Non aggiorniamo più il servizio Amazon Machine Learning né accettiamo nuovi utenti. Questa documentazione è disponibile per gli utenti esistenti, ma non la aggiorniamo più. Per ulteriori informazioni, consulta Cos'è Amazon Machine Learning.
Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Fase 5. Utilizzare il modello ML per generare previsioni
Amazon Machine Learning (Amazon ML) può generare due tipi di previsioni: in batch e in tempo reale.
Una previsione in tempo reale è una previsione per una singola osservazione generata da Amazon ML su richiesta. Le previsioni in tempo reale sono ideali per applicazioni per dispositivi mobili, siti Web e altre applicazioni che devono utilizzare i risultati in modo interattivo.
Una previsione in batch è un insieme di previsioni per un gruppo di osservazioni. Amazon ML elabora insieme i record in una previsione in batch, quindi l'elaborazione può richiedere del tempo. Usare le previsioni in batch per le applicazioni che richiedono previsioni per un set di osservazioni o previsioni che non utilizzano i risultati in modo interattivo.
Per questo tutorial, verrà generata un previsione in tempo reale per prevedere se un potenziale cliente effettuerà la sottoscrizione al nuovo prodotto. Verranno inoltre generate previsioni per un batch di grandi dimensioni di potenziali clienti. Per la previsione in batch, si utilizzerà il file banking-batch.csv che è stato caricato in Fase 1. Preparare i dati.
Iniziamo con una previsione in tempo reale.
Nota
Per le applicazioni che richiedono previsioni in tempo reale, è necessario creare un endpoint in tempo reale per il modello ML. Durante la disponibilità di un endpoint in tempo reale sono previsti addebiti di costi. Prima di decidere di utilizzare le previsioni in tempo reale e iniziare a sostenere i costi associati, è possibile provare a usare la funzione di previsione in tempo reale in un browser Web, senza creare un endpoint in tempo reale. È quanto faremo per questo tutorial.
Per provare una previsione in tempo reale
-
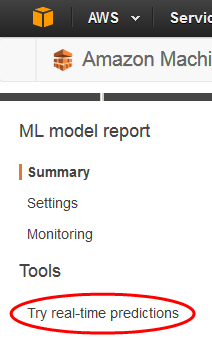
Nel riquadro di navigazione ML model report (Report del modello ML), scegliere Try real-time predictions (Prova le previsioni in tempo reale).
-
Scegliere Paste a record (Incolla un record).

-
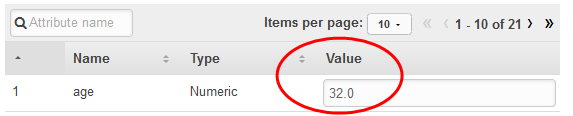
Nella finestra di dialogo Paste a record (Incolla un record), incollare la seguente osservazione:
32,services,divorced,basic.9y,no,unknown,yes,cellular,dec,mon,110,1,11,0,nonexistent,-1.8,94.465,-36.1,0.883,5228.1 -
Nella finestra di dialogo Incolla un record, scegli Invia per confermare che desideri generare una previsione per questa osservazione. Amazon ML inserisce i valori nel modulo di previsione in tempo reale.
Nota
È inoltre possibile popolare i campi Value (Valore) digitando i singoli valori. Indipendentemente dal metodo scelto, si deve fornire un'osservazione che non è stata utilizzata per addestrare il modello.
-
Nella parte inferiore della pagina, scegliere Create prediction (Crea previsione).
La previsione appare nel riquadro Prediction results (Risultati delle previsioni) a destra. Questa previsione ha una Predicted label (Etichetta prevista) corrispondente a
0, il che significa che è improbabile che il potenziale cliente reagisca alla campagna. Una Predicted label (Etichetta prevista) uguale a1significherebbe che è probabile che il cliente reagisca alla campagna.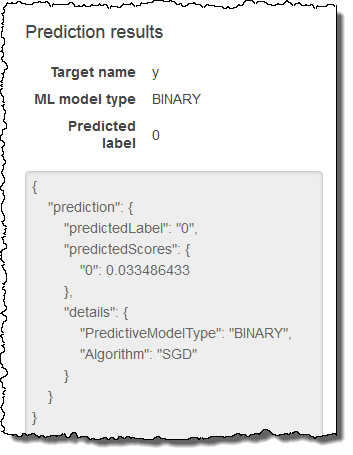
Ora si procede alla creazione di una previsione in batch. Fornirai ad Amazon ML il nome del modello ML che stai utilizzando, la posizione Amazon Simple Storage Service (Amazon S3) dei dati di input per i quali desideri generare previsioni (Amazon ML creerà un'origine dati di previsione in batch da questi dati) e la posizione Amazon S3 per l'archiviazione dei risultati.
Per creare una previsione in batch.
-
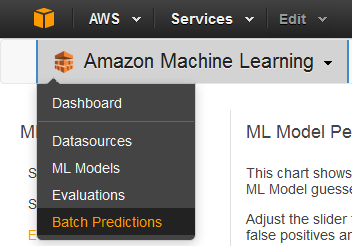
Scegliere Amazon Machine Learning, quindi Batch Predictions (Previsioni in batch).
-
Scegliere Create new batch prediction (Crea nuova previsione in batch).
-
Nella pagina ML model for batch predictions (Modello ML per le previsioni in batch), scegliere ML model: Banking Data 1 (Modello ML: Banking Data 1).
Amazon ML visualizza il nome del modello ML, l'ID, l'ora di creazione e l'ID dell'origine dati associato.
-
Scegli Continua.
-
Per generare previsioni, devi fornire ad Amazon ML i dati per cui ti servono le previsioni. Si chiamano dati di input. Innanzitutto, inserisci i dati di input in un'origine dati in modo che Amazon ML possa accedervi.
