Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creazione di tabelle
Anche se l'esecuzione di un crawler è il metodo consigliato per fare l'inventario dei dati negli archivi dati, puoi aggiungere tabelle di metadati manualmente. AWS Glue Data Catalog Questo approccio consente di avere un maggiore controllo sulle definizioni dei metadati e di personalizzarle in base a requisiti specifici.
Puoi anche aggiungere tabelle al Data Catalog manualmente nei seguenti modi:
-
Usando la console AWS Glue per creare manualmente una tabella nel AWS Glue Data Catalog. Per ulteriori informazioni, consulta Creazione di tabelle utilizzando la console.
-
Usando l'operazione
CreateTablenell'AWS Glue API per creare una tabella nel AWS Glue Data Catalog Per ulteriori informazioni, consulta CreateTable azione (Python: create_table). -
Usa AWS CloudFormation i modelli. Per ulteriori informazioni, consulta AWS CloudFormation per AWS Glue.
Quando definisci manualmente una tabella utilizzando la console o un'API, specifichi lo schema della tabella e il valore di un campo di classificazione che indica il tipo e il formato dei dati nell'origine dati. Se un crawler crea la tabella, lo schema e il formato dei dati sono determinati da un classificatore incorporato o da un classificatore personalizzato. Per ulteriori informazioni sulla creazione di una tabella tramite la console AWS Glue, consulta Creazione di tabelle utilizzando la console.
Argomenti
Partizioni tabella
Un a definizione di tabella AWS Glue di una cartella Amazon Simple Storage Service (Amazon S3) può descrivere una tabella partizionata. Ad esempio, per migliorare le prestazioni delle query, una tabella partizionata potrebbe separare i dati mensili in diversi file utilizzando il nome del mese come chiave. Le definizioni di tabella in AWS Glue includono la chiave di partizionamento di una tabella. Quando AWS Glue valuta i dati nelle cartelle Amazon S3 per catalogare una tabella, determina se viene aggiunta una singola tabella o una tabella partizionata.
È possibile creare indici delle partizioni su una tabella per recuperare un sottoinsieme delle partizioni invece di caricare tutte le partizioni nella tabella. Per ulteriori informazioni sull'utilizzo degli indici delle partizioni, consulta Creazione di indici di partizione .
Perché AWS Glue possa creare una tabella partizionata per una cartella Amazon S3, devono essere vere tutte le condizioni seguenti:
-
Gli schemi dei file sono simili, come stabilito da AWS Glue.
-
Il formato dati dei file è lo stesso.
-
Il formato di compressione dei file è lo stesso.
Ad esempio, puoi avere un tuo bucket Amazon S3 denominato my-app-bucket, in cui vengono memorizzati i dati di vendita delle app iOS e Android. I dati sono partizionati in base ad anno, mese e giorno. I file di dati per le vendite iOS e Android hanno lo stesso schema, formato dei dati e formato di compressione. In AWS Glue Data Catalog, il AWS Glue crawler crea una definizione di tabella con chiavi di partizionamento per anno, mese e giorno.
Il seguente elenco Amazon S3 di my-app-bucket mostra alcune delle partizioni. Il simbolo = viene utilizzato per assegnare i valori di chiave di partizione.
my-app-bucket/Sales/year=2010/month=feb/day=1/iOS.csv my-app-bucket/Sales/year=2010/month=feb/day=1/Android.csv my-app-bucket/Sales/year=2010/month=feb/day=2/iOS.csv my-app-bucket/Sales/year=2010/month=feb/day=2/Android.csv ... my-app-bucket/Sales/year=2017/month=feb/day=4/iOS.csv my-app-bucket/Sales/year=2017/month=feb/day=4/Android.csv
Collegamenti di risorsa della tabella
| La console AWS Glue è stata recentemente aggiornata. La versione corrente della console non supporta i collegamenti di risorsa alla tabella. |
Il catalogo dati può anche contenere collegamenti di risorsa della tabella. Un collegamento di risorsa della tabella è un collegamento a un database locale o condiviso. Al momento, puoi creare collegamenti di risorsa solo in AWS Lake Formation. Dopo aver creato un collegamento di risorsa a una tabella, è possibile utilizzare il nome del collegamento di risorsa ovunque desideri utilizzare il nome della tabella. Insieme alle tabelle di cui si è proprietari o che sono condivisi con l'utente, i collegamenti di risorsa alla tabella vengono restituiti da glue:GetTables() e vengono visualizzati come voci nella pagina Tables (Tabelle) della console AWS Glue.
