Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Ciclo di vita degli incidenti in Incident Manager
Strumento di gestione degli incidenti AWS Systems Manager fornisce un step-by-step framework basato sulle migliori pratiche per identificare e reagire agli incidenti, come interruzioni del servizio o minacce alla sicurezza. L'obiettivo principale di Incident Manager è aiutare a ripristinare i servizi o le applicazioni interessati alla normalità il più rapidamente possibile attraverso una soluzione completa di gestione del ciclo di vita degli incidenti.
Come illustrato nella figura seguente, Incident Manager fornisce strumenti e best practice per ogni fase del ciclo di vita dell'incidente:
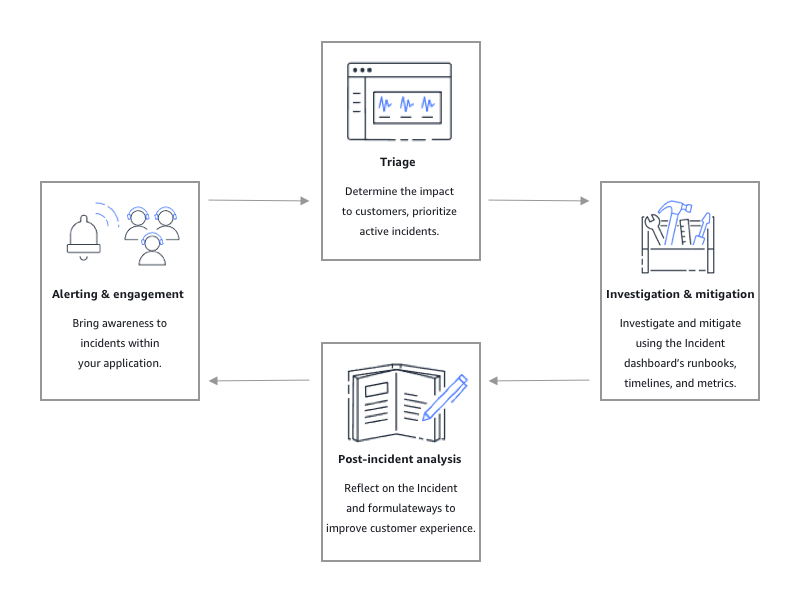
Avvisi e coinvolgimento
La fase di avviso e coinvolgimento del ciclo di vita degli incidenti si concentra sulla sensibilizzazione agli incidenti all'interno delle applicazioni e dei servizi. Questa fase inizia prima che venga rilevato un incidente e richiede una comprensione approfondita delle applicazioni. Puoi utilizzare i CloudWatchparametri di Amazon per monitorare i dati sulle prestazioni delle tue applicazioni o utilizzare Amazon EventBridge per aggregare avvisi provenienti da diverse fonti, applicazioni e servizi. Dopo aver impostato il monitoraggio delle applicazioni, puoi iniziare a inviare avvisi in caso di metriche che non rientrano nella norma storica. Per ulteriori informazioni sulle best practice di monitoraggio, consulta. Monitoraggio
Per supportare la diagnosi degli incidenti da parte dei soccorritori, puoi abilitare la funzionalità Findings in Incident Manager. I risultati sono informazioni sulle AWS CodeDeploy implementazioni e sugli aggiornamenti degli AWS CloudFormation stack avvenuti nel periodo in cui si è verificato un incidente. La disponibilità di queste informazioni riduce il tempo necessario per valutare le potenziali cause, il che può ridurre il tempo medio di ripristino (MTTR) a seguito di un incidente.
Ora che state monitorando gli incidenti nelle vostre applicazioni, potete definire un piano di risposta agli incidenti da utilizzare durante un incidente. Per ulteriori informazioni sulla creazione di piani di risposta, consultaCreazione e configurazione dei piani di risposta in Incident Manager. Amazon EventBridge Events or CloudWatch Alarms può creare automaticamente un incidente utilizzando i piani di risposta come modello. Per ulteriori informazioni sulla creazione di incidenti, consultaCreazione di incidenti automaticamente o manualmente in Incident Manager.
I piani di risposta lanciano piani di intensificazione e piani di coinvolgimento correlati per coinvolgere i primi soccorritori nell'incidente. Per ulteriori informazioni sulla configurazione dei piani di escalation, vedere. Crea un piano di escalation Contemporaneamente, Amazon Q Developer nelle applicazioni di chat invia notifiche ai soccorritori utilizzando un canale di chat indirizzandoli alla pagina dei dettagli dell'incidente. Utilizzando il canale di chat e i dettagli dell'incidente, il team può comunicare e valutare un incidente. Per ulteriori informazioni sulla configurazione dei canali di chat in Incident Manager, consultaAttività 2: creare un canale di chat in Amazon Q Developer nelle applicazioni di chat.
