Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creazione di immagini di pacchetti modello
Un pacchetto di modelli Amazon SageMaker AI è un modello pre-addestrato che fa previsioni e non richiede ulteriore formazione da parte dell'acquirente. Puoi creare un pacchetto modello in SageMaker AI e pubblicare il tuo prodotto di machine learning su. Marketplace AWS Le seguenti sezioni spiegano come creare un pacchetto modello per Marketplace AWS. Ciò include la creazione dell'immagine del contenitore e la creazione e il test dell'immagine localmente.
Panoramica
Un pacchetto modello include i seguenti componenti:
-
Un'immagine di inferenza memorizzata in Amazon Elastic Container Registry
(Amazon ECR) -
(Facoltativo) Artefatti del modello, archiviati separatamente in Amazon S3
Nota
Gli artefatti del modello sono file utilizzati dal modello per fare previsioni e sono generalmente il risultato di processi di formazione personalizzati. Gli artefatti possono essere di qualsiasi tipo di file necessario al modello, ma è necessaria la compressione use.tar.gz. Per i pacchetti di modelli, possono essere raggruppati nella tua immagine di inferenza o archiviati separatamente in Amazon SageMaker AI. Gli artefatti del modello archiviati in Amazon S3 vengono caricati nel contenitore di inferenza in fase di esecuzione. Quando pubblichi il tuo pacchetto modello, questi artefatti vengono pubblicati e archiviati in bucket Amazon S3 di Marketplace AWS proprietà inaccessibili direttamente all'acquirente.
Suggerimento
Se il tuo modello di inferenza è costruito con un framework di deep learning come Gluon, Keras,,,, TensorFlow -Lite o ONNX MXNet PyTorch TensorFlow, prendi in considerazione l'utilizzo di Amazon AI Neo. SageMaker Neo può ottimizzare automaticamente i modelli di inferenza da distribuire su una famiglia specifica di tipi di istanze cloud come, e altri. ml.c4 ml.p2 Per ulteriori informazioni, consulta Optimize model performance using Neo nella Amazon SageMaker AI Developer Guide.
Il diagramma seguente mostra il flusso di lavoro per la pubblicazione e l'utilizzo di prodotti con pacchetti modello.
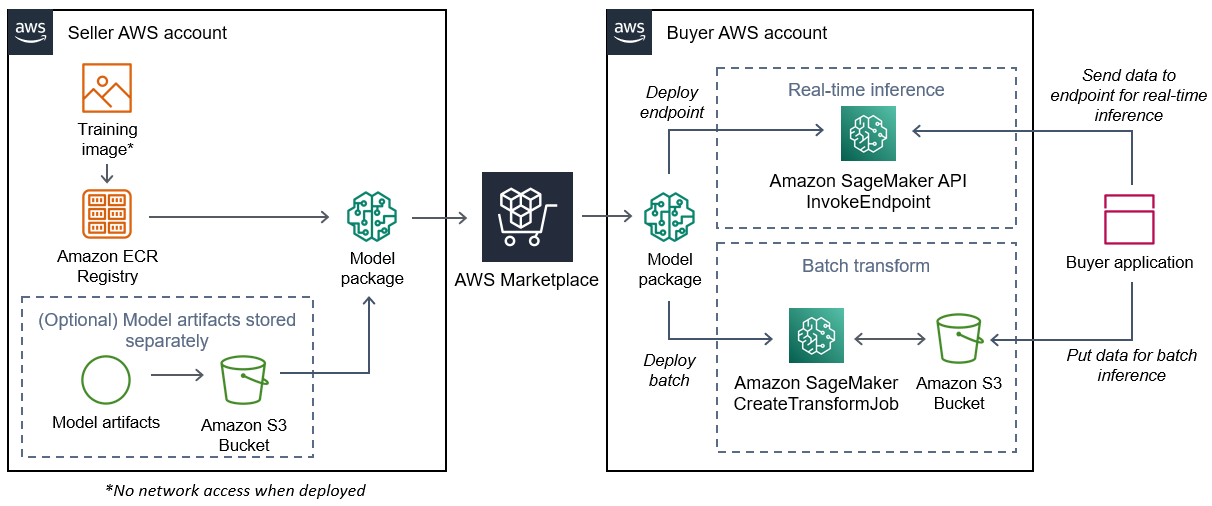
Il flusso di lavoro per la creazione di un pacchetto modello di SageMaker intelligenza artificiale per Marketplace AWS include i seguenti passaggi:
-
Il venditore crea un'immagine di inferenza (nessun accesso alla rete quando viene implementata) e la inserisce nel registro Amazon ECR.
Gli artefatti del modello possono essere raggruppati nell'immagine di inferenza o archiviati separatamente in S3.
-
Il venditore crea quindi una risorsa per il pacchetto modello in Amazon SageMaker AI e pubblica il suo prodotto ML su Marketplace AWS.
-
L'acquirente sottoscrive il prodotto ML e implementa il modello.
Nota
Il modello può essere implementato come endpoint per inferenze in tempo reale o come processo in batch per ottenere previsioni per un intero set di dati contemporaneamente. Per ulteriori informazioni, consulta Deploy Models for Inference.