Per Locate the input data (Individuare i dati di input), scegliere My data is in S3, and I need to create a datasource (I miei dati sono in S3 e devo creare un'origine dati).

-
Per Datasource name (Nome origine dati), digitare
Banking Data 2. -
Per S3 Location, digita la posizione completa del
banking-batch.csvfile:.your-bucket/banking-batch.csv -
Per Does the first line in your CSV contain the column names? (La prima riga del CSV contiene i nomi di colonna?), scegliere Yes (Sì).
-
Selezionare Verify (Verifica).
Amazon ML convalida la posizione dei tuoi dati.
-
Scegli Continua.
-
Per la destinazione S3, digita il nome della posizione Amazon S3 in cui hai caricato i file nella Fase 1: Prepara i tuoi dati. Amazon ML carica i risultati della previsione lì.
-
Per il nome della previsione Batch, accetta l'impostazione predefinita,
Batch prediction: ML model: Banking Data 1. Amazon ML sceglie il nome predefinito in base al modello che utilizzerà per creare previsioni. In questo tutorial, il modello e le previsioni sono denominati sulla base dell'origine datiBanking Data 1. -
Scegli Rivedi.
-
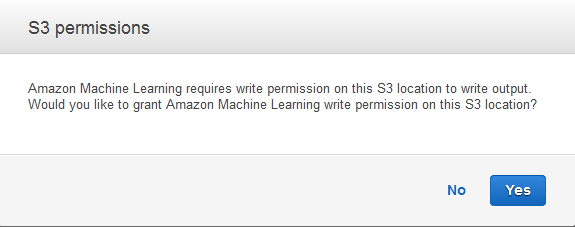
Nella finestra di dialogo S3 permissions (Autorizzazioni S3), scegliere Yes (Sì).
-
Nella pagina Review (Rivedi), scegliere Finish (Fine).
La richiesta di previsione in batch viene inviata ad Amazon ML e inserita in una coda. Il tempo impiegato da Amazon ML per elaborare una previsione in batch dipende dalla dimensione dell'origine dati e dalla complessità del modello di machine learning. Mentre Amazon ML elabora la richiesta, riporta lo stato In corso. Dopo aver completato la previsione in batch, lo stato della richiesta diventa Completed (Completato). A quel punto è possibile visualizzare i risultati.
Per visualizzare le previsioni
-
Scegliere Amazon Machine Learning, quindi Batch Predictions (Previsioni in batch).
-
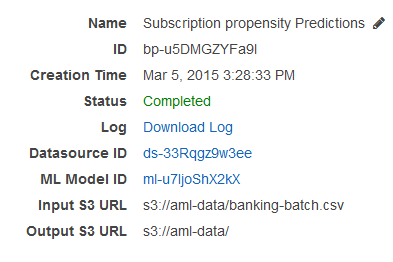
Nell'elenco delle previsioni, scegliere Batch prediction: ML model: Banking Data 1 (Previsione in batch: modello ML: Banking Data 1). Viene visualizzata la pagina Batch prediction info (Informazioni sulla previsione in batch).
-
Per visualizzare i risultati della previsione in batch, vai alla console Amazon S3 all'https://console.aws.amazon.com/s3/
indirizzo e accedi alla posizione Amazon S3 a cui si fa riferimento nel campo URL Output S3. Da qui, accedere alla cartella dei risultati, che ha un nome simile a s3://aml-data/batch-prediction/result.
La previsione è memorizzata in un file compresso .gzip con estensione .gz.
-
Scaricare il file di previsione nel desktop, decomprimerlo e aprirlo.
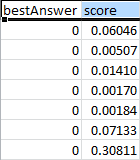
Il file ha due colonne, bestAnswer (migliore risposta) e score (punteggio) e una riga per ogni osservazione all'interno dell'origine dati. I risultati nella colonna bestAnswer (migliore risposta) sono basati sul punteggio soglia di 0,77 impostato in Fase 4. Esaminare le prestazioni predittive del modello ML e impostare un punteggio soglia. Uno score (punteggio) maggiore di 0,77 dà origine a una bestAnswer (migliore risposta) di 1, che costituisce una risposta o previsione positiva, e uno score (punteggio) inferiore a 0,77 dà origine a una bestAnswer (migliore risposta) di 0, che costituisce una risposta o previsione negativa.
I seguenti esempi mostrano previsioni positive e negative basate sul punteggio soglia di 0,77.
Previsione positiva:
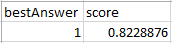
In questo esempio, il valore di bestAnswer (migliore risposta) è 1 e il valore di score (punteggio) è 0,8228876. Il valore di bestAnswer (migliore risposta) è 1 perché score (punteggio) è superiore al punteggio soglia di 0,77. Un valore bestAnswer (migliore risposta) 1 indica che è probabile che il cliente acquisterà il prodotto e, pertanto, è considerata una previsione positiva.
Previsione negativa:
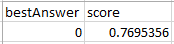
In questo esempio, il valore di bestAnswer (migliore risposta) è 0 perché il valore di score (punteggio) è 0,7695356, che è inferiore al punteggio soglia di 0,77. Un valore bestAnswer (migliore risposta) 0 indica che è improbabile che il cliente acquisterà il prodotto e, pertanto, è considerata una previsione negativa.
Ogni riga del risultato in batch corrisponde a una riga nell'input in batch (un'osservazione nell'origine dati).
Dopo aver analizzato le previsioni, è possibile avviare la campagna di marketing mirata, ad esempio inviando volantini a tutti gli utenti con un punteggio previsto di 1.
Dopo aver creato, rivisto e utilizzato il modello, ripulire i dati e le risorse AWS creati per evitare di incorrere in costi inutili e mantenere il workspace ordinato.