Il catalogo dati può anche contenere collegamenti di risorsa ai database.
Per ulteriori informazioni sui collegamenti di risorsa, consulta Creazione di collegamenti di risorsa nella Guida per gli sviluppatori di AWS Lake Formation .
Creazione di tabelle utilizzando la console
Una tabella in AWS Glue Data Catalog è la definizione di metadati che rappresenta i dati in un data store. Puoi creare tabelle quando esegui un crawler oppure puoi creare una tabella manualmente nella console AWS Glue . L'elenco Tables (Tabelle) nella console AWS Glue mostra i valori dei metadati della tabella. Usa le definizioni di tabella per specificare origini e destinazioni al momento della creazione di processi ETL (estrazione, trasformazione e caricamento).
Nota
A seguito delle recenti modifiche alla console di AWS gestione, potrebbe essere necessario modificare i ruoli IAM esistenti per disporre dell'SearchTablesautorizzazione. Per la creazione di nuovi ruoli, l'autorizzazione dell'API SearchTables è già stata aggiunta come impostazione predefinita.
Per iniziare, accedi AWS Management Console e apri la AWS Glue console all'indirizzo https://console.aws.amazon.com/glue/
Aggiunta di tabelle nella console
Per usare un crawler per aggiungere tabelle, scegli Add tables (Aggiungi tabelle), Add tables using a crawler (Aggiungi tabelle utilizzando un crawler). Quindi segui le istruzioni nella procedura guidata Add crawler (Aggiungi crawler). Quando il crawler viene eseguito, vengono aggiunte tabelle al AWS Glue Data Catalog. Per ulteriori informazioni, consulta Utilizzo dei crawler per popolare il Data Catalog .
Se conosci gli attributi necessari per creare una definizione di tabella Amazon Simple Storage Service (Amazon S3) nel catalogo dati, puoi crearla con la procedura guidata di creazione di tabelle. Scegli Add tables (Aggiungi tabelle), Add table manually (Aggiungi tabella manualmente) e segui le istruzioni della procedura guidata Add tables (Aggiungi tabella).
Quando aggiungi una tabella manualmente attraverso la console, considera quanto segue:
-
Se prevedi di accedere alla tabella da Amazon Athena, fornisci un nome con solo caratteri alfanumerici e di sottolineatura. Per ulteriori informazioni, consulta Nomi di Athena.
-
L'ubicazione dei dati di origine deve essere un percorso Amazon S3.
-
Il formato dei dati deve corrispondere a uno dei formati elencati nella procedura guidata. La classificazione corrispondente e SerDe le altre proprietà della tabella vengono compilate automaticamente in base al formato scelto. Puoi definire tabelle con i seguenti formati:
- Avro
-
Formato binario Apache Avro JSON.
- CSV
-
Character separated values. Puoi anche specificare il delimitatore di virgola, barra verticale, punto e virgola, tab o Ctrl-A.
- JSON
-
JavaScript Notazione degli oggetti.
- XML
-
Formato Extensible Markup Language. Specifica il tag XML che definisce una riga nei dati. Le colonne sono definite all'interno di tag di riga.
- Parquet
-
Storage a colonne Apache Parquet.
- ORC
-
Formato di file Optimized Row Columnar (ORC). Un formato progettato per archiviare in modo efficiente i dati Hive.
-
Puoi definire una chiave di partizione per la tabella.
-
Al momento, le tabelle partizionate che crei con la console non possono essere utilizzate in processi ETL.
Attributi della tabella
Di seguito sono elencati alcuni importanti attributi della tua tabella:
- Nome
-
Il nome viene stabilito in fase di creazione della tabella e non può essere modificato. Dovrai fare riferimento a un nome di tabella in molte operazioni AWS Glue.
- Database
-
L'oggetto container in cui la tabella risiede. Questo oggetto contiene un'organizzazione delle tabelle che esiste all'interno dell'archivio dati AWS Glue Data Catalog e potrebbe differire da quella dell'organizzazione del data store. Quando elimini un database, anche tutte le tabelle in esso contenute vengono eliminate dal catalogo dati.
- Descrizione
-
La descrizione della tabella. Puoi scrivere una descrizione per aiutarti a comprendere i contenuti della tabella.
- Formato della tabella
-
Specificate la creazione di una AWS Glue tabella standard o di una tabella in formato Apache Iceberg.
Il Data Catalog offre le seguenti opzioni di ottimizzazione delle tabelle per gestire l'archiviazione delle tabelle e migliorare le prestazioni delle query per le tabelle Iceberg.