-
SageMaker L'intelligenza artificiale esegue l'immagine di inferenza. Tutti gli artefatti del modello forniti dal venditore non inclusi nell'immagine di inferenza vengono caricati dinamicamente in fase di esecuzione.
-
SageMaker L'intelligenza artificiale passa i dati di inferenza dell'acquirente al contenitore utilizzando gli endpoint HTTP del contenitore e restituisce i risultati della previsione.
Crea un'immagine di inferenza per i pacchetti modello
Questa sezione fornisce una procedura dettagliata per impacchettare il codice di inferenza in un'immagine di inferenza per il prodotto del pacchetto modello. Il processo prevede i seguenti passaggi:
L'immagine di inferenza è un'immagine Docker contenente la logica di inferenza. Il contenitore in fase di esecuzione espone gli endpoint HTTP per consentire all' SageMaker IA di trasferire dati da e verso il contenitore.
Nota
Quello che segue è solo un esempio di codice di imballaggio per un'immagine di inferenza. Per ulteriori informazioni, consulta Using Docker containers with SageMaker AI e gli esempi di Marketplace AWS
SageMaker intelligenza artificiale
L'esempio seguente utilizza un servizio web, Flask
Passaggio 1: creare l'immagine del contenitore
Affinché l'immagine di inferenza sia compatibile con l' SageMaker intelligenza artificiale, l'immagine Docker deve esporre gli endpoint HTTP. Mentre il container è in esecuzione, l'SageMaker intelligenza artificiale trasmette gli input dell'acquirente per l'inferenza all'endpoint HTTP del contenitore. I risultati dell'inferenza vengono restituiti nel corpo della risposta HTTP.
La procedura dettagliata seguente utilizza la CLI Docker in un ambiente di sviluppo che utilizza una distribuzione Linux Ubuntu.
Crea lo script del server web
Questo esempio utilizza un server Python chiamato Flask
Nota
Flask
Crea uno script del server web Flask che serva i due endpoint HTTP sulla porta TCP 8080 utilizzata da AI. SageMaker I seguenti sono i due endpoint previsti:
-
/ping— SageMaker L'IA invia richieste HTTP GET a questo endpoint per verificare se il contenitore è pronto. Quando il contenitore è pronto, risponde alle richieste HTTP GET su questo endpoint con un codice di risposta HTTP 200. -
/invocations— SageMaker L'IA invia richieste HTTP POST a questo endpoint a scopo di inferenza. I dati di input per l'inferenza vengono inviati nel corpo della richiesta. Il tipo di contenuto specificato dall'utente viene passato nell'intestazione HTTP. Il corpo della risposta è l'output dell'inferenza. Per informazioni dettagliate sui timeout, vedere. Requisiti e best practice per la creazione di prodotti di machine learning
./web_app_serve.py
# Import modules import json import re from flask import Flask from flask import request app = Flask(__name__) # Create a path for health checks @app.route("/ping") def endpoint_ping(): return "" # Create a path for inference @app.route("/invocations", methods=["POST"]) def endpoint_invocations(): # Read the input input_str = request.get_data().decode("utf8") # Add your inference code between these comments. # # # # # # Add your inference code above this comment. # Return a response with a prediction response = {"prediction":"a","text":input_str} return json.dumps(response)
Nell'esempio precedente, non esiste una logica di inferenza effettiva. Per l'immagine di inferenza effettiva, aggiungi la logica di inferenza nell'app Web in modo che elabori l'input e restituisca la previsione effettiva.
L'immagine di inferenza deve contenere tutte le dipendenze richieste perché non avrà accesso a Internet né sarà in grado di effettuare chiamate verso nessuna di esse. Servizi AWS
Nota
Lo stesso codice viene chiamato sia per le inferenze in tempo reale che per quelle in batch
Crea lo script per l'esecuzione del contenitore
Crea uno script denominato serve che l' SageMaker IA esegua quando esegue l'immagine del contenitore Docker. Lo script seguente avvia il server Web HTTP.
./serve
#!/bin/bash # Run flask server on port 8080 for SageMaker flask run --host 0.0.0.0 --port 8080
Creazione del Dockerfile
Crea un Dockerfile nel tuo contesto di compilazione. Questo esempio utilizza Ubuntu 18.04, ma puoi iniziare da qualsiasi immagine di base che funzioni per il tuo framework.
./Dockerfile
FROM ubuntu:18.04 # Specify encoding ENV LC_ALL=C.UTF-8 ENV LANG=C.UTF-8 # Install python-pip RUN apt-get update \ && apt-get install -y python3.6 python3-pip \ && ln -s /usr/bin/python3.6 /usr/bin/python \ && ln -s /usr/bin/pip3 /usr/bin/pip; # Install flask server RUN pip install -U Flask; # Add a web server script to the image # Set an environment to tell flask the script to run COPY /web_app_serve.py /web_app_serve.py ENV FLASK_APP=/web_app_serve.py # Add a script that Amazon SageMaker AI will run # Set run permissions # Prepend program directory to $PATH COPY /serve /opt/program/serve RUN chmod 755 /opt/program/serve ENV PATH=/opt/program:${PATH}
DockerfileAggiunge i due script creati in precedenza all'immagine. La directory dello serve script viene aggiunta al PATH in modo che possa essere eseguita durante l'esecuzione del contenitore.
