Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Guida introduttiva alle tabelle Apache Iceberg in Amazon Athena SQL
Amazon Athena fornisce supporto integrato per Apache Iceberg. È possibile utilizzare Iceberg senza passaggi o configurazioni aggiuntivi, ad eccezione della configurazione dei prerequisiti del servizio descritti nella sezione Guida introduttiva della documentazione di Athena. Questa sezione fornisce una breve introduzione alla creazione di tabelle in Athena. Per ulteriori informazioni, consulta Lavorare con le tabelle Apache Iceberg utilizzando Athena SQL più avanti in questa guida.
È possibile creare tabelle Iceberg AWS utilizzando motori diversi. Queste tabelle funzionano perfettamente su tutti i tavoli. Servizi AWS Per creare le tue prime tabelle Iceberg con Athena SQL, puoi utilizzare il seguente codice boilerplate.
CREATE TABLE <table_name> ( col_1 string, col_2 string, col_3 bigint, col_ts timestamp) PARTITIONED BY (col_1, <<<partition_transform>>>(col_ts)) LOCATION 's3://<bucket>/<folder>/<table_name>/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
Le sezioni seguenti forniscono esempi di creazione di tabelle Iceberg partizionate e non partizionate in Athena. Per ulteriori informazioni, consulta la sintassi di Iceberg dettagliata nella documentazione di Athena.
Creazione di una tabella non partizionata
L'istruzione di esempio seguente personalizza il codice SQL standard per creare una tabella Iceberg non partizionata in Athena. È possibile aggiungere questa istruzione all'editor di query in Athenaconsole per creare la tabella.
CREATE TABLE athena_iceberg_table ( color string, date string, name string, price bigint, product string, ts timestamp) LOCATION 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/athena_iceberg_table/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
Per step-by-step istruzioni sull'uso dell'editor di query, consulta Guida introduttiva nella documentazione di Athena.
Creazione di una tabella partizionata
L'istruzione seguente crea una tabella partizionata basata sulla data utilizzando il concetto di partizionamento nascosto di Iceberg.day() trasformazione per ricavare partizioni giornaliere, utilizzando il dd-mm-yyyy formato, da una colonna di timestamp. Iceberg non memorizza questo valore come nuova colonna nel set di dati. Invece, il valore viene derivato al volo quando si scrivono o si interrogano dati.
CREATE TABLE athena_iceberg_table_partitioned ( color string, date string, name string, price bigint, product string, ts timestamp) PARTITIONED BY (day(ts)) LOCATION 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/athena_iceberg_table/' TBLPROPERTIES ( 'table_type' ='ICEBERG' )
Creazione di una tabella e caricamento dei dati con una singola istruzione CTAS
Negli esempi partizionati e non partizionati delle sezioni precedenti, le tabelle Iceberg vengono create come tabelle vuote. È possibile caricare dati nelle tabelle utilizzando l'istruzione or. INSERT MERGE In alternativa, è possibile utilizzare un'CREATE TABLE AS SELECT (CTAS)istruzione per creare e caricare dati in una tabella Iceberg in un unico passaggio.
CTAS è il modo migliore in Athena per creare una tabella e caricare dati in un'unica istruzione. L'esempio seguente illustra come utilizzare CTAS per creare una tabella Iceberg (iceberg_ctas_table) da una tabella Hive/Parquet () esistente in Athena. hive_table
CREATE TABLE iceberg_ctas_table WITH ( table_type = 'ICEBERG', is_external = false, location = 's3://DOC_EXAMPLE_BUCKET/ice_warehouse/iceberg_db/iceberg_ctas_table/' ) AS SELECT * FROM "iceberg_db"."hive_table" limit 20 --- SELECT * FROM "iceberg_db"."iceberg_ctas_table" limit 20
Per ulteriori informazioni su CTAS, consulta la documentazione CTAS di Athena.
Inserimento, aggiornamento ed eliminazione dei dati
Athena supporta diversi modi di scrivere dati su una tabella Iceberg utilizzando le istruzioniINSERT INTO, UPDATEMERGE INTO, e M. DELETE FRO
Nota: UPDATEMERGE INTO, e DELETE FROM utilizzate l' merge-on-read approccio con le eliminazioni posizionali. L' copy-on-write approccio non è attualmente supportato in Athena SQL.