-
Compattazione: i file di dati vengono uniti e riscritti, rimuovono i dati obsoleti e consolidano i dati frammentati in file più grandi ed efficienti.
Conservazione delle istantanee: le istantanee sono versioni con data e ora di una tabella Iceberg. Le configurazioni di conservazione delle istantanee consentono ai clienti di stabilire per quanto tempo conservare le istantanee e quante istantanee conservare. La configurazione di un ottimizzatore di conservazione delle istantanee può aiutare a gestire il sovraccarico di archiviazione rimuovendo le istantanee più vecchie e non necessarie e i relativi file sottostanti.
Eliminazione di file orfani: i file orfani sono file a cui non fanno più riferimento i metadati della tabella Iceberg. Questi file possono accumularsi nel tempo, soprattutto dopo operazioni come l'eliminazione di tabelle o i processi ETL non riusciti. L'abilitazione dell'eliminazione dei file orfani consente di AWS Glue identificare e rimuovere periodicamente questi file non necessari, liberando spazio di archiviazione.
Per ulteriori informazioni, consulta Ottimizzazione delle tabelle Iceberg.
-
- Configurazione di ottimizzazione
È possibile utilizzare le impostazioni predefinite o personalizzare le impostazioni per abilitare gli ottimizzatori di tabella.
- Ruolo IAM
Per eseguire gli ottimizzatori di tabella, il servizio assume un ruolo IAM per tuo conto. Puoi scegliere un ruolo IAM utilizzando il menu a discesa. Assicurati che il ruolo disponga delle autorizzazioni necessarie per abilitare la compattazione.
Consulta Prerequisiti per l'ottimizzazione delle tabelle per ulteriori informazioni sulle autorizzazioni necessarie per il ruolo IAM.
- Ubicazione
-
Il puntatore all'ubicazione dei dati in un datastore rappresentato da questa definizione di tabella.
- Classificazione
-
Un valore di categorizzazione fornito al momento della creazione della tabella. Solitamente viene scritto quando un crawler viene eseguito e specifica il formato dei dati di origine.
- Ultimo aggiornamento
-
Data e ora (UTC) in cui questa tabella è stata aggiornata nel catalogo dati.
- Data aggiunta
-
Data e ora (UTC) in cui questa tabella è stata aggiunta al catalogo dati.
- Deprecated
-
Se AWS Glue rileva che una tabella nel catalogo dati non è più presente nel datastore originale, la contrassegna come obsoleta nel catalogo dati. Se esegui un processo che fa riferimento a una tabella obsoleta, il processo potrebbe fallire. Modifica processi che fanno riferimento a tabelle obsolete per rimuoverle come origini e destinazioni. Consigliamo di eliminare le tabelle obsolete quando non sono più necessarie.
- Connessione
-
Se AWS Glue richiede una connessione al datastore, il nome della connessione è associato alla tabella.
Visualizzazione e gestione dei dettagli delle tabelle
Per vedere i dettagli di una tabella esistente, scegli il nome tabella nell'elenco quindi scegli Action, View details (Operazione, Mostra dettagli).
I dettagli tabella includono le proprietà della tabella e del relativo schema. Questa vista mostra lo schema della tabella, inclusi i nomi colonna nell'ordine definito per la tabella, i tipi di dati e le colonne chiave per le partizioni. Se una colonna è di tipo complesso, puoi scegliere View properties (Visualizza proprietà) per visualizzare i dettagli della struttura di tale campo, come mostrato nell'esempio seguente:
{ "StorageDescriptor": { "cols": { "FieldSchema": [ { "name": "primary-1", "type": "CHAR", "comment": "" }, { "name": "second ", "type": "STRING", "comment": "" } ] }, "location": "s3://aws-logs-111122223333-us-east-1", "inputFormat": "", "outputFormat": "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat", "compressed": "false", "numBuckets": "0", "SerDeInfo": { "name": "", "serializationLib": "org.apache.hadoop.hive.serde2.OpenCSVSerde", "parameters": { "separatorChar": "|" } }, "bucketCols": [], "sortCols": [], "parameters": {}, "SkewedInfo": {}, "storedAsSubDirectories": "false" }, "parameters": { "classification": "csv" } }
Per ulteriori informazioni sulle proprietà di una tabella, come StorageDescriptor, consulta StorageDescriptor struttura.
Per modificare lo schema di una tabella, scegli Edit schema (Modifica schema) per aggiungere o rimuovere colonne, modificarne i nomi e modificare i tipi di dati.