Triage
Il triage è il momento in cui i primi soccorritori cercano di determinare l'impatto sui clienti. La visualizzazione dei dettagli dell'incidente nella console Incident Manager fornisce ai soccorritori tempistiche e metriche per aiutarli a valutare l'incidente. La valutazione dell'impatto di un incidente pone anche le basi per i tempi di risposta, la risoluzione e la comunicazione dell'incidente. I soccorritori danno priorità agli incidenti utilizzando valutazioni di impatto da 1 (Critico) a 5 (Nessun impatto).
La tua organizzazione può definire l'ambito esatto di ogni valutazione di impatto come preferisci. La tabella seguente fornisce esempi di come ogni livello di impatto potrebbe essere generalmente definito.
| Codice di impatto | Nome dell'impatto | Esempio di ambito definito |
|---|---|---|
1 |
Critical |
Errore completo dell'applicazione che ha un impatto sulla maggior parte dei clienti. |
2 |
High |
Errore completo dell'applicazione che ha un impatto su un sottoinsieme di clienti. |
3 |
Medium |
Errore parziale dell'applicazione con ripercussioni sul cliente. |
4 |
Low |
Guasti intermittenti che hanno un impatto limitato sui clienti. |
5 |
No Impact |
I clienti non sono attualmente interessati, ma è necessaria un'azione urgente per evitare l'impatto. |
Indagine e mitigazione
La visualizzazione dei dettagli degli incidenti fornisce al team i runbook, le tempistiche e le metriche. Per scoprire come gestire un incidente, consulta il. Visualizzazione dei dettagli degli incidenti nella console
I runbook forniscono comunemente procedure di indagine e possono estrarre automaticamente dati o tentare soluzioni di uso comune. I runbook forniscono anche passaggi chiari e ripetibili che il team ha ritenuto utili per mitigare gli incidenti. La scheda Runbook si concentra sulla fase corrente del runbook e mostra le fasi passate e future.
Incident Manager si integra con Systems Manager Automation per creare runbook. Usa i runbook per eseguire una delle seguenti operazioni:
-
Gestisci istanze e risorse AWS
-
Esegui automaticamente gli script
-
Gestisci le risorse AWS CloudFormation
Per ulteriori informazioni sui tipi di azioni supportati, vedere il riferimento alle azioni di Systems Manager Automation nella Guida per l'AWS Systems Manager utente.
La scheda Cronologia mostra quali azioni sono state intraprese. La timeline registra ciascuna con un timestamp e dettagli creati automaticamente. Per aggiungere eventi personalizzati alla sequenza temporale, consulta la Sequenza temporale sezione nella pagina dei dettagli dell'incidente di questa guida per l'utente.
La scheda Diagnosi mostra le metriche compilate automaticamente e le metriche aggiunte manualmente. Questa visualizzazione fornisce informazioni preziose sulle attività dell'applicazione durante un incidente.
La scheda Impegni consente di aggiungere altri contatti all'incidente e aiuta a fornire le risorse necessarie per consentire al contatto coinvolto di mettersi rapidamente al corrente una volta coinvolto nell'incidente. I contatti vengono coinvolti attraverso piani di escalation definiti o piani di coinvolgimento personali.
Utilizzando un canale di chat, puoi interagire direttamente con il tuo incidente e con gli altri soccorritori del tuo team. Utilizzando Amazon Q Developer nelle applicazioni di chat, puoi configurare i canali di chat in. Slack, Microsoft Teamse Amazon Chime. In Slack e Microsoft Teams canali, i soccorritori possono interagire con gli incidenti direttamente dal canale di chat utilizzando una serie di comandi. ssm-incidents Per ulteriori informazioni, consulta Interagire tramite il canale di chat.
Analisi post-incidente
Incident Manager fornisce un framework per riflettere su un incidente, adottare le misure necessarie per evitare che l'incidente si ripeta in futuro e per migliorare le attività di risposta agli incidenti in generale. I miglioramenti possono includere:
-
Modifiche alle applicazioni coinvolte in un incidente. Il tuo team può utilizzare questo tempo per migliorare il sistema e renderlo più tollerante ai guasti.
-
Modifiche a un piano di risposta agli incidenti. Prenditi il tempo necessario per incorporare le lezioni apprese.
-
Modifiche ai runbook. Il tuo team può approfondire i passaggi necessari per la risoluzione e i passaggi che puoi automatizzare.
-
Modifiche agli avvisi. Dopo un incidente, il tuo team potrebbe aver notato dei punti critici nelle metriche che puoi utilizzare per avvisare il team prima di un incidente.
Incident Manager facilita questi potenziali miglioramenti utilizzando una serie di domande di analisi post-incidente e di azioni da intraprendere insieme alla cronologia dell'incidente. Per ulteriori informazioni sul miglioramento attraverso l'analisi, vedere. Performing a post-incident analysis in Incident Manager
