Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Aggiunta di una connessione JDBC utilizzando i propri driver JDBC
Quando si utilizza una connessione JDBC è possibile utilizzare il proprio driver JDBC. Quando il driver predefinito utilizzato dal AWS Glue crawler non è in grado di connettersi a un database, è possibile utilizzare il proprio driver JDBC. Ad esempio, se desideri utilizzare SHA-256 con il tuo database Postgres e i driver Postgres precedenti non lo supportano, puoi utilizzare il tuo driver JDBC.
Origini dati supportate
| Origini dati supportate | Origini dati non supportate |
|---|---|
| MySQL | Snowflake |
| Postgres | |
| Oracle | |
| Redshift | |
| SQL Server | |
| Aurora* |
* Supportato se si utilizza il driver JDBC nativo. Non è possibile avvalersi di tutte le funzionalità del driver.
Aggiunta del driver JDBC a una connessione JDBC
Nota
Se scegli di importare le tue versioni dei driver JDBC, AWS Glue i crawler consumeranno risorse nei job e nei bucket AWS Glue Amazon S3 per garantire che il driver fornito venga eseguito nel tuo ambiente. L'utilizzo aggiuntivo delle risorse si rifletterà nel tuo account. Il costo dei AWS Glue crawler e dei job rientra nella categoria della fatturazione. AWS Glue Inoltre, è importante sottolineare che anche se si fornisce il proprio driver JDBC, ciò non implica automaticamente che il crawler possa sfruttare tutte le funzionalità offerte da tale driver.
Per aggiungere il proprio driver JDBC a una connessione JDBC:
-
Aggiungi il file del driver JDBC a una posizione Amazon S3. È possibile creare una cartella bucket o utilizzare una and/or cartella bucket esistente. and/or
-
Nella AWS Glue console, scegli Connessioni nel menu a sinistra sotto Data Catalog, quindi crea una nuova connessione.
-
Completa i campi per le Proprietà di connessione e scegli JDBC per il Tipo di connessione.
-
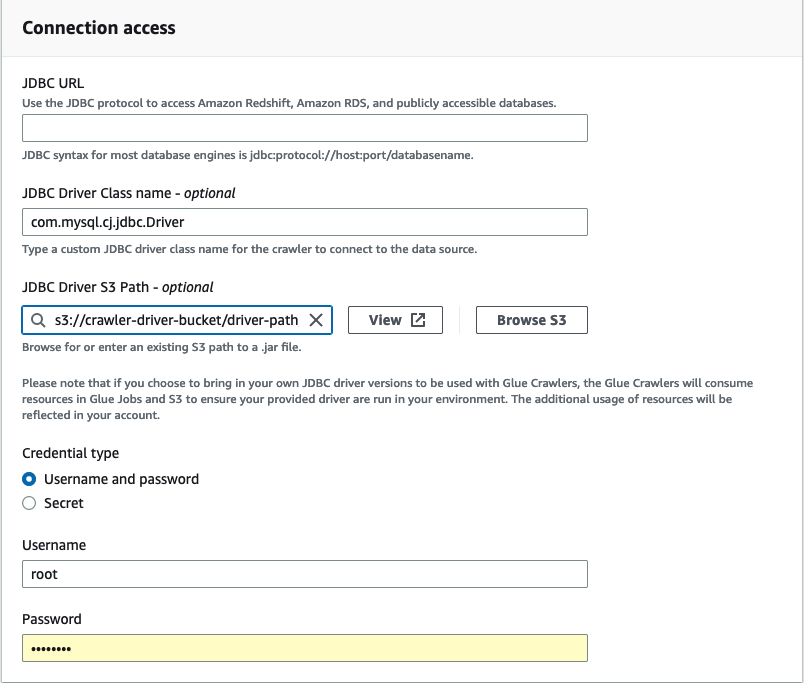
In Accesso alla connessione, inserisci l'URL JDBC e il Nome della classe del driver JDBC - facoltativo. Il nome della classe del driver deve riferirsi a un'origine dati supportata dai crawler. AWS Glue
-
Scegli il percorso Amazon S3 in cui si trova il driver JDBC nel campo Percorso del driver JDBC Amazon S3 - facoltativo.