Per confrontare diverse versioni di una tabella, incluso lo schema, scegli Confronta versioni per visualizzare un side-by-side confronto tra due versioni dello schema per una tabella. Per ulteriori informazioni, consulta Confronto delle versioni dello schema delle tabelle .
Per visualizzare i file che costituiscono una partizione Amazon S3, scegli View partition (Visualizza partizione). Per tabelle Amazon S3, la colonna Key (Chiave) visualizza le chiavi di partizione usate per partizionare la tabella nel datastore di origine. Il partizionamento è un modo per dividere una tabella in parti correlate in base ai valori di una colonna chiave, ad esempio data, ubicazione o reparto. Per ulteriori informazioni sulle partizioni, cercare "hive partitioning." su Internet.
Nota
Per ottenere step-by-step indicazioni sulla visualizzazione dei dettagli di una tabella, consulta il tutorial Esplora la tabella nella console.
Confronto delle versioni dello schema delle tabelle
Quando si confrontano due versioni di schemi di tabelle, è possibile confrontare le modifiche apportate alle righe nidificate espandendo e comprimendo le righe nidificate, confrontare gli schemi di due versioni e visualizzare le side-by-side proprietà delle tabelle. side-by-side
Come confrontare le versioni
-
Dalla console AWS Glue, scegli Tabelle, quindi Azioni e scegli Confronta versioni.
-
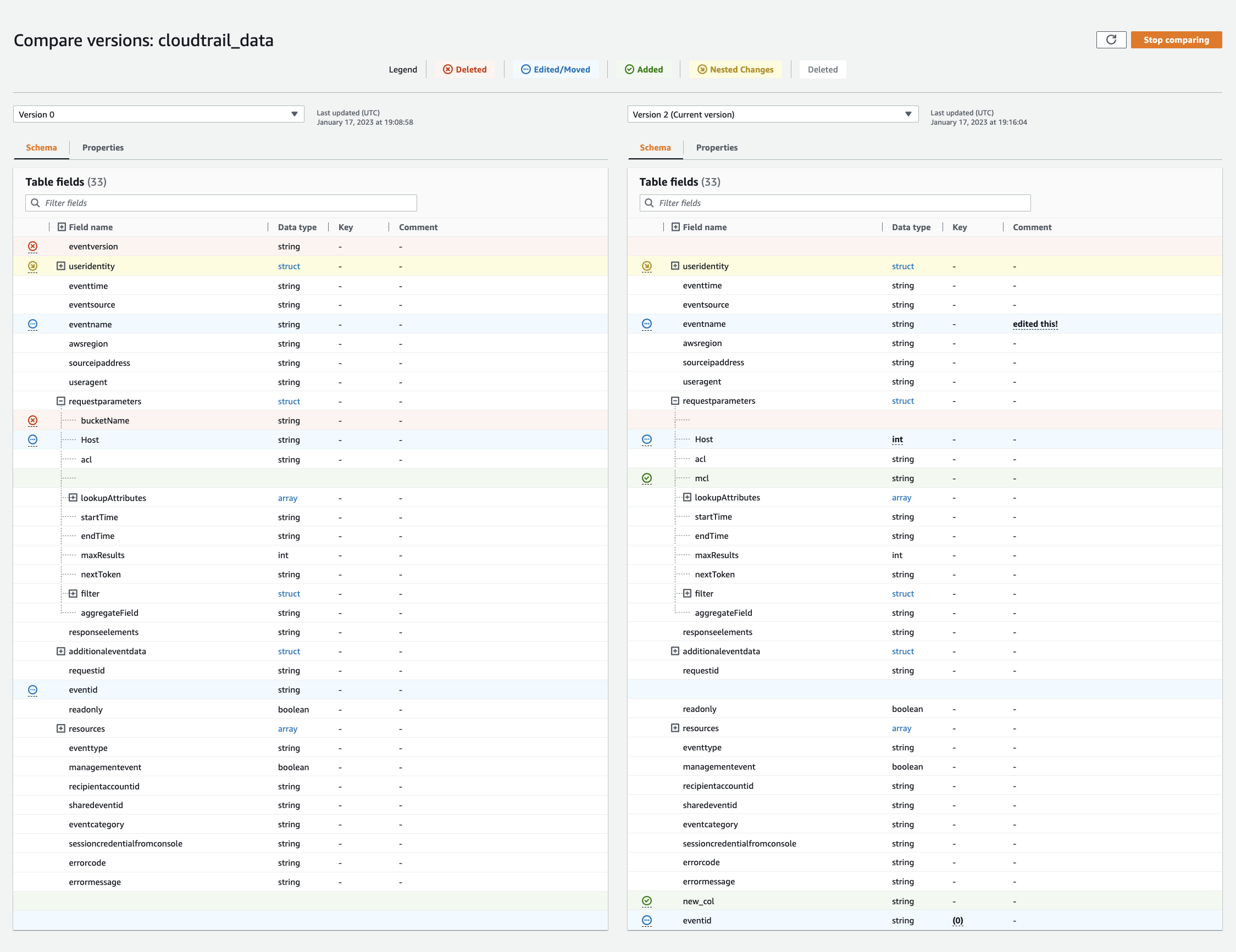
Scegli una versione da confrontare scegliendo il menu a discesa delle versioni. Quando si confrontano gli schemi, la scheda Schema è evidenziata in arancione.