Package o carica gli artefatti del modello
I due modi per fornire gli artefatti del modello, dall'addestramento del modello all'immagine di inferenza, sono i seguenti:
-
Confezionato staticamente con l'immagine di inferenza.
-
Caricato dinamicamente in fase di esecuzione. Poiché è caricata dinamicamente, puoi utilizzare la stessa immagine per creare pacchetti di diversi modelli di machine learning.
Se desideri impacchettare gli artefatti del modello con l'immagine di inferenza, includi gli artefatti in. Dockerfile
Se desideri caricare gli artefatti del modello in modo dinamico, archivia tali artefatti separatamente in un file compresso (.tar.gz) in Amazon S3. Quando crei il pacchetto del modello, specifica la posizione del file compresso e l' SageMaker IA estrae e copia il contenuto nella directory del contenitore durante l'esecuzione del contenitore. /opt/ml/model/ Quando pubblichi il tuo pacchetto modello, questi artefatti vengono pubblicati e archiviati in bucket Amazon S3 di Marketplace AWS
proprietà inaccessibili direttamente all'acquirente.
Fase 2: Creare e testare l'immagine localmente
Nel contesto della compilazione, ora esistono i seguenti file:
-
./Dockerfile -
./web_app_serve.py -
./serve -
La tua logica di inferenza e le tue dipendenze (opzionali)
Successivamente compila, esegui e testa l'immagine del contenitore.
Costruisci l'immagine
Esegui il comando Docker nel contesto di compilazione per creare e taggare l'immagine. Questo esempio utilizza il tagmy-inference-image.
sudo docker build --tag my-inference-image ./
Dopo aver eseguito questo comando Docker per creare l'immagine, dovresti vedere l'output mentre Docker crea l'immagine in base a ciascuna riga del tuo. Dockerfile Al termine, dovresti vedere qualcosa di simile al seguente.
Successfully built abcdef123456
Successfully tagged my-inference-image:latestEsecuzione di in locale
Una volta completata la compilazione, puoi testare l'immagine localmente.
sudo docker run \ --rm \ --publish 8080:8080/tcp \ --detach \ --name my-inference-container \ my-inference-image \ serve
Di seguito sono riportati i dettagli sul comando:
-
--rm— Rimuove automaticamente il contenitore dopo che si è fermato. -
--publish 8080:8080/tcp— Esponi la porta 8080 per simulare la porta a cui l' SageMaker IA invia le richieste HTTP. -
--detach— Esegui il contenitore in background. -
--name my-inference-container— Assegna un nome a questo contenitore funzionante. -
my-inference-image— Esegui l'immagine creata. -
serve— Esegui lo stesso script che l' SageMaker IA esegue durante l'esecuzione del contenitore.
Dopo aver eseguito questo comando, Docker crea un contenitore dall'immagine di inferenza che hai creato e lo esegue in background. Il contenitore esegue lo serve script, che avvia il server Web a scopo di test.
Esegui il test dell'endpoint HTTP per il ping
Quando l' SageMaker intelligenza artificiale esegue il container, esegue periodicamente il ping dell'endpoint. Quando l'endpoint restituisce una risposta HTTP con codice di stato 200, segnala all' SageMaker IA che il contenitore è pronto per l'inferenza. Puoi verificarlo eseguendo il comando seguente, che verifica l'endpoint e include l'intestazione della risposta.
curl --include http://127.0.0.1:8080/ping
L'output di esempio è il seguente.
HTTP/1.0 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 0
Server: MyServer/0.16.0 Python/3.6.8
Date: Mon, 21 Oct 2019 06:58:54 GMTVerifica l'endpoint HTTP di inferenza
Quando il contenitore indica di essere pronto restituendo un codice di stato 200 al ping, l' SageMaker IA passa i dati di inferenza all'endpoint /invocations HTTP tramite una richiesta. POST Verifica il punto di inferenza eseguendo il comando seguente.
curl \ --request POST \ --data "hello world" \ http://127.0.0.1:8080/invocations
L'output di esempio è il seguente.
{"prediction": "a", "text": "hello
world"}
Con questi due endpoint HTTP funzionanti, l'immagine di inferenza è ora compatibile con SageMaker l'IA.
Nota
Il modello del prodotto del pacchetto modello può essere implementato in due modi: in tempo reale e in batch. In entrambe le implementazioni, l' SageMaker intelligenza artificiale utilizza gli stessi endpoint HTTP durante l'esecuzione del contenitore Docker.
Per arrestare il contenitore, esegui il comando seguente.
sudo docker container stop my-inference-container
Quando l'immagine di inferenza è pronta e testata, puoi continuare a Caricamento delle immagini su Amazon Elastic Container Registry farlo.
