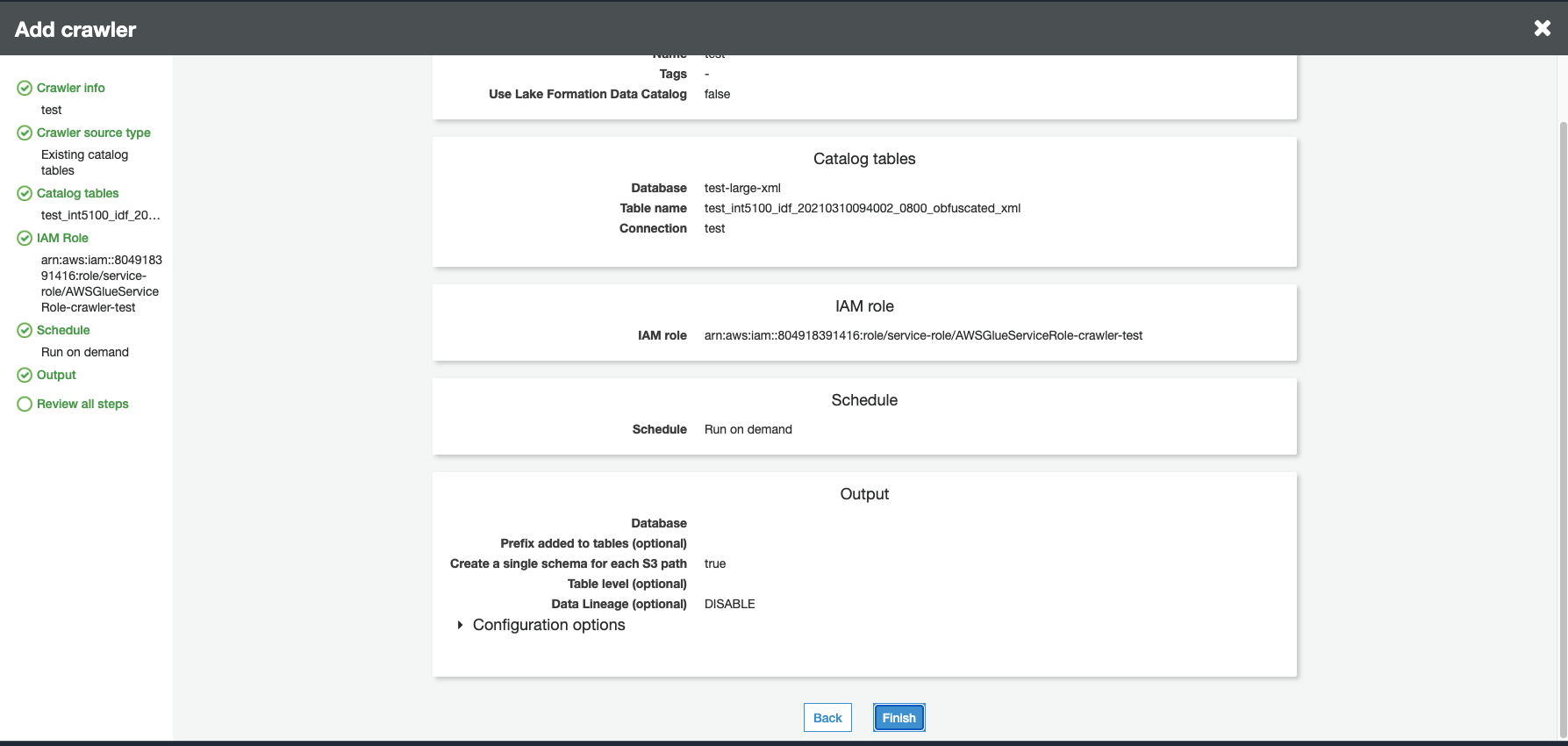
Esecuzione di un crawler
Esegui il crawler.

Risoluzione dei problemi
Per la risoluzione dei problemi relativi ai bucket Amazon S3 che utilizzano un gateway VPC, consulta l'argomento relativo alle difficoltà di connessione a un bucket S3 usando un endpoint VPC gateway