-
Quando si confrontano le tabelle tra due versioni, gli schemi delle tabelle vengono visualizzati sul lato sinistro e destro dello schermo. Ciò consente di determinare visivamente le modifiche confrontando il nome della colonna, il tipo di dati, la chiave e i campi di commento. side-by-side Quando viene apportata una modifica, un'icona colorata mostra il tipo di modifica apportata.
-
Eliminata: contrassegnata da un'icona rossa, indica dove la colonna è stata rimossa da una versione precedente dello schema della tabella.
-
Modificata o spostata: contrassegnata da un'icona blu, indica dove la colonna è stata modificata o spostata in una versione più recente dello schema della tabella.
-
Aggiunta: contrassegnata da un'icona verde, indica dove la colonna è stata aggiunta a una versione più recente dello schema della tabella.
-
Modifiche annidate: contrassegnata da un'icona gialla, indica le modifiche nella colonna annidata. Scegli la colonna da espandere e visualizza le colonne che sono state eliminate, modificate, spostate o aggiunte.
-
-
Utilizza la barra di ricerca dei campi di filtro per visualizzare i campi in base ai caratteri che inserisci qui. Se immetti un nome di colonna in una delle versioni della tabella, i campi filtrati vengono visualizzati in entrambe le versioni della tabella per mostrare dove sono state apportate le modifiche.
-
Per confrontare le proprietà, scegli la scheda Proprietà.
-
Per interrompere il confronto tra le versioni, scegli Interrompi confronto per tornare all'elenco delle tabelle.
Aggiornamento delle tabelle del catalogo dati create manualmente usando i crawler
Potresti voler creare le AWS Glue Data Catalog tabelle manualmente e poi mantenerle aggiornate con i AWS Glue crawler. I crawler in esecuzione su una pianificazione possono aggiungere nuove partizioni e aggiornare le tabelle con qualsiasi modifica dello schema. Questo vale anche per le tabelle migrate da un metastore Apache Hive.
Per fare ciò, quando definisci un crawler, invece di specificare uno o più datastoe come origine di un crawling, puoi specificare una o più tabelle del catalogo dati esistenti. Il crawler esegue quindi il crawling dei datastore specificati dalle tabelle del catalogo. In questo caso, non vengono create nuove tabelle mentre le tabelle create manualmente vengono aggiornate.
Di seguito sono riportati altri motivi per cui puoi creare manualmente le tabelle di catalogo e specificarle come origini del crawler:
-
Desideri scegliere il nome della tabella del catalogo e non fare affidamento sull'algoritmo di denominazione della tabella del catalogo.
-
Desideri impedire la creazione di nuove tabelle nel caso in cui i file con un formato che potrebbe interrompere il rilevamento della partizione vengano erroneamente salvati nel percorso dell'origine dati.
Per ulteriori informazioni, consulta Fase 2: Scelta delle origini dei dati e dei classificatori.
Proprietà della tabella del catalogo dati
Le proprietà della tabella, o parametri, come sono noti nella AWS CLI, sono stringhe di chiavi e valori non convalidate. È possibile impostare le proprie proprietà sulla tabella per supportare gli usi del catalogo dati all'esterno di AWS Glue. È possibile che lo facciano anche altri servizi che utilizzano il Data Catalog. AWS Glue imposta alcune proprietà della tabella durante l'esecuzione di job o crawler. Salvo diversa indicazione, queste proprietà sono per uso interno, non supportiamo il fatto che continuino a esistere nella loro forma attuale o che supportino il comportamento del prodotto se queste proprietà vengono modificate manualmente.
Per ulteriori informazioni sulle proprietà delle tabelle impostate dai AWS Glue crawler, consultate. Parametri impostati sulle tabelle del catalogo dati dal crawler