-
Se inserisci un nome utente e una password o un segreto, completa i campi per Tipo di credenziale. Al termine, scegli Crea connessione.
Nota
Il test delle connessioni personalizzate non è attualmente supportato. Quando esegui il crawling dell'origine dati con un driver JDBC fornito da te, il crawler salta questo passaggio.
-
Aggiungi la connessione appena creata a un crawler. Nella AWS Glue console, scegli Crawler nel menu a sinistra sotto Data Catalog, quindi crea un nuovo crawler.
-
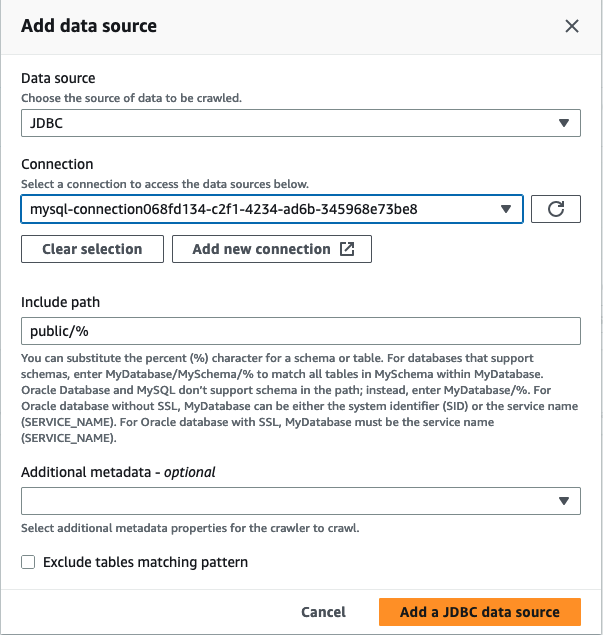
Nella procedura guidata Aggiungi crawler, nel passaggio 2 scegli Aggiungi un'origine dati.
-
Scegli JDBC come origine dati e scegli la connessione creata nei passaggi precedenti. Completa
-
Per utilizzare il tuo driver JDBC con un AWS Glue crawler, aggiungi le seguenti autorizzazioni al ruolo utilizzato dal crawler:
-
Concedi le autorizzazioni per le seguenti operazioni di processo:
CreateJob,DeleteJob,GetJob,GetJobRun,StartJobRun. -
Concedi le autorizzazioni per le operazioni IAM:
iam:PassRole -
Concedi le autorizzazioni per le operazioni di Amazon S3:
s3:DeleteObjects,s3:GetObject,s3:ListBucket,s3:PutObject. -
Concedi l'accesso principale al servizio nella policy IAM. bucket/folder
Policy IAM di esempio:
Il AWS Glue crawler crea due cartelle: _glue_job_crawler e _crawler.
Se il driver jar si trova nella cartella, aggiungi le seguenti risorse:
s3://amzn-s3-demo-bucket/driver.jar""Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/_glue_job_crawler/*", "arn:aws:s3:::amzn-s3-demo-bucket/_crawler/*" ]Se il driver jar si trova nella
s3://amzn-s3-demo-bucket/tmp/driver/subfolder/driver.jar"cartella, aggiungi le seguenti risorse:"Resource": [ "arn:aws:s3:::amzn-s3-demo-bucket/tmp/_glue_job_crawler/*", "arn:aws:s3:::amzn-s3-demo-bucket/tmp/_crawler/*" ] -
-
Se si utilizza un VPC, è necessario consentire l'accesso all' AWS Glue endpoint creando l'endpoint dell'interfaccia e aggiungendolo alla tabella di routing. Per ulteriori informazioni, consulta Creazione di un endpoint VPC di interfaccia per AWS Glue
-
Se utilizzi la crittografia nel tuo Data Catalog, crea l'endpoint di AWS KMS interfaccia e aggiungilo alla tabella di routing. Per ulteriori informazioni, consulta la pagina Creating a VPC endpoint for AWS KMS.