Ad esempio, l'istruzione seguente utilizza INSERT INTO per aggiungere dati a una tabella Iceberg:
INSERT INTO "iceberg_db"."ice_table" VALUES ( 'red', '222022-07-19T03:47:29', 'PersonNew', 178, 'Tuna', now() ) SELECT * FROM "iceberg_db"."ice_table" where color = 'red' limit 10;
Output di esempio:

Per ulteriori informazioni, consulta la documentazione di Athena.
Interrogazione delle tabelle Iceberg
È possibile eseguire normali query SQL sulle tabelle Iceberg utilizzando Athena SQL, come illustrato nell'esempio precedente.
Oltre alle consuete interrogazioni, Athena supporta anche le interrogazioni sui viaggi nel tempo per le tabelle Iceberg. Come discusso in precedenza, è possibile modificare i record esistenti mediante aggiornamenti o eliminazioni in una tabella Iceberg, quindi è comodo utilizzare le query sui viaggi nel tempo per esaminare le versioni precedenti della tabella sulla base di un timestamp o di un ID istantaneo.
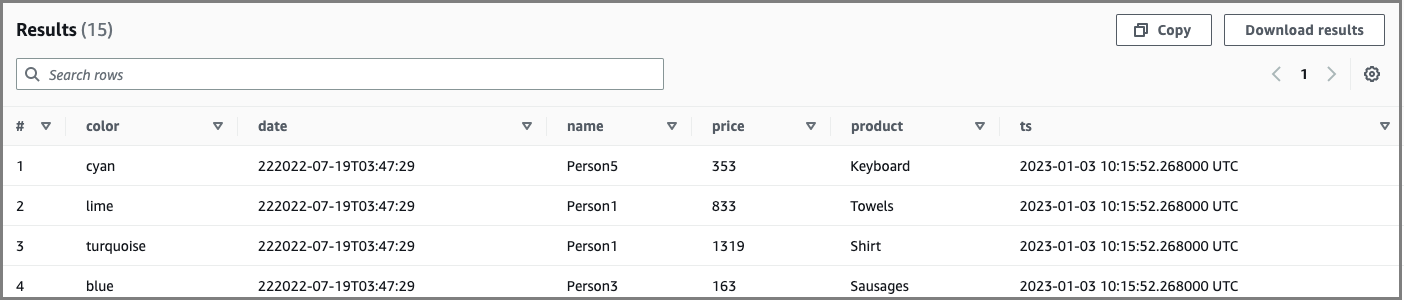
Ad esempio, l'istruzione seguente aggiorna un valore di colore perPerson5, quindi visualizza un valore precedente del 4 gennaio 2023:
UPDATE ice_table SET color='new_color' WHERE name='Person5' SELECT * FROM "iceberg_db"."ice_table" FOR TIMESTAMP AS OF TIMESTAMP '2023-01-04 12:00:00 UTC'
Output di esempio:
Anatomia del tavolo Iceberg
Ora che abbiamo spiegato i passaggi di base per lavorare con i tavoli Iceberg, approfondiamo i dettagli complessi e il design di un tavolo Iceberg.
Per abilitare le funzionalità descritte in precedenza in questa guida, Iceberg è progettato con livelli gerarchici di dati e file di metadati. Questi livelli gestiscono i metadati in modo intelligente per ottimizzare la pianificazione e l'esecuzione delle query.
Il diagramma seguente illustra l'organizzazione di una tabella Iceberg attraverso due prospettive: quella Servizi AWS utilizzata per archiviare la tabella e il posizionamento dei file in Amazon S3.
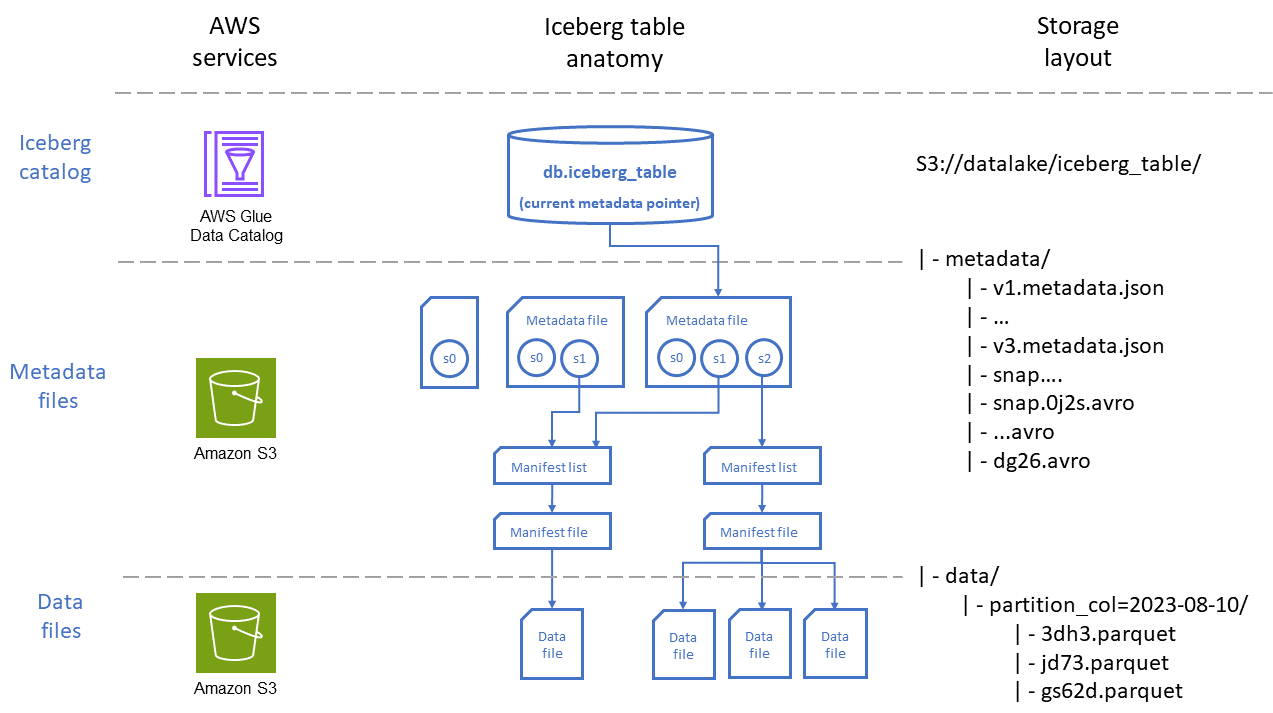
Come mostrato nel diagramma, una tabella Iceberg è composta da tre livelli principali:
-
Catalogo Iceberg: AWS Glue Data Catalog si integra nativamente con Iceberg ed è, per la maggior parte dei casi d'uso, l'opzione migliore per i carichi di lavoro su cui vengono eseguiti. AWS I servizi che interagiscono con le tabelle Iceberg (ad esempio Athena) utilizzano il catalogo per trovare la versione istantanea corrente della tabella, per leggere o scrivere dati.
-
Livello di metadati: i file di metadati, vale a dire i file manifest e i file di elenco manifest, tengono traccia di informazioni come lo schema delle tabelle, la strategia di partizione e la posizione dei file di dati, nonché le statistiche a livello di colonna come gli intervalli minimi e massimi per i record archiviati in ogni file di dati. Questi file di metadati sono archiviati in Amazon S3 all'interno del percorso della tabella.
-
I file manifesto contengono un record per ogni file di dati, inclusi posizione, formato, dimensione, checksum e altre informazioni pertinenti.
-
Gli elenchi manifest forniscono un indice dei file manifest. Man mano che il numero di file manifest in una tabella aumenta, la suddivisione di tali informazioni in sottosezioni più piccole aiuta a ridurre il numero di file manifest che devono essere scansionati mediante query.
-
I file di metadati contengono informazioni sull'intera tabella Iceberg, inclusi gli elenchi dei manifest, gli schemi, i metadati delle partizioni, i file di istantanea e altri file utilizzati per gestire i metadati della tabella.
-
-
Livello dati: questo livello contiene i file che contengono i record di dati su cui verranno eseguite le query. Questi file possono essere archiviati in diversi formati, tra cui Apache Parquet, Apache
Avro e Apache ORC. -
I file di dati contengono i record di dati per una tabella.
-
I file di eliminazione codifica le operazioni di eliminazione e aggiornamento a livello di riga in una tabella Iceberg. Iceberg ha due tipi di eliminazione dei file, come descritto nella documentazione di Iceberg.
Questi file vengono creati mediante operazioni che utilizzano la merge-on-read modalità.
-
